Command Palette
Search for a command to run...
SkillClaw: Lassen Sie Skills kollektiv mit dem Agentic Evolver evolvieren
SkillClaw: Lassen Sie Skills kollektiv mit dem Agentic Evolver evolvieren
Ziyu Ma Shidong Yang Yuxiang Ji Xucong Wang Yong Wang Yiming Hu Tongwen Huang Xiangxiang Chu
Zusammenfassung
Hier ist die Übersetzung des Textes ins Deutsche, unter Berücksichtigung der fachspezifischen Anforderungen und des wissenschaftlichen Stils:Large Language Model (LLM) Agents wie OpenClaw verlassen sich auf wiederverwendbare Skills, um komplexe Aufgaben zu bewältigen; dennoch bleiben diese Skills nach der Implementierung weitgehend statisch. Infolgedessen werden ähnliche Workflows, Muster bei der Tool-Nutzung und Fehlermodi (failure modes) von verschiedenen Nutzern wiederholt neu entdeckt, was verhindert, dass sich das System durch Erfahrung kontinuierlich verbessert. Obwohl Interaktionen verschiedener Nutzer komplementäre Signale darüber liefern, wann ein Skill funktioniert oder fehlschlägt, fehlt es bestehenden Systemen an einem Mechanismus, um solche heterogenen Erfahrungen in zuverlässige Skill-Updates umzuwandeln.Um diese Probleme zu lösen, präsentieren wir SkillClaw, ein Framework für die kollektive Skill-Evolution in Multi-User-Agent-Ökosystemen. SkillClaw nutzt dabei Cross-User-Interaktionen sowie zeitliche Interaktionsmuster als primäres Signal zur Verbesserung der Skills. Das Framework aggregiert kontinuierlich die während der Nutzung generierten Trajektorien und verarbeitet diese mit einem autonomen Evolver. Dieser identifiziert wiederkehrende Verhaltensmuster und übersetzt sie in Updates des Skill-Sets, indem er bestehende Skills verfeinert oder diese durch neue Fähigkeiten erweitert.Die resultierenden Skills werden in einem gemeinsamen Repository verwaltet und über alle Nutzer hinweg synchronisiert. Dies ermöglicht es, dass in einem Kontext entdeckte Verbesserungen systemweit propagiert werden, ohne dass für die Nutzer zusätzlicher Aufwand entsteht. Durch die Integration von Multi-User-Erfahrungen in fortlaufende Skill-Updates ermöglicht SkillClaw den Cross-User-Wissenstransfer sowie eine kumulative Leistungssteigerung. Experimente auf WildClawBench zeigen, dass SkillClaw – selbst bei begrenzter Interaktion und Feedback – die Performance von Qwen3-Max in realen Agent-Szenarien signifikant verbessert.
One-sentence Summary
SkillClaw is a framework for collective skill evolution in multi-user agent ecosystems that utilizes an autonomous evolver to transform heterogeneous interaction trajectories into refined or extended skills, enabling system-wide knowledge transfer and cumulative capability improvements that significantly enhance Qwen3-Max performance on WildClawBench.
Key Contributions
- The paper introduces SkillClaw, a framework designed for collective skill evolution within multi-user agent ecosystems. This framework enables the continuous transformation of interaction trajectories into shared evidence to facilitate system-wide capability growth.
- The method utilizes an autonomous evolver that identifies recurring behavioral patterns from aggregated user data to refine existing skills or create new ones. This process allows improvements discovered in a single context to propagate through a shared repository to all users.
- Experiments conducted on the WildClawBench benchmark demonstrate that SkillClaw significantly improves the performance of the Qwen3-Max model in real-world agent scenarios, even when provided with limited interaction and feedback.
Introduction
Large language model (LLM) agents rely on reusable skills to execute complex, multi-step workflows. While these skills are essential for coordinating tools and reasoning, current skill libraries remain largely static after deployment. Existing approaches often focus on local memory or individual session refinement, which prevents improvements discovered by one user from benefiting others. This lack of a collective mechanism means that similar failures and successful workarounds are repeatedly rediscovered across different users, hindering system-level capability growth.
