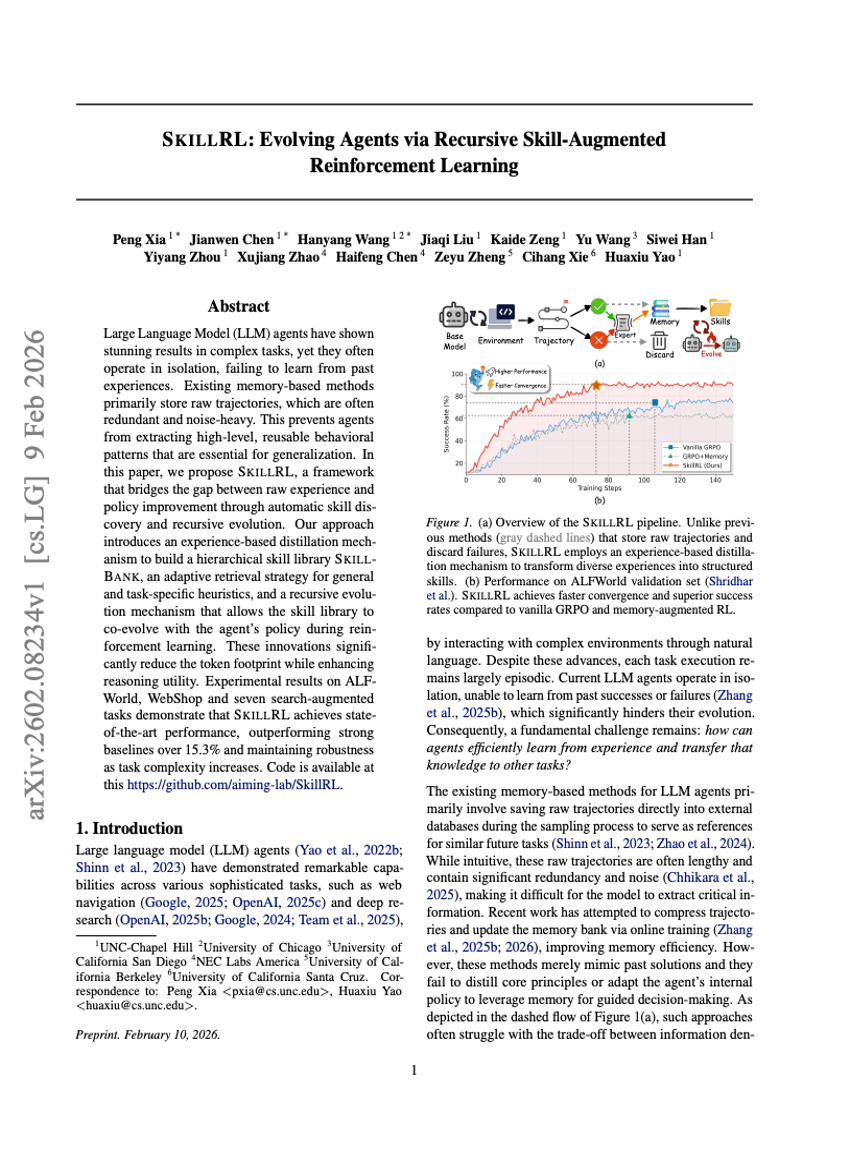
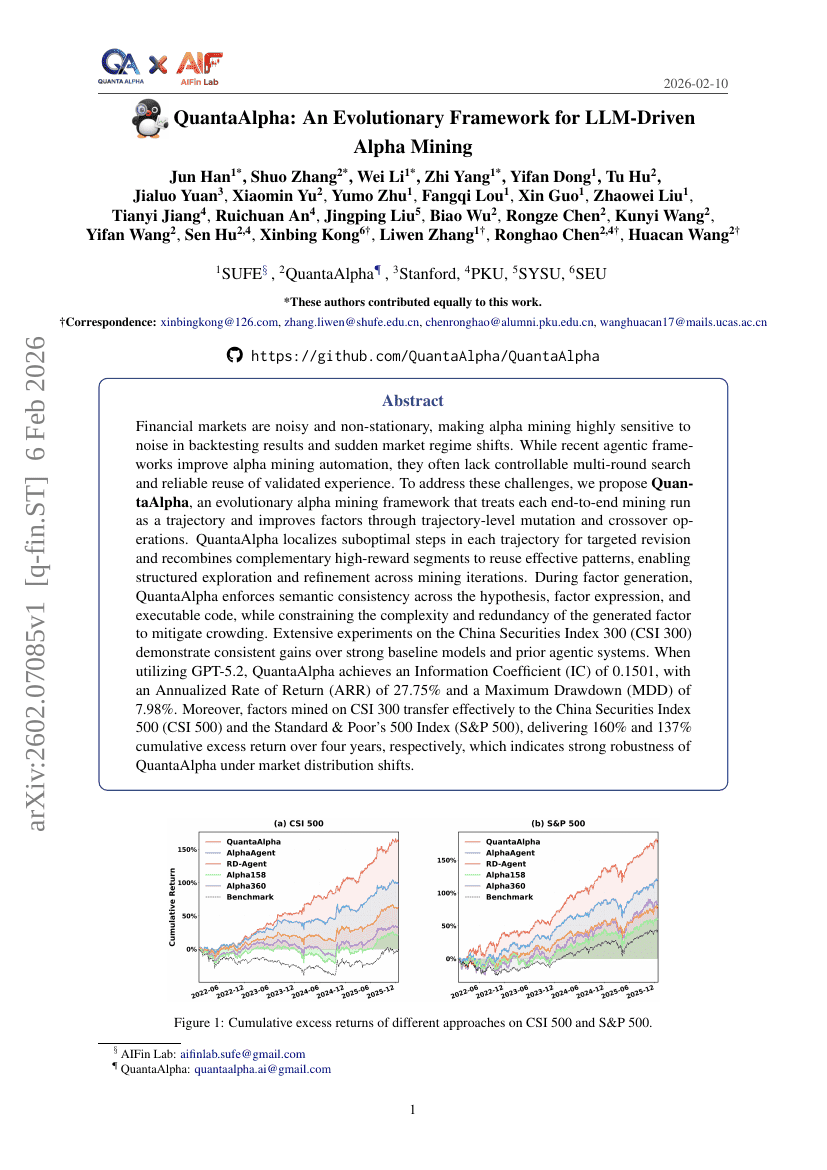
自律的な数学研究への道
LLMやAgent、tokenなどの技術の進展により、数学研究の自動化は現実のものとなりつつある。特に、大規模な言語モデル(LLM)は、数学的証明の探索、定理の発見、問題解決の戦略設計において、人間の研究者と協働する能力を備えている。これらのモデルは、数学的な記号や論理構造を理解し、複雑な推論を実行することで、新たな数学的知見を生成する可能性を秘めている。さらに、Agentアーキテクチャを用いることで、複数のLLMが協調して数学的課題に取り組むことが可能となり、長期的な研究プロセスの自律的進行が期待される。このように、LLMとAgentの統合は、数学研究の自動化を推進し、新たな発見の速度と範囲を飛躍的に拡大する可能性を示している。
Tony Feng, Trieu H. Trinh, Garrett Bingham, et al.