HyperAI
Command Palette
Search for a command to run...
الأوراق البحثية
أوراق بحثية متطورة في مجال الذكاء الاصطناعي يتم تحديثها يوميًا لمساعدتك على مواكبة أحدث اتجاهات الذكاء الاصطناعي
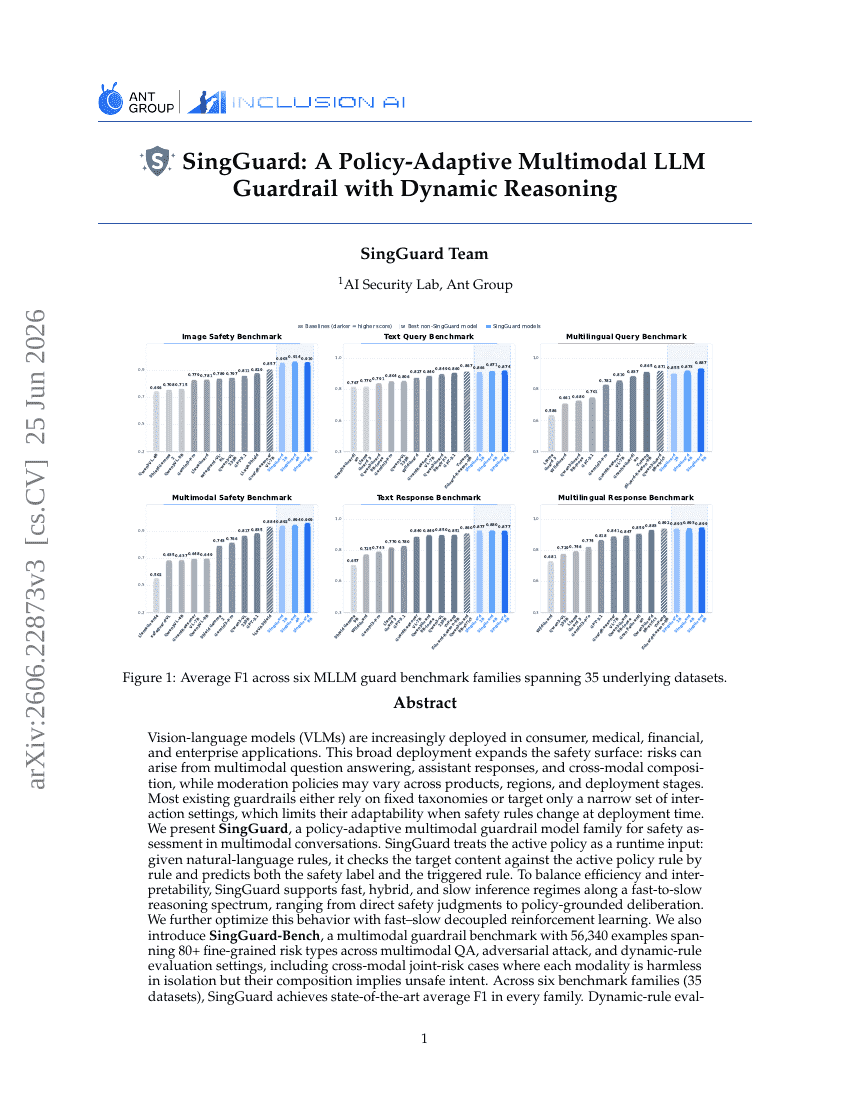
SingGuard: حاجز حماية متعدد الوسائط لنماذج اللغة الكبيرة متكيف مع السياسات مع استدلال ديناميكي

صياغة رسمية للأفكار الكامنة: أربع بديهيات لتمثيل الفكر في نماذج اللغة الكبيرة (LLMs)


























SingGuard: حاجز حماية متعدد الوسائط لنماذج اللغة الكبيرة متكيف مع السياسات مع استدلال ديناميكي
صياغة رسمية للأفكار الكامنة: أربع بديهيات لتمثيل الفكر في نماذج اللغة الكبيرة (LLMs)
MultiHashFormer: نماذج لغوية توليدية قائمة على التجزئة
تقرير تقني حول Qwen-Image-2.0-RL
الإزاحة كإجراء جسري: نقل مهارات التلاعب من البشر إلى الروبوتات
PhysisForcing: محاكي العالم المدعَّم بالفيزياء للتلاعب الروبوتي
OpenTME: مجموعة بيانات مفتوحة تحتوي على ملفات تعريف للميكروبيوم الورمي المُستخلصة من تقنية H&E باستخدام الذكاء الاصطناعي، ومستمدة من مشروع TCGA.
