Command Palette
Search for a command to run...
AutoResearch AI: نحو أتمتة البحث المدعومة بالذكاء الاصطناعي للاكتشاف العلمي
AutoResearch AI: نحو أتمتة البحث المدعومة بالذكاء الاصطناعي للاكتشاف العلمي
الملخص
تشكّل أنظمة الذكاء الاصطناعي تحولاً متزايداً في مسار البحث العلمي، إذ تنتقل من دور المساعدة المنعزلة إلى عمليات طويلة المدى تشمل توطيد النصوص الأدبية (literature grounding)، وتوليد الفرضيات، وإجراء التجارب، والتحقق منها، وإعداد التقارير، والمراجعة. ويشير هذا التحول إلى انتقال من مستوى «الذكاء الاصطناعي للمهام» في مجال العلم نحو «أتمتة سير العمل البحثي» على المستوى الوظيفي الشامل. ومع ذلك، لا يزال الحقل البحثي متشظياً؛ حيث تختلف الأنظمة الحالية بشكل جوهري من حيث درجة الاستقلالية، ونطاق المجال، وبيئة التنفيذ، وآليات التحقق، ومدى الاعتماد على الإشراف البشري. ورغم أن العديد من الأنظمة قادرة على توليد أفكار معقولة، وتشغيل الأدوات، وإجراء تجارب محدودة النطاق، أو إنتاج منتجات نهائية متميزة، إلا أنها لا تزال تواجه تحديات مستمرة تتعلق بالحفاظ على الأدلة، وإمكانية إعادة الإنتاج، ورفض المسارات الضعيفة، وتتبع الأصول (provenance tracking)، والقوة عبر المجالات (cross-domain robustness)، وإغلاق العملية العلمية بمساءلة واضحة (accountable scientific closure). وتستعرض هذه الدراسة الشاملة هذه التطورات من خلال منظور «البحث الآلي» (AutoResearch)، الذي نُعرّفه بأنه الطيف التطوري لأتمتة سير العمل العلمي المدعوم بالذكاء الاصطناعي. وفي إطار هذا الطيف، يُشار إلى «البحث النغمي» (Vibe Research) بأنه المنطقة الموجهة بشرياً، حيث يوسّع الذكاء الاصطناعي القدرة البحثية المحلية من خلال المساعدة القائمة على الـprompt وتنفيذ يتحقق منه البشر، بينما تبدأ الأنظمة الموجهة بالذكاء الاصطناعي الناشئة في تنسيق أجزاء أكبر من دورة الاكتشاف دون أن تحقق بعد درجة قوية من الاستقلالية.
One-sentence Summary
This survey examines AI-powered scientific workflow automation through the lens of AutoResearch, defining a developmental spectrum from human-steered Vibe Research to emerging AI-led systems while analyzing persistent challenges in evidence preservation and reproducibility to facilitate accountable scientific closure.
Key Contributions
- The survey defines AutoResearch as a developmental spectrum of AI-powered scientific workflow automation and specifies Vibe Research as the human-steered region where AI expands local capability through prompt-based assistance and human-verified execution.
- The survey organizes the field through a workflow-centered autonomy spectrum and examines systems such as The AI Scientist and Co-Scientist to demonstrate that the practical frontier remains concentrated in human-steered assistance.
- The survey analyzes domain-conditioned autonomy ceilings, showing that computational sciences offer favorable conditions for workflow closure whereas experimental fields impose stricter limits due to physical and safety constraints.
Introduction
Scientific research is transitioning from isolated AI assistance to workflow level automation where systems manage literature grounding, hypothesis generation, and experimentation. This shift matters because it expands AI participation across the entire discovery loop but introduces challenges in evidence preservation, reproducibility, and accountable scientific closure. Prior work often fragments the landscape by focusing on model architecture or task completion while overlooking the redistribution of control and validation authority. The authors define AutoResearch as a workflow level paradigm and introduce a five-level autonomy spectrum to distinguish human-steered assistance from AI-led coordination. They further organize technical foundations around five recurring workflow conditions and propose evaluation dimensions centered on scientific credibility such as novelty and provenance. Their analysis demonstrates that the practical ceiling for automation is strongly domain-conditioned, advancing faster in computational fields than in embodied or high-stakes scientific areas.
