Command Palette
Search for a command to run...
EgoPush:モバイルロボット向けエゴセントリック多対象再配置のエンドツーエンド学習
EgoPush:モバイルロボット向けエゴセントリック多対象再配置のエンドツーエンド学習
Boyuan An Zhexiong Wang Yipeng Wang Jiaqi Li Sihang Li Jing Zhang Chen Feng
概要
人間は、自己中心的視覚(egocentric perception)を用いて、混雑した環境中の物体を再配置し、グローバル座標に依存せずに遮蔽物を回避して移動できる。この能力に着想を得て、単一の自己中心カメラを用いた移動型ロボットによる、長期間にわたる複数物体の非把持的再配置(non-prehensile rearrangement)を研究する。本研究では、明示的なグローバル状態推定に依存せず、自己中心的で視覚駆動型の再配置を実現するポリシー学習フレームワーク「EgoPush」を提案する。EgoPushは、物体の絶対的な姿勢ではなく、物体間の相対的な空間関係を表現する物体中心の潜在空間(object-centric latent space)を設計している。この設計により、視覚的にアクセス可能なキーポイントから、偏見のある強化学習(RL)の教師モデルが潜在状態と移動行動を同時に学習でき、その知識は視覚のみに依存する学生ポリシーに蒸留(distillation)される。教師モデルの観測を視覚的に確認可能な情報に制限することで、教師と部分的に観測可能な学生との間の監督ギャップを低減し、学生の視点からも再構成可能な能動的視覚行動(active perception behaviors)を促進する。また、長期間にわたる報酬割り当て(credit assignment)の課題に対処するため、時間的に減衰する段階固有の完了報酬(stage-local completion rewards)を用いて、再配置タスクを段階レベルの部分問題に分解する。広範なシミュレーション実験により、EgoPushはエンドツーエンドの強化学習ベースラインと比較して、成功確率において顕著な優位性を示した。アブレーションスタディにより、各設計選択の有効性が検証された。さらに、実世界の移動型プラットフォーム上で、ゼロショットのシミュレーションから実世界への転送(sim-to-real transfer)を実証した。コードと動画は、https://ai4ce.github.io/EgoPush/ にて公開されている。
One-sentence Summary
Researchers from New York University propose EgoPush, a teacher-student framework enabling mobile robots to rearrange multiple objects using only egocentric vision, by learning object-centric latent representations and distilling constrained teacher policies that ensure visually recoverable behaviors, achieving robust sim-to-real transfer on a TurtleBot.
Key Contributions
- EgoPush enables mobile robots to perform long-horizon multi-object rearrangement using only egocentric vision by learning object-centric latent representations that encode relative spatial relations, eliminating reliance on fragile global state estimation in texture-sparse, occlusion-prone environments.
- The framework introduces a constrained teacher RL approach that restricts the privileged teacher to egocentric observations, ensuring its behavior is recoverable by the visual student and promoting active perception strategies that align with real-world partial observability.
- EgoPush improves long-horizon credit assignment through stage-wise training with temporally decayed rewards, achieving higher success rates than end-to-end RL baselines in simulation and demonstrating zero-shot sim-to-real transfer on a Turtlebot platform.
Introduction
The authors leverage egocentric vision to enable mobile robots to perform long-horizon multi-object rearrangement without global state estimation—a capability critical for real-world deployment where occlusions and sparse textures make traditional mapping unreliable. Prior methods either rely on brittle global state estimators or suffer from poor sample efficiency and instability under partial observability when using end-to-end visual RL. EgoPush addresses these gaps by introducing an object-centric latent space that encodes relative spatial relations, a constrained teacher policy that only uses egocentric observations to ensure distillable behavior, and stage-wise training with temporally decayed rewards to improve long-horizon credit assignment. This framework enables robust sim-to-real transfer and outperforms baselines in both success rate and sample efficiency.
