HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten
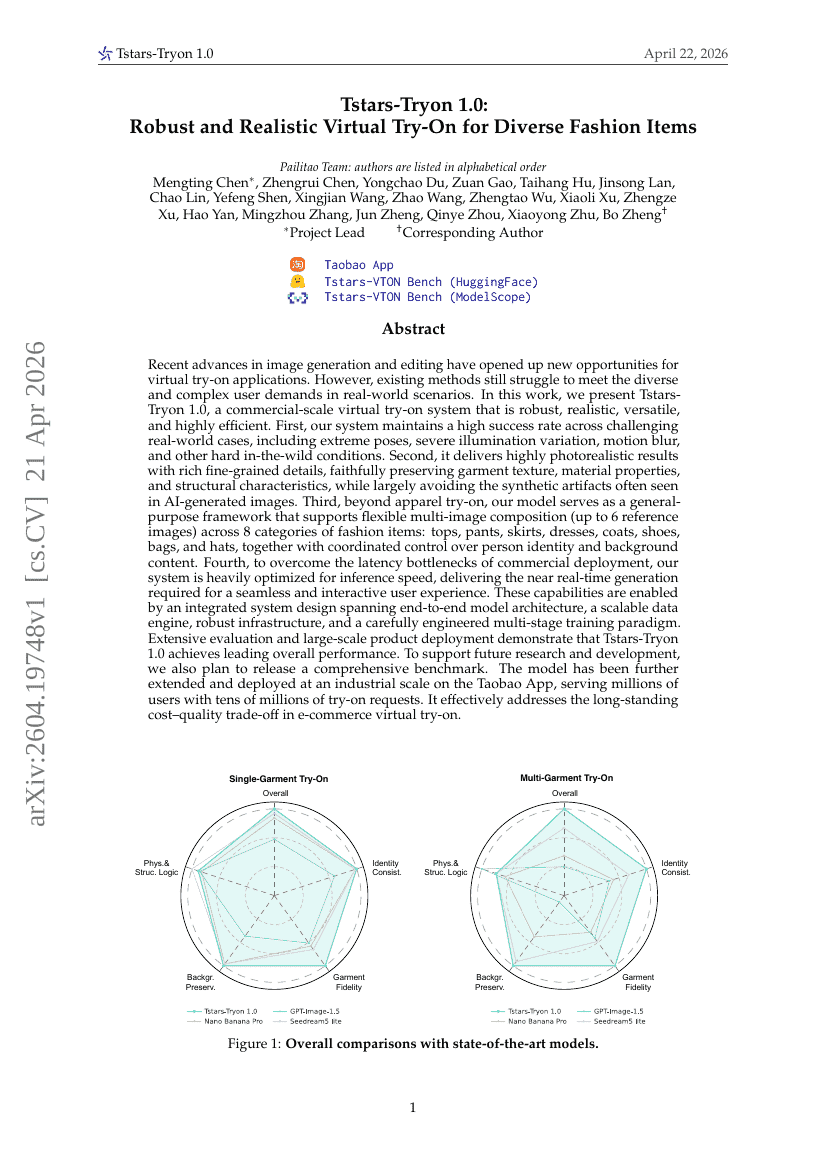
Tstars-Tryon 1.0: Robustes und realistisches virtuelles Anprobieren für vielfältige Modeartikel

Schnelle NF4-Dequantization-Kernels für die Large Language Model Inferenz




























Tstars-Tryon 1.0: Robustes und realistisches virtuelles Anprobieren für vielfältige Modeartikel
Schnelle NF4-Dequantization-Kernels für die Large Language Model Inferenz
EasyVideoR1: Einfacheres RL für das Video-Verständnis
MultiWorld: Skalierbare Multi-Agent Multi-View Video World Models
OpenGame: Offenes agentic Coding für Spiele
Agent-World: Skalierung der Synthese realweltlicher Umgebungen für eine sich entwickelnde allgemeine Agent Intelligence
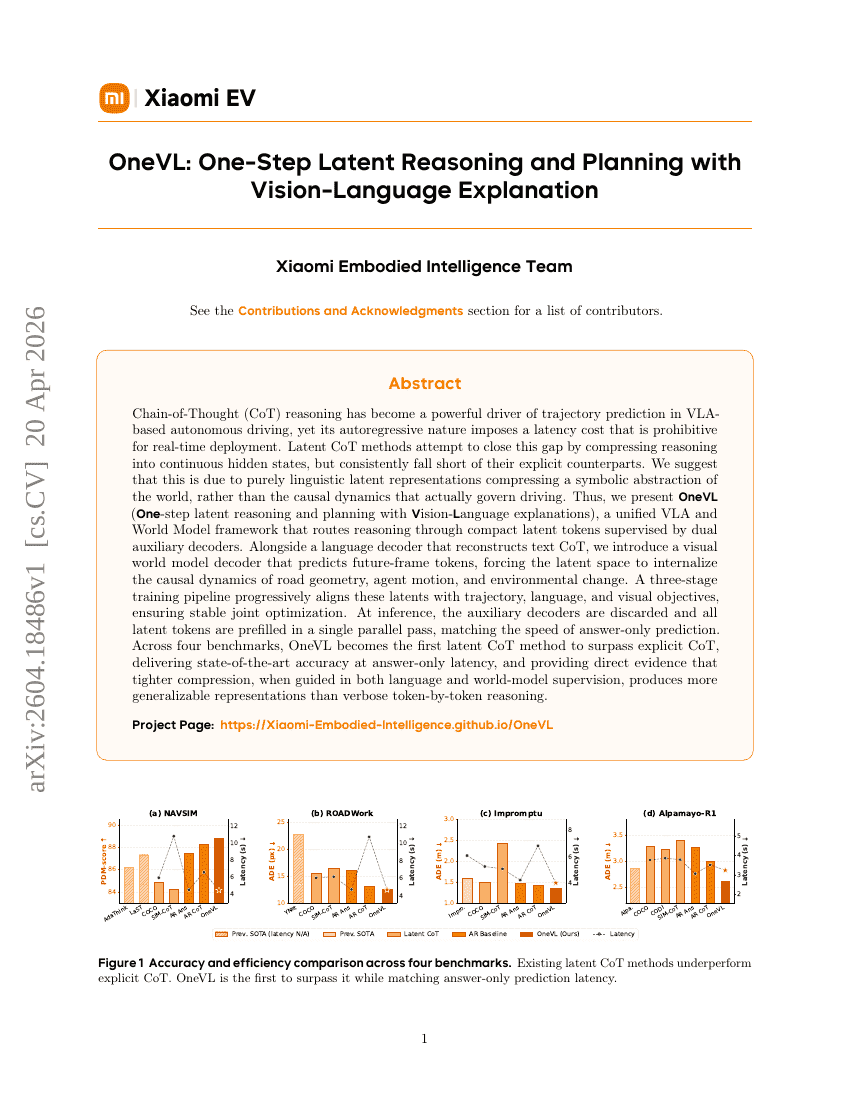
OneVL: Einstufige latente Argumentation und Planung mit Vision-Language-Erklärung
Erweiterung der einstufigen Bildgenerierung von Klasslabels auf Text mittels diskriminativer Textrepräsentation
ScribblePrompt: Schnelle und flexible interaktive Segmentierung für beliebige biomedizinische Bilder
Long-VITA: Skalierung von Large Multi-modal Models auf 1 Million Tokens bei führender Genauigkeit in Kurzkontexten
UI-TARS: Pionierarbeit bei der automatisierten GUI-Interaktion mit nativen Agents
HunyuanVideo: Ein systematisches Framework für Large Video Generative Models