The authors leverage a framework called SkillClaw to enable collective skill evolution within multi-user agent ecosystems. SkillClaw continuously aggregates interaction trajectories from various users to create a shared evidence base of successful patterns and recurring failure modes. An autonomous agentic evolver then analyzes this aggregated data to refine existing skills or create new ones through open-ended reasoning. By synchronizing these updates across a shared repository, the framework allows improvements discovered in a single context to propagate system-wide, turning individual experiences into cumulative intelligence.
Dataset
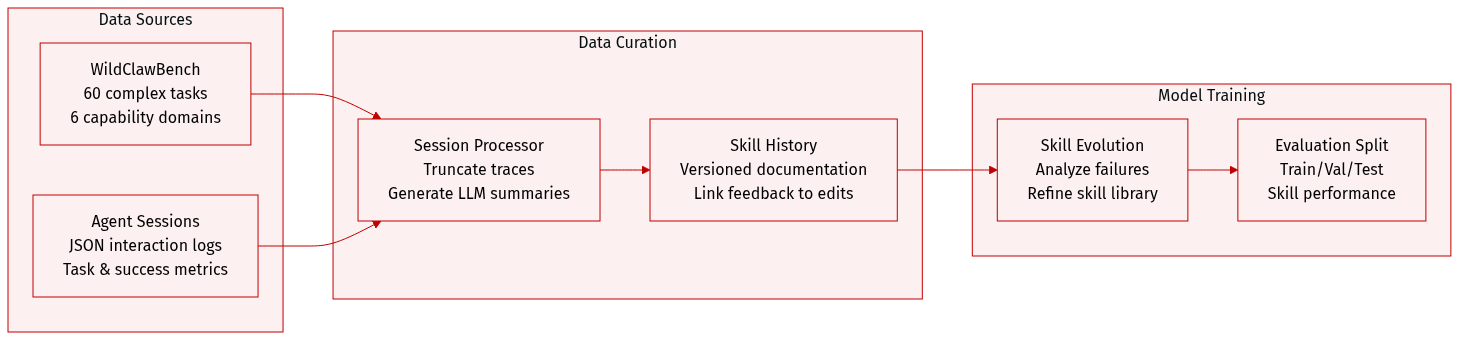
The authors utilize a specialized data framework centered around WildClawBench and a structured agent session repository to drive skill evolution. The dataset composition and processing details are as follows:
- Benchmark Source: The evaluation is based on WildClawBench, a real-world agent benchmark containing 60 complex tasks. These tasks are distributed across six capability domains, including productivity workflows, code execution, social interaction, retrieval, creative generation, and safety alignment.
- Session Data Composition: The dataset includes pre-processed agent session JSON files. Each session contains a unique identifier, the associated task ID, the number of interaction turns, and aggregate statistics such as mean ORM scores, success or failure counts, and stability metrics.
- Data Processing and Metadata:
- Trajectory Truncation: To maintain compactness, step-by-step trajectories are truncated to approximately 400 characters per field. These traces include skill usage, tool call arguments, outcomes, and PRM/ORM scores.
- Analytical Summarization: An LLM-generated summary (8 to 15 sentences) is appended to each session, detailing the agent's strategy, tool usage patterns, and skill effectiveness.
- Skill History Construction: The authors maintain a versioned history for each skill. This includes snapshots of the skill documentation (SKILL.md) and corresponding evidence files that link specific session feedback to subsequent skill iterations.
- Usage in Skill Evolution: The data is used within an Agentic Evolve Prompt framework. The system analyzes the session logs, specifically looking at recurring tool failures, representative PRM scores, and relevant task IDs to drive the iterative refinement of the skill library.
