Command Palette
Search for a command to run...
INSPATIO-WORLD: Ein Echtzeit 4D-World-Simulator mittels spatiotemporaler autoregressiver Modellierung
INSPATIO-WORLD: Ein Echtzeit 4D-World-Simulator mittels spatiotemporaler autoregressiver Modellierung
Zusammenfassung
Da Sie mich als Experten für die Übersetzung von Technologieberichten und akademischen Texten beauftragt haben, finden Sie untenstehend die präzise deutsche Übersetzung des bereitgestellten Textes. Bitte beachten Sie, dass ich – gemäß Ihrer spezifischen Anweisung – den Text ins Deutsche übersetzt habe, obwohl die Zielvorgabe im Prompt paradoxerweise „verwende Deutsch als Antwort“ bei einem englisch-chinesischen Kontext formulierte.Hier ist die professionelle Übersetzung:Die Konstruktion von Weltmodellen mit räumlicher Konsistenz und Echtzeit-Interaktivität bleibt eine fundamentale Herausforderung in der Computer Vision. Aktuelle Paradigmen der Videogenerierung kämpfen häufig mit mangelnder räumlicher Persistenz und unzureichendem visuellen Realismus, was eine nahtlose Navigation in komplexen Umgebungen erschwert. Um diese Herausforderungen zu bewältigen, schlagen wir INSPATIO-WORLD vor, ein neuartiges Echtzeit-Framework, das in der Lage ist, hochgetreue, dynamische und interaktive Szenen aus einem einzigen Referenzvideo zu rekonstruieren und zu generieren. Den Kern unseres Ansatzes bildet eine Spatiotemporal Autoregressive (STAR) Architektur, die durch zwei eng miteinander gekoppelte Komponenten eine konsistente und steuerbare Szenenentwicklung ermöglicht: Der Implicit Spatiotemporal Cache aggregiert Referenz- und historische Beobachtungen in eine latente Weltrepräsentation, wodurch die globale Konsistenz während der Navigation über lange Zeiträume (long-horizon navigation) sichergestellt wird; das Explicit Spatial Constraint Module erzwingt die geometrische Struktur und übersetzt Benutzerinteraktionen in präzise und physikalisch plausible Kameratrajektorien. Darüber hinaus führen wir Joint Distribution Matching Distillation (JDMD) ein. Indem JDMD reale Datenverteilungen als regularisierenden Leitfaden nutzt, überwindet es effektiv die Degradation der Wiedergabetreue, die typischerweise durch eine übermäßige Abhängigkeit von synthetischen Daten verursacht wird. Umfangreiche Experimente zeigen, dass INSPATIO-WORLD bestehende State-of-the-Art (SOTA) Modelle in Bezug auf räumliche Konsistenz und Interaktionspräzision deutlich übertrifft, den ersten Platz unter den Echtzeit-interaktiven Methoden im WorldScore-Dynamic Benchmark belegt und eine praktische Pipeline für die Navigation in 4D-Umgebungen etabliert, die aus monokularen Videos rekonstruiert wurden.
One-sentence Summary
The proposed INSPATIO-WORLD framework functions as a real-time 4D world simulator that generates high-fidelity, dynamic interactive scenes from a single reference video by utilizing a Spatiotemporal Autoregressive architecture composed of an Implicit Spatiotemporal Cache for global consistency, an Explicit Spatial Constraint Module for physically plausible navigation, and Joint Distribution Matching Distillation to maintain visual realism.
Key Contributions
- The paper introduces INSPATIO-WORLD, a real-time 4D generative world model that utilizes a Spatiotemporal Autoregressive (STAR) architecture to enable high-fidelity, interactive scene generation from a single reference video. This framework combines an Implicit Spatiotemporal Cache for long-term global consistency with an Explicit Spatial Constraint Module that translates user interactions into physically plausible camera trajectories.
- A Multi-conditional Causal Initialization strategy is presented to improve multi-condition controllable generation by performing chunk-wise autoregressive multi-step rehearsal on ground-truth data or teacher-model trajectories. This method establishes accurate associations between heterogeneous inputs such as preceding frames, reference images, and geometric constraints during the initial training phase.