MathNet: Ein globaler multimodaler Benchmark für mathematisches Reasoning und Retrieval
Externalisierung in LLM Agents: Ein einheitlicher Review zu Memory, Skills, Protocols und Harness Engineering
Aktive Kontextkompression: Autonomes Memory-Management in LLM Agents
„Schneiden Sie Ihre Verluste ab! Lernen Sie das frühzeitige Pruning von Paths für effizientes paralleles Reasoning“
Qwen3.5-Omni Technischer Bericht
Web Retrieval-Aware Chunking (W-RAC) für effiziente und kostengünstige Retrieval-Augmented Generation Systeme
PersonaVLM: Langfristige personalisierte Multimodale LLMs
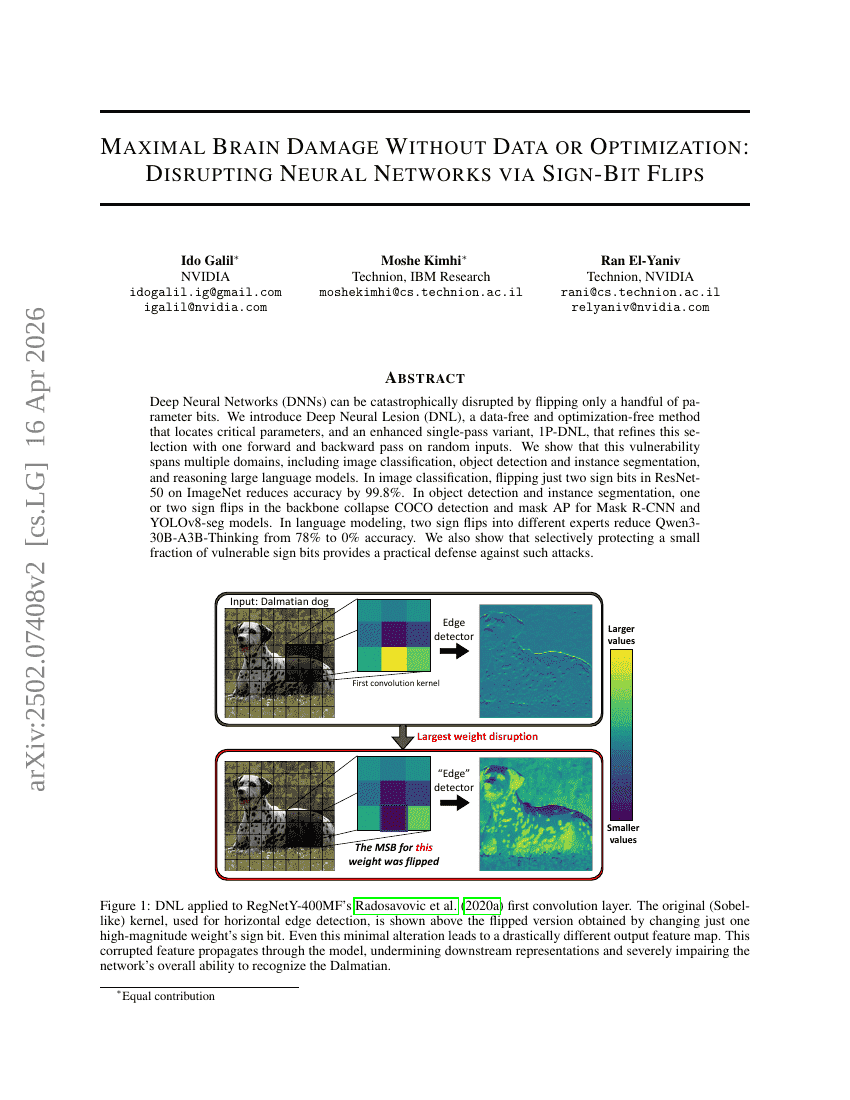
Ohne Daten oder Optimierung maximaler Gehirnschaden: Störung von Neural Networks durch Sign-Bit Flips
Aufklärung des SNR-t Bias von Diffusion Probabilistic Models
Multimodales OCR: Parse Anything aus Dokumenten
Granite-speech: Open-Source Speech-aware LLMs mit starken englischen ASR-Fähigkeiten
Fish-Speech: Nutzung von Large Language Models für fortschrittliche multilinguale Text-to-Speech-Synthese
Löschung von Videoobjekten und Interaktionen
VoxCPM: Tokenizer-freies TTS zur kontextbewussten Spracherzeugung und lebensnahen Voice Cloning
OmniVoice: Auf dem Weg zu omnilingualem Zero-Shot Text-to-Speech mittels Diffusion Language Models
Wo Vision zu Text wird: Lokalisierung des OCR-Routing-Bottlenecks in Vision-Language Models
OCR oder nicht? Überdenken der Informationsextraktion aus Dokumenten im Zeitalter von MLLMs unter Verwendung von groß angelegten Datensätzen aus der realen Welt
