HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

QuanBench+: Ein einheitliches Multi-Framework Benchmark für LLM-basiertes Quantum Code Generation

ELT: Elastische geschaltete Transformer-Modelle für die visuelle Generierung

























QuanBench+: Ein einheitliches Multi-Framework Benchmark für LLM-basiertes Quantum Code Generation
ELT: Elastische geschaltete Transformer-Modelle für die visuelle Generierung
ECHO: Effiziente Generierung von Thorax-Röntgenberichten mittels One-step Block Diffusion
Matrix-Game 3.0: Ein Echtzeit- und Streaming-basiertes interaktives World Model mit Long-Horizon Memory
EXAONE 4.5 Technischer Bericht
RefineAnything: Multimodale regionsspezifische Verfeinerung für perfekte lokale Details
FORGE: Feinkörnige Multimodale Evaluation für Manufacturing-Szenarien
WildDet3D: Skalierung von Promptable 3D Detection in the Wild
Autoreason: Selbstverfeinerung, die weiß, wann sie aufhören muss
ActiveGlasses: Erlernen von Manipulation durch Active Vision aus egozentrischen menschlichen Demonstrationen
MegaStyle: Konstruktion eines vielfältigen und skalierbaren Style-Datensatzes durch konsistentes Text-to-Image Style Mapping
Wenn Zahlen sprechen: Die Ausrichtung von textuellen Zahlenwerten und visuellen Instanzen in Text-to-Video Diffusion Modellen
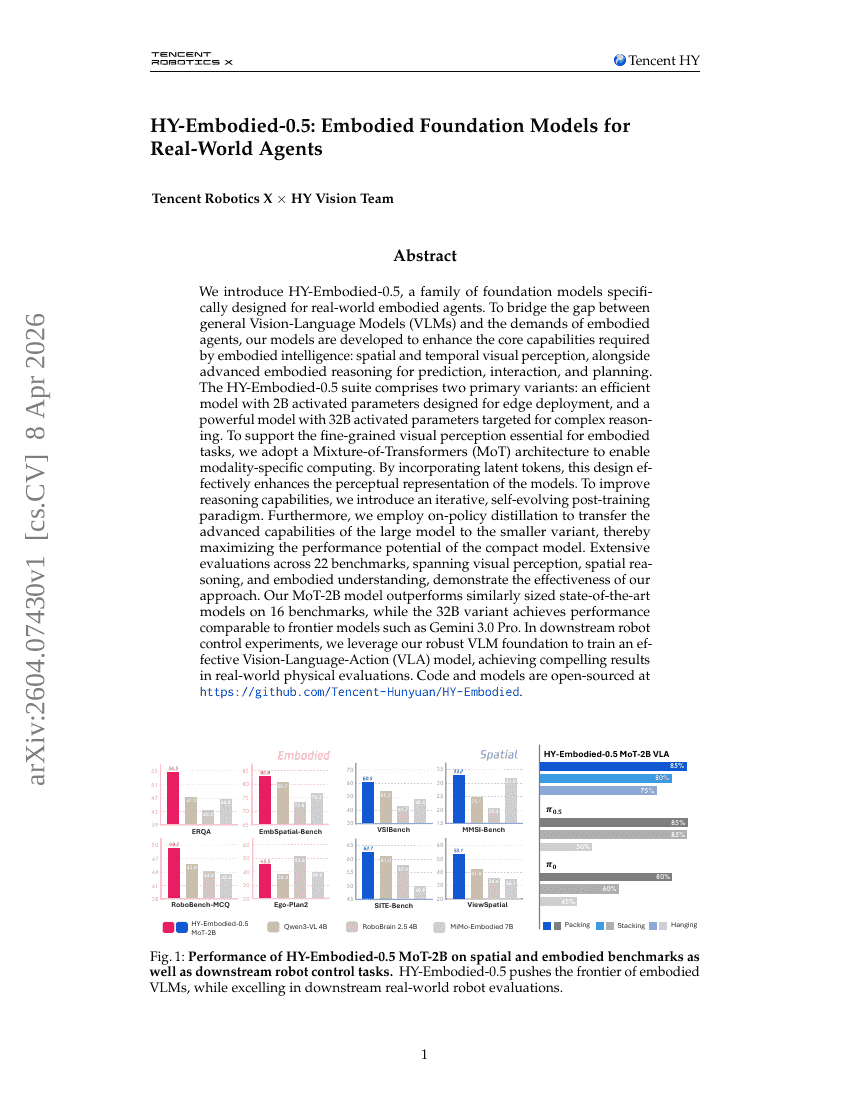
HY-Embodied-0.5: Embodied Foundation Models für Real-World Agents