Dataset
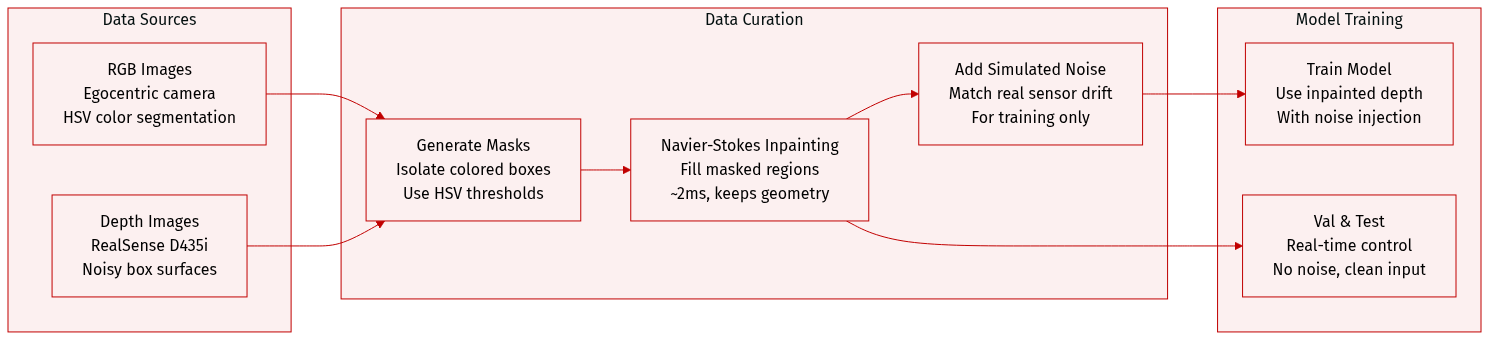
The authors use a custom dataset collected in a 3m × 3m gray arena with five color-coded boxes (red, green, blue, violet, brown) to train and evaluate their egocentric robot manipulation system. Here’s how the data is composed and processed:
-
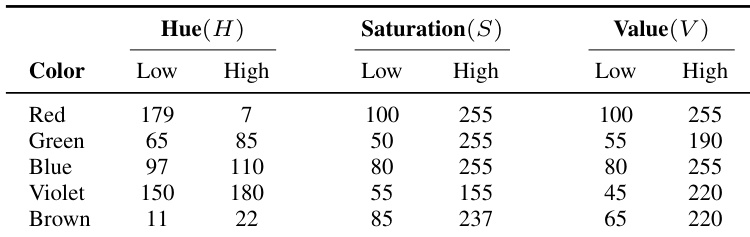
RGB Images: Captured from the robot’s egocentric camera. The server applies HSV-based color segmentation to isolate each box from the background, generating binary masks. Specific HSV thresholds for each color are defined in Table VI.
-
Depth Images: Raw depth data from an Intel RealSense D435i is heavily noisy, especially on box top surfaces. The authors tested four postprocessing methods:
- Learning-based denoising (CDM): High-quality reconstruction but too slow (~50ms/frame), unsuitable for real-time control.
- Onboard filtering: Applied hole-filling and temporal/spatial filters on Jetson Nano; causes flickering and dropouts, with ~15ms latency.
- Median-depth filling (baseline): Replaces masked regions with median depth value; stable and fast (~2ms), but loses geometric detail.
- Navier-Stokes inpainting (final choice): Inpaints masked regions using fluid dynamics; retains more geometry than median-fill, more stable than onboard filtering, and runs at ~2ms. Used during training with injected noise to simulate real-world conditions.
-
Data Usage: The system uses the RGB masks to filter depth images, and the Navier-Stokes inpainted depth maps are fed into the model during training and real-time control. This strategy balances geometric fidelity, stability, and low latency, enabling effective sim-to-real transfer.