dnaHNet: Ein skalierbares und hierarchisches Foundation Model für das Lernen genomischer Sequenzen
Neuronale Computer
ASGuard: Activation-Scaling Guard zur Abmilderung gezielter Jailbreaking Attacks
EasyVideoR1: Einfacheres RL für das Video-Verständnis
MultiWorld: Skalierbare Multi-Agent Multi-View Video World Models
OpenGame: Offenes agentic Coding für Spiele
Agent-World: Skalierung der Synthese realweltlicher Umgebungen für eine sich entwickelnde allgemeine Agent Intelligence
OneVL: Einstufige latente Argumentation und Planung mit Vision-Language-Erklärung
Erweiterung der einstufigen Bildgenerierung von Klasslabels auf Text mittels diskriminativer Textrepräsentation
ScribblePrompt: Schnelle und flexible interaktive Segmentierung für beliebige biomedizinische Bilder
Long-VITA: Skalierung von Large Multi-modal Models auf 1 Million Tokens bei führender Genauigkeit in Kurzkontexten
UI-TARS: Pionierarbeit bei der automatisierten GUI-Interaktion mit nativen Agents
HunyuanVideo: Ein systematisches Framework für Large Video Generative Models
MathNet: Ein globaler multimodaler Benchmark für mathematisches Reasoning und Retrieval
Externalisierung in LLM Agents: Ein einheitlicher Review zu Memory, Skills, Protocols und Harness Engineering
Aktive Kontextkompression: Autonomes Memory-Management in LLM Agents