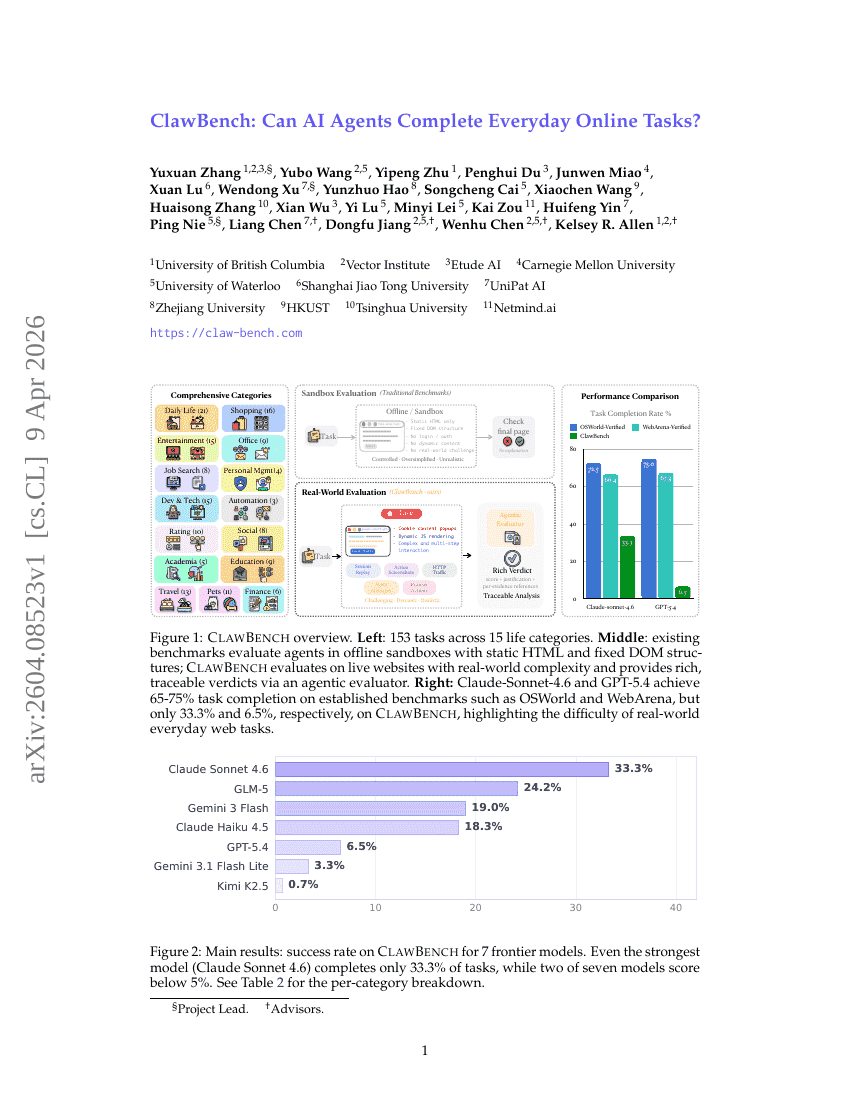
ClawBench: Können AI Agents alltägliche Online-Aufgaben bewältigen?
Überdenken der Generalisierung beim Reasoning SFT: Eine bedingte Analyse von Optimierung, Daten und Model Capability
SkillClaw: Lassen Sie Skills kollektiv mit dem Agentic Evolver evolvieren
MDPBench: Ein Benchmark für mehrsprachiges Dokumenten-Parsing in realen Szenarien
TC-AE: Freischaltung der Token-Kapazität für Deep Compression Autoencoders
INSPATIO-WORLD: Ein Echtzeit 4D-World-Simulator mittels spatiotemporaler autoregressiver Modellierung
FlowInOne: Unifying Multimodal Generation as Image-in, Image-out Flow Matching
MARS: Ermöglicht die Multi-Token-Generierung für Autoregressive Modelle
Denken in Strichen, nicht in Pixeln: Prozessgesteuerte Bildgenerierung durch interleaved Reasoning
RAGEN-2: Reasoning Collapse in Agentic RL
Vanast: Virtuelles Anprobieren durch Human Image Animation mittels synthetischer Triplet Supervision
ThinkTwice: Gemeinsame Optimierung von Large Language Models für Reasoning und Self-Refinement
ACES: Wer testet die Tests? Leave-One-Out AUC-Konsistenz für Code Generation
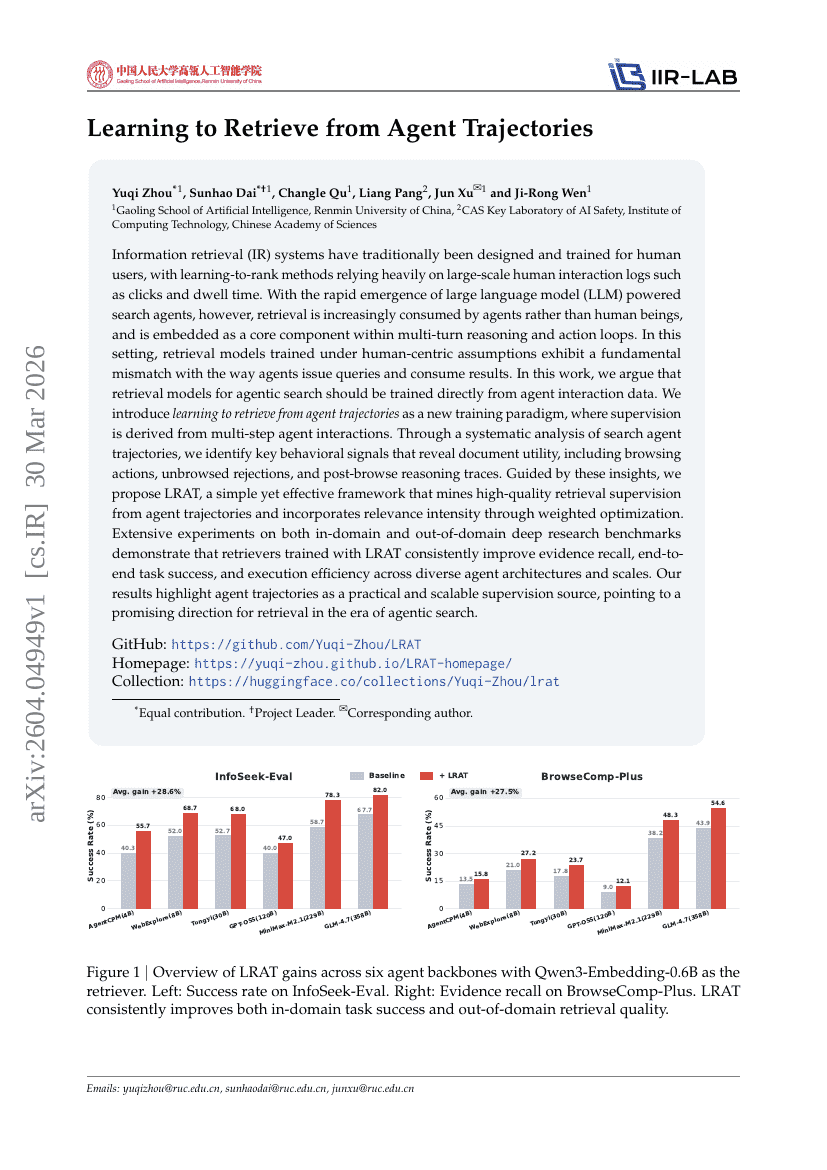
Lernen des Retrieval aus Agent Trajectories
Claw-Eval: Auf dem Weg zu einer vertrauenswürdigen Evaluation von Autonomous Agents
Video-MME-v2: Auf dem Weg zur nächsten Stufe von Benchmarks für umfassendes Video Understanding
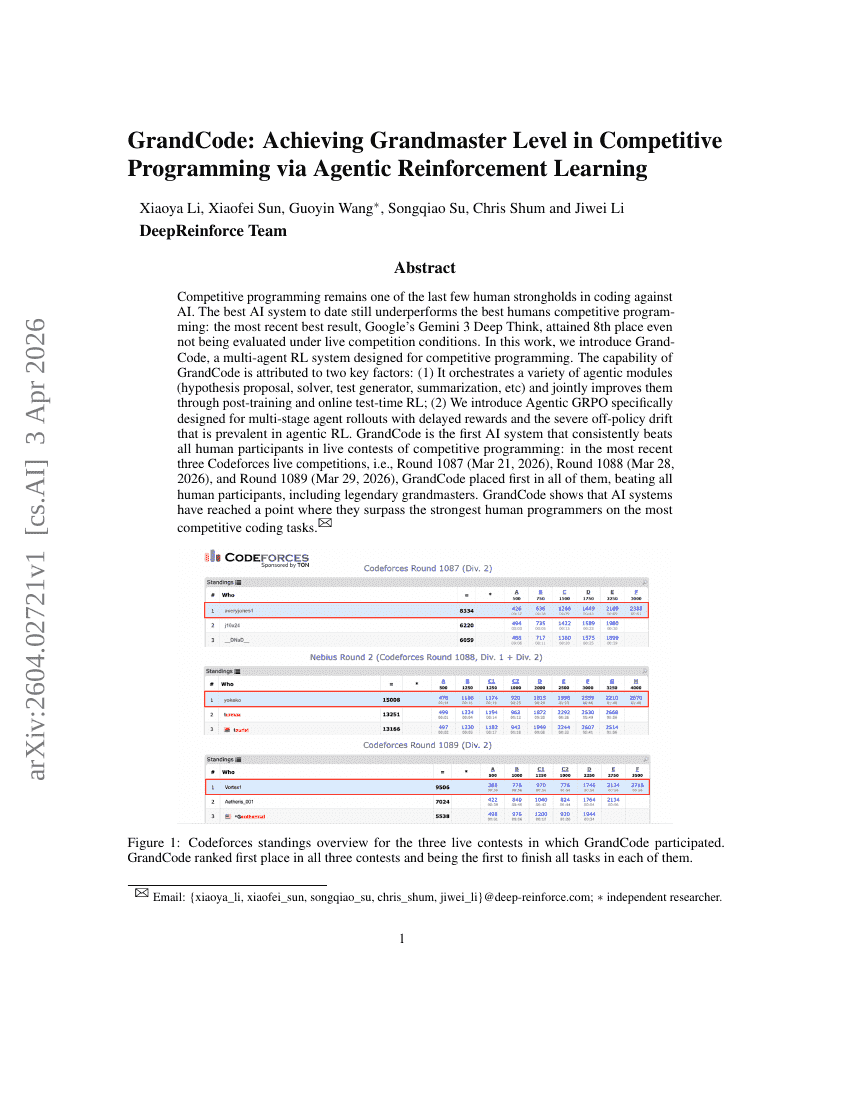
