Command Palette
Search for a command to run...
الأنظمة الوكيلية كمعزِّز للنماذج ذات الاستدراك الضعيف
الأنظمة الوكيلية كمعزِّز للنماذج ذات الاستدراك الضعيف
Varun Sunkaraneni Pierfrancesco Beneventano Riccardo Neumarker Tomer Galanti
الملخص
هل يمكن للجنة مكونة من نماذج استدلال ضعيفة أن تبلغ مستويات أداء النماذج الأقوى بكثير؟ تدرس هذه الورقة بحث اللجنة المدعوم بمحقّقين (Verifiers) كآلية لتعزيز الأداء أثناء الاستدلال (Inference-time boosting) في نماذج اللغة المعقّلة (Reasoning Language Models). لا تكمن الآلية ببساطة في فكرة أن "المزيد من الوكلاء يساعد"، بل إن العينات (Samples) تكشف حلولاً صحيحة كامنة، في حين يتعين على النقّاد (Critics) والمقارنات (Comparators) استعادة هذه الحلول دون الوصول إلى المحقّق المخفي. نصوّّر هذا المنظور بشكل رسمي من خلال فصل تغطية المقترحات (Proposal coverage)، والإمكانية المحلية للتحديد (Local identifiability)، والتقدّم، والتنوّع. نُثبت أن التغطية يمكن تضخيمها من خلال العينات المتكررة، ولكن لا يمكنها وحدها توليد نقّاد أو مقارنات مفيدة؛ إذ يتطلب التضخيم الموثوق إشارات محلية للصحة (Local soundness signal)، مثل التنفيذ الفعلي، أو التحقق من البراهين، أو فحص الأنواع، أو الاختبارات، أو حل القيود.نقدم حدوداً قائمة على الترتيب (Rank-based bounds) توضح متى تتراكب أخطاء التحديد المحلي لتُشكّل مسارات موثوقة، ونحدد السقف الأقصى لطرف المقترحات: فإن تحسين "الأفضل من بين كـ" المثالي (Oracle best-of-k) يتقارب فقط نحو كتلة شرائح المهمة التي ينسب فيها نظام المقترحات احتمالاً مفيداً غير صفري. عملياً، ومن خلال مجموعة اختبارات SWE-bench Verified، حلّت مقترحات نموذج GPT-5.4 nano المفرد 67.0% من المهام. وباستخدام نفس النموذج النانوي، حقّقت تنسيقات عمل النقّاد والمقارنات لدينا 76.4% باستخدام k=8 مقترحات، ما يعادل الأداء المستقل لـ Gemini 3 Pro و Claude Opus 4.5 Thinking، ويقترب من الحد الأعلى النظري لمثالي "الأفضل من بين 8" (Oracle best-of-8) والبالغ 79.0%.
One-sentence Summary
The authors propose verifier-backed committee search as an inference-time boosting mechanism for weak reasoning models, demonstrate that reliable amplification requires a local soundness signal beyond sampling coverage, and show that orchestrating critic-comparator systems with GPT-5.4 nano proposals achieves 76.4% accuracy on SWE-bench Verified with k=8 proposals, matching the standalone performance of Gemini 3 Pro and Claude Opus 4.5 Thinking.
Key Contributions
- This work formalizes verifier-backed committee search by separating proposal coverage, local identifiability, progress, and diversity to create a diagnostic lens for multi-agent systems. Theoretical analysis proves that coverage amplification requires local soundness signals and provides rank-based bounds on how selection errors compose into reliable trajectories.
- The method employs verifier-backed committee search as inference-time boosting where critics and comparators recover latent correct solutions from samples without access to a hidden verifier. This orchestration allows weak reasoning models to reach the performance of much stronger models through repeated sampling and local selection.
- Empirical evaluation on SWE-bench Verified demonstrates that a critic-comparator orchestration using a single GPT-5.4 nano model reaches 76.4% task resolution with eight proposals. This performance matches standalone results from Gemini 3 Pro and Claude Opus 4.5 Thinking while approaching the 79.0% oracle best-of-8 upper bound.
Introduction
Verifier-backed reasoning tasks such as code repair and theorem proving require systems to generate intermediate moves and validate them without access to hidden ground truth labels. Existing inference-time methods often rely on repeated sampling or voting, yet these strategies struggle when models share blind spots or lack the ability to distinguish correct partial solutions from flawed ones. The authors formalize agentic systems as inference-time boosting by separating proposal coverage from local identifiability and proving that reliable amplification requires additional soundness signals like execution or type checking. Their theoretical bounds characterize the limits imposed by shared blind spots while empirical results on SWE-bench Verified show that orchestrating weak models can match the performance of substantially stronger standalone systems.
Method
The authors model verifier-backed agent systems as a bounded-depth search process over partial objects, such as intermediate proof states or partially written programs. They define a valid state system where a state represents a partial reasoning object, and a rank function dx(s) measures the "distance from solution." The goal is to transition from an initial state s0(x) to a terminal state where the verifier accepts the solution. This process relies on the existence of progressing-sound actions, which preserve validity and strictly decrease the rank function.
