Command Palette
Search for a command to run...
سوّاق القصص: نحو اتساق بصري طويل المدى يمكن التحكم فيه مع تكييف متعدد الوسائط
سوّاق القصص: نحو اتساق بصري طويل المدى يمكن التحكم فيه مع تكييف متعدد الوسائط
Zhengjian Yao Yongzhi Li Xinyuan Gao Quan Chen Peng Jiang Yanye Lu
الملخص
نقدم "Narrative Weaver"، إطار عمل مبتكر يهدف إلى معالجة تحدٍ أساسي في مجال الذكاء الاصطناعي التوليدي: وهو تحقيق توليد محتوى مرئي طويل المدى، متسق، وقابل للتحكم متعدد الوسائط (multi-modal). في حين تفوق النماذج الحالية في توليد محتوى مرئي قصير المدى وعالي الجودة، فإنها تواجه صعوبات في الحفاظ على الترابط السردي والاتساق البصري عبر تسلسلات طويلة، وهو ما يمثل قيداً حاسماً للتطبيقات الواقعية مثل صناعة الأفلام والإعلانات التجارية. يُقدم "Narrative Weaver" الحل الشامل الأول الذي يدمج بسلاسة ثلاث قدرات أساسية: التحكم الدقيق (fine-grained control)، والتخطيط السردي الآلي، والاتساق طويل المدى (long-range coherence). يجمع نظامنا بين نموذج لغوي كبير متعدد الوسائط (MLLM) للتخطيط السردي عالي المستوى مع وحدة تحكم دقيقة جديدة تحتوي على "بنك ذاكرة ديناميكي" (dynamic Memory Bank) يمنع انحراف العناصر البصرية (visual drift). ولتمكين النشر العملي، قمنا بتطوير استراتيجية تدريب تقدمية ومتعددة المراحل تستغل بفعالية النماذج المدربة مسبقاً، محققةً أداءً متفوقاً حتى مع وجود بيانات تدريب محدودة. وإدراكاً منها من عدم وجود معايير تقييم مناسبة، قمنا بإنشاء وإطلاق مجموعة بيانات لوحات القصة الإعلانية التجارية (E-commerce Advertising Video Storyboard Dataset - EAVSD)، وهي أول مجموعة بيانات شاملة لهذا المهمة، تتضمن أكثر من 330 ألف صورة عالية الجودة مع_annotations سردي غنية.
One-sentence Summary
Narrative Weaver addresses the challenge of multi-modal controllable, long-range, and consistent visual content generation by integrating a Multimodal Large Language Model for narrative planning with a dynamic Memory Bank to prevent visual drift, employing a progressive, multi-stage training strategy, and releasing the E-commerce Advertising Video Storyboard Dataset as the first comprehensive dataset for filmmaking and e-commerce advertising.
Key Contributions
- This work presents Narrative Weaver, a framework designed to achieve multi-modal controllable and consistent visual content generation across extended sequences. The architecture combines a Multimodal Large Language Model (MLLM) for high-level planning with a dynamic Memory Bank module to prevent visual drift.
- A progressive, multi-stage training strategy is developed to efficiently leverage existing pre-trained models for practical deployment. This approach achieves state-of-the-art performance even when operating with limited training data.
- To address the absence of suitable evaluation benchmarks, the E-commerce Advertising Video Storyboard Dataset (EAVSD) is constructed and released containing over 330K high-quality images. This resource provides rich narrative annotations specifically designed for conditional image-to-multiframe generation tasks.
Introduction
Generative AI models currently excel at producing high-fidelity short-form content but struggle to maintain narrative coherence and visual consistency across extended sequences, a critical limitation for real-world applications like filmmaking and e-commerce advertising. Existing approaches often rely on purely textual conditioning or fail to anchor subsequent frames to initial visual inputs, leading to character and background drift over time. To bridge this gap, the authors present Narrative Weaver, a framework that integrates a Multimodal Large Language Model for automatic narrative planning with a dynamic Memory Bank to ensure long-range visual consistency. They further introduce a progressive multi-stage training strategy and release the E-commerce Advertising Video Storyboard Dataset to address the scarcity of suitable evaluation benchmarks for controllable multi-modal generation.
Dataset
The authors utilize three primary datasets for training and evaluation, detailed as follows:
-
E-commerce Advertising Video Storyboard Dataset (EAVSD)
- Composition: This proprietary dataset contains 36K samples totaling approximately 330K high-quality images designed for conditional image-to-multiframe generation.
- Structure: Each instance pairs an initial condition, consisting of a product image and textual instruction, with a target output containing a narrative plan and storyboard images.
