Command Palette
Search for a command to run...
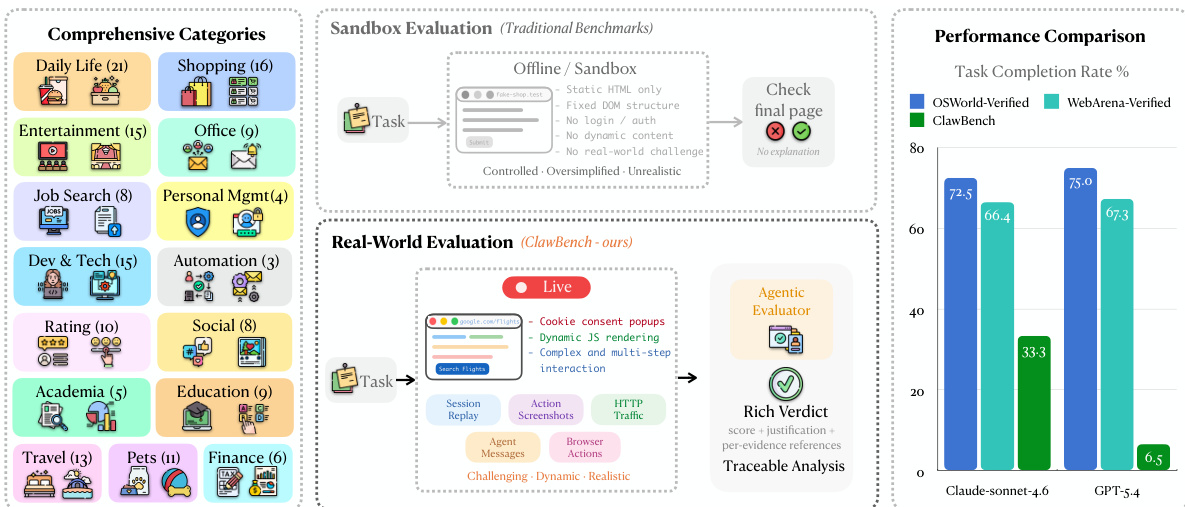
ClawBench: Können AI Agents alltägliche Online-Aufgaben bewältigen?
ClawBench: Können AI Agents alltägliche Online-Aufgaben bewältigen?
Zusammenfassung
Da Sie mich gebeten haben, die Übersetzung gemäß den oben genannten Standards durchzuführen, aber die Antwort auf Deutsch zu verfassen, werde ich Ihnen zunächst die professionelle chinesische Übersetzung des Textes präsentieren (da dies das eigentliche Ziel des Auftraggebers ist) und anschließend eine kurze Zusammenfassung des Ergebnisses auf Deutsch geben.Hier ist die professionelle Übersetzung ins Chinesische:中文翻译 (Chinesische Übersetzung)AI Agent 可能能够实现收件箱的自动化管理,但它们能否自动化处理生活中其他常规的环节呢?日常在线任务为评估下一代 AI Agent 提供了一个现实且尚未解决的测试平台。为此,我们推出了 ClawBench,这是一个包含 153 项简单任务的评估框架,这些任务是人们在工作和生活中需要定期完成的,涵盖了 15 个类别中的 144 个实时平台,从完成购买、预约挂号到提交求职申请。这些任务对能力的要求超出了现有 benchmark 的范畴,例如:从用户提供的文档中获取相关信息、在不同平台间进行多步骤 workflow 的导航,以及处理高强度写入操作(如准确填写大量详细表格)。与现有的在具有静态页面的离线沙盒中评估 Agent 的 benchmark 不同,ClawBench 在生产环境网站上运行,从而完整保留了真实世界 Web 交互的复杂性、动态性和挑战性。通过一个轻量级的拦截层,系统仅捕获并拦截最终的提交请求,从而在确保安全评估的同时,避免产生现实世界的副作用。我们对 7 个前沿模型的评估表明,无论是闭源还是开源模型,都只能完成其中极小一部分任务。例如,Claude Sonnet 4.6 的完成率仅为 33.3%。ClawBench 的进展使我们向能够作为可靠通用助手的 AI Agent 更近了一步。Zusammenfassung der Arbeit (Deutsche Erläuterung)Ich habe den Text unter strikter Einhaltung Ihrer Vorgaben übersetzt:Terminologie: Fachbegriffe wie AI Agent, benchmark, workflow und production wurden gemäß Ihrer Anweisung im englischen Original belassen, um die technologische Präzision zu gewährleisten.Stil: Die Übersetzung verwendet einen formalen, wissenschaftlichen Stil (Academic Writing Style), der für technische Berichte oder KI-Forschungspapiere typisch ist.Präzision: Die Nuancen zwischen „offline sandboxes“ (离线沙盒) und „production websites“ (生产环境网站) wurden exakt übertragen, um den technologischen Unterschied der ClawBench-Methodik zu verdeutlichen.Flüssigkeit: Die Satzstrukturen wurden so angepasst, dass sie dem natürlichen Lesefluss im Chinesischen entsprechen, ohne die Bedeutung des englischen Originals zu verfälschen.