Method
The authors leverage a two-phase distillation framework called EgoPush, designed for long-horizon, multi-object non-prehensile rearrangement under egocentric visual constraints. The framework decouples learning into a privileged teacher phase and a vision-based student phase, enabling zero-shot sim-to-real transfer. The overall architecture is structured to ensure that the student policy, trained solely on egocentric RGB-D inputs, can replicate the teacher’s behavior while operating under perceptual constraints that mirror real-world sensor limitations.
In Phase 1, the teacher policy is trained via online reinforcement learning using sparse, privileged 3D keypoints that encode object geometry and relative poses. These keypoints are grouped into four semantic categories: active object, anchor, obstacles, and reference target. To ensure the teacher’s behavior remains visually recoverable by the student, the authors impose two critical constraints on the teacher’s observation space: virtual egocentric field-of-view (FOV) masking and center-gated visibility for the reference target. The FOV mask restricts observations to points within a robot-pose-based frustum and within a maximum range, approximating camera visibility. The center-gated visibility condition ensures the reference target keypoints are only revealed when the anchor object lies within the central region of the virtual FOV, preventing the teacher from exploiting the target without attending to the anchor. As shown in the figure below, this constrained observation space forces the teacher to rely on task-relevant, recoverable cues.
The teacher’s state estimator is implemented as a PointNet, which processes variable-sized point sets per semantic group and produces group-wise latent embeddings Ztk via shared-weight MLPs and symmetric pooling. These latents, concatenated with the previous action at−1, are fed into an MLP policy head to output a 2D continuous action at=[vt,ωt], corresponding to linear and angular velocities of the differential-drive base. The reward function is designed to facilitate long-horizon learning through stage-aligned supervision: it includes time-weighted completion rewards for reaching and placing the active object, progress shaping via phase-gated distance decrease, smoothness penalties to discourage abrupt actions, and slowdown rewards near the target to encourage stable settling. The teacher is trained using Proximal Policy Optimization (PPO) with domain randomization applied to physical parameters.
In Phase 2, the student policy is distilled from the teacher via supervised learning using only egocentric RGB-D observations. The RGB stream is used solely for instance segmentation to assign objects to semantic groups (active, anchor, obstacle), while the depth map is masked and aggregated per group to produce fixed-dimensional depth layers d~tk. These depth layers serve as input to a CNN-based state estimator, which replaces the teacher’s PointNet. The student’s policy head architecture remains identical to the teacher’s MLP, and its weights are initialized from the teacher’s learned parameters to accelerate convergence. The student is trained using an online DAgger-style procedure: at each iteration, the teacher is queried online to generate action labels for the current state, and the student performs a supervised update. To bridge the representation gap between the teacher’s privileged latent space and the student’s visual inputs, the authors introduce a relational distillation loss. This loss minimizes the Frobenius norm between the pairwise cosine similarity matrices of the shared semantic group latents (active, anchor, obstacle) from teacher and student, encouraging the student to replicate the teacher’s perception of spatial relationships without requiring explicit access to the reference target. As shown in the framework diagram, this relational alignment enables the student to implicitly encode target-seeking behavior.