Dataset
-
Dataset Composition and Sources
- The authors curate a heterogeneous stack of evaluation instruments from the current AutoResearch landscape.
- Sources include DiscoveryBench, ResearchBench, MAgentBench, ScienceAgentBench, DeepScholar-Bench, and CiteME.
- The collection represents a fragmented set of resources rather than a unified benchmark regime.
-
Key Details for Each Subset
- Discovery benchmarks test structured search, decomposition, and frontier-facing ideation.
- Experimentation and verification benchmarks stress executable behavior, replication, and empirical discipline.
- Deep-research benchmarks evaluate long-horizon retrieval, report construction, and open-world information integration.
- Review and provenance instruments target claim support, citation traceability, and deployment documentation.
-
How the Paper Uses the Data
- The paper uses these resources to demonstrate a shift from task accuracy to workflow-specific scientific burden.
- Benchmarks serve as complementary constraints on AutoResearch behavior instead of substitutes for one another.
- Evaluation covers dimensions such as novelty, validity, reliability, and provenance across different workflow stages.
- No training splits or mixture ratios are defined as the focus remains on evaluation infrastructure.
-
Processing and Selection Details
- The authors retain resources whose primary contribution is a directly usable evaluation instrument for research agents.
- Benchmarks are grouped by evaluative role rather than by topic or domain.
- The selection process highlights methodological properties of AutoResearch evaluation regarding novelty and validity.
- Performance is treated as evidence for bounded capability rather than sufficient support for mature AI-led autonomy.
Method
The authors frame the technical foundations of AutoResearch not as a single monolithic model, but as a set of workflow conditions that constrain how scientific activity becomes