Command Palette
Search for a command to run...
ProRL: التعلم التعزيزي الفعال للتوصية الاستباقية عبر تقدير تدرج السياسة المُصحَّح
ProRL: التعلم التعزيزي الفعال للتوصية الاستباقية عبر تقدير تدرج السياسة المُصحَّح
Hongru Hou Tiehua Mei Denghui Geng Jinhui Huang Ao Xu Hengrui Chen Jiaqing Liang Deqing Yang
الملخص
تهدف أنظمة التوصية الاستباقية (PRSs) إلى توجيه تحول تفضيلات المستخدم نحو العناصر المستهدفة من خلال توليد مسارات من التوصيات الوسيطة. يوفر التعلم التعزيزي (RL) إطاراً منهجياً لتحسين مهام اتخاذ القرار المتسلسل، حيث يمكن لمكافآت المسار أن تلتقط بشكل طبيعي كلاً من القبول قصير المدى وفعالية التوجيه طويلة المدى. ومع ذلك، فإن التطبيق المباشر لتدرجات السياسة على أنظمة التوصية الاستباقية يؤدي إلى تقدير تدرج غير دقيق. نحدد عيبين رئيسيين: (1) تتحلل مكافآت مستوى المسار إلى مكافآت مستوى الخطوة ذات متوسط موجب، مما يخلق تحيزاً يعتمد على الطول يؤدي إلى تفضيل التدرجات لتمديد المسار على الاستكشاف ذي المعنى؛ (2) يؤدي وزن كل خطوة بمكافأة مستوى المسار الكاملة إلى تجاهل بنية التحلل، مما ينتج عنه تباين عالٍ في التدرج. لتصحيح هذين العيبين، نقترح إطار عمل فعال للتعلم التعزيزي هو ProRL، يتضمن آليتين جديدتين للتوصية الاستباقية. أولاً، يعمل توسيط المكافآت التدريجية على طرح المكافآت المتوقعة لتحييد التحيز المعتمد على الطول، مما يضمن أن يؤدي تمديد المسار إلى إشارة تدرج متوقعة تساوي صفراً. ثانياً، يستفيد تقدير الميزة المحددة بالموقع من بنية تحلل المكافآت لحساب خطوط أساس تعتمد على الخطوة، مما يقلل من تباين التدرج. وبشكل مشترك، تنتج هذه الآليات تدرجات سياسة تستهدف بدقة جودة المسار. وتُظهر تجاربنا على ثلاث مجموعات بيانات واقعية أن ProRL يتفوق بشكل كبير على أحدث أنظمة التوصية الاستباقية (PRSs). يتوفر الكود المصدري الخاص بنا على الرابط: https://github.com/hongruhou89/ProRL.
One-sentence Summary
ProRL, a reinforcement learning framework for proactive recommender systems, rectifies the length-dependent bias and high variance of naive policy gradients through Stepwise Reward Centering and Position-Specific Advantage Estimation, enabling precise path optimization that significantly outperforms state-of-the-art systems across three real-world datasets.
Key Contributions
- This work identifies two critical deficiencies in standard policy-gradient estimation for proactive recommendation systems, specifically a length-dependent bias that incentivizes unnecessary path extension and elevated gradient variance caused by uniformly weighting steps with path-level rewards.
- The proposed ProRL framework rectifies these estimation errors through two specialized mechanisms, utilizing Stepwise Reward Centering to eliminate length bias and Position-Specific Advantage Estimation to compute step-dependent baselines without a learned critic.
- Experimental evaluations on three real-world datasets demonstrate that ProRL significantly outperforms state-of-the-art proactive recommender systems, with ablation studies confirming the independent efficacy of each mechanism.
Introduction
Proactive Recommender Systems aim to gradually shift user preferences toward target items by generating sequential paths of intermediate recommendations, a capability that helps platforms introduce new content without alienating users anchored in familiar habits. Prior approaches rely on heuristic rules that optimize locally but fail globally, large language models that are too expensive for production, or supervised imitation learning that cannot discover paths beyond historical data. When researchers attempted to apply standard reinforcement learning to this sequential decision problem, policy gradient estimation broke down due to a length-dependent bias that favored artificially extended paths and high gradient variance from uniform step weighting. To resolve these issues, the authors leverage ProRL, a novel reinforcement learning framework that rectifies policy gradient estimation through Stepwise Reward Centering and Position-Specific Advantage Estimation. These mechanisms neutralize spurious length shortcuts and compute low-variance, step-adapted baselines, enabling the model to effectively optimize both immediate user acceptance and long-term guidance success.
