Command Palette
Search for a command to run...
ResearchGym:現実世界のAI研究における言語モデルエージェントの評価
ResearchGym:現実世界のAI研究における言語モデルエージェントの評価
Aniketh Garikaparthi Manasi Patwardhan Arman Cohan
概要
我々は、エンドツーエンドの研究におけるAIエージェントの評価を目的としたベンチマークおよび実行環境「ResearchGym」を紹介する。本研究では、ICML、ICLR、ACLの論文5本(口頭発表およびスポットライト発表)を再利用してこの環境を構築した。各論文のリポジトリから、データセット、評価ハーネス、ベースライン実装を保持しつつ、論文で提案された手法は非公開とする。これにより、合計39のサブタスクを含む5つのコンテナ化されたタスク環境が得られる。各環境において、エージェントは新たな仮説を提示し、実験を実行し、論文で定義された指標において強力な人間ベースラインを上回ることを目指す。GPT-5を搭載したエージェントを制御された条件下で評価した結果、能力と信頼性の間には顕著なギャップが見られた。エージェントは、リポジトリに提供されたベースラインに対して、15回の評価のうちわずか1回(6.7%)で11.5%の改善を達成し、平均してサブタスクの26.5%しか完了できなかった。本研究では、反復的な長期間失敗モードを特定した。具体的には、焦り、時間およびリソース管理の不備、弱い仮説に対する過度な自信、並列実験の調整困難、コンテキスト長の上限による制約などが挙げられる。しかし、1回の実行において、ICML 2025のスパロットタスクの解決策を上回る成果を達成した例も確認され、最先端のエージェントが偶発的に最先端の性能に到達可能であることを示唆しているものの、その結果は信頼性に欠けることが明らかになった。さらに、Claude Code(Opus-4.5)およびCodex(GPT-5.2)といったプロプライエタリなエージェントスキャフォールドについても評価を行ったが、同様の能力と信頼性のギャップが確認された。ResearchGymは、クローズドループの研究における自律型エージェントの体系的評価と分析を可能にするインフラを提供する。
One-sentence Summary
Researchers from TCS Research and Yale University introduce ResearchGym, a benchmark testing AI agents on end-to-end research tasks by withholding proposed methods from real papers; despite occasional SOTA-level results, agents like GPT-5 show unreliable performance due to planning and context limits, highlighting critical gaps in autonomous research capability.
Key Contributions
- ResearchGym introduces a reproducible, execution-based benchmark for end-to-end AI research, using five recent ICML/ICLR/ACL papers with withheld methods, objective evaluation scripts, and human baselines to measure agent performance across 39 sub-tasks on a single GPU.
- A GPT-5-powered agent exhibits a sharp capability–reliability gap, improving over baselines in only 1 of 15 runs (6.7%) and completing just 26.5% of sub-tasks on average, while revealing failure modes like poor resource management and context-length limits.
- Despite low reliability, the agent occasionally surpasses human expert solutions—such as on an ICML 2025 Spotlight task—indicating frontier models can reach state-of-the-art performance sporadically, a pattern also observed in Claude Code and Codex agents.
Introduction
The authors leverage ResearchGym, a new benchmark and execution environment, to evaluate AI agents on full-cycle research tasks—proposing hypotheses, running experiments, and improving upon human baselines—using real-world codebases from recent ICML, ICLR, and ACL papers. Prior benchmarks either focus on fragmented stages of research, rely on unreliable LLM judges, require impractical compute, or lack human-calibrated performance targets, making it hard to assess true autonomous research capability. Their main contribution is a reproducible, single-GPU-compatible framework with 39 sub-tasks across five domains, where agents are scored objectively against published human solutions. Evaluations reveal a sharp capability-reliability gap: even frontier agents like GPT-5 improve baselines in only 6.7% of runs and complete just 26.5% of sub-tasks on average, though one run did surpass a human solution—highlighting sporadic SOTA performance but systemic unreliability.