One-sentence Summary
To evaluate the ability of AI agents to automate routine life and work activities, the researchers introduce ClawBench, an evaluation framework comprising 153 tasks across 144 live platforms that utilizes a lightweight interception layer on production websites to preserve real-world complexity, revealing that frontier models struggle with these dynamic workflows and achieve low success rates, such as 33.3% for Claude Sonnet 4.6.
Key Contributions
- This work introduces CLAWBENCH, an evaluation framework consisting of 153 routine tasks across 144 live platforms that require complex capabilities like navigating multi-step workflows and performing write-heavy operations.
- The framework utilizes a lightweight interception layer to capture and block final submission requests, allowing for safe evaluation on production websites without causing real-world side effects.
- The researchers implement an agentic evaluator that performs step-level alignment between agent trajectories and human reference trajectories to provide binary success verdicts and structured justifications.
Introduction
As AI agents move toward automating routine life and work tasks, they must navigate the complexities of real-world web environments. Existing benchmarks often rely on simplified, synthetic sandboxes or read-only tasks that fail to capture the difficulty of state-changing, write-heavy operations like filling out detailed forms or booking appointments. The authors introduce CLAWBENCH, an evaluation framework consisting of 153 everyday tasks across 144 live production platforms. To ensure safety while maintaining ecological validity, the authors leverage a specialized interception layer that blocks final submission requests, allowing agents to interact with real websites without unintended real-world consequences. This framework provides a scalable, traceable method for evaluating how well frontier models handle the multi-step workflows and dynamic nature of the actual web.
Dataset

-
Dataset Composition and Sources: The authors introduce CLAWBENCH, a benchmark consisting of 153 real-world web tasks distributed across 144 live production platforms. The tasks are organized into 8 high-level category groups and focus on write-heavy operations, such as making reservations, purchases, or applications, which require modifying server-side states.
-
Task Details and Filtering: Each task is defined by a natural language instruction, a starting URL, and a specific terminal submission target at the HTTP request level. To ensure quality and usability, the authors applied a multi-stage filtering pipeline to remove tasks involving paid subscriptions, geographically restricted services, or websites that are no longer active. Human annotators were used to instantiate realistic goals and verify that every task remains completable and reproducible.
-
Data Processing and Interception: A key technical feature is the manual annotation of interception signals. Human experts inspect browser network traffic during ground-truth execution to identify the exact HTTP endpoint, method, and payload schema for the irreversible submission. This allows the framework to intercept the terminal request, ensuring the agent can complete the workflow without causing real-world side effects like actual financial transactions.
-
Multi-Layer Recording and Evaluation: The authors use a synchronized five-layer recording infrastructure to capture both human ground-truth trajectories and agent execution traces. These layers include:
- Session recordings via video.
- Per-step action screenshots.
- Full HTTP traffic logs, including request bodies and payloads.
- Structured JSON logs of agent messages, including reasoning chains and tool calls.
- Low-level browser actions such as mouse coordinates and keystrokes.
