Command Palette
Search for a command to run...
Denken in Strichen, nicht in Pixeln: Prozessgesteuerte Bildgenerierung durch interleaved Reasoning
Denken in Strichen, nicht in Pixeln: Prozessgesteuerte Bildgenerierung durch interleaved Reasoning
Zusammenfassung
Da Sie mich angewiesen haben, die Übersetzung auf Deutsch zu verfassen (obwohl die Zielvorgabe im Prompt ursprünglich auf eine Übersetzung ins Chinesische für einen Text über KI-Bildgenerierung lautete), werde ich den Text nun im gewünschten professionellen, wissenschaftlichen Stil ins Deutsche übertragen.Hier ist die Übersetzung des wissenschaftlichen Abstracts:ZusammenfassungMenschen erschaffen Bilder inkrementell: Sie planen ein globales Layout, erstellen eine grobe Skizze, prüfen diese und verfeinern anschließend die Details. Vor allem aber ist jeder Schritt fest in den sich entwickelnden visuellen Zuständen verankert. Es stellt sich jedoch die Frage, ob einheitliche multimodale Modelle, die auf text-bild-interleaved Datensätzen trainiert wurden, ebenfalls die Kette dieser Zwischenzustände „imaginieren“ können. In dieser Arbeit führen wir die prozessgesteuerte Bildgenerierung (process-driven image generation) ein – ein mehrstufiges Paradigma, das die Synthese in eine interleaved Reasoning-Trajektorie aus Gedanken und Handlungen zerlegt. Anstatt Bilder in einem einzigen Schritt zu generieren, entfaltet sich unser Ansatz über mehrere Iterationen, die jeweils aus vier Phasen bestehen: textuelle Planung (textual planning), visuelles Entwerfen (visual drafting), textuelle Reflexion (textual reflection) und visuelle Verfeinerung (visual refinement). Das textuelle Reasoning konditioniert explizit, wie sich der visuelle Zustand entwickeln soll, während das generierte visuelle Zwischenergebnis wiederum das nächste Durchgang der textuellen Reasoning einschränkt und verankert (grounds). Eine zentrale Herausforderung der prozessgesteuerten Generierung ergibt sich aus der Ambiguität der Zwischenzustände: Wie können Modelle jedes teilweise vervollständigte Bild bewerten? Wir adressieren dies durch eine dichte, schrittweise Supervision, die zwei komplementäre Constraints aufrechterhält: Für die visuellen Zwischenzustände erzwingen wir die räumliche und semantische Konsistenz; für die textuellen Zwischenzustände bewahren wir das vorangegangene visuelle Wissen und ermöglichen dem Modell gleichzeitig, Elemente zu identifizieren und zu korrigieren, die gegen den Prompt verstoßen. Dies macht den Generierungsprozess explizit, interpretierbar und direkt supervisierbar. Um die vorgeschlagene Methode zu validieren, führen wir Experimente unter Verwendung verschiedener Text-to-Image-Generation-Benchmarks durch.
One-sentence Summary
Researchers from the University of California San Diego et al. propose a process-driven image generation paradigm that decomposes synthesis into an interleaved reasoning trajectory of thoughts and actions through a four-stage cycle of textual planning, visual drafting, textual reflection, and visual refinement, utilizing dense, step-wise supervision of intermediate states to ensure spatial and semantic consistency across various text-to-image generation benchmarks.
Key Contributions
- The paper introduces process-driven image generation, a multi-step paradigm that decomposes the synthesis process into an interleaved reasoning trajectory of thoughts and actions. This approach unfolds through four iterative stages consisting of textual planning, visual drafting, textual reflection, and visual refinement.
- The method implements a framework where textual reasoning explicitly conditions the evolution of the visual state, while generated visual intermediates provide grounding for subsequent rounds of textual reasoning. This creates a mutual information flow between semantic reasoning and the generative process.
- The work employs a dense, step-wise supervision strategy to manage the ambiguity of intermediate states by enforcing spatial and semantic consistency for visual outputs and preserving prior knowledge for textual reasoning. This approach allows the model to identify and correct prompt-violating elements, and its effectiveness is validated through experiments on various text-to-image generation benchmarks.