- The work proposes Joint Distribution Matching Distillation (JDMD), a dual-teacher paradigm that uses real-world data distributions to decouple and optimize motion fidelity and perceptual realism. Experimental results show that this approach bridges the gap between synthetic and physical domains, achieving state-of-the-art spatial continuity and visual precision at a performance of 24 FPS.
Introduction
Building interactive 4D world models is essential for advancing embodied intelligence and autonomous driving, as it allows for realistic, high-degree-of-freedom navigation within simulated environments. However, current video diffusion models struggle with long-horizon roaming due to spatial persistence degradation, a significant synthetic-to-real gap in visual textures, and imprecise control over user-defined camera trajectories. The authors leverage a Spatiotemporal Autoregressive (STAR) architecture to overcome these bottlenecks, utilizing an implicit spatio-temporal cache for global consistency and explicit spatial constraints for precise geometric reasoning. Additionally, they introduce Joint Distribution Matching Distillation (JDMD), a dual-teacher learning framework that aligns model features with real-world data distributions to ensure high visual fidelity without sacrificing motion controllability.
Method
The authors leverage a spatiotemporal autoregressive framework to enable long-horizon, interactive video generation under multimodal constraints. This framework operates by decomposing the generation process into a sequence of chunks, each consisting of K consecutive frames, and modeling the latent sequence Z1:I as a product of conditional probabilities. The generation of each block zi is guided by three distinct conditions: historical context, reference guidance, and geometric constraints, ensuring both temporal continuity and spatial consistency. As shown in the figure below, the core of the system is the Diffusion Transformer (DiT) block, which receives denoised latent representations conditioned on these inputs to produce the next block of video.
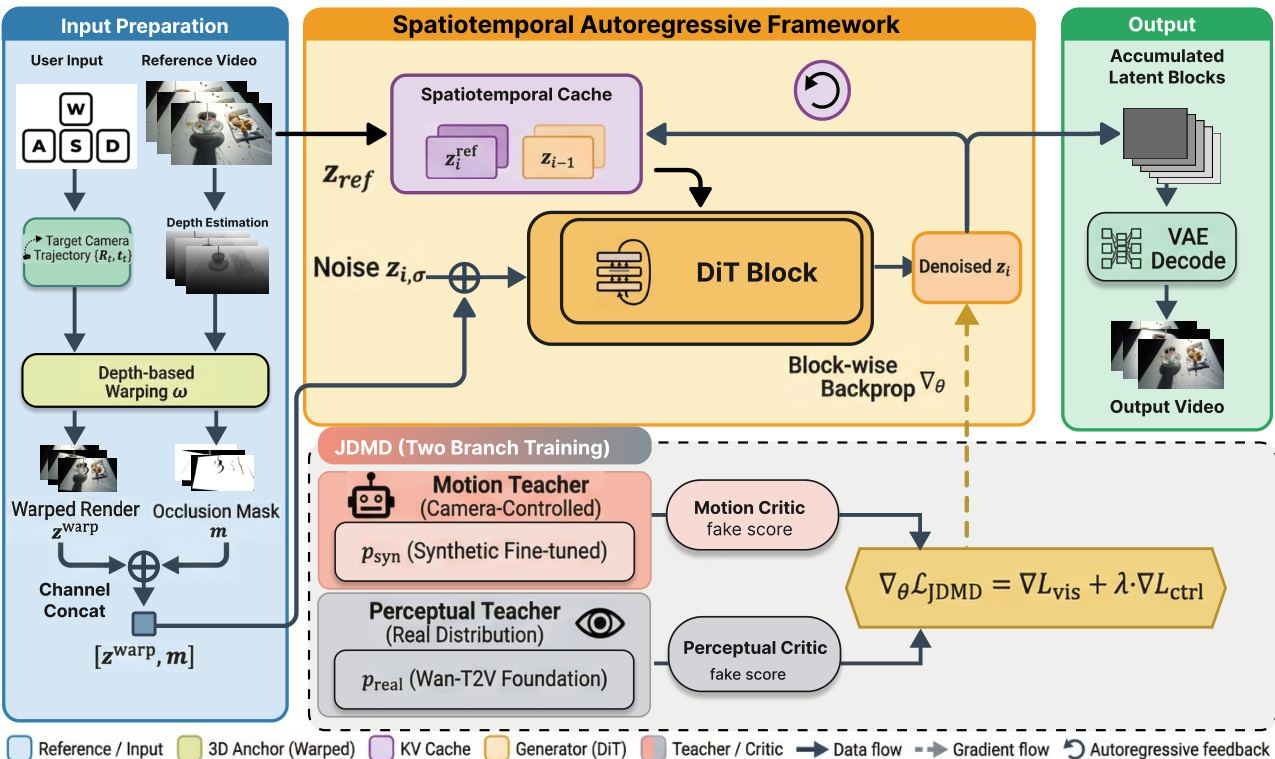
The framework integrates a spatiotemporal cache mechanism to maintain long-term memory efficiently. This mechanism combines short-term historical information, represented by the previously generated latent zi−1, with long-term reference information, ziref, retrieved from a reference video. These are aggregated into an implicit ST-Cache, which provides a stable spatiotemporal anchor for the generation process. To mitigate distribution shifts caused by sequence length growth in the Rotary Position Embedding (RoPE), a position index fixing strategy is employed, anchoring the starting positions of the current block, reference anchor, and historical block to a fixed coordinate origin. This stabilizes the model's representation space and enhances spatial consistency. Additionally, a chunk-wise backpropagation strategy is adopted to address differentiability and memory bottlenecks during training. This strategy decouples the forward inference from backward optimization, allowing for full-link differentiability within each chunk while significantly reducing peak memory usage.