grounded, executable, revisable, and communicable. The overall architecture is decomposed into five recurring stages that transform raw research inputs into communicable scientific artifacts. Refer to the framework diagram for the decomposition of AutoResearch into these five stages, from literature grounding to reporting.
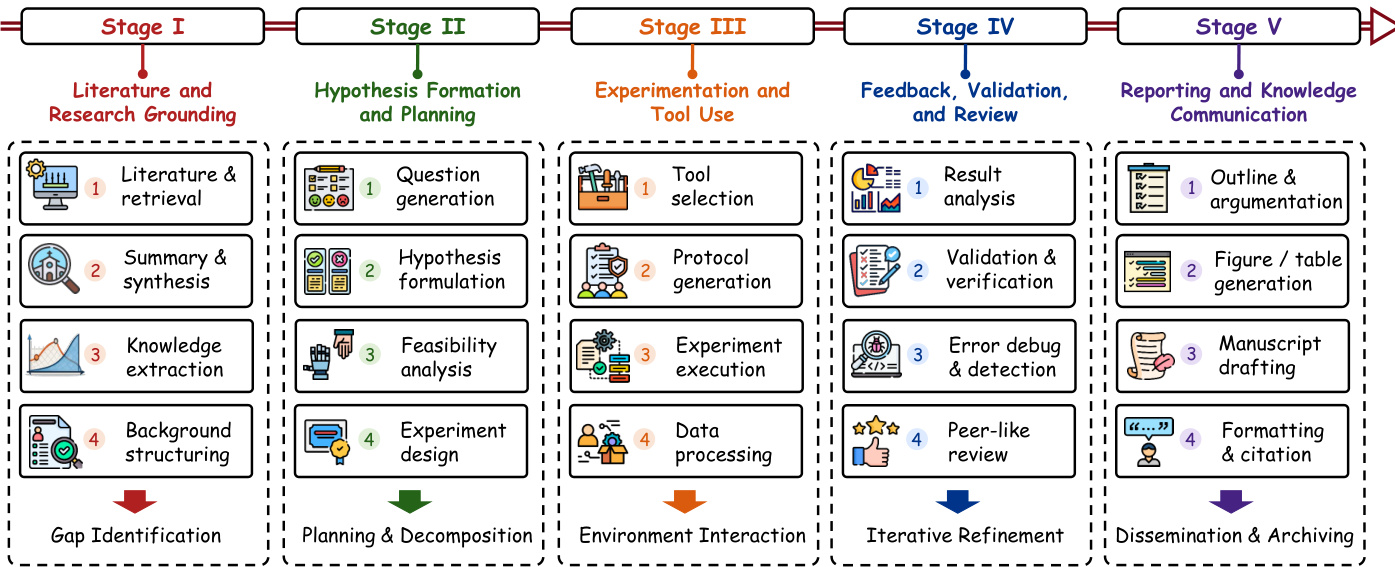
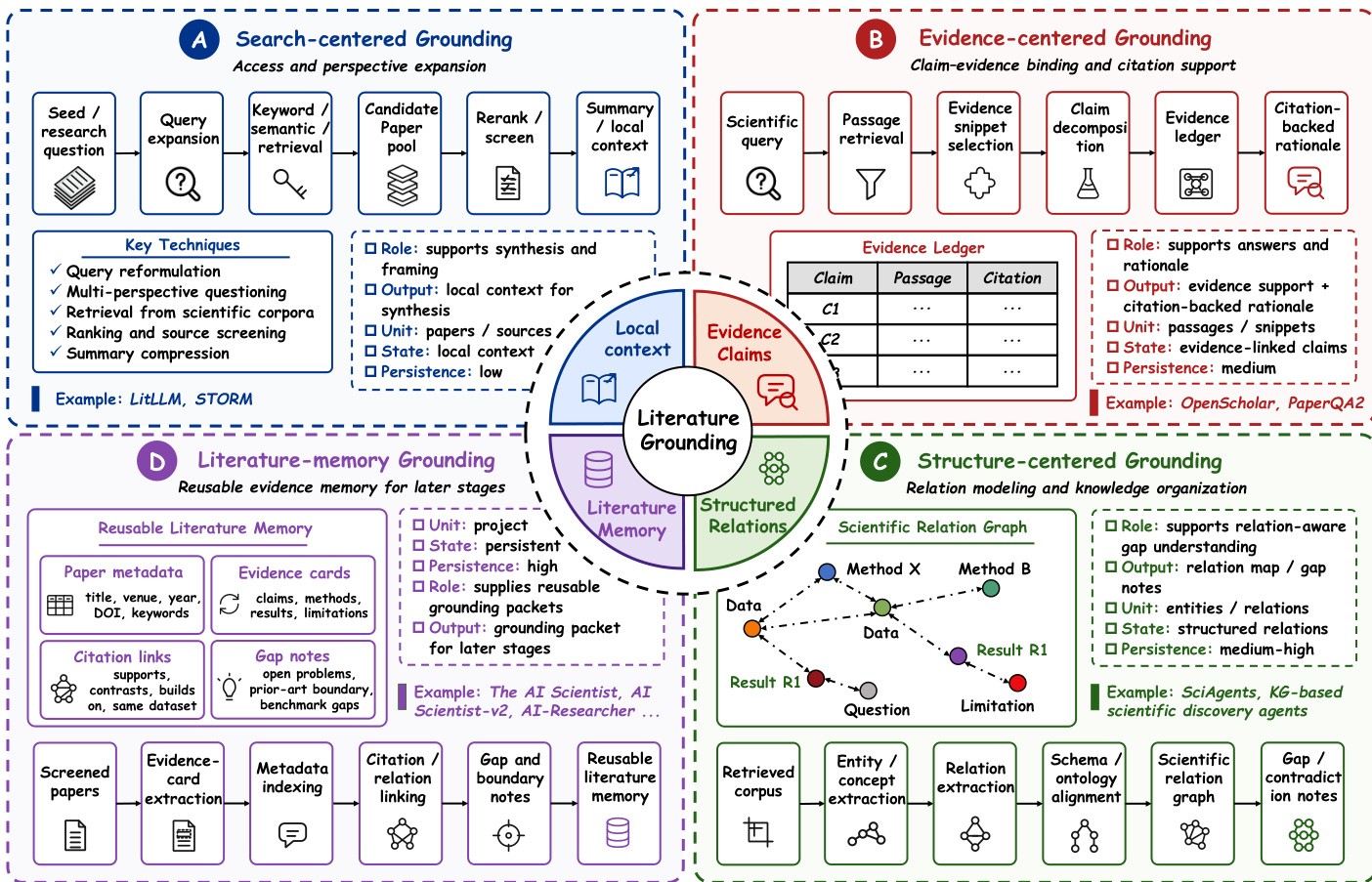
Stage I: Literature and Research Grounding Literature and research grounding is the first major technical stage because every later part of the workflow depends on how prior work is accessed, filtered, represented, and reused. This stage establishes the evidential basis on which hypotheses are proposed, experiments are designed, and results are interpreted. The central technical concern is not only whether a system can find relevant papers, but whether it can construct a scientific context that remains usable, inspectable, and updateable as the workflow evolves. Current