Dataset

- Dataset Composition and Sources: The authors utilize three public recommendation datasets: MovieLens-1M, Steam, and Amazon-Book.
- Subset Details and Filtering Rules: MovieLens-1M contains 1,000,209 interactions across 3,040 items, averaging 165.59 interactions per user, and is filtered with a 20-core constraint for users and a 40-core constraint for items. Steam provides 7,793,069 interactions across 15,474 items, averaging 3.03 interactions per user, and receives the same 20-user and 40-item core filters. Amazon-Book features 29,475,453 interactions across 4,493,336 items, averaging 2.86 interactions per user, and undergoes stricter preprocessing with a 100-core user constraint and a 40-core item constraint.
- Metadata Construction and Sequence Processing: To capture relationships between consecutive items, the authors define bridge attributes for each dataset. MovieLens uses film genres (excluding the broad Drama category), Steam relies on categories, publishers, and developers, and Amazon-Book utilizes product categories. These attributes help identify correlated adjacent items. The raw interactions are then converted into proactive logs that pair historical sequences with target items.
- Training Usage and Data Splitting: The authors partition the filtered data using a user-centric strategy to prevent information leakage and evaluate generalization on unseen users. They divide the interactions into training, validation, and testing sets at an 80, 10, and 10 ratio. This structure supports the model's training and evaluation in proactive recommendation scenarios.
Method
The authors frame proactive recommendation as a reinforcement learning problem where the goal is to generate a sequence of intermediate recommendations that guide a user's preferences toward a specified target item. The system operates within a user simulator that estimates the probability of user acceptance for any given item, enabling reward computation without online feedback. The quality of a recommendation path is quantified using three metrics: Increment of Interest (IoI), which measures the increase in predicted interest in the target item; Increment of Rank (IoR), which measures the improvement in the target's ranking; and Click-Through Rate (CTR), which measures the feasibility of the path by estimating the likelihood of user acceptance of intermediate items. These metrics are combined into a natural reward function Rnath=α⋅IoI+β⋅IoR+γ⋅CTR. The policy, parameterized by πθ, is trained to maximize the expected path reward, which is formulated as a policy gradient objective that includes a KL-divergence term to prevent overfitting to the initial policy π0.
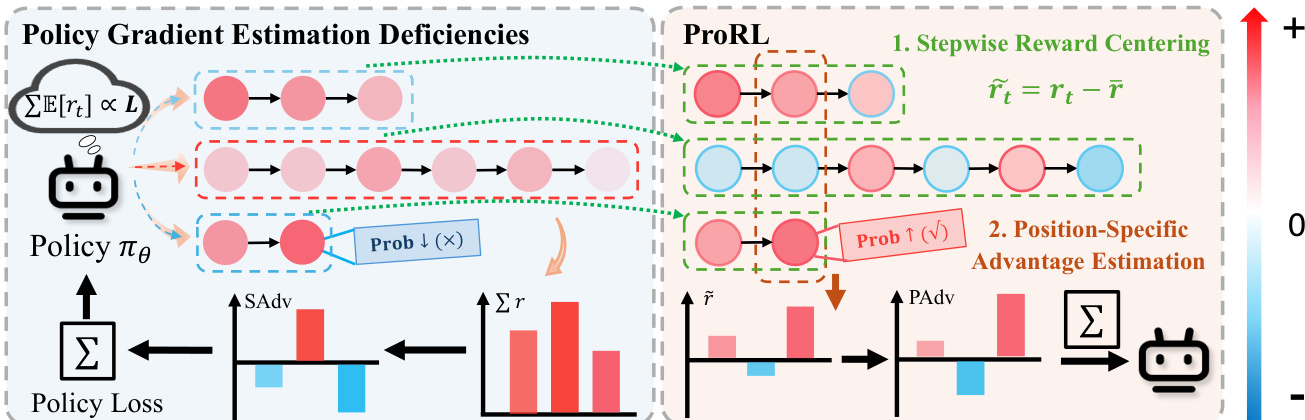
However, the standard policy gradient estimator, which uses the entire path reward as the baseline for each step, suffers from two critical deficiencies in this setting. As shown in the figure below, the standard approach is prone to a "length shortcut," where the positive mean of step-level rewards causes the gradient signal to be dominated by path length, leading the model to generate overly long, redundant paths. This issue is further exacerbated by high gradient variance, as the standard estimator weights each step's gradient by the total path reward, including irrelevant past rewards. The authors identify that the decomposition of the path reward into a sum of step-level rewards, R=∑t=1Lrt, is the root cause of these problems.