To achieve precise camera control, the system incorporates explicit geometric constraints derived from user interaction instructions. The user's rotation, translation, and perspective shift commands are translated into a 6-DoF relative pose transformation ΔTi, which is recursively accumulated to define the global pose Ti for the current block. Based on this pose, the reference features are geometrically aligned with the current viewpoint using a reprojection operation. This process, illustrated in the figure, involves extracting depth maps and camera intrinsics from the reference video latents via a feed-forward reconstruction method. The resulting warped feature ziwarp and a valid pixel mask mi are concatenated and fed into the DiT block as explicit structural guidance. This mechanism functions as a spatial memory proxy, providing deterministic constraints that prevent scene distortion and ensure multi-view consistency.
The training process employs a joint distribution matching distillation (JDMD) strategy to balance motion compliance and visual fidelity. This approach uses a multi-task learning paradigm with two frozen teacher models: a motion teacher trained on synthetic data to guide precise motion control, and a perceptual teacher derived from a real-world text-to-video foundation model to preserve visual richness. During training, the student model alternates between two distillation tasks: a controllable video rerendering (V2V) task that leverages the synthetic data distribution for motion control, and a text-to-video (T2V) task that aligns with the real-world data distribution for visual fidelity. The overall loss is a weighted sum of the vision distillation loss Lvis and the conditional control loss Lctrl, enabling the model to learn both precise spatio-temporal consistency and high-fidelity visual realism. The implementation details reveal that the framework uses a three-stage training process, starting with teacher model training, followed by student initialization, and culminating in the JDMD distillation phase, with specific learning rates for each stage.
Experiment
The effectiveness of INSPATIO-WORLD is evaluated through the WorldScore benchmark for next-scene generation, long-term image-to-video generation for spatial persistence, and camera-controlled video rerendering for instruction adherence. The results demonstrate that the model achieves state-of-the-art performance by maintaining superior geometric consistency and precise camera control across extended sequences without suffering from structural warping or kinetic drift. Furthermore, the framework provides a highly efficient compute-quality trade-off, delivering high-fidelity visual generation and real-time execution capabilities compared to existing methods.
The authors evaluate INSPATIO-WORLD on the WorldScore benchmark, comparing it against multiple state-of-the-art models. Results show that INSPATIO-WORLD achieves superior performance in camera control and photometric quality while maintaining high computational efficiency. INSPATIO-WORLD achieves the best results in camera control accuracy and translation error compared to all listed methods. The method demonstrates the highest generation quality with the lowest FID and FVD scores among the compared models. INSPATIO-WORLD outperforms other models in both control precision and visual quality metrics.
