Command Palette
Search for a command to run...
نماذج الإجراءات العالمية هي سياسات ذات قدرة على التكيف الفوري (Zero-shot Policies).
نماذج الإجراءات العالمية هي سياسات ذات قدرة على التكيف الفوري (Zero-shot Policies).
الملخص
تتميز نماذج الرؤية-اللغة-الإجراء (Vision-Language-Action - VLA) المتقدمة في تحقيق تعميم دلالي، إلا أنها تواجه صعوبات في التعميم على الحركات الفيزيائية غير المرئية في بيئات جديدة. نقدم "DREAM ZERO"، وهو نموذج العالم للإجراء (World Action Model - WAM) مبني على أساس نموذج انتشار الفيديو المدرب مسبقاً. على عكس نماذج VLA، تتعلم نماذج WAM الديناميكيات الفيزيائية من خلال التنبؤ بحالات العالم المستقبلية والإجراءات المتوقعة، مستخدمة الفيديو كتمثيل كثيف لكيفية تطور العالم. ومن خلال نمذجة الفيديو والإجراء معاً، تتعلم DREAM ZERO مهارات متنوعة بفعالية من بيانات الروبوتات المختلفة دون الاعتماد على التكرار الشديد في العرض العملي. ونتيجة لذلك، تم تحقيق تحسين بنسبة تزيد عن الضعف (2x) في التعميم على المهام والبيئات الجديدة مقارنةً بنماذج VLA المتقدمة في تجارب الروبوتات الحقيقية. وأخيراً، من خلال التحسينات في النظام والنموذج، أصبح من الممكن لنموذج انتشار الفيديو الذاتي الانحدار ذي الـ 14 مليار معامل أن يتحكم بشكل مغلق في الوقت الفعلي بسرعة 7 هرتز. وأخيراً، أثبتنا شكلين من أشكال النقل عبر الهياكل المختلفة: إظهار النتائج من خلال بيانات فيديو فقط من روبوتات أخرى أو البشر يؤدي إلى تحسين نسبي يزيد عن 42% في أداء المهام غير المرئية مع استخدام 10-20 دقيقة فقط من البيانات. والأكثر إثارة للدهشة، أن DREAM ZERO قادر على التكيف قليل العينات مع الهياكل المختلفة، حيث ينتقل إلى هيكل جديد مع بيانات لعب لمدة 30 دقيقة فقط مع الحفاظ على التعميم غير المشروط.
One-sentence Summary
DREAM ZERO is a World Action Model built upon a pretrained 14B autoregressive video diffusion backbone that learns physical dynamics by predicting future world states and actions, enabling diverse skill learning from heterogeneous robot data without repetitive demonstrations while achieving over 2x improvement in generalization compared to state-of-the-art Vision-Language-Action models, real-time closed-loop control at 7Hz, and over 42% relative improvement on unseen tasks through video-only cross-embodiment transfer.
Key Contributions
- DREAM ZERO is introduced as a World Action Model built on a pretrained video diffusion backbone that jointly predicts future world states and actions using video as a dense representation of physical dynamics. This approach achieves over 2x improvement in generalization to new tasks and environments compared to state-of-the-art VLAs in real robot experiments.
- Model and system optimizations enable a 14B autoregressive video diffusion model to perform real-time closed-loop control at 7Hz. This capability avoids the need for test-time optimization or search procedures typically required by alternative world model architectures.
- Cross-embodiment transfer is demonstrated where video-only demonstrations from other robots or humans yield over 42% relative improvement on unseen task performance with just 10 to 20 minutes of data. The method further supports few-shot embodiment adaptation by transferring to a new embodiment with only 30 minutes of play data while retaining zero-shot generalization.