-
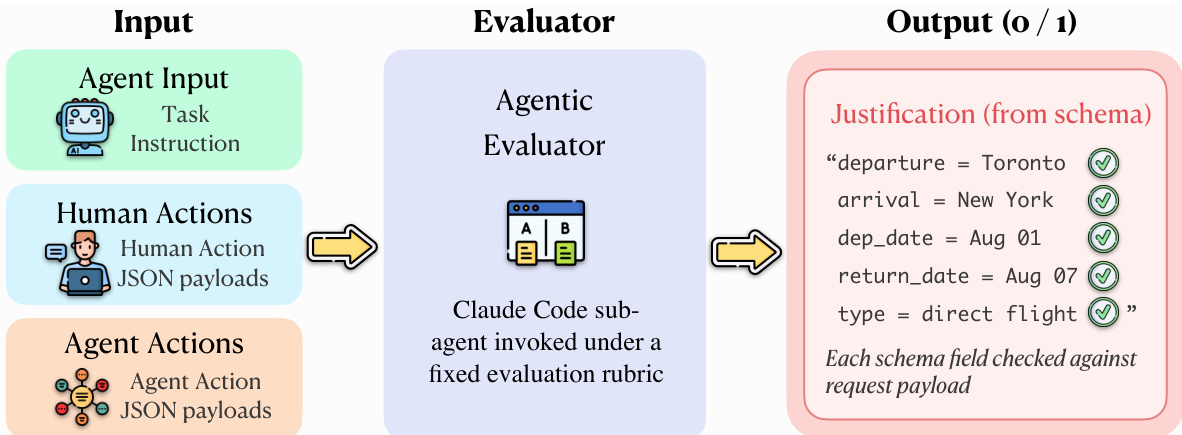
Usage in Evaluation: The dataset is used to evaluate AI agents by comparing their full behavioral trajectories against human ground-truth references. An Agentic Evaluator performs step-level alignment across the five multimodal layers to determine success, enabling deep diagnostic traceability to identify exactly where an agent's reasoning or actions diverged from the human reference.
Method
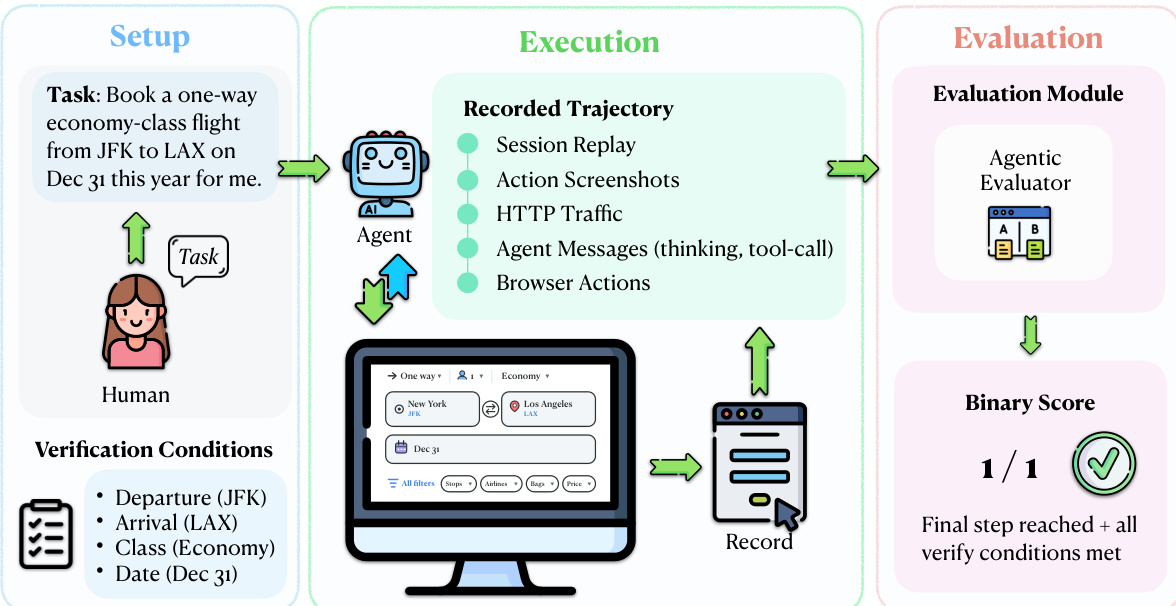
The authors leverage a real-world evaluation framework centered on a multi-layered trajectory comparison between agent and human executions. The core of this approach is the interception mechanism, which enables safe and ecologically valid evaluation by capturing only the final request of a task without allowing it to reach the server. Refer to the framework diagram, which illustrates the overall process from task setup to evaluation. This mechanism is implemented via a lightweight Chrome extension and a Chrome DevTools Protocol (CDP) server that monitors outgoing HTTP requests. When an agent action triggers a request matching a human-annotated URL pattern and HTTP method, the system captures the full request payload—including form fields, headers, and query parameters—blocks the request from reaching the server, and logs it locally with a timestamp and tab URL. All other requests, such as page loads and dynamic content fetches, pass through unmodified, preserving the agent's interaction experience.