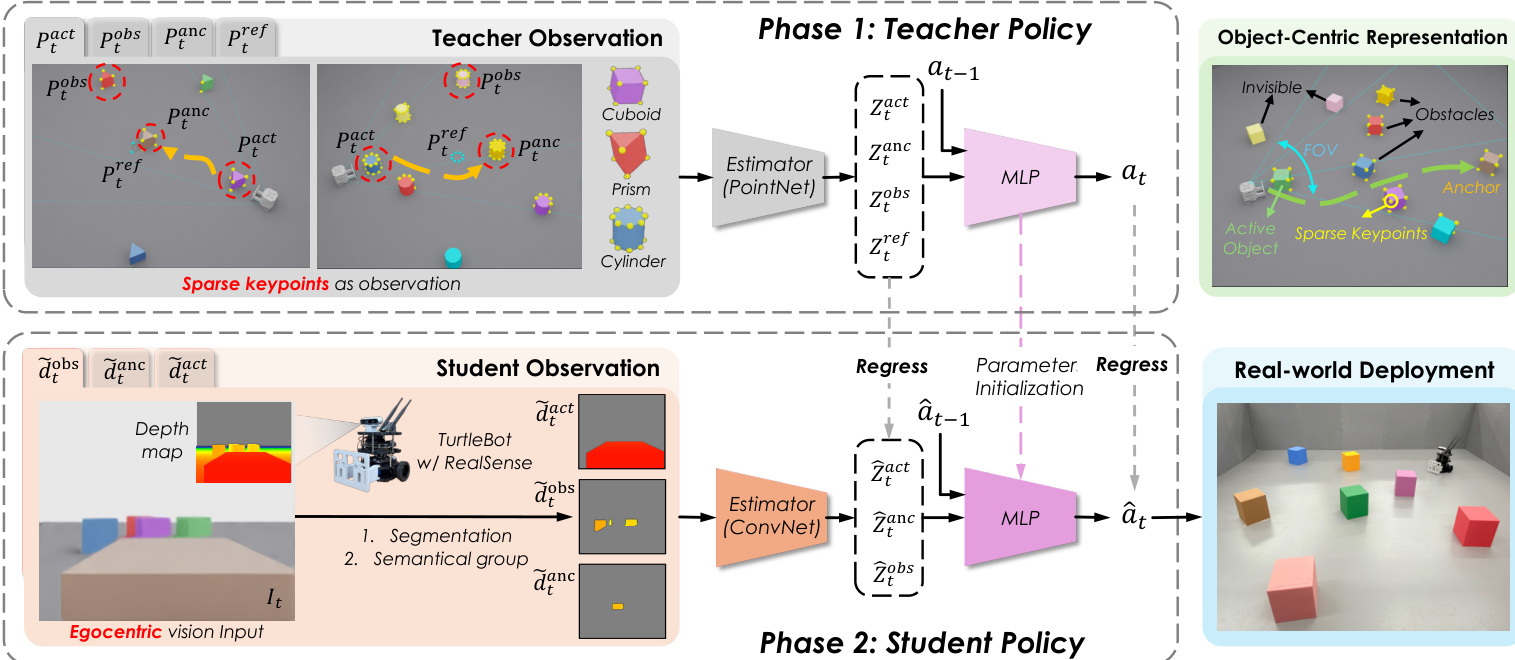
For real-world deployment, the student policy operates on RGB-D inputs from a RealSense camera mounted on a TurtleBot equipped with a front pusher. The pusher mitigates the depth camera’s sensing dead zone but introduces dynamical challenges due to an extended moment arm, which the learned policy compensates for through adaptive control. Domain randomization is further applied to camera-pose-related observations during distillation to enhance robustness. The student’s ability to generalize to real-world conditions without fine-tuning is enabled by the structured distillation process and the alignment of perceptual constraints between simulation and reality.
Experiment
- EgoPush successfully performs multi-object rearrangement with diverse object geometries in both simulation and real-world settings, achieving high precision in target formations.
- Constraining the RL teacher’s observation space improves student learning by aligning supervision with the student’s partial observability, leading to significantly better performance than unrestricted teacher variants.
- Decomposing long-horizon tasks into sequential sub-tasks with stage-level time-decayed rewards accelerates RL convergence and enhances credit assignment, enabling stable and efficient learning.
- Adding a relational distillation loss helps the student inherit the teacher’s spatial reasoning, proving critical for complex, asymmetric tasks where geometric consistency matters.
- Baseline methods—including end-to-end visual RL and classical mapping approaches—fail to solve the task reliably due to poor long-horizon reasoning, partial observability, and drift-induced state inconsistency.
- Real-world deployment demonstrates zero-shot transfer success, achieving 80% success rate with minor deviations, though torque limits reduce robustness compared to simulation.