فلاش أتنتينشن-4: تصميم مشترك بين الخوارزمية ومجرى النواة لتحقيق قابلية التوسع غير المتناظرة للأجهزة
DSpark: فك شفريته المفترضة المجدولة حسب الثقة مع التوليد شبه الذاتوي الشرح:
"Confidence-Scheduled" تترجم إلى "المجدولة حسب الثقة" حيث أن "scheduled" تعني مجدولة و "confidence" تعني الثقة. "Speculative Decoding" تترجم إلى "فك شفريته المفترضة" حيث أن "speculative" تعني مفترضة و "decoding" تعني فك شفريته. "Semi-Autoregressive Generation" تترجم إلى "التوليد شبه الذاتوي" حيث أن "semi" تعني شبه و "autoregressive" تعني الذاتوي.
هذا الترجمة تعكس المصطلحات الأكاديمية المتداولة في مجال الذكاء الاصطناعي واللغويات الحاسوبية.
ViQ: تمثيلات بصرية مُكمّاة متوافقة مع النص بأي دقة
أفق التحقق: لا توجد رصاصة فضية لمكافآت البرمجة agent
Qwen-Image-Agent: سد فجوة السياق في توليد الصور في العالم الحقيقي
OPID: تقطير المهارات ضمن السياسة للتعلم التعزيزي الوكيلى
نمذجة العالم في السياق للتحكم الروبوتي
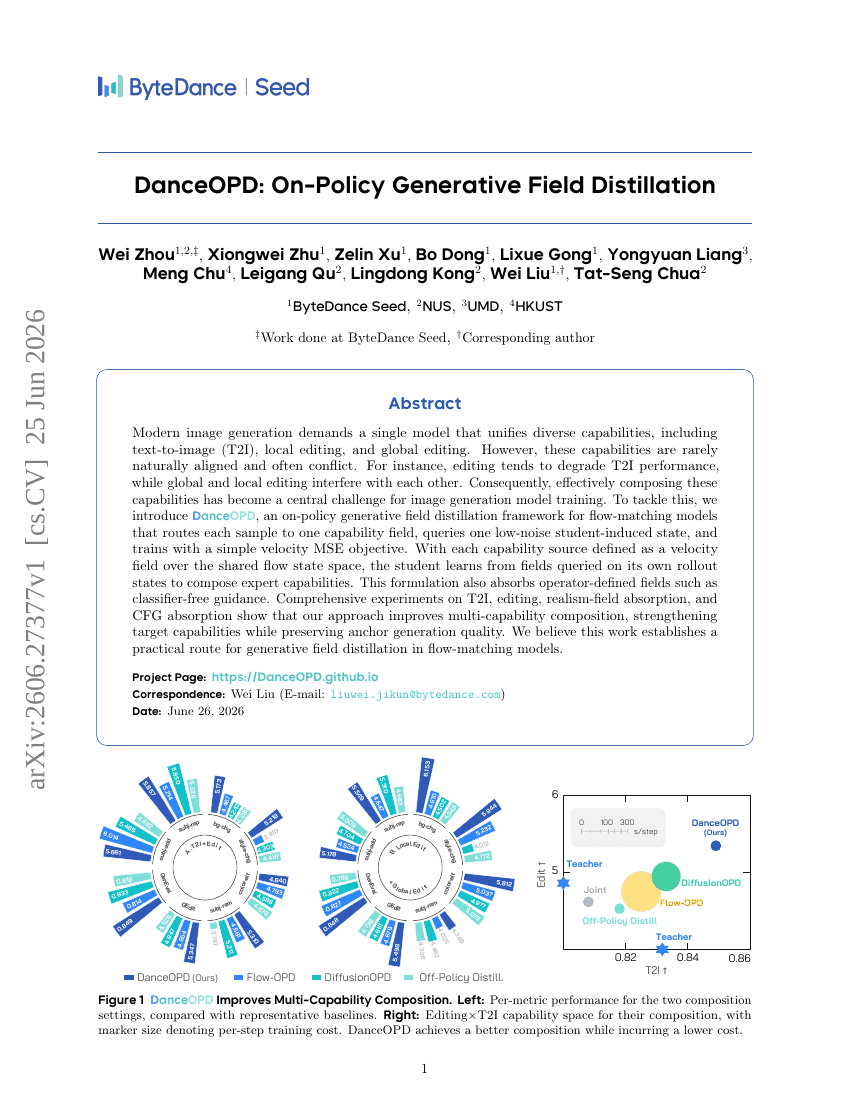
DanceOPD: تقطير الحقل التوليدي حسب السياسة
Autodata: عالم بيانات ذي قدرة على التصرف لإنشاء بيانات صناعية عالية الجودة
نماذج الانتشار الكبيرة المحسنة
ما مدى متانة الاستدلال الضوئي للحروف؟ تقييم متانة الاستدلال الضوئي للحروف لنماذج الرؤية واللغة تحت التشويش البصري
روبوأتلاس: SLAM النشط السياقي
تعلّم الملاحة البصرية للروبوت في الحشود عبر تمثيلات المشهد الواعية بالنوايا
التحكم التنبؤي القائم على البيانات والمُفعّل بالأحداث والمعزّز بالتعلم المعزز العميق لذراع روبوتي لين مدفوع بالكابلات ثلاثي الأبعاد