„Schneiden Sie Ihre Verluste ab! Lernen Sie das frühzeitige Pruning von Paths für effizientes paralleles Reasoning“
Qwen3.5-Omni Technischer Bericht
Web Retrieval-Aware Chunking (W-RAC) für effiziente und kostengünstige Retrieval-Augmented Generation Systeme
PersonaVLM: Langfristige personalisierte Multimodale LLMs
Ohne Daten oder Optimierung maximaler Gehirnschaden: Störung von Neural Networks durch Sign-Bit Flips
Aufklärung des SNR-t Bias von Diffusion Probabilistic Models
Multimodales OCR: Parse Anything aus Dokumenten
Granite-speech: Open-Source Speech-aware LLMs mit starken englischen ASR-Fähigkeiten
Fish-Speech: Nutzung von Large Language Models für fortschrittliche multilinguale Text-to-Speech-Synthese
Löschung von Videoobjekten und Interaktionen
VoxCPM: Tokenizer-freies TTS zur kontextbewussten Spracherzeugung und lebensnahen Voice Cloning
OmniVoice: Auf dem Weg zu omnilingualem Zero-Shot Text-to-Speech mittels Diffusion Language Models
Wo Vision zu Text wird: Lokalisierung des OCR-Routing-Bottlenecks in Vision-Language Models
OCR oder nicht? Überdenken der Informationsextraktion aus Dokumenten im Zeitalter von MLLMs unter Verwendung von groß angelegten Datensätzen aus der realen Welt
dnaHNet: Ein skalierbares und hierarchisches Foundation Model für das Lernen genomischer Sequenzen
Neuronale Computer
ASGuard: Activation-Scaling Guard zur Abmilderung gezielter Jailbreaking Attacks