To rectify these issues, the authors propose ProRL, which introduces two key mechanisms. First, Stepwise Reward Centering eliminates the length shortcut by subtracting the global expected step reward rˉ from each step-level reward rt, resulting in a centered reward r~t=rt−rˉ. This ensures that the expected gain from extending a path is zero, redirecting the policy's focus from length to path quality. Second, Position-Specific Advantage Estimation (PSE) reduces gradient variance. Instead of using the total path reward as a baseline, PSE computes a reward-to-go Gt for each step t and then subtracts a position-specific baseline Gˉi,t, which is the average reward-to-go at that position across all paths from the same input. This creates an advantage estimate A^t=Gt−Gˉi,t that is a lower-variance, unbiased measure of a step's relative quality, as it only considers future rewards and uses a more adaptive baseline. The rectified gradient estimator is then computed as g^rect=nm1∑i=1n∑j=1m[∑t=1L(i,j)∇θlogπθ(i,j,t)⋅A^t(i,j)]. This two-pronged approach effectively aligns the policy gradient with the true objective of optimizing both the feasibility and effectiveness of the recommendation path.
Experiment
The evaluation benchmarks ProRL against multiple recommendation baselines across diverse datasets, validating its capacity to simultaneously optimize path feasibility and long-term guidance effectiveness. Training dynamics and ablation studies reveal that standard policy gradients suffer from a structural length shortcut that forces models into excessively long, low-quality sequences, whereas ProRL’s rectified gradient estimation eliminates this bias to yield stable, moderate-length paths. Cross-evaluator and robustness analyses further confirm that the approach generalizes reliably across unseen models and varying intervention intensities without overfitting to specific reward signals. Ultimately, the experiments demonstrate that correcting policy gradient estimation unlocks latent guidance capabilities in pretrained models, enabling robust and semantically coherent proactive recommendations.
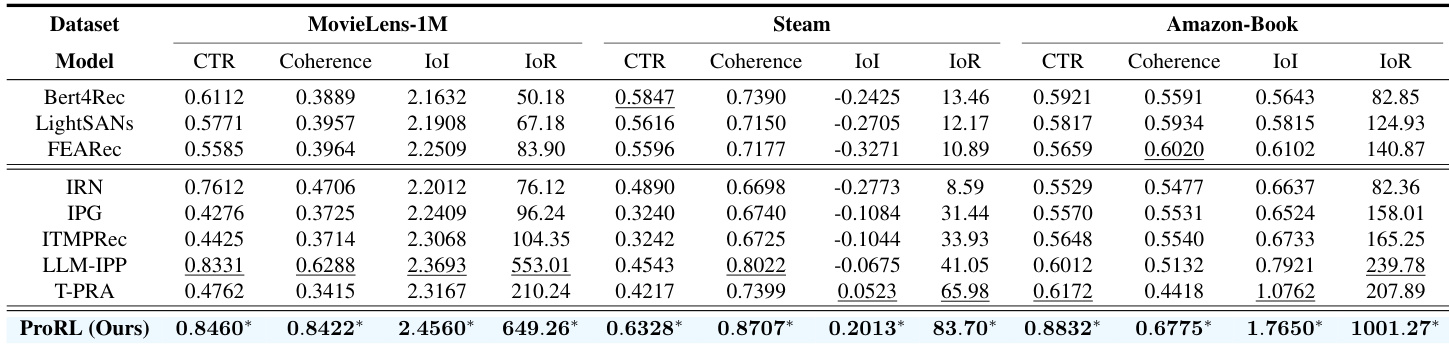
The authors evaluate ProRL against multiple baselines on proactive recommendation tasks across different datasets, demonstrating that their method achieves superior performance in both guidance effectiveness and path feasibility. ProRL consistently outperforms existing methods in metrics such as CTR, coherence, IoI, and IoR, with notable gains in path quality and stability, even when evaluated with unseen recommendation models. The results indicate that ProRL learns generalizable and robust guidance strategies that are not limited to specific reward designs or evaluation models. ProRL achieves the best performance across all datasets and metrics, outperforming both sequential and proactive recommendation methods. ProRL maintains high path feasibility and coherence while significantly improving guidance effectiveness, indicating a balanced optimization of user engagement and recommendation quality. ProRL shows robust and stable performance across different target selection schemes and intervention intensities, demonstrating its adaptability and generalization ability.