فك التعمق الطبيعي: التحكم غير المتماثل في القواعد التي تنجو من التدريب المسبق
كل عدد صحيح غير سالب هو مجموع عدد مثلثي، وعدد خماسي الأضلاع، وعدد سباعي الأضلاع
الهندسة التكرارية: دليل Anthropic لتصميم أنظمة تُوجّه وكلاءك
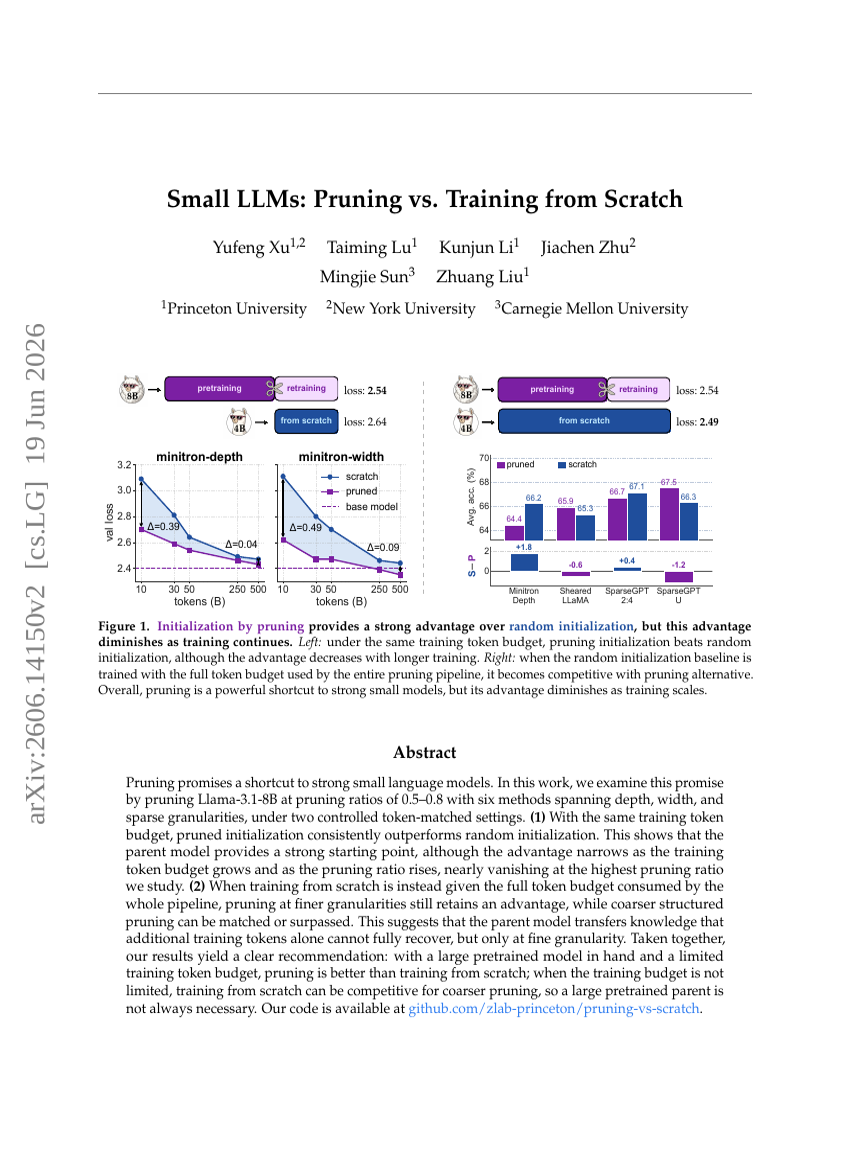
اللغات النموذجية الكبيرة الصغيرة: الحذف مقابل التدريب من الصفر
OpenThoughts-Agent: وصفات البيانات للنماذج الوكيلية
LingxiDiagBench: إطار عمل متعدد الـ Agent لتقييم نماذج اللغات الكبيرة في الاستشارات والتشخيص النفسي باللغة الصينية
AOHP: إطار عمل Agent مفتوح المصدر على مستوى نظام التشغيل لتفاعل مخصص وفعّال وآمن
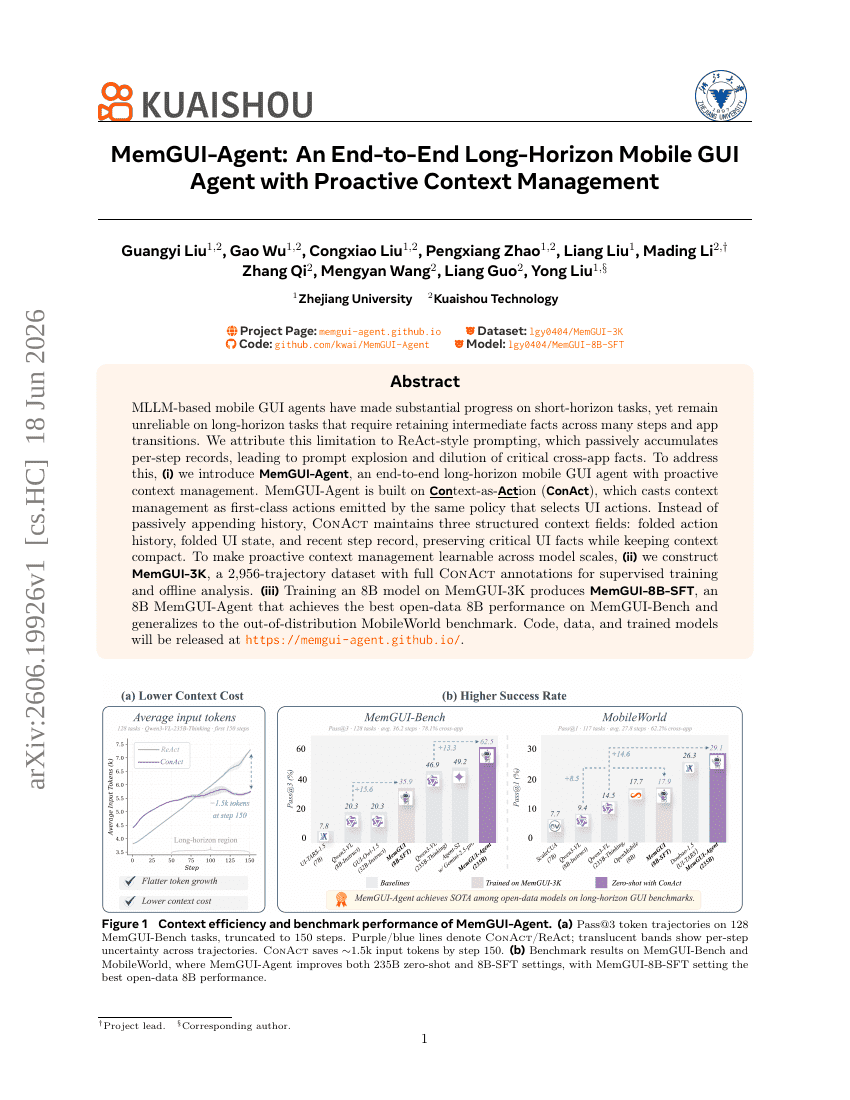
MemGUI-Agent: Mobile Agent طويل المدى من البداية إلى النهاية لواجهة المستخدم الرسومية للجوال مع إدارة السياق الاستباقية