The core architecture is the Committee Protocol Πk,m,r, which separates generation from identification. At each reachable non-terminal state s, the protocol executes a three-stage loop to select the next action. First, a proposer harness samples k candidate actions. Second, m independent critic calls are applied to each candidate to filter out locally refutable errors. Third, among the surviving candidates, a Copeland winner is selected using r comparator votes per pair. This selected action transitions the system to the next state st+1. The process repeats for a bounded number of steps L.
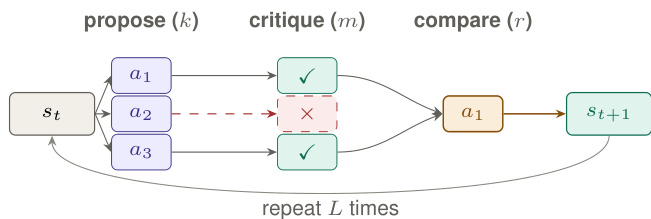
The theoretical guarantee of this architecture depends on two distinct resources: proposal coverage and local identifiability. Assumption 1 posits that a proposer portfolio exists such that a progressing-sound action can be sampled with non-zero probability α0. Assumption 2 ensures efficient local identifiability, meaning critics can reject unsound actions with probability at least β0, and comparators can prefer sound actions over unsound ones with probability at least 1/2+σ0.
The authors derive a local error decomposition for the probability of selecting an unsound action or failing locally. This error εloc(s) is bounded by the sum of proposal failure and identification failure. Specifically, the identification error decreases exponentially with the number of critic calls m and comparator votes r, governed by the edges β and σ. The global failure probability over a trajectory of length Lx is bounded by the sum of local errors at each step.
Further analysis of the proposal term reveals a "blind-spot floor." The probability of proposal failure converges to a value Bs as k→∞, representing latent subpopulations where the proposal system assigns zero probability to sound actions. Increasing k reduces the finite-sampling residual but cannot eliminate the blind-spot floor. To achieve reliable amplification, the system requires both a diverse proposer portfolio to cover the search space and a sound verification signal to identify valid moves. In the experimental instantiation, the critic is implemented as a binary patch judge, and the comparator performs pairwise evaluations of code patches to determine which is more likely to resolve the issue without breaking existing functionality.
Experiment
The experiments evaluate inference-time orchestration on SWE-bench Verified using a fixed pool of candidate patches to isolate selection quality from generation capabilities. Results indicate that while proposal diversity exposes latent correct solutions, a combined harness of critics and comparators is necessary to recover most of this potential, with critics filtering flawed patches and comparators ranking plausible ones. Failure decomposition reveals that remaining errors stem primarily from proposal coverage limitations rather than selection failures, suggesting that future gains require more diverse proposers alongside robust selection mechanisms.
The authors evaluate selector ablations to determine the impact of aggregation rules and critic thresholds on solve rates. Results show that all-pairs aggregation methods like Copeland round-robin and strict dominance outperform single-elimination brackets. Additionally, introducing a permissive critic gate significantly improves performance over using comparators alone, with optimal results found at lower thresholds before performance declines with stricter filtering. All-pairs aggregation methods yield better results than single-elimination brackets. Filtering out patches with zero critic support improves performance compared to using no gate. Stricter critic thresholds beyond the optimal level lead to slight performance decreases.
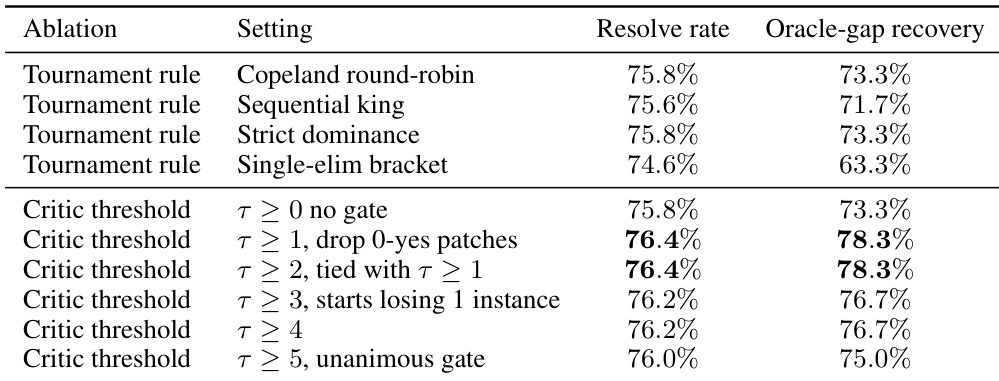
The authors evaluate selector ablations to determine the impact of aggregation rules and critic thresholds on solve rates. Results demonstrate that all-pairs aggregation methods, including Copeland round-robin and strict dominance, outperform single-elimination brackets. Furthermore, introducing a permissive critic gate enhances performance compared to using comparators alone, although performance declines with stricter filtering.