Introduction
State-of-the-art Vision-Language-Action models excel at semantic generalization but struggle to adapt to unseen physical motions or novel environments due to a lack of spatiotemporal priors. These models often rely on repetitive demonstrations and fail to transfer skills across different robot embodiments without extensive task-specific data. The authors introduce DREAM ZERO, a 14B World Action Model built upon a pretrained video diffusion backbone that jointly predicts future world states and actions. This architecture allows the system to learn diverse skills from heterogeneous robot data while inheriting rich physical dynamics from web-scale video pretraining. Consequently, the model achieves over 2x improvement in zero-shot generalization compared to existing VLAs and supports cross-embodiment transfer using minimal video-only demonstrations. System optimizations further enable real-time closed-loop control at 7Hz.
Dataset
-
Dataset Composition and Sources
- The authors utilize two primary sources for pretraining: proprietary AgiBot G1 teleoperation data and the public DROID dataset.
- AgiBot data spans 22 real-world environments including homes, restaurants, and offices, totaling approximately 500 hours across 7.2K episodes.
- DROID serves as a heterogeneous validation set collected on a Franka single-arm robot to ensure reproducibility.
- Post-training relies on three specific downstream tasks collected on the AgiBot robot.
-
Key Details for Each Subset
- AgiBot Pretraining episodes average 4.4 minutes and contain roughly 42 subtasks per episode.
- Post-training subsets include Shirt folding (33 hours), Fruit packing (12 hours), and Table bussing (40 hours).
- The DROID subset is used to evaluate performance on open-source heterogeneous data.
-
Model Usage and Training Configuration
- The authors train using a Wan2.1-I2V-14B-480P image-to-video diffusion backbone.
- Pretraining runs for 100K steps with a global batch size of 128 for both AgiBot and DROID datasets.
- Post-training consists of 50K steps per specific task.
- The text encoder, image encoder, and VAE remain frozen while DiT blocks and action encoders are updated.
- Idle actions are filtered out during data preparation.
-
Processing and Collection Strategy
- Data collection prioritizes diversity over repetition by collecting across varied real-world settings rather than controlled labs.
- Each episode combines three distinct tasks to maximize diversity and encourage learning smooth task transitions.
- Tasks are deprecated from the collection sheet after 50 episodes to force the expansion of the task distribution.
- Relative joint positions serve as the default action representation.
- Evaluation protocols include applying an image overlay to the initial scene to reduce variance during post-training assessment.
Method
The authors propose DreamZero, a framework designed to convert pretrained video diffusion models into effective World Action Models (WAMs). As illustrated in the overview, the system leverages diverse, non-repetitive pretraining data to achieve zero-shot generalization to unseen tasks and environments, as well as few-shot adaptation to new embodiments.

The core architecture is a Joint Video-Action Diffusion Transformer (DiT). Refer to the framework diagram which details the training and inference pipeline. The model takes video, action, proprioception, and language as inputs. Video frames are encoded into latents via a VAE Encoder, while actions are processed by an Action Encoder. Proprioception and language are handled by a State/Text Encoder. These modalities are fused and passed into Causal DiT Blocks. The model is trained to jointly denoise video latents and action chunks.
During training, the authors employ a flow-matching objective. The model predicts the velocity field for both video and action modalities. To handle variable-length trajectories, the model operates in an autoregressive, chunk-wise manner. Each chunk contains a fixed number of latent frames matching the action horizon. The attention mask, shown in the grid diagram, ensures that the current noisy chunk can attend to the clean context of previous chunks while preventing information leakage from future tokens. This design facilitates teacher forcing, where the model is trained to denoise the current chunk conditioned on clean previous chunks.