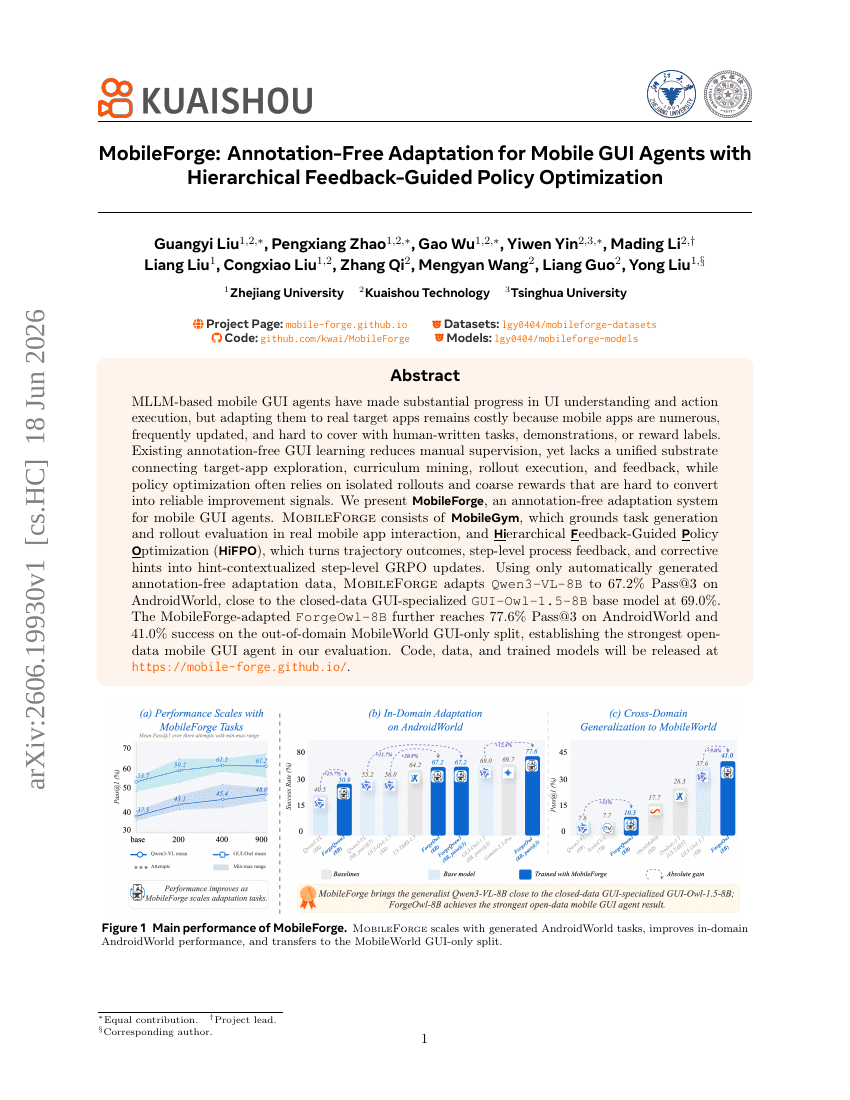
MobileForge: تكييف خالٍ من التوثيق لوكلاء واجهة المستخدم الرسومية على الهاتف المحمول Agents باستخدام تحسين السياسة الموجه بالتغذية الراجعة الهرمية
Qwen-AgentWorld: نماذج العالم اللغوية لـ Agents العامة
إعادة التفكير في أهداف التدريب، المعماريات، وجودة البيانات للتعزيز الصوتي الشامل
MultiHashFormer: نماذج لغوية توليدية قائمة على التجزئة
تقرير تقني حول Qwen-Image-2.0-RL
الإزاحة كإجراء جسري: نقل مهارات التلاعب من البشر إلى الروبوتات
PhysisForcing: محاكي العالم المدعَّم بالفيزياء للتلاعب الروبوتي
OpenTME: مجموعة بيانات مفتوحة تحتوي على ملفات تعريف للميكروبيوم الورمي المُستخلصة من تقنية H&E باستخدام الذكاء الاصطناعي، ومستمدة من مشروع TCGA.