- Generation Pipeline: Proprietary e-commerce texts are processed by Qwen3-30B-A3B to generate detailed prompts. Reference images are created using Qwen-Image, followed by keyframe synthesis via Flux.1-kontext to ensure cross-frame consistency.
- Filtering: An automated Qwen2.5-VL-32B model filters the data to remove AI artifacts such as malformed limbs and verifies entity preservation and stylistic coherence.
- Prompting Strategy: Instructions avoid specific clothing or identity details to preserve subject consistency, focusing instead on actions, environment, and camera angles.
-
CoMM Dataset
- Usage: Employed to evaluate autonomous narrative generation capabilities.
- Selection: The authors selected the Instructables and WikiHow subsets to address data imbalance found in the original compilation.
- Processing: Samples are limited to 16 images and 12 step elements. Training data is created by randomly truncating sequences, yielding roughly 170K continuation samples and 150K question-based samples.
- Resolution: All images are rescaled to 512×512 pixels to maintain consistency with the original benchmark.
-
CI-VID Dataset
- Usage: Utilized for video narrative generation tasks.
- Processing: The fifth frame is selected from each video segment to serve as the anchor.
- Inputs: The first frame uses the clip caption, while subsequent frames rely on inter-clip transition descriptions.
- Resolution: Data is processed at 480p (480×854) with the original aspect ratio preserved.
Method
The authors present Narrative Weaver, a hybrid framework that integrates Autoregressive (AR) planning with Diffusion-based visual generation to create coherent visual narratives. As illustrated in the framework overview below:
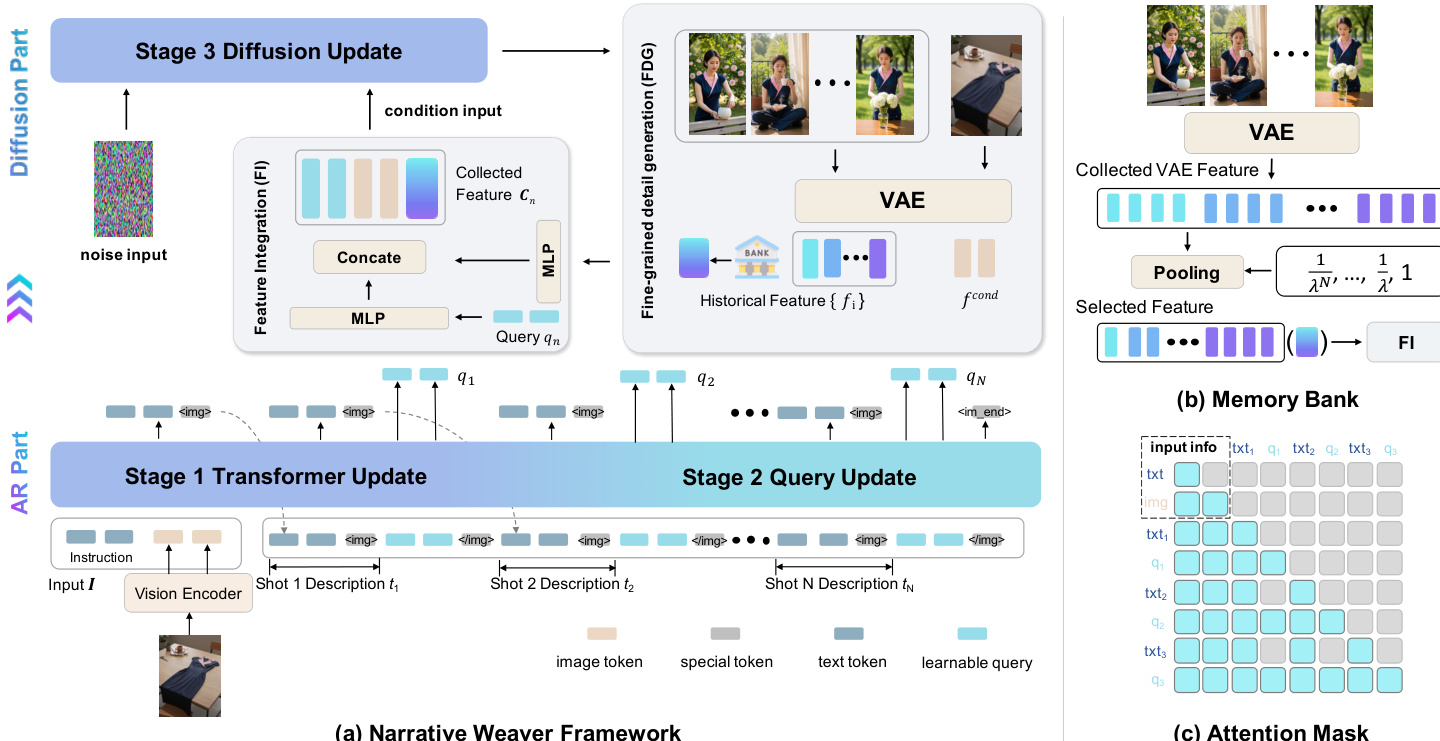
The system is divided into an AR part and a Diffusion part. The AR component, based on a Multimodal Large Language Model (MLLM), processes input I (condition images and instructions) to explicitly plan narrative logic T in textual form and condense historical multimodal information into learnable queries Q. These queries serve as a compact high-level representation for the diffusion model. To ensure temporal stability across generated sequences, the framework employs a Memory Bank. This module caches VAE features of previously generated images. To manage computational costs and emphasize recent history, the features undergo a series-based decay via average pooling with a decay factor λ. This geometric decay ensures a bounded total sequence length for the aggregated memory features. The comprehensive conditioning signal Cn for the n-th keyframe is formed by concatenating the current learnable query qn, the VAE feature of the input conditioning image fcond, and the pooled features from the memory bank.