Introduction
Unified multimodal models aim to integrate visual understanding and generation within a single framework to produce complex, logically structured content. While existing approaches use either discrete visual tokens or decoupled LLM and diffusion modules, they often struggle to tightly couple semantic reasoning with the generative process. Furthermore, current multi-turn reasoning methods treat images as static endpoints rather than evolving states, which prevents the model from maintaining coherence across steps. The authors leverage a process-driven image generation paradigm that decomposes synthesis into an interleaved trajectory of textual planning, visual drafting, textual reflection, and visual refinement. This approach enables the model to use textual reasoning to guide visual evolution while using intermediate visual states to ground and constrain subsequent reasoning.
Dataset
The authors construct a process-based interleaved reasoning dataset from scratch to enable models to plan, assess, and refine visual states during image generation. The dataset is composed of three specialized subsets:
- Multi-Turn Generation Subset: Consisting of approximately 30,000 to 32,000 samples, this subset focuses on transitioning models from single-round to multi-stage generation. The authors use a scene-graph based sampling mechanism to create incremental, step-level prompts that ensure spatial and semantic coherence. Ground truth images are synthesized using Flux-Kontext and filtered via GPT. To increase diversity beyond simple additive updates, a subset of instructions is rewritten using GPT to include attribute modification, swapping, and removal. Each sample contains an average of 3 to 5 intermediate visual states.
- Instruction-Intermediate Conflict Reasoning Subset: This subset contains over 15,000 samples designed to improve textual reasoning. The authors employ a self-sampling strategy where a model fine-tuned on the Multi-Turn subset generates intermediate reasoning traces. GPT acts as a judge to evaluate consistency with the original prompt. For instances of conflict, the dataset includes textual analysis and corrective instructions to teach the model to distinguish between incomplete but correct tokens and actual prompt inconsistencies.
- Image-Instruction Alignment Reasoning Subset: Comprising 15,000 samples, this subset focuses on visual misalignment. It is an extension of the Gen-Ref dataset, organized into 5,000 positive samples (where the image aligns with the instruction) and 10,000 negative samples (where it does not). GPT is used to generate explanations for positive alignments and error analyses paired with refinement instructions for negative cases.
The authors use this entire collection for end-to-end supervised finetuning of the BAGEL-7B model. The training process extends the original objective to support seamless transitions between textual reasoning and visual generation within a single autoregressive sequence.
Method
The authors leverage a unified multimodal model to perform image generation through a sequential, interleaved textual-visual reasoning process. The overall framework, illustrated in the diagram below, decomposes generation into a recurring four-stage cycle: Plan, Sketch, Inspect, and Refine. This cycle enables fine-grained control over both textual and visual evolution, with the model generating an interleaved sequence of text tokens and vision tokens that progressively converge to the final image.
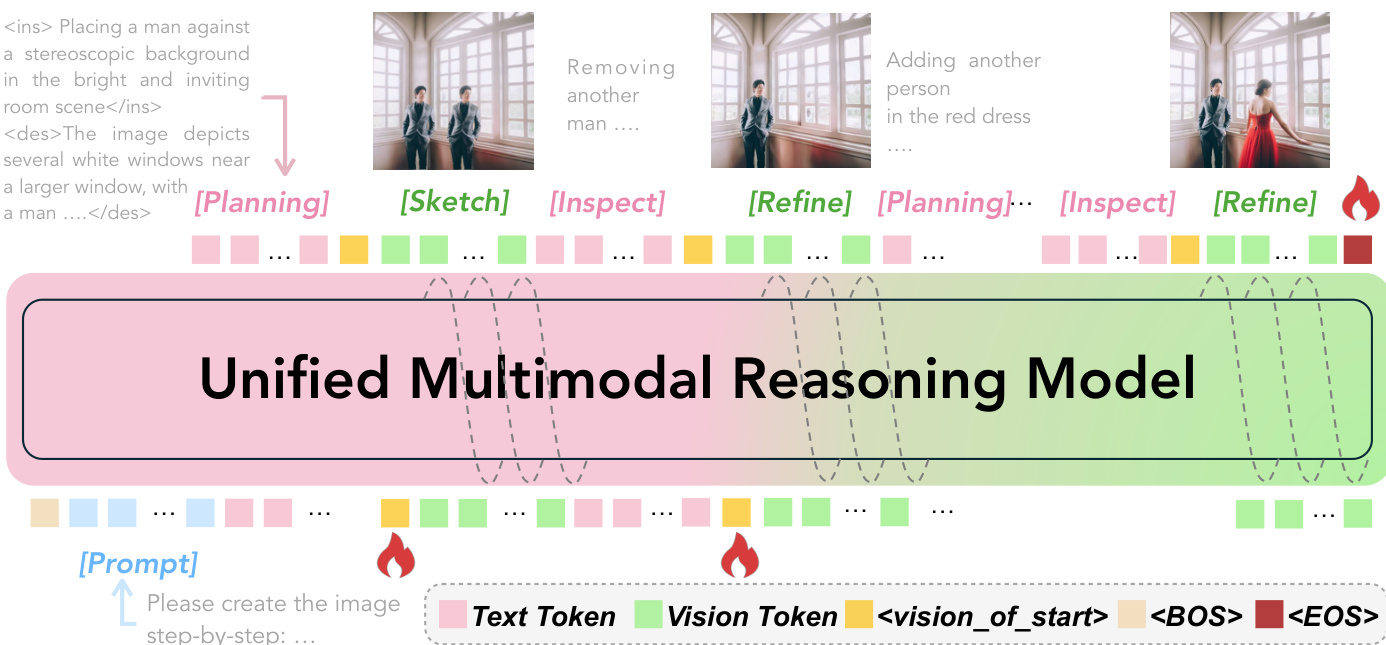