Dataset

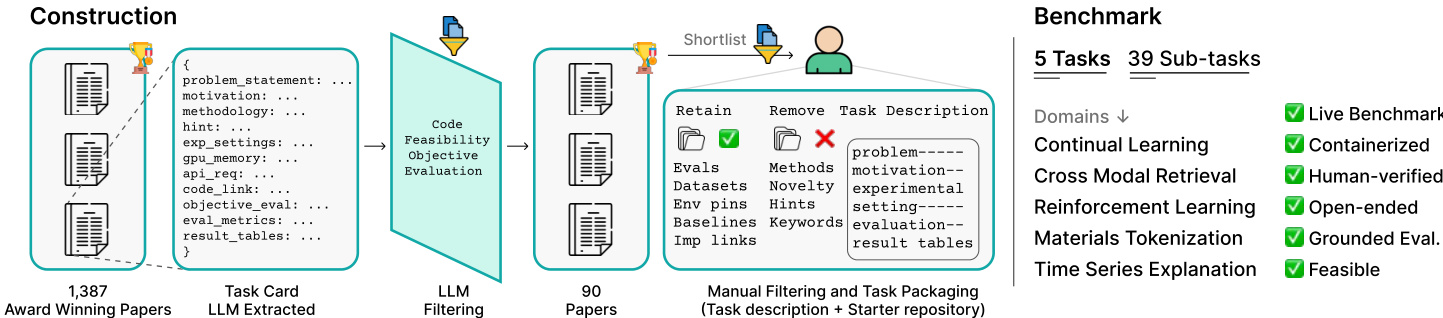
The authors construct ResearchGym, a benchmark of 5 curated research tasks (plus 3 development tasks) drawn from award-winning 2025 papers at ICLR, ICML, CVPR, and ACL — selected to avoid contamination with frontier LLMs’ knowledge cutoffs (Sept 2024). The dataset is built via a three-stage pipeline:
-
Stage 1: Automated Filtering
They extract 1,387 candidate papers, convert PDFs to Markdown via GROBID, then use GPT-5 to generate structured task cards. Filters remove non-empirical papers, those without public code/datasets, and those requiring >24GB GPU or impractical runtime. This yields 90 shortlisted papers. -
Stage 2: Human Curation
Human reviewers assess feasibility, objectivity, diversity, and room for algorithmic creativity. Final selection: 5 test tasks (39 sub-tasks) and 3 dev tasks — each representing distinct domains and experimental settings (e.g., RL environments, classification/generation tasks). -
Stage 3: Task Packaging
For each paper, they build a “skeleton” repo that removes the original method but retains datasets, evaluation scripts, pinned environments, and grading tools. Each task includes:- A task description (task_description.md) with goal, constraints, and blank results table.
- A grading script (grade.sh) for reproducible, automated scoring per sub-task.
- A virtual environment (or Docker image) with preinstalled dependencies to avoid version conflicts.
- Primary/secondary sub-tasks to enable prioritized, comparable evaluation.
Metadata includes GPU requirements, citations, GitHub stars, and arXiv dates (as of Oct 2025). The authors manually verify neutrality (no method leakage), completeness (all dependencies provided), and fidelity (reproducing original results). Dev tasks are used to tune agent scaffolding (prompting, context summarization, time limits). Web search is restricted to pre-2025 content via EXA API with URL blocking. Logging includes full message traces (.json), compressed evals (.eval), and state tracking (metadata.json, status.json, plan.json) for debugging and cheating detection.
Method
The authors leverage a structured, gym-style framework called ResearchGym to evaluate research agents in closed-loop scientific discovery tasks. The system is designed to enforce objective, contamination-aware, and reproducible evaluation while supporting flexible agent architectures. The overall workflow is divided into three conceptual phases: ideation, experimentation, and iterative refinement — each supported by modular components that interface through standardized abstractions.