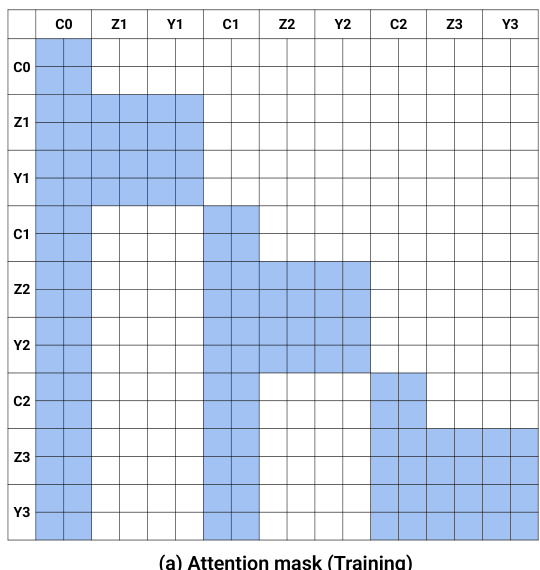
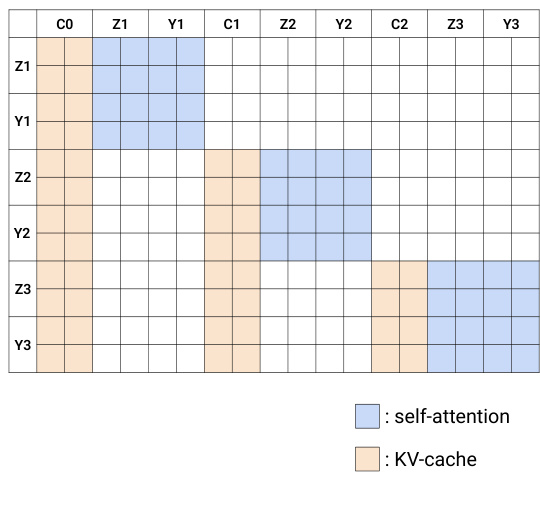
For inference, the system utilizes a closed-loop real-world execution strategy. Unlike bidirectional models that may suffer from modality misalignment or require video subsampling, the autoregressive design allows for precise alignment between video frames and robot actions. As shown in the timeline comparison, bidirectional approaches often introduce mismatches between video and action sampling points. In contrast, the autoregressive approach maintains a consistent video context. Furthermore, the system exploits the closed-loop nature of robotics: after an action chunk is executed, the predicted future frames are replaced with ground-truth observations in the KV cache. This eliminates compounding errors and enables efficient inference via KV caching.

To address the latency bottleneck of diffusion models, the authors introduce DREAMZero-Flash. This optimization decouples the noise schedules for video and action. Refer to the noise schedule graph which visualizes this decoupling. While standard training uses a shared uniform timestep, Flash biases video timesteps toward high-noise states using a Beta distribution while keeping action timesteps uniform. This trains the model to predict clean actions from noisy visual contexts, allowing for fewer diffusion steps during inference without degrading action quality. This results in significant speedups for real-time control.
Experiment
Experiments conducted on AgiBot and Franka robots validate that DREAMZero achieves superior zero-shot generalization to unseen tasks and environments compared to baseline vision-language-action models, especially when utilizing diverse training data. The joint video-action formulation enables robust cross-embodiment transfer and few-shot adaptation using only visual information, whereas baseline models often overfit to repetitive demonstrations. Furthermore, ablation studies indicate that autoregressive architectures and system optimizations preserve performance quality while enhancing temporal consistency and inference efficiency.
The the the table evaluates the impact of cross-embodiment transfer learning on task progress for unseen tasks using the DREAMZERO framework. It compares the baseline model against versions augmented with video data from human demonstrations and another robot embodiment, showing that both transfer methods significantly enhance performance. Both Human2Robot and Robot2Robot transfer strategies result in higher task progress compared to the baseline DREAMZERO model. Robot2Robot transfer achieves the highest performance, yielding the largest improvement over the baseline. Human2Robot transfer also demonstrates a substantial gain in task progress, validating the utility of human visual data despite the morphological differences.