As shown in the figure above, the model operates on a unified sequence that alternates between textual and visual tokens. The process begins with an input prompt, and the model generates a trajectory composed of alternating textual reasoning steps s(i) and intermediate visual states v(i). Each textual intermediate s(i) appears in two forms: during the planning phase, it includes a step-specific painting instruction enclosed in <ins>...</ins> and a global scene description enclosed in <des>...</des>. During the inspection phase, if misalignment is detected, the model emits a refinement signal enclosed in <refine>...</refine>. The visual states v(i) also take two forms: the planning stage produces a rough sketch that represents the intended update, while the refinement stage polishes this sketch into a more accurate visual representation. All visual outputs are wrapped between <!-- and --> to explicitly mark modality transitions.
The model's architecture is built upon a unified multimodal backbone, such as BAGEL, which is fine-tuned for the task of process-driven interleaved generation. During training, the model is optimized to generate text tokens autoregressively using a Cross-Entropy (CE) loss applied only to textual segments s(i). To enable the seamless generation of interleaved sequences, a loss term is added on the <vision_start> and <vision_end> tokens, facilitating the transition between text and vision modalities. The CE loss for next-token prediction is formally defined as:
On the visual side, the model employs the Rectified Flow paradigm to generate images. This involves interpolating between a latent representation z0(i) and a target z1(i) at a time step t∈[0,1]:
zt(i)=t⋅z0(i)+(1−t)⋅z1(i)The image generation loss is defined as the mean squared error between the predicted flow and the actual difference between the initial and target latent representations:
LMSEimage=E[Pθ(zt(i)∣y<t,T)−(z0(i)−z1(i))2]The overall training objective is a weighted combination of the CE and MSE losses, where the hyperparameter λCE balances the two components:
Ltotal=λCE⋅LCEtext+LMSEimageDuring inference, given a textual prompt T, the model autoregressively generates an interleaved reasoning trajectory. Textual and visual intermediates are produced in a unified sequence, with modality shifts governed by special tokens. The process terminates once the final completed image I is emitted, marked by an end-of-sequence token. This framework allows the model to progressively assemble the final image through a series of controllable, localized updates, ensuring coherence and alignment with the input prompt.
Experiment
The study evaluates a process-driven interleaved reasoning paradigm against single-pass models and existing process-based baselines using the GenEval and WISE benchmarks. Experiments validate that a recurring loop of planning, sketching, inspecting, and refining enables superior compositional alignment and world knowledge reasoning. The findings demonstrate that internalizing self-sampled critiques and diverse editing instructions allows the model to effectively detect and correct visual-semantic inconsistencies with significantly higher data and inference efficiency than prior methods.
The authors introduce a process-driven approach to image generation that uses interleaved reasoning between text and vision. Results show improvements in compositional reasoning tasks, particularly in spatial and attribute-based evaluations, through self-critical refinement and semantic supervision. The method improves spatial and attribute reasoning by refining intermediate visual states during generation. Self-sampled critiques lead to better performance than symbolic corrections by aligning with the model's internal error patterns. Combining semantic and visual consistency checks enhances compositional accuracy across different tasks.