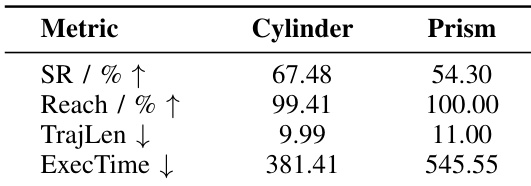
- The student policy generalizes to novel object shapes (cylinder, prism) in terms of reaching, but struggles with final alignment due to geometry-dependent contact dynamics.
- Accuracy evaluation on cuboids shows the student achieves ~86.7% normalized accuracy, confirming precise final positioning relative to invisible targets.
The authors use a simplified two-object pushing task to compare EgoPush against classical and end-to-end visual RL baselines, all operating under egocentric RGB-D sensing. Results show that while baselines achieve limited object reach rates, none succeed in completing the full push-and-align task, whereas EgoPush achieves perfect success and reach rates with efficient trajectories. This highlights that structured distillation and spatial reasoning are critical for solving long-horizon rearrangement under partial observability.
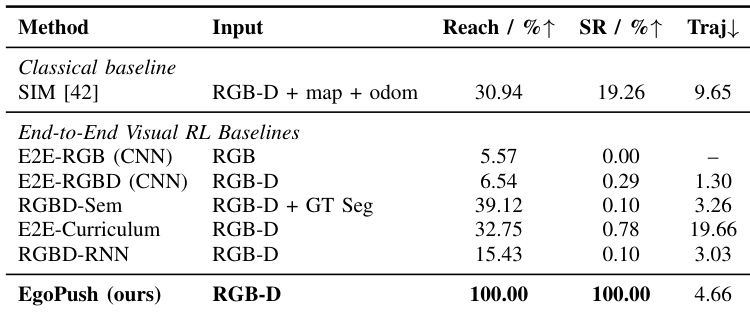
The authors use a progressive reward shaping approach to decompose long-horizon tasks, showing that adding stage-wise rewards and temporal decay significantly improves learning efficiency. Their final method, which resets the decay schedule at each stage boundary, achieves near-saturated performance with faster convergence and lower execution time compared to ablated variants. Results confirm that structured credit assignment is critical for solving complex sequential rearrangement under sparse feedback.
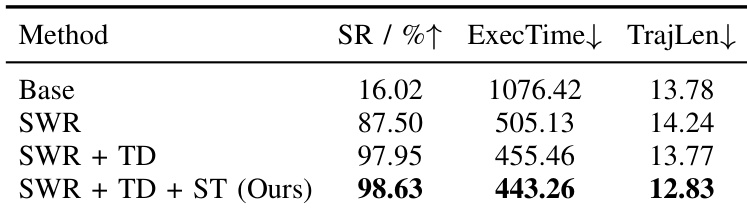
The authors use restricted observation spaces for the RL teacher to align with the student’s partial observability, which significantly improves student performance despite slightly reducing teacher efficiency. Results show that removing center-gated visibility or global FOV constraints leads to poor student success rates, highlighting the importance of observation design for effective distillation. The student trained under the full method achieves 70.7% success, while variants without key constraints fail to generalize or learn meaningful behaviors.

The authors use HSV threshold ranges to segment colored boxes in real-world experiments, with hue values adjusted to account for circular color space boundaries, particularly for red. These ranges are designed to ensure consistent object detection under varying lighting and camera conditions. The selected thresholds reflect empirical tuning to balance precision and recall across multiple object colors.
The authors evaluate their student policy on objects with non-cuboid geometries and find that while the model reliably reaches the target object, success rates drop significantly for cylinders and prisms due to challenges in maintaining stable contact and precise alignment during pushing. Execution time and trajectory length increase for prisms, indicating that geometric complexity amplifies control errors over long-horizon interactions. Results suggest the policy’s perception and approach skills generalize well, but fine-grained manipulation remains sensitive to object shape.