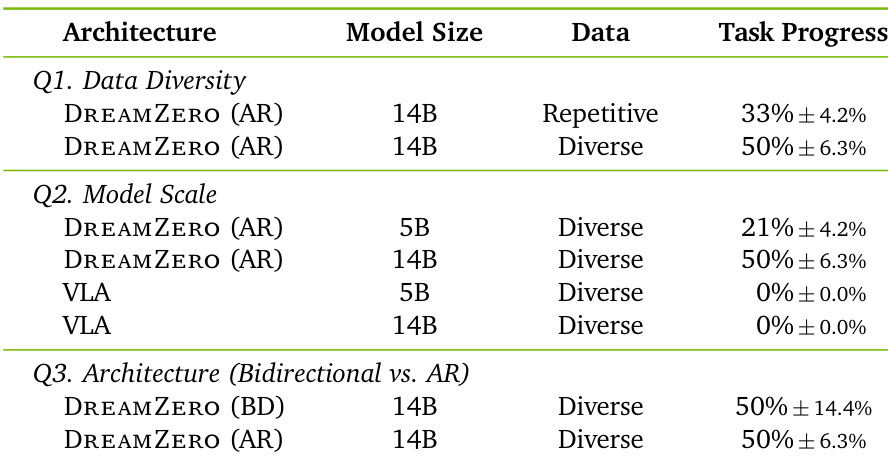
The authors evaluate the effects of data diversity, model scale, and architecture on task progress using DREAMZERO and VLA baselines. The results show that diverse data and larger model sizes significantly boost DREAMZERO performance, whereas VLAs fail to learn from diverse data regardless of scale. Additionally, bidirectional and autoregressive architectures yield comparable task progress scores. DREAMZERO achieves higher task progress when trained on diverse data compared to repetitive data. Larger DREAMZERO models outperform smaller ones, while VLAs show negligible progress across all sizes. Autoregressive and bidirectional architectures achieve similar task progress levels.
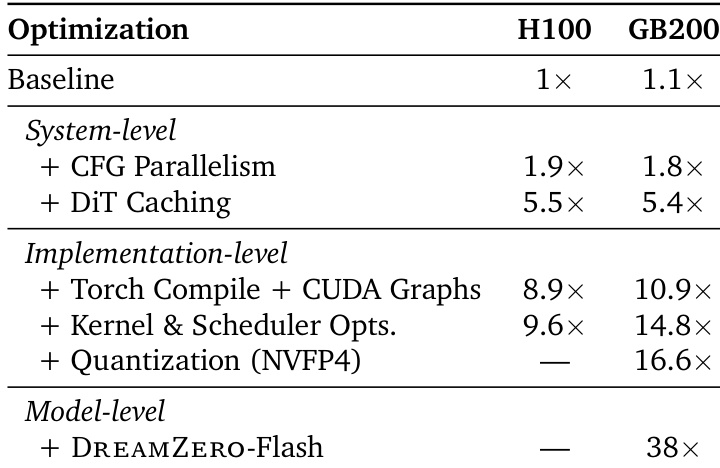
The the the table presents cumulative inference speedups achieved by stacking system, implementation, and model-level optimizations on H100 and GB200 hardware. Results indicate that system and implementation optimizations yield substantial gains, with the final model-level optimization providing a dramatic performance boost specifically on the GB200 architecture. Quantization and model-level techniques are shown to be applicable only to the GB200 hardware. System and implementation optimizations yield a cumulative speedup of approximately 9x on H100 and roughly 16x on GB200. The addition of DREAMZERO-Flash at the model level results in a 38x speedup on GB200 hardware. Quantization and the final model-level optimization are exclusive to the GB200 architecture in this evaluation.
The authors evaluate the trade-off between inference speed and task performance by reducing denoising steps. While the standard model suffers a significant accuracy drop with single-step inference, the DREAMZERO-Flash variant recovers most performance levels while maintaining the speed benefits. This indicates that the Flash variant offers a superior balance for real-time deployment scenarios. Reducing the standard model to a single denoising step causes a substantial decline in task progress. The Flash variant achieves significantly higher task progress at a single step compared to the standard single-step configuration. Single-step inference configurations provide a substantial speedup over the multi-step baseline.

The evaluation assesses the DREAMZERO framework across cross-embodiment transfer learning, data diversity, and inference efficiency to validate its generalization and speed capabilities. Experiments show that transfer strategies and diverse training data significantly improve task progress compared to VLA baselines, while larger scales further enhance performance across different architectures. Finally, cumulative optimizations achieve substantial inference speedups, where the DREAMZERO-Flash variant maintains high accuracy at single-step inference suitable for real-time applications.