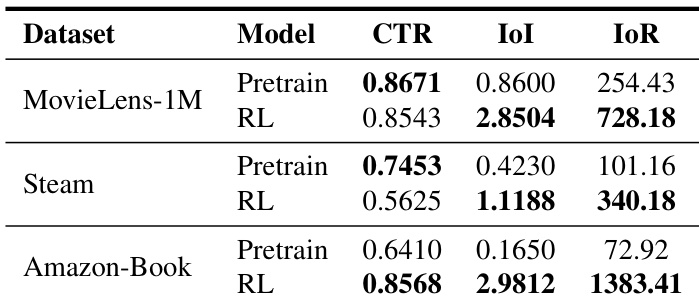
The authors compare the performance of a pretrained model and a reinforcement learning (RL) model across multiple datasets, focusing on metrics related to user engagement and guidance effectiveness. Results show that the RL model consistently outperforms the pretrained model in guidance metrics, while the pretrained model achieves higher path feasibility metrics. The RL model maintains a balance between feasibility and effectiveness, achieving superior overall performance. The RL model outperforms the pretrained model in guidance effectiveness metrics across all datasets. The pretrained model achieves higher path feasibility metrics compared to the RL model. The RL model maintains a balanced performance between path feasibility and guidance effectiveness.
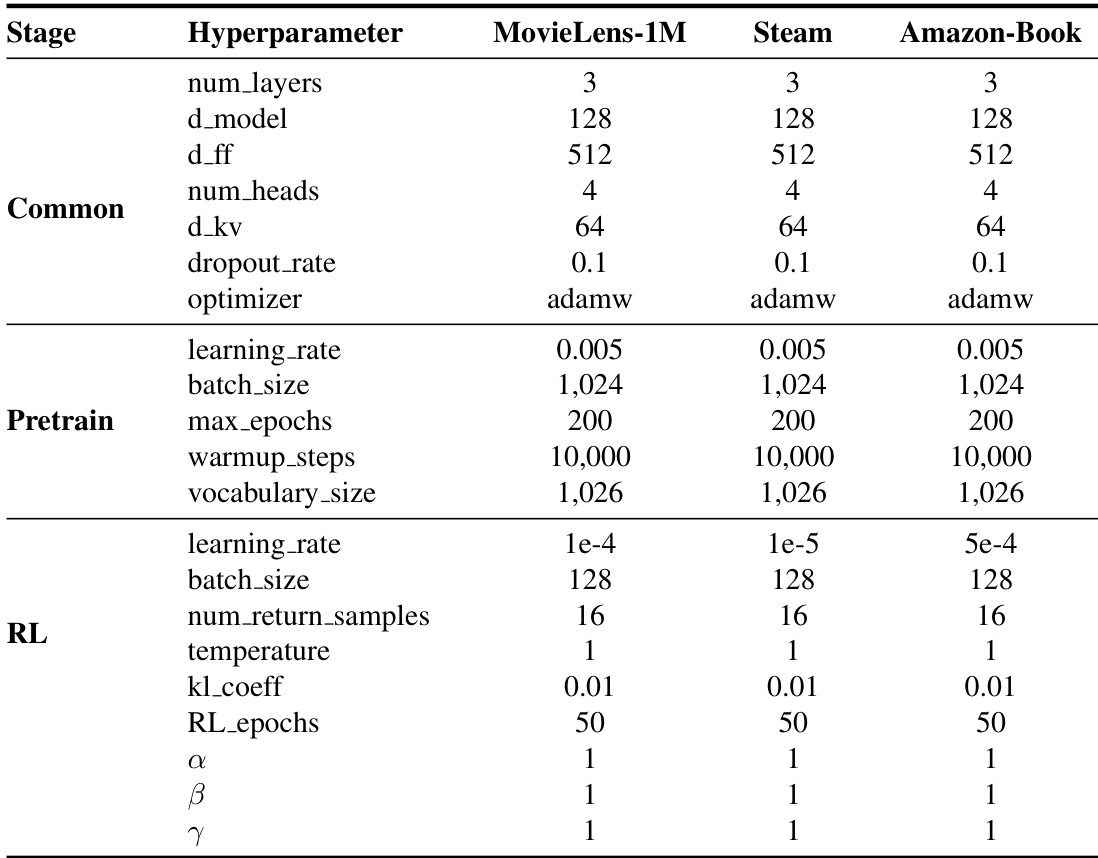
The authors present a comprehensive experimental setup for their ProRL framework, detailing hyperparameters across different training stages including pretraining and reinforcement learning. The the the table shows consistent configurations across datasets for common parameters, while highlighting variations in learning rates and training epochs that reflect dataset-specific requirements. The setup supports the evaluation of proactive recommendation methods with a focus on optimizing guidance effectiveness and user engagement. The experimental setup uses consistent hyperparameters across datasets for common model architecture and