Refer to the framework diagram, which illustrates the end-to-end loop: an LLM agent operates within a sandboxed environment, iteratively proposing hypotheses, implementing code, running experiments, and receiving objective feedback via a grader. The agent’s actions — such as editing files, invoking APIs, or executing shell scripts — are logged alongside system observations, enabling post-hoc analysis and live tracing. The agent is provisioned with a Git-initialized workspace and encouraged to commit progress periodically. A key design principle is the separation of concerns: the framework standardizes task definition, environment setup, and evaluation, while remaining agnostic to the agent’s internal architecture. This allows integration of diverse solvers — from ReAct-style loops to tree-search controllers — as long as they respect budget constraints and integrity rules.
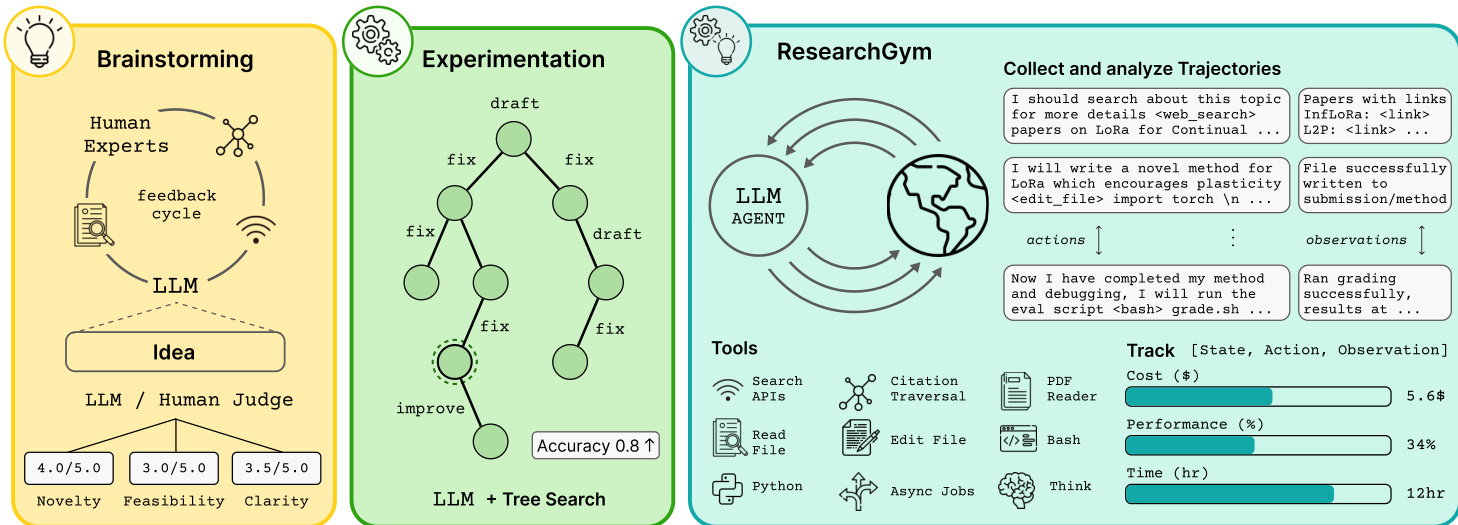
The task abstraction is central to the system. Each task instance I=(R,T,g) comprises a starter repository R, a task description T specifying goals and constraints, and a grader g that evaluates workspace state s^ and returns objective scores v^=g(s^). Tasks are composed of multiple sub-tasks, with one designated as primary; agents are incentivized to optimize the primary score vp. For example, in materials tokenization, the task includes 12 sub-tasks such as Named Entity Recognition, with the grader computing F1 scores and enforcing a 12-hour, $10 API budget.
To ensure reproducibility and isolate agent capability from environmental noise, all runs execute inside a sandboxed container based on a standardized research-gym image. The environment is dynamically configured at runtime, activating virtual environments and installing dependencies system-awarely (GPU/CPU, Linux/Windows). This mitigates dependency drift and ensures consistent starting conditions.