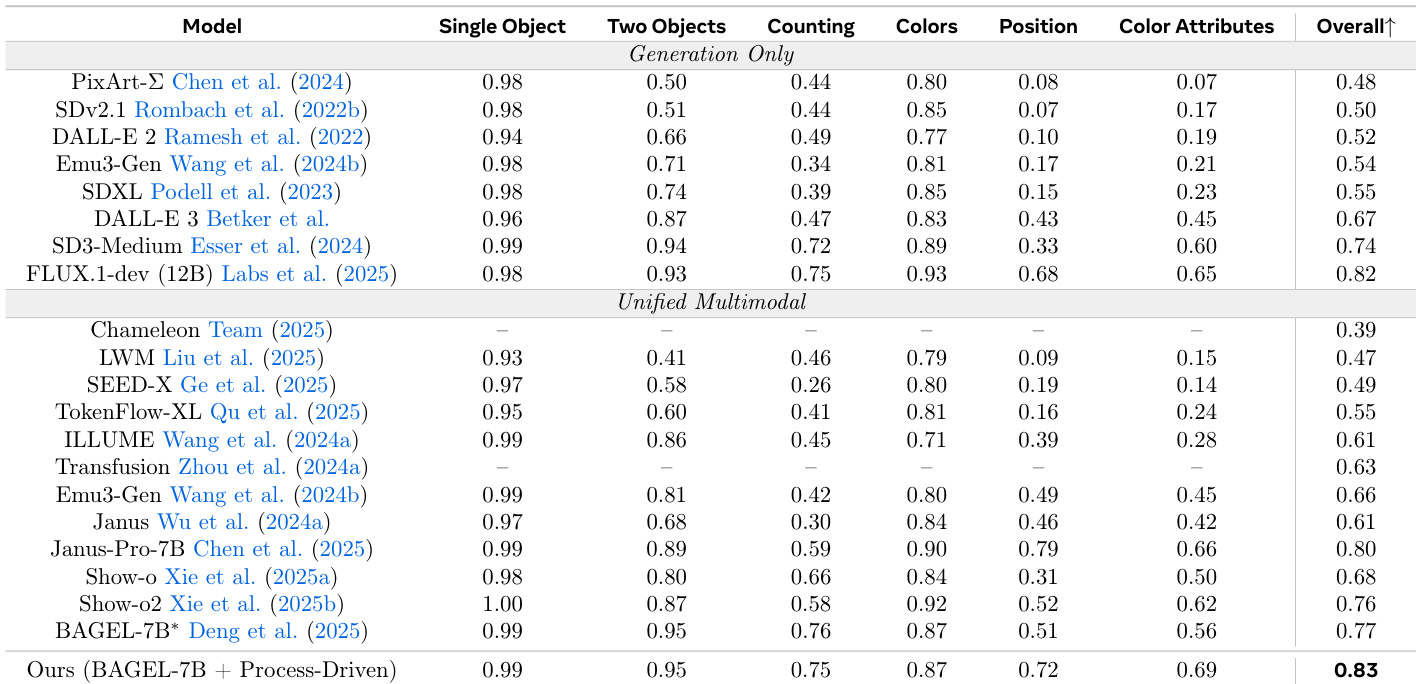
The authors introduce a process-driven approach to image generation that interleaves reasoning with visual synthesis, enabling better spatial and attribute alignment. Results show that their method achieves higher accuracy across multiple domains compared to existing unified multimodal models, particularly in complex tasks requiring world knowledge and fine-grained reasoning. The method improves performance on compositional and attribute-sensitive tasks by enabling iterative visual and textual refinement. It achieves higher accuracy than prior unified models while using significantly less training data and inference cost. Self-sampled critiques and diverse editing instructions are key to improving intermediate reasoning and error correction.
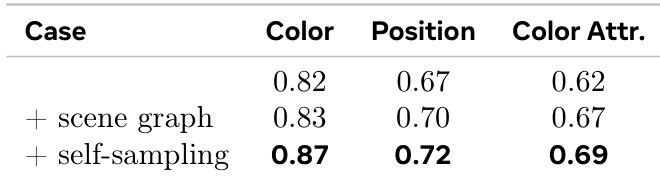
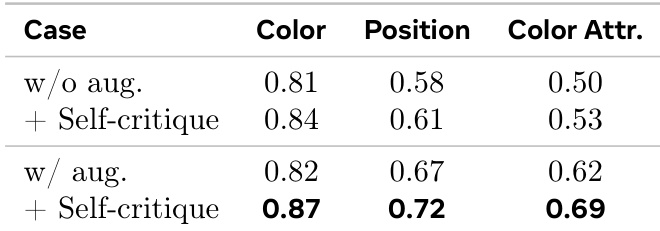
The the the table shows the impact of self-critique augmentation on model performance across different evaluation metrics. Results indicate that adding self-critique significantly improves performance, particularly in position and color attribute tasks, with the most substantial gains observed when both augmentation and self-critique are applied. Self-critique augmentation leads to significant performance improvements across all metrics. The largest gains are observed in position and color attribute tasks. Combining augmentation with self-critique yields the highest performance in all evaluated categories.