optimization settings, with variations in learning rates and training epochs to accommodate dataset-specific characteristics. The reinforcement learning stage employs a lower learning rate and fewer epochs compared to pretraining, indicating a more stable and fine-tuned optimization process. Hyperparameter choices are aligned with the model's dual-phase training approach, supporting both initial supervised learning and subsequent reinforcement learning for improved guidance performance.
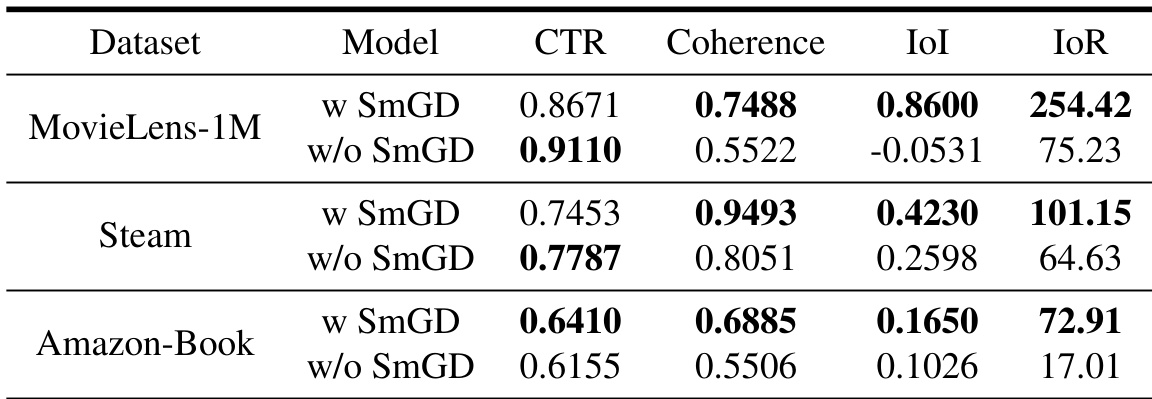
The experiment evaluates the impact of Smooth-Guided Data (SmGD) on proactive recommendation performance across multiple datasets. Results show that models trained with SmGD consistently outperform those without it in terms of Click-Through Rate (CTR), Coherence, and guidance effectiveness metrics (IoI and IoR), indicating that SmGD enhances both user engagement and the quality of guidance. The performance gap is particularly pronounced on dense datasets, suggesting SmGD's effectiveness in preserving user engagement while improving recommendation quality. Models trained with Smooth-Guided Data (SmGD) achieve significantly higher Click-Through Rate and Coherence compared to those without SmGD. The use of SmGD leads to better guidance effectiveness, as measured by IoI and IoR, across all datasets. The performance improvement is most notable on dense datasets, where SmGD helps maintain high user engagement while enhancing recommendation quality.