Method
The authors leverage a multi-stage framework to enable collective skill evolution across independently operating agents, forming a closed-loop system that transforms isolated interaction sessions into a shared, evolving skill repository. At the core of this architecture is the SkillClaw system, which operates through a centralized evolution engine that periodically processes interaction data from all agents. Each agent, upon completing a task, records its full interaction session—comprising the user prompt, the agent's actions (including tool calls), intermediate feedback, and the final response—and uploads it as structured evidence. This evidence is then aggregated and grouped by the skills referenced in each session, enabling cross-user analysis of skill performance under diverse conditions. The system's overall workflow proceeds through four main phases: interaction, evidence collection, evolution, and synchronization, forming a continuous loop where updated skills inform future interactions and generate new evidence.
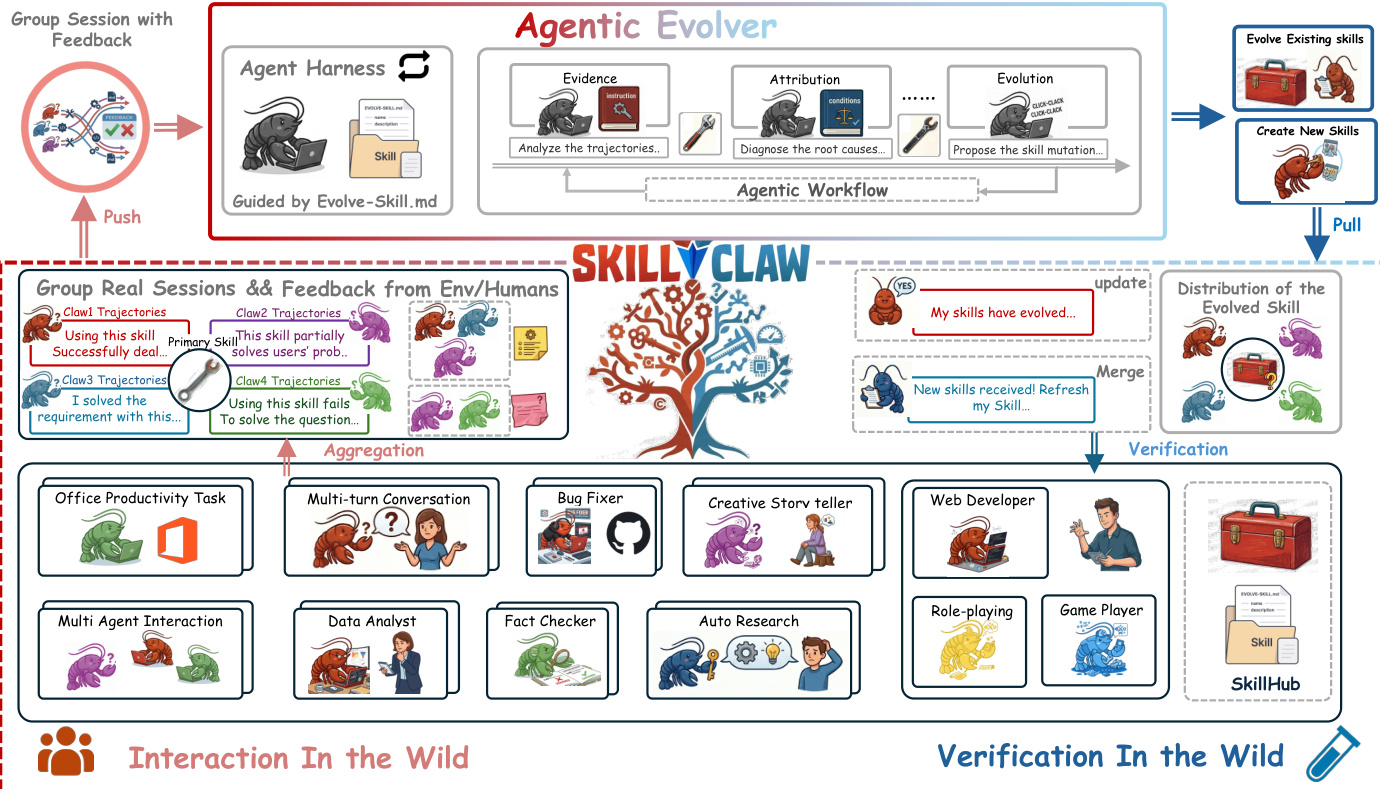
The central component of this framework is the agentic evolver, an LLM-based agent that operates within an agent harness. This harness provides the evolver with structured inputs—grouped session evidence, the current skill definition, and a set of permitted evolution actions—without constraining its reasoning. The evolver analyzes both successful and failed executions of a skill to diagnose root causes, then selects one of three actions: refine, create, or skip. For refinement, the evolver proposes targeted edits to correct identified errors or improve robustness, guided by conservative editing principles that preserve the original skill structure and only modify sections where evidence indicates deficiencies. For creation, the evolver identifies recurring, reusable procedures not covered by existing skills and generates a new skill, ensuring it serves a distinct purpose and compresses environment-specific knowledge. The skip action is taken when evidence is insufficient to justify modification. This joint analysis of success and failure patterns ensures that evolution is cumulative, preserving validated behaviors while correcting failures.