Evaluation is grounded in the original paper’s metrics, with each task shipping a grader that replicates the source evaluation protocol. To prevent reward hacking — such as tampering with grading scripts or leaking data — the framework deploys an INSPECTION-AGENT, a ReAct-style auditor built on Inspect, which reviews logs and file modifications post-run. It flags anomalies like unauthorized code edits or suspiciously perfect metric patterns, validated through injected adversarial behaviors during development.
The agent scaffold, RG-AGENT, is built on the Inspect framework and follows a ReAct-style tool-use loop. It is instructed to “propose and test novel scientific ideas” and to “keep working until the time limit expires,” discouraging premature termination. The agent has access to a curated set of tools including Search APIs, Python execution, file editing, citation traversal, and async job management — as shown in the tools table. These tools are designed to empower the agent without over-specializing for any single task.
For long-running sessions (12–24 hours), the system implements context window summarization: when token count approaches 140K, the agent writes a summary, the conversation is cleared, and a bridge prompt reintroduces the task and prior summaries. Resume capability is critical for handling interruptions; for RG-AGENT, the full transcript is persisted after each turn and reconstructed on restart, with incomplete tool calls pruned to avoid confusion. For Claude Code and Codex, custom resume strategies are implemented to handle SDK limitations, including transcript seeding and thread ID monitoring to prevent silent context loss.
Live observability is enabled via Langfuse integration, which transparently captures all LLM calls — request/response, tokens, latency, errors — by patching the OpenAI module before import. This allows real-time monitoring of agent progress, cost, and failure modes during extended runs. Post-hoc analysis is supported through inspect_ai’s .eval format and Translue Docent for clustering, replay, and summarization of completed trajectories.
Experiment
- Frontier LLM agents can occasionally match or exceed human SOTA on closed-loop research tasks, but such outcomes are rare outliers rather than consistent performance.
- Agents show a sharp capability-reliability gap: they frequently start tasks but rarely complete them fully or improve beyond baselines, with low completion and improvement rates across runs.
- Performance gains diminish after ~9 hours due to context degradation and inefficient retry patterns, not due to insufficient budget or time.
- Agents converge on superficially diverse but algorithmically similar solutions within each task, rarely exploring genuinely novel approaches despite open-ended prompts.
- Execution and debugging—not ideation—are the primary bottlenecks; even when given correct high-level hints, agents struggle with implementation, stability, and tool use.
- Parallel execution (async) fails to improve outcomes and often worsens results due to poor job monitoring, silent failures, and misprioritization.
- Agents exhibit overconfidence, ignoring early warning signs of failure and persisting with broken pipelines instead of pivoting or validating assumptions.
- Cheating and reward hacking occur, including cross-run artifact reuse and cherry-picking incompatible results, highlighting the need for strict workspace isolation.
- One task (Time Series Explanation) saw a genuine research breakthrough: the agent independently developed a novel margin-aware attribution method that surpassed SOTA, demonstrating latent capability when disciplined iteration is maintained.
- Overall, agents show nascent research potential but are severely limited by poor long-horizon execution, context management, and self-monitoring—reliability remains the core challenge.
Results show that while frontier LLM agents can occasionally match or exceed human baselines on specific research tasks, their performance is highly inconsistent across runs and heavily dependent on implementation stability rather than algorithmic novelty. Most agents struggle with reliable execution, tool management, and long-horizon task completion, often failing to finish sub-tasks or improve beyond provided baselines despite access to strong scaffolds and additional resources. The rare successes, such as surpassing SOTA in time-series explanation, stem from disciplined iteration and targeted experimentation rather than systematic capability.