فلاش أتنتينشن-4: تصميم مشترك بين الخوارزمية ومجرى النواة لتحقيق قابلية التوسع غير المتناظرة للأجهزة
DSpark: فك شفريته المفترضة المجدولة حسب الثقة مع التوليد شبه الذاتوي الشرح:
"Confidence-Scheduled" تترجم إلى "المجدولة حسب الثقة" حيث أن "scheduled" تعني مجدولة و "confidence" تعني الثقة. "Speculative Decoding" تترجم إلى "فك شفريته المفترضة" حيث أن "speculative" تعني مفترضة و "decoding" تعني فك شفريته. "Semi-Autoregressive Generation" تترجم إلى "التوليد شبه الذاتوي" حيث أن "semi" تعني شبه و "autoregressive" تعني الذاتوي.
هذا الترجمة تعكس المصطلحات الأكاديمية المتداولة في مجال الذكاء الاصطناعي واللغويات الحاسوبية.
ViQ: تمثيلات بصرية مُكمّاة متوافقة مع النص بأي دقة
أفق التحقق: لا توجد رصاصة فضية لمكافآت البرمجة agent
Qwen-Image-Agent: سد فجوة السياق في توليد الصور في العالم الحقيقي
OPID: تقطير المهارات ضمن السياسة للتعلم التعزيزي الوكيلى
نمذجة العالم في السياق للتحكم الروبوتي
DanceOPD: تقطير الحقل التوليدي حسب السياسة
Autodata: عالم بيانات ذي قدرة على التصرف لإنشاء بيانات صناعية عالية الجودة
نماذج الانتشار الكبيرة المحسنة
ما مدى متانة الاستدلال الضوئي للحروف؟ تقييم متانة الاستدلال الضوئي للحروف لنماذج الرؤية واللغة تحت التشويش البصري
روبوأتلاس: SLAM النشط السياقي
تعلّم الملاحة البصرية للروبوت في الحشود عبر تمثيلات المشهد الواعية بالنوايا
التحكم التنبؤي القائم على البيانات والمُفعّل بالأحداث والمعزّز بالتعلم المعزز العميق لذراع روبوتي لين مدفوع بالكابلات ثلاثي الأبعاد
فك التعمق الطبيعي: التحكم غير المتماثل في القواعد التي تنجو من التدريب المسبق
كل عدد صحيح غير سالب هو مجموع عدد مثلثي، وعدد خماسي الأضلاع، وعدد سباعي الأضلاع
الهندسة التكرارية: دليل Anthropic لتصميم أنظمة تُوجّه وكلاءك
اللغات النموذجية الكبيرة الصغيرة: الحذف مقابل التدريب من الصفر
OpenThoughts-Agent: وصفات البيانات للنماذج الوكيلية
LingxiDiagBench: إطار عمل متعدد الـ Agent لتقييم نماذج اللغات الكبيرة في الاستشارات والتشخيص النفسي باللغة الصينية
AOHP: إطار عمل Agent مفتوح المصدر على مستوى نظام التشغيل لتفاعل مخصص وفعّال وآمن
MemGUI-Agent: Mobile Agent طويل المدى من البداية إلى النهاية لواجهة المستخدم الرسومية للجوال مع إدارة السياق الاستباقية
MobileForge: تكييف خالٍ من التوثيق لوكلاء واجهة المستخدم الرسومية على الهاتف المحمول Agents باستخدام تحسين السياسة الموجه بالتغذية الراجعة الهرمية
Qwen-AgentWorld: نماذج العالم اللغوية لـ Agents العامة
إعادة التفكير في أهداف التدريب، المعماريات، وجودة البيانات للتعزيز الصوتي الشامل