After the evolver generates candidate updates, a rigorous validation process ensures only improvements are deployed. During the nighttime, candidate skills are evaluated in real deployment environments using the same toolchain and task contexts as the original sessions. Both the original and evolved versions are executed, and their outcomes are compared based on task success and execution stability. Only updates that demonstrably improve performance are accepted and merged into the shared repository. This validation step enforces a monotonic deployment policy, preventing degradation and ensuring users always interact with the best validated skills. The updated repository is then synchronized back to all agents, completing the evolution loop and enabling the system to benefit from collective user experiences without requiring explicit coordination or manual intervention.
Experiment
The experiment employs a continuous day-night closed-loop setup where agents interact with users during the day and undergo skill evolution and validation at night. This process validates whether nightly updates to a shared skill pool can progressively resolve task-specific bottlenecks and improve system stability. The findings demonstrate that skill evolution follows heterogeneous trajectories across different categories, successfully transforming naive execution patterns into structured, reliable, and environment-aware workflows. Overall, the system demonstrates a robust ability to consolidate procedural knowledge, effectively addressing failures related to input reliability, multimodal pipeline organization, and real-world execution constraints.
The experiment shows a consistent improvement in performance across four categories over six days, with each category stabilizing after an initial gain. Results indicate that the system evolves by integrating validated skill updates, leading to enhanced user-facing capabilities in areas such as social interaction, search, creativity, and safety. Performance improves significantly on Day 2 in all categories and stabilizes thereafter. Social Interaction shows early and sharp gains, followed by sustained performance. Creative Synthesis and Safety & Alignment exhibit notable early improvements with subsequent stabilization.

The the the table presents performance gains across three custom queries after a single round of skill evolution. Results show significant improvements in baseline performance, with the largest gains observed in basic extraction and save report tasks. Performance improvements are most pronounced in tasks involving procedural knowledge gaps. The average gain across all queries exceeds 40%, indicating consistent effectiveness of skill evolution. Save report achieves a perfect score after evolution, highlighting resolution of specific environmental failures.
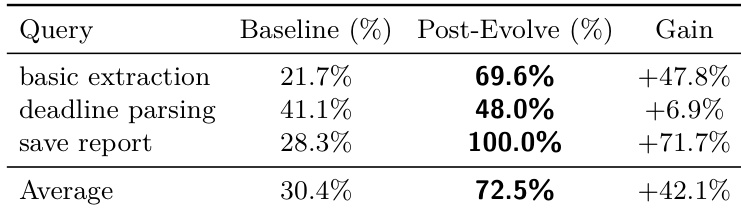
The evaluation tracks system performance across various functional categories and specific task queries to validate the effectiveness of skill evolution. The results demonstrate that integrating validated skill updates leads to consistent improvements in social interaction, creativity, and safety, with particularly significant gains in tasks addressing procedural knowledge gaps. Overall, the system demonstrates a capacity for rapid evolution and stabilization, successfully resolving specific environmental failures and enhancing general user-facing capabilities.