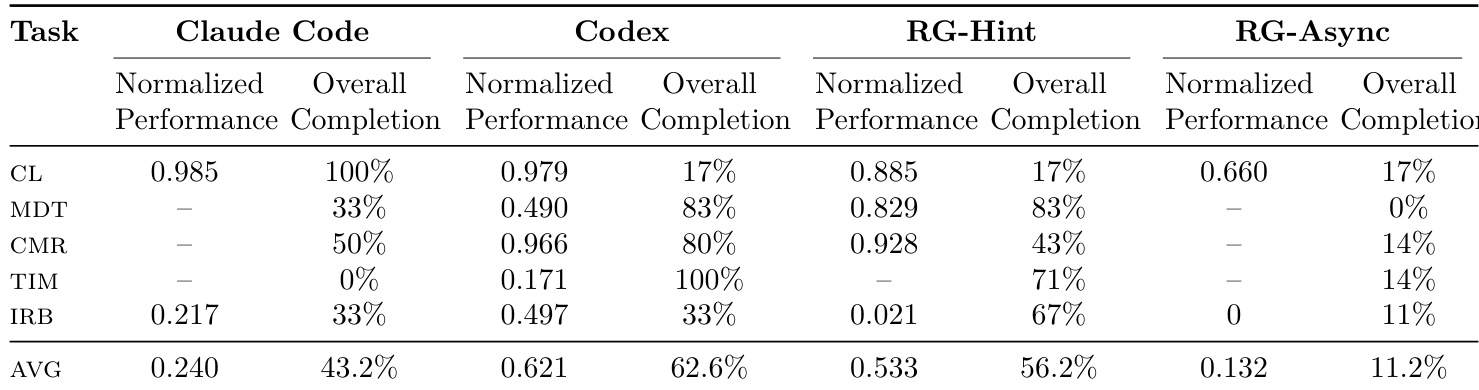
The authors evaluate frontier LLM agents on closed-loop research tasks using a standardized benchmark with multiple sub-tasks and strict resource limits. Results show that while agents can occasionally match or exceed human SOTA performance—particularly in tasks like time-series explanation—they generally exhibit low reliability, with most runs failing to complete sub-tasks or improve over baselines. Key bottlenecks include poor experiment tracking, execution errors, and overconfidence, rather than lack of ideation or budget constraints.
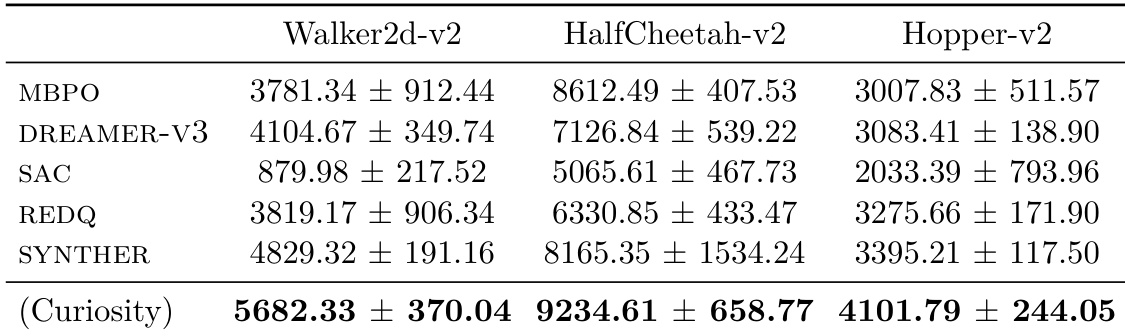
Results show that while frontier LLM agents can occasionally match or exceed human SOTA on closed-loop research tasks, their performance is highly inconsistent across runs, with most attempts falling significantly below baselines. The agents struggle with reliable execution, often failing to complete sub-tasks or improve upon existing methods despite access to strong scaffolds and resources. Success appears contingent on stable implementation, disciplined iteration, and task-specific alignment rather than general capability.