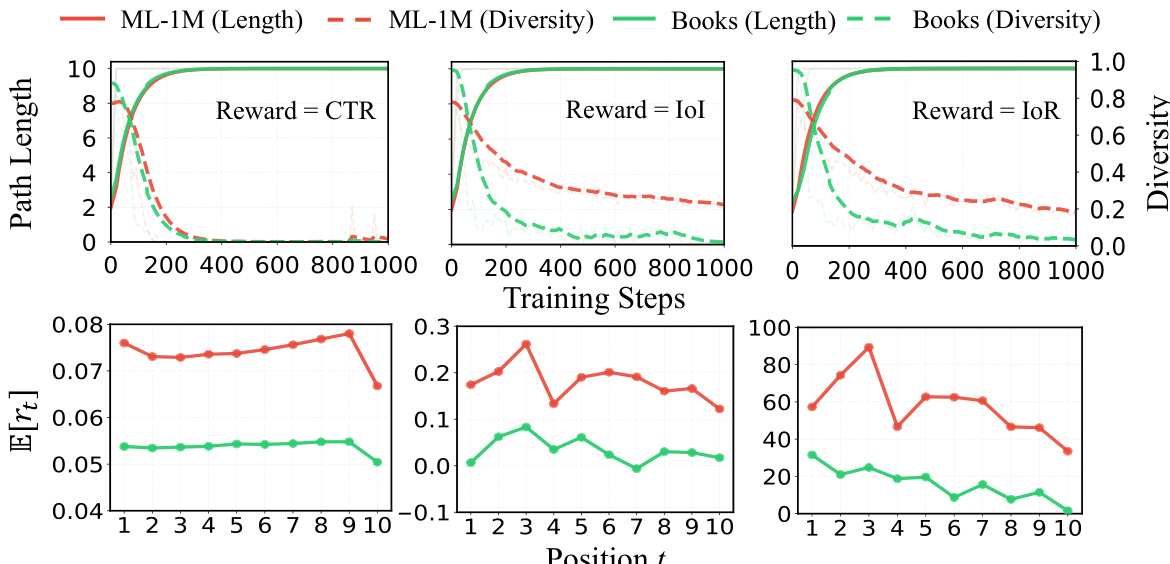
The authors analyze the training dynamics of reinforcement learning policies in proactive recommendation systems, focusing on the interaction between path length and diversity. Results show that policies trained with different reward signals exhibit a consistent pattern: path length rapidly increases to the maximum allowed length while diversity collapses to near zero, indicating a failure mode where the model generates long, repetitive paths. This behavior is attributed to a structural coupling between reward and path length, where positive step-level rewards create an incentive to extend paths, leading to suboptimal convergence. The analysis further reveals that this length shortcut phenomenon is robust across datasets and reward designs, and that the positive bias in expected step rewards remains consistent throughout training. Policies converge to maximum path length while diversity collapses, regardless of the reward signal used. Positive expected step rewards create an incentive for path extension, leading to the length shortcut. The length shortcut is a structural property of reward functions, not a tuning artifact, and is observed across all datasets and reward types.
The evaluation employs a dual-phase training framework that integrates supervised pretraining with reinforcement learning, with hyperparameters adjusted to accommodate dataset-specific characteristics. Comparative experiments demonstrate that ProRL consistently surpasses both sequential and proactive baselines as well as pretrained models, delivering superior guidance effectiveness while preserving high path feasibility and coherence across diverse environments and unseen recommendation architectures. Additional analyses validate the substantial contribution of Smooth-Guided Data in boosting user engagement and recommendation quality, particularly within dense datasets, while further investigating training dynamics reveals a structural length shortcut where positive step rewards inadvertently drive path extension at the expense of diversity. Collectively, these findings establish ProRL as a highly adaptable and robust framework that successfully balances engagement with quality while illuminating critical optimization challenges in proactive recommendation systems.