GrandCode: Erreichen des Grandmaster-Levels im Competitive Programming mittels Agentic Reinforcement Learning
LIBERO-Para: Ein diagnostisches Benchmark und Metriken für die Robustheit gegenüber Paraphrasen in VLA-Modellen
TriAttention: Effiziente lange Reasoning-Prozesse mittels trigonometrischer KV-Compression
ECHO: Effiziente Generierung von Thorax-Röntgenberichten mittels One-step Block Diffusion
Matrix-Game 3.0: Ein Echtzeit- und Streaming-basiertes interaktives World Model mit Long-Horizon Memory
EXAONE 4.5 Technischer Bericht
RefineAnything: Multimodale regionsspezifische Verfeinerung für perfekte lokale Details
FORGE: Feinkörnige Multimodale Evaluation für Manufacturing-Szenarien
WildDet3D: Skalierung von Promptable 3D Detection in the Wild
Autoreason: Selbstverfeinerung, die weiß, wann sie aufhören muss
ActiveGlasses: Erlernen von Manipulation durch Active Vision aus egozentrischen menschlichen Demonstrationen
MegaStyle: Konstruktion eines vielfältigen und skalierbaren Style-Datensatzes durch konsistentes Text-to-Image Style Mapping
Wenn Zahlen sprechen: Die Ausrichtung von textuellen Zahlenwerten und visuellen Instanzen in Text-to-Video Diffusion Modellen
HY-Embodied-0.5: Embodied Foundation Models für Real-World Agents
ClawBench: Können AI Agents alltägliche Online-Aufgaben bewältigen?
Überdenken der Generalisierung beim Reasoning SFT: Eine bedingte Analyse von Optimierung, Daten und Model Capability