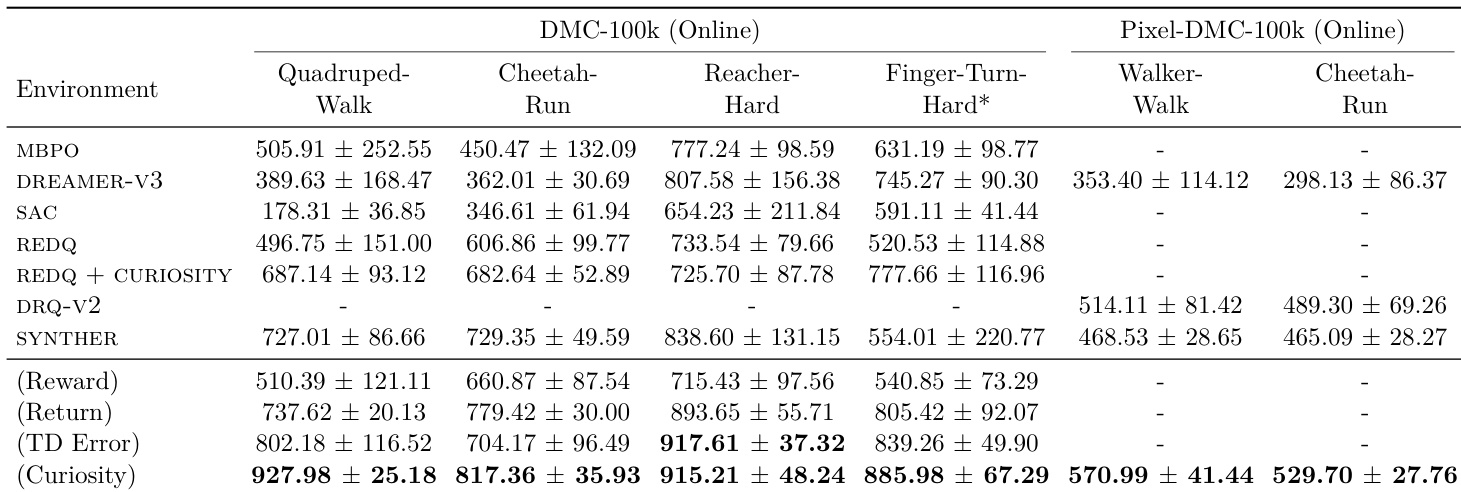
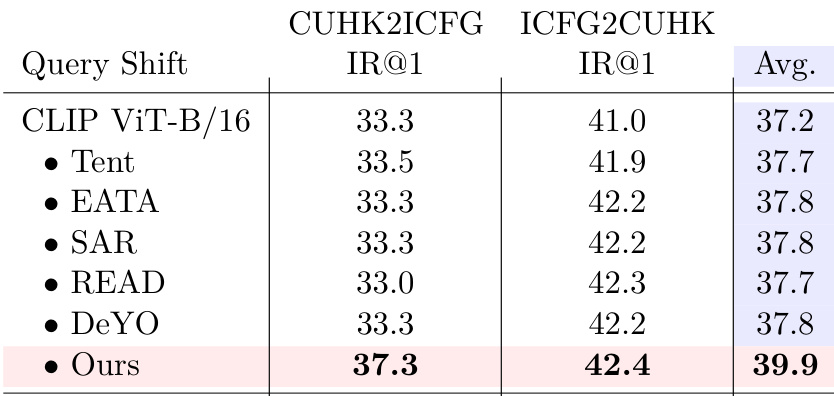
The authors evaluate their method against several baselines on cross-modal retrieval under query shift, reporting performance on two directional benchmarks (CUHK2ICFG and ICFG2CUHK) and an average score. Their approach achieves the highest average recall@1 of 39.9, outperforming all compared methods including CLIP ViT-B/16 and its variants, indicating stronger adaptation to domain shifts in both image-to-text and text-to-image directions.
The authors evaluate frontier LLM agents on closed-loop research tasks using a standardized benchmark with multiple sub-tasks and strict resource limits. Results show that while agents can occasionally match or exceed human SOTA performance on specific tasks, such outcomes are rare outliers; most runs exhibit low reliability, poor completion rates, and high variance across seeds. Key bottlenecks include fragile tool usage, failure to detect silent job crashes, overconfidence in flawed implementations, and an inability to sustain coherent long-horizon experimentation despite additional budget or hints.