For multimodal interaction, the authors propose a dynamic causal attention mask. In this configuration, each learnable query qn has access to the full multimodal context (input I, narrative text, and previous queries), ensuring visual coherence. In contrast, textual tokens are constrained by a causal mechanism to facilitate robust narrative planning. Special tokens <img> and </img> bracket the query sequence, allowing the model to learn the timing for visual output.
The training process follows a progressive multi-stage strategy designed to decouple narrative planning from visual generation.
- Stage 1 (Narrative Planning): The MLLM is trained to formulate narrative plans while the ViT encoder remains frozen. The objective minimizes the negative log-likelihood of ground-truth text tokens.
- Stage 2 (Semantically Coherent Visual Generation): This stage trains the learnable queries and the projector connecting the MLLM to the diffusion model. It involves pre-training on large-scale text-image pairs followed by fine-tuning on high-resolution samples to align queries with the diffusion model's semantic space.
- Stage 3 (Fine-grained Alignment): The diffusion model is fully trained to achieve fine-grained inter-visual consistency. The conditioning signal is augmented with low-level visual features from the VAE branch and the Memory Bank.
To support this framework, the authors utilize a structured data construction pipeline involving specific prompt templates to generate high-quality training data. Refer to the prompt template below:

This template guides the generation of advertising shot descriptions with strong storytelling and marketing appeal, ensuring the generated content highlights the product and adheres to specific style requirements such as cinematic lighting and detailed scene descriptions. The system is designed to handle both long-range image and video generation, leveraging the efficiency of the MLLM mediator to reduce computational complexity from quadratic to linear growth with the number of images.
Experiment
The evaluation systematically assesses Narrative Weaver on long-range visual consistency, autonomous narrative planning, and practical utility in e-commerce scenarios. Qualitative and quantitative results demonstrate that the model maintains robust character identity and stylistic coherence across frames while effectively utilizing cinematic conventions such as cross-cutting and reverse shots. Furthermore, user studies and ablation analyses confirm that the framework achieves superior performance by balancing semantic alignment with fine-grained control, offering a scalable solution for coherent visual storytelling.
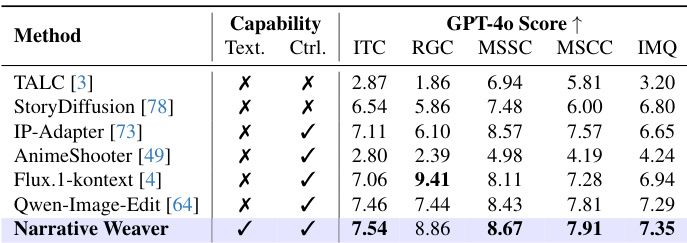
The authors evaluate Narrative Weaver against multiple baseline methods using GPT-4o scoring across five key dimensions of visual generation. The results indicate that the proposed method achieves state-of-the-art performance in most categories, particularly excelling in maintaining style and content consistency across multiple shots. While specialized editing models show higher reference fidelity, Narrative Weaver demonstrates superior overall balance in text-image alignment and image quality. Narrative Weaver achieves the highest scores in Image-Text Consistency, Multi-Shot Style Consistency, Multi-Shot Content Consistency, and Image Quality. The proposed method supports both text generation and control capabilities, unlike most baseline approaches which lack one or both features. Specialized editing models outperform the proposed method in reference fidelity but fall short in maintaining multi-shot style and content consistency.