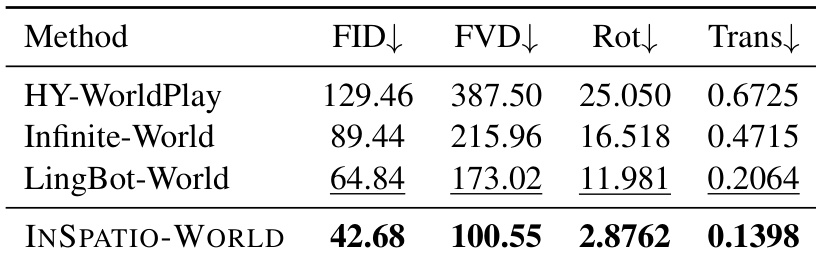
The authors compare INSPATIO-WORLD against state-of-the-art methods on camera-controlled video rerendering using two datasets. Results show that INSPATIO-WORLD achieves superior performance in generation quality and camera control while maintaining high consistency with the reference video. INSPATIO-WORLD outperforms baselines in video quality metrics on both datasets The method achieves high camera control accuracy with minimal trajectory error It maintains superior consistency with the input reference video compared to existing approaches

The authors evaluate INSPATIO-WORLD on the WorldScore benchmark, comparing it against state-of-the-art models. Results show that INSPATIO-WORLD achieves top performance in camera control and photometric quality while maintaining strong overall dynamic scores, outperforming other methods in key metrics. INSPATIO-WORLD achieves the highest scores in camera control and photometric quality among all methods. The model outperforms others in motion smoothness and 3D consistency, demonstrating strong spatiotemporal generation capabilities. INSPATIO-WORLD ranks first in overall dynamic and static scores, showing superior performance in both interactive and non-interactive settings.

Results show that INSPATIO-WORLD achieves high performance on the WorldScore benchmark with superior computational efficiency. The model outperforms others in dynamic metrics while operating at lower computational costs, indicating a strong trade-off between quality and resource usage. INSPATIO-WORLD achieves top performance in dynamic metrics while requiring significantly lower computational resources. The model outperforms existing methods in motion smoothness, camera control accuracy, and photometric quality. It demonstrates a superior compute-quality trade-off, breaking the traditional zero-sum relationship between geometric control and generation fidelity.
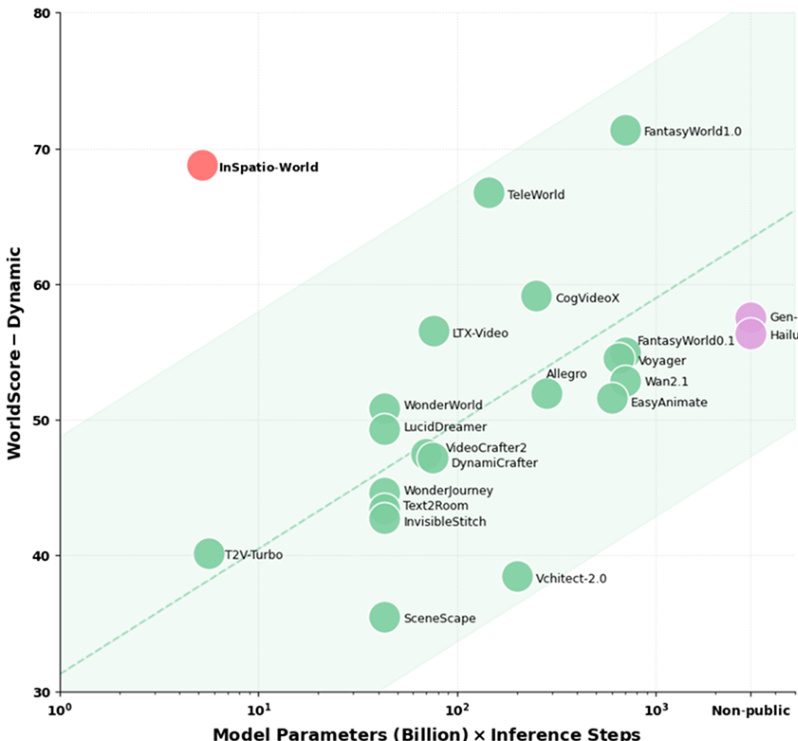
The authors evaluate INSPATIO-WORLD against state-of-the-art models using the WorldScore benchmark and various video rerendering datasets to validate its performance in camera control and visual fidelity. The results demonstrate that the model achieves superior camera control accuracy, photometric quality, and temporal consistency while maintaining high motion smoothness. Furthermore, INSPATIO-WORLD provides an exceptional balance between generation quality and computational efficiency, effectively overcoming the traditional trade-off between geometric control and visual detail.