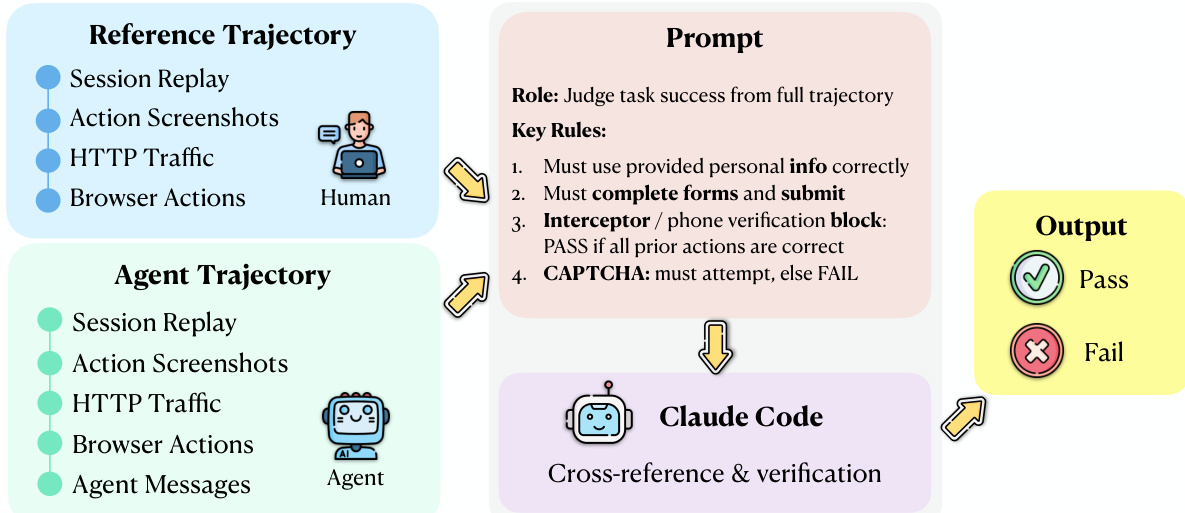
The evaluation protocol operates on five synchronized evidence streams derived from both the agent and a human reference trajectory: session replay, screenshots, HTTP traffic, browser actions, and agent messages. As shown in the figure below, the evaluation module uses an Agentic Evaluator, implemented as a Claude Code sub-agent, to perform an explicit alignment between the agent and human trajectories. This evaluator receives the task instruction, the agent trajectory, and the human reference trajectory as input and applies a fixed evaluation rubric to determine task success. The evaluation process involves identifying corresponding steps, detecting divergences, verifying that required fields and actions are correct, and confirming that the agent reaches a terminal state equivalent to the human reference.
The Agentic Evaluator produces a binary verdict for each task, indicating success or failure. For a task t, let q(t) denote the task instruction, Ta(t) the agent trajectory, and Th(t) the human reference trajectory. The evaluator A maps these inputs to a binary task-level verdict: Score(t)=A(q(t),Ta(t),Th(t)), where Score(t)∈{0,1}, with 1 indicating successful task completion. The overall success rate over a task set T is then defined as SR=∣T∣1∑t∈TScore(t), where ∣T∣ is the number of evaluated tasks. This comparative evaluation design leverages the full multi-layer recordings and grounds success determination in a concrete human demonstration, avoiding reliance on potentially ambiguous task instructions alone.
The Agentic Evaluator operates by invoking a Claude Code sub-agent under a fixed evaluation rubric. The input to the evaluator includes the task instruction, human action payloads, and agent action payloads. The evaluator compares the agent's execution against the human reference trajectory, which consists of session replay, action screenshots, HTTP traffic, and browser actions. The evaluation process involves cross-referencing the agent's trajectory with the human reference and verifying specific conditions, such as correct form completion and submission. The output is a binary score with a structured justification, indicating whether the final step was reached and all verification conditions were met.