grounding techniques are organized into four recurring regimes: search-centered, evidence-centered, structure-centered, and literature-memory grounding. These regimes differ in evidential strength, persistence, and workflow integration. Refer to the figure below for the comparison of these regimes as evidence-state construction.
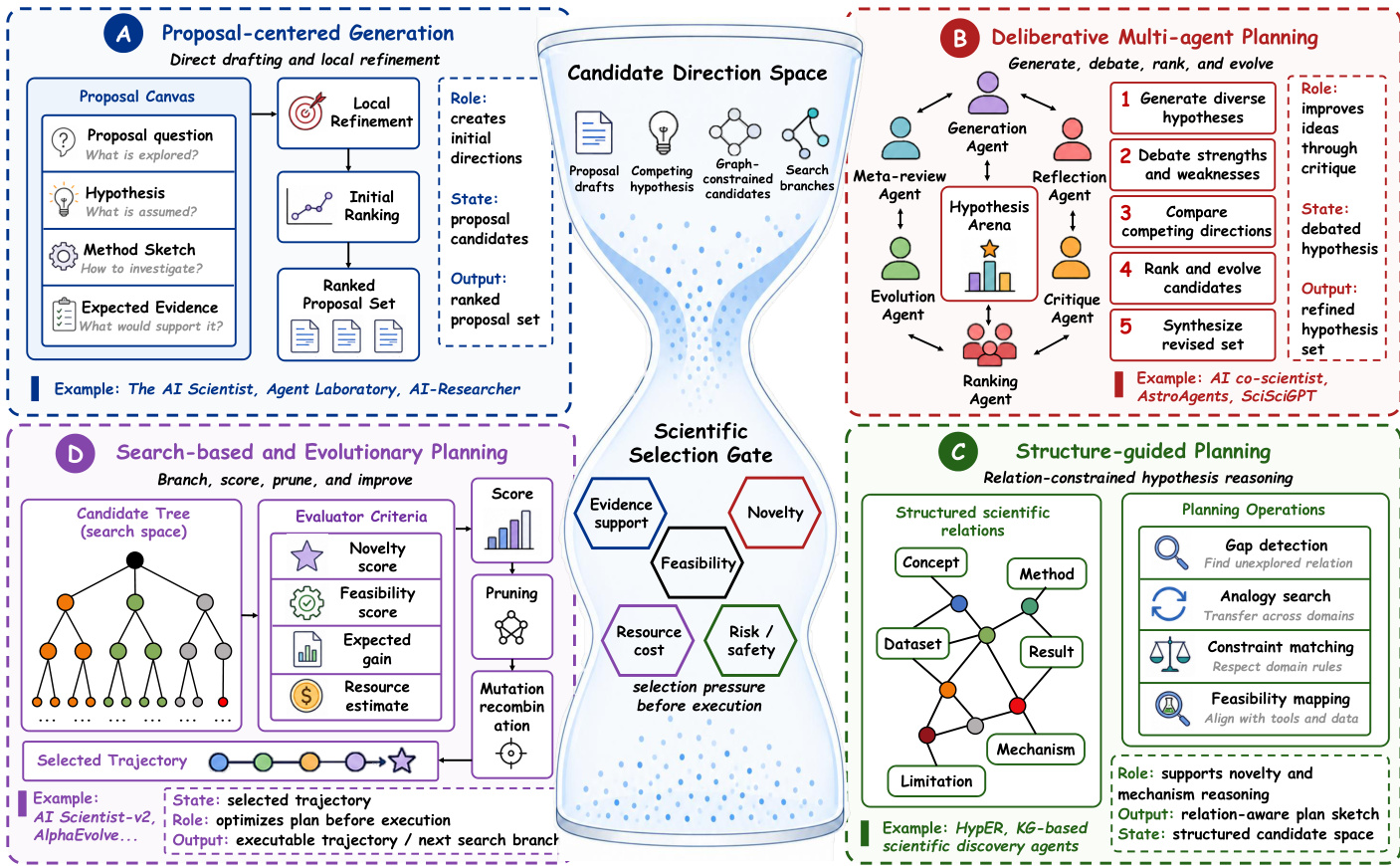
Stage II: Hypothesis Formation and Planning Hypothesis formation and planning constitute the second major technical stage, where grounded scientific context is converted into a candidate direction. If literature grounding determines what a system knows about prior work, this stage determines what the system is prepared to do with that knowledge. The technical goal is to transform grounded context into disciplined scientific direction so that later stages inherit candidate hypotheses and plans that are sufficiently grounded, comparable, and rejectable. Current hypothesis-formation techniques are