SkillClaw: Lassen Sie Skills kollektiv mit dem Agentic Evolver evolvieren
MDPBench: Ein Benchmark für mehrsprachiges Dokumenten-Parsing in realen Szenarien
TC-AE: Freischaltung der Token-Kapazität für Deep Compression Autoencoders
INSPATIO-WORLD: Ein Echtzeit 4D-World-Simulator mittels spatiotemporaler autoregressiver Modellierung
FlowInOne: Unifying Multimodal Generation as Image-in, Image-out Flow Matching
MARS: Ermöglicht die Multi-Token-Generierung für Autoregressive Modelle
Denken in Strichen, nicht in Pixeln: Prozessgesteuerte Bildgenerierung durch interleaved Reasoning
RAGEN-2: Reasoning Collapse in Agentic RL
Vanast: Virtuelles Anprobieren durch Human Image Animation mittels synthetischer Triplet Supervision
ThinkTwice: Gemeinsame Optimierung von Large Language Models für Reasoning und Self-Refinement
ACES: Wer testet die Tests? Leave-One-Out AUC-Konsistenz für Code Generation
Lernen des Retrieval aus Agent Trajectories
Claw-Eval: Auf dem Weg zu einer vertrauenswürdigen Evaluation von Autonomous Agents
Video-MME-v2: Auf dem Weg zur nächsten Stufe von Benchmarks für umfassendes Video Understanding
GrandCode: Erreichen des Grandmaster-Levels im Competitive Programming mittels Agentic Reinforcement Learning
LIBERO-Para: Ein diagnostisches Benchmark und Metriken für die Robustheit gegenüber Paraphrasen in VLA-Modellen
TriAttention: Effiziente lange Reasoning-Prozesse mittels trigonometrischer KV-Compression