The the the table compares the computational cost of the proposed method against a vanilla baseline across varying numbers of generated keyframes. Results indicate that while the baseline method suffers from a steep increase in computational demand as sequence length grows, the proposed approach maintains a much flatter and more efficient growth curve. The proposed method demonstrates significantly better scalability, keeping computational costs low even with a higher number of keyframes. In contrast, the vanilla implementation shows a rapid increase in resource usage as the number of frames rises. The efficiency advantage is particularly pronounced for longer sequences, where the baseline cost becomes substantially higher than the proposed method.

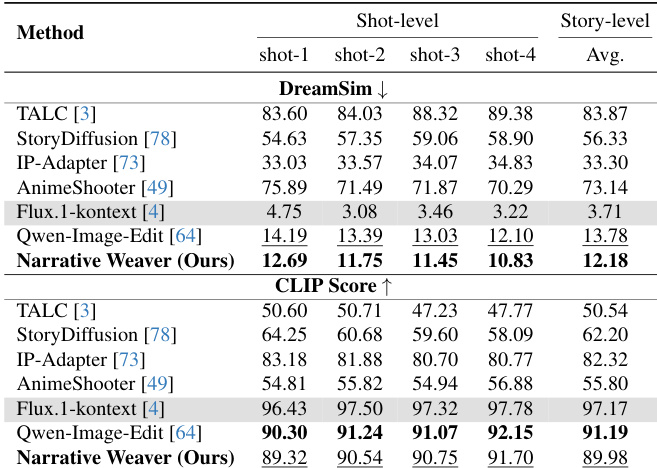
The the the table evaluates consistent keyframe generation using DreamSim and CLIP Score metrics across multiple shot levels. Narrative Weaver outperforms video generation baselines like TALC and StoryDiffusion, showing superior balance between consistency and dynamic storytelling. While specialized editing models achieve higher metric scores, they often suffer from static artifacts, whereas the proposed method successfully maintains coherence across the sequence. Narrative Weaver surpasses multi-scene video generation baselines in both consistency and text-image alignment metrics. Specialized editing models achieve higher numerical scores but tend to produce static results lacking dynamic narrative progression. The proposed method maintains strong performance across sequential shots, demonstrating effective long-range consistency preservation.
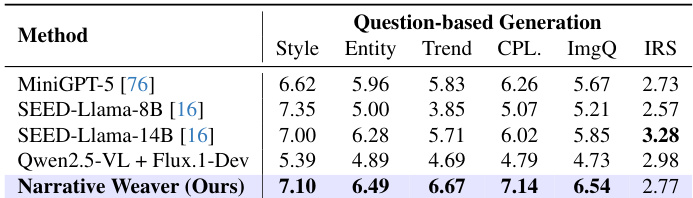
The authors assess autonomous narrative planning capabilities through a question-based generation task, comparing their approach against various open-source baselines. The proposed method demonstrates superior performance across the majority of evaluation dimensions, particularly excelling in consistency metrics and narrative integrity. The proposed method achieves the highest scores in style, entity, and trend consistency. Superior performance is observed in narrative completeness and image quality evaluations. The model effectively balances narrative planning with visual fidelity across multiple dimensions.
The ablation study evaluates the specific contributions of Stage 2 and Stage 3 training to the model's overall performance. Results indicate that the full configuration, which includes both stages, yields the superior performance across all measured dimensions. Excluding either stage leads to a decline in scores, confirming that both semantic coherence and visual consistency training are essential for the method's effectiveness. The complete model combining Stage 2 and Stage 3 achieves the highest average score and top results in most consistency metrics. Including Stage 3 notably improves multi-shot style and content consistency compared to the variant without it. The absence of either training stage results in lower overall performance, validating the necessity of the full multi-stage pipeline.
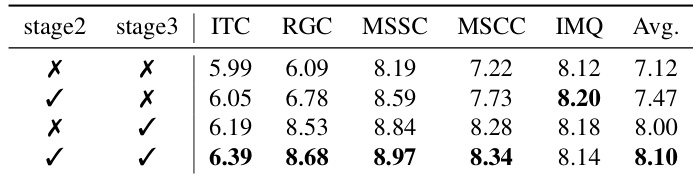
The authors evaluate Narrative Weaver against multiple baselines using GPT-4o scoring and consistency metrics to assess visual generation and autonomous narrative planning. Results indicate that the proposed method achieves state-of-the-art performance in style and content consistency with superior scalability, while outperforming specialized editing models by maintaining dynamic narrative progression. Ablation studies confirm that the multi-stage training pipeline is necessary to balance semantic coherence with visual fidelity.