organized into four recurring regimes: proposal-centered ideation, deliberative multi-agent ideation, structure-guided ideation, and search-based ideation and planning. Refer to the figure below for the comparison of these planning regimes.
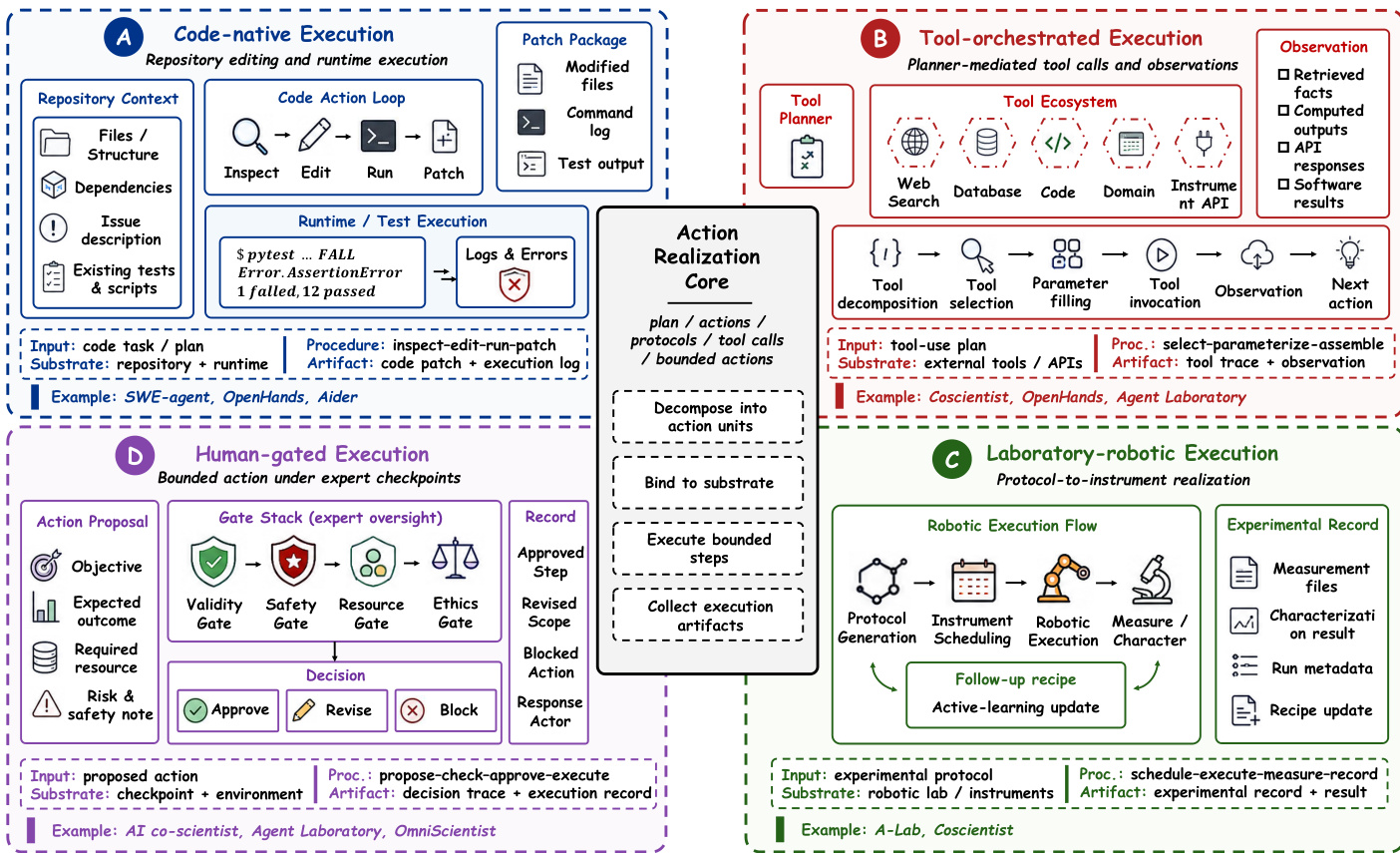
Stage III: Experimentation and Tool Use Experimentation and tool use constitute the third major technical stage because they determine how candidate scientific directions are translated into concrete actions. If grounding establishes the evidential basis and planning determines which directions are worth pursuing, execution determines whether those directions can be realized through code, tools, instruments, or protocols. This stage is not exhausted by generic tool calling but includes repository editing, code execution, simulator use, and scientific software invocation. Current execution techniques are organized into four recurring regimes: code-native, tool-orchestrated, laboratory-robotic, and human-gated execution. Refer to the figure below for the comparison of these action realization regimes.