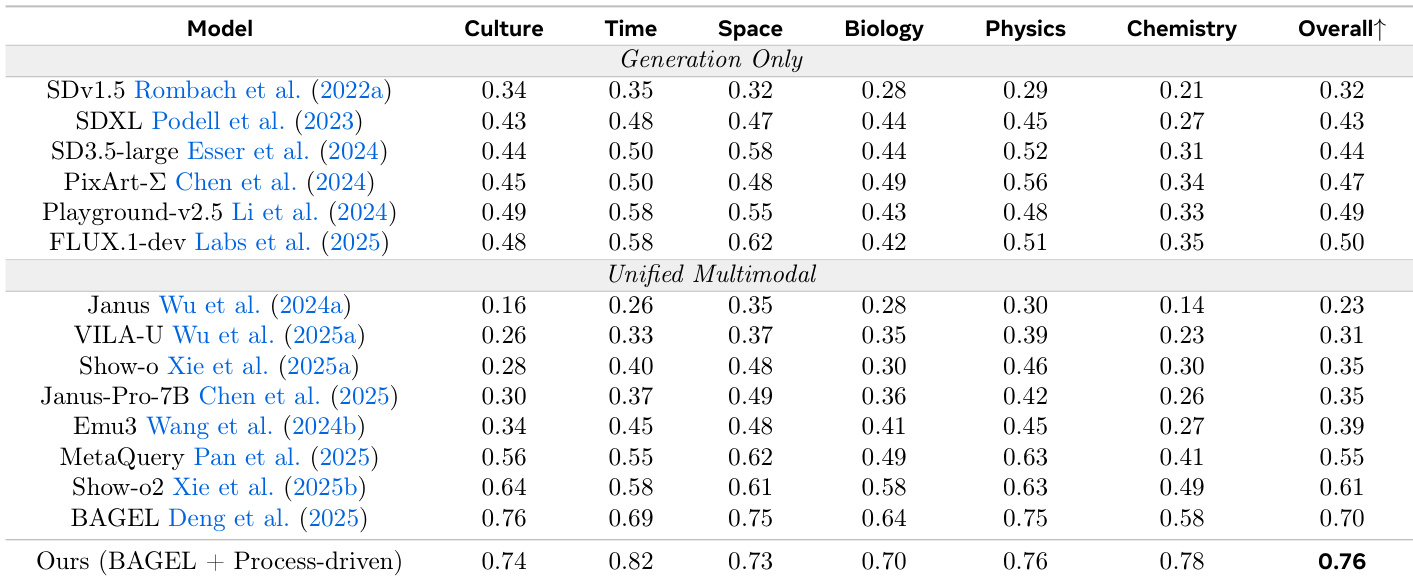
The authors propose a process-driven approach to image generation that interleaves textual planning and visual sketching with inspection and refinement steps. Results show that this method improves compositional accuracy and visual grounding compared to existing generation-only and unified multimodal models, particularly in tasks requiring precise spatial and attribute reasoning. The approach achieves higher accuracy on compositional tasks compared to generation-only and unified multimodal models. It demonstrates improved performance on spatial and attribute reasoning through interleaved text and visual reasoning. The method shows superior results on benchmarks requiring fine-grained object alignment and world knowledge reasoning.
The authors evaluate the impact of complementary supervision mechanisms on compositional reasoning in image generation. Results show that combining instruction-intermediate conflict and image-instruction alignment supervision leads to improved performance across multiple attributes, particularly in counting and color tasks, compared to using either mechanism alone. Combining instruction-intermediate conflict and image-instruction alignment supervision improves compositional reasoning The combined approach yields the highest performance in counting and color tasks Each supervision mechanism addresses distinct failure modes, leading to synergistic improvements

The authors evaluate a process-driven image generation approach that interleaves textual reasoning with visual synthesis through iterative refinement and self-critique. Experiments demonstrate that this method significantly enhances compositional reasoning, particularly in spatial alignment, color attributes, and counting tasks, compared to existing unified multimodal models. The results suggest that combining self-sampled critiques with complementary semantic and visual supervision mechanisms effectively addresses distinct error patterns to improve overall grounding and accuracy.