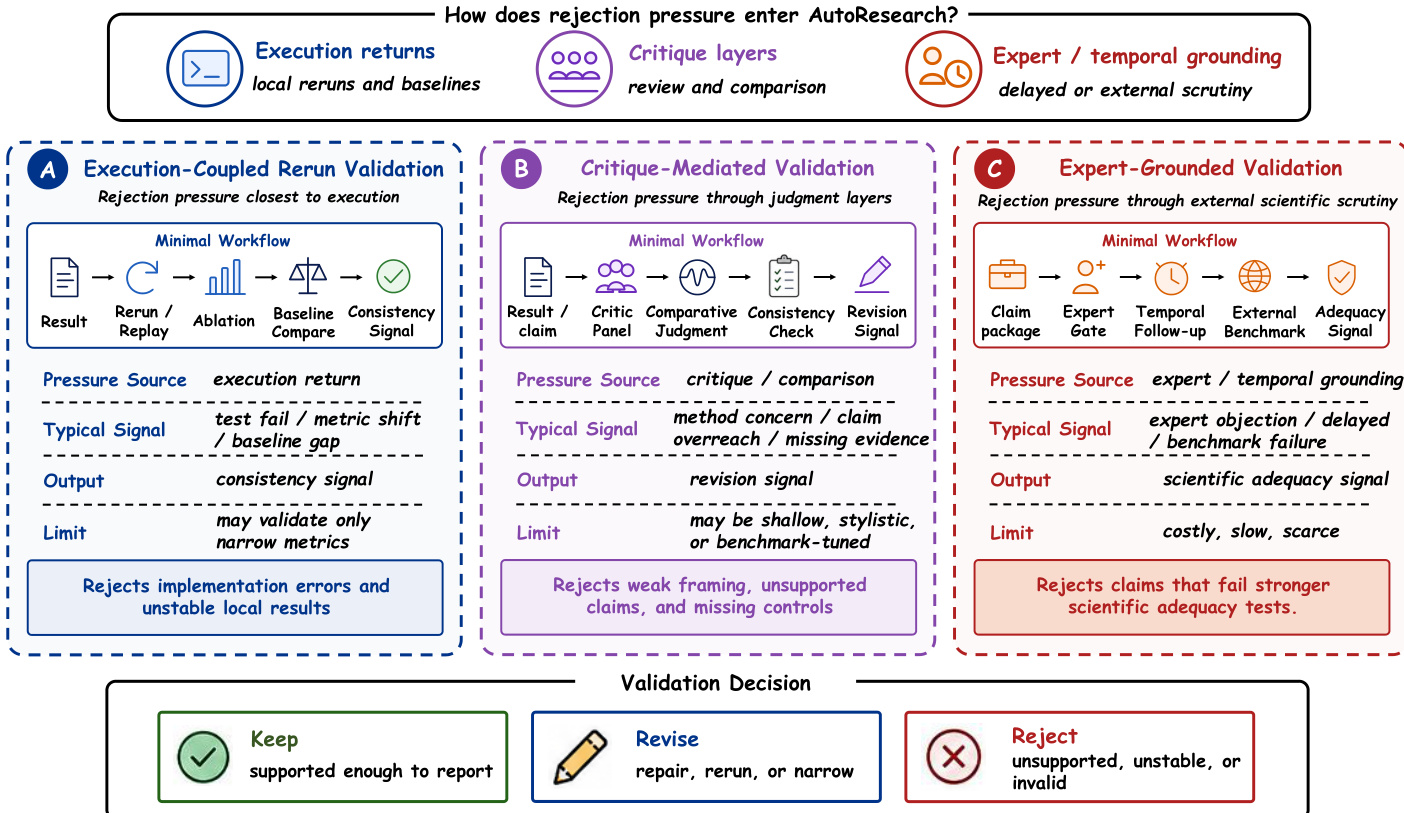
Stage IV: Feedback, Validation, and Review Feedback, validation, and review constitute the fourth major technical stage because they determine whether intermediate and final outputs are revised, rejected, or allowed to persist as candidate scientific claims. If execution exposes directions to operational or empirical resistance, validation determines whether the resulting outputs are subjected to sufficiently strong filtering to support credible scientific progress. This stage includes baseline comparison, rerun validation, error detection, and critical review. Current validation techniques are organized into three recurring regimes: execution-coupled rerun validation, critique-mediated validation, and expert- or temporally-grounded validation. Refer to the figure below for the comparison of these validation regimes.
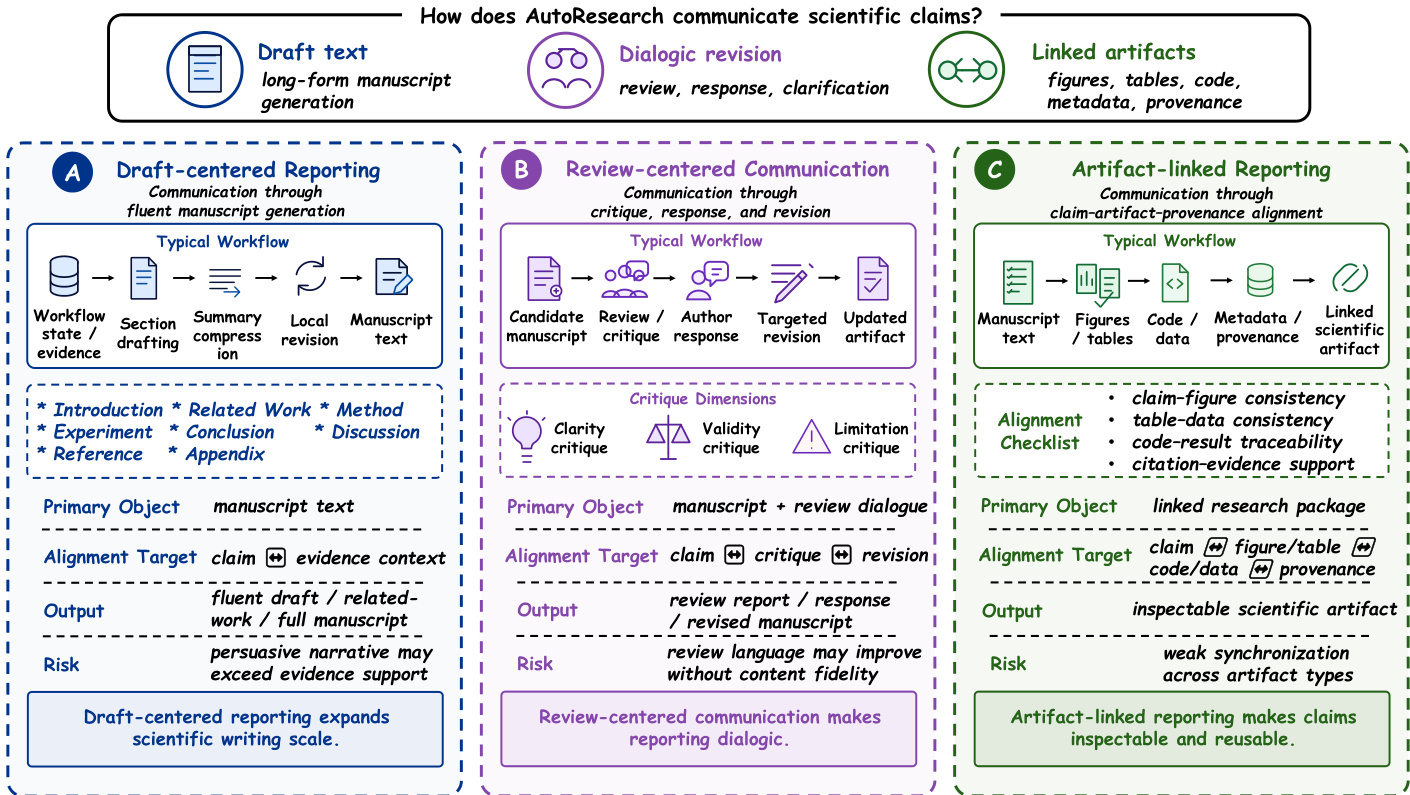
Stage V: Reporting and Knowledge Communication Reporting and knowledge communication constitute the fifth major technical stage because they determine how workflow state is translated into scientific artifacts that can be inspected, critiqued, and reused. If validation determines which outputs survive scrutiny, reporting determines how those filtered outputs are presented to scientific audiences. This stage includes drafting, revision, figure and table production, and the linking of claims to evidence, code, and provenance. Current reporting techniques are organized into three recurring regimes: draft-centered reporting, review-centered communication, and artifact-linked reporting. Refer to the figure below for the comparison of these communication regimes.
Experiment
Computational and formal sciences currently serve as the primary testbed for AutoResearch because their digital substrates enable rapid iteration and end-to-end workflows, whereas other domains like chemistry, biology, and social sciences support only narrow autonomy islands constrained by physical or interpretive factors. Current evaluation setups predominantly measure workflow execution and reliability rather than scientific value, leaving dimensions like novelty and long-term impact difficult to assess through short-horizon benchmarks. Consequently, existing systems validate their ability to operate within bounded experimental loops but remain limited in selecting consequential problems or establishing broad scientific closure without human oversight.