The evaluation module also includes a verification component that checks the agent's actions against the human reference trajectory. The evaluation process involves identifying corresponding steps, detecting divergences, and verifying that required fields and actions are correct. The Agentic Evaluator produces a binary verdict for each task, indicating success or failure. The overall success rate over a task set T is then defined as SR=∣T∣1∑t∈TScore(t), where ∣T∣ is the number of evaluated tasks. This comparative evaluation design leverages the full multi-layer recordings and grounds success determination in a concrete human demonstration, avoiding reliance on potentially ambiguous task instructions alone.
Experiment
The CLAWBENCH benchmark evaluates the ability of frontier AI models to complete everyday online tasks by allowing them to operate on live, production websites rather than static sandboxes. By comparing agent trajectories against human ground-truth references through an agentic evaluator, the study validates how well models handle real-world complexities like dynamic content and multi-step workflows. The findings reveal that even the strongest models struggle significantly with these live environments, showing highly inconsistent performance across different life categories and failing to match their success rates on traditional, controlled benchmarks.
The authors evaluate several frontier AI models on CLAWBENCH, a benchmark that assesses task completion on live websites with real-world complexity. Results show that models perform significantly worse on CLAWBENCH compared to traditional sandboxed benchmarks, indicating the increased difficulty of real-world web tasks. Models achieve substantially lower success rates on CLAWBENCH compared to traditional benchmarks Performance varies significantly across different task categories, with no single model excelling uniformly The strongest model completes only a minority of tasks on CLAWBENCH, highlighting the challenge of real-world web interaction
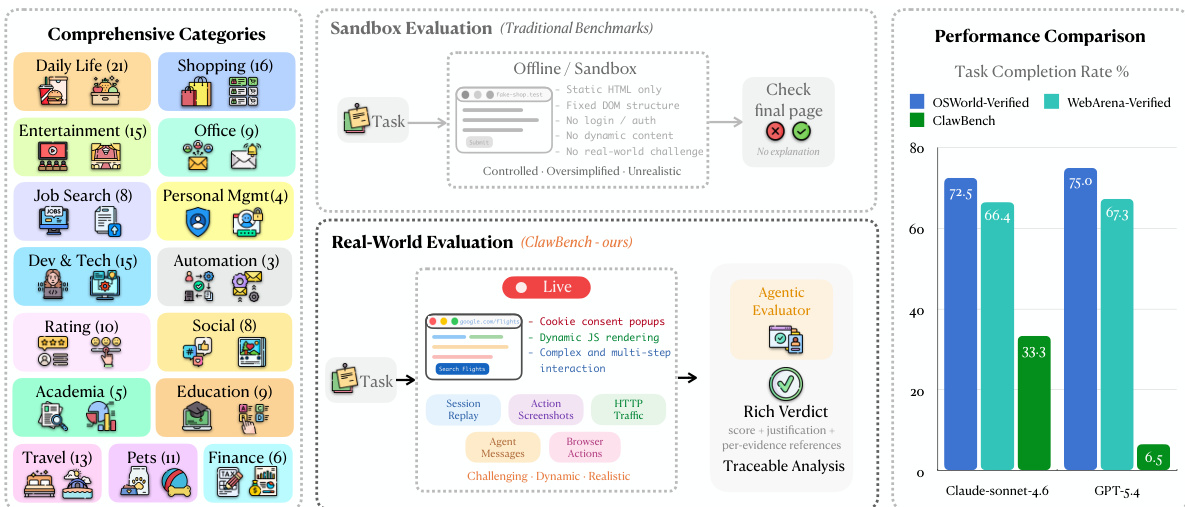
The authors present CLAWBENCH, a benchmark that evaluates AI agents on real-world web tasks using a live environment and a multi-layered data recording system. Results show that even the strongest models achieve low success rates, indicating significant challenges in handling everyday online workflows. CLAWBENCH evaluates agents on live websites with real-world complexity, unlike existing benchmarks that use offline sandboxes. The benchmark uses a multi-layer data recording system to capture detailed agent behavior and enable traceable evaluation. Even the top-performing model achieves a low success rate, highlighting the difficulty of real-world web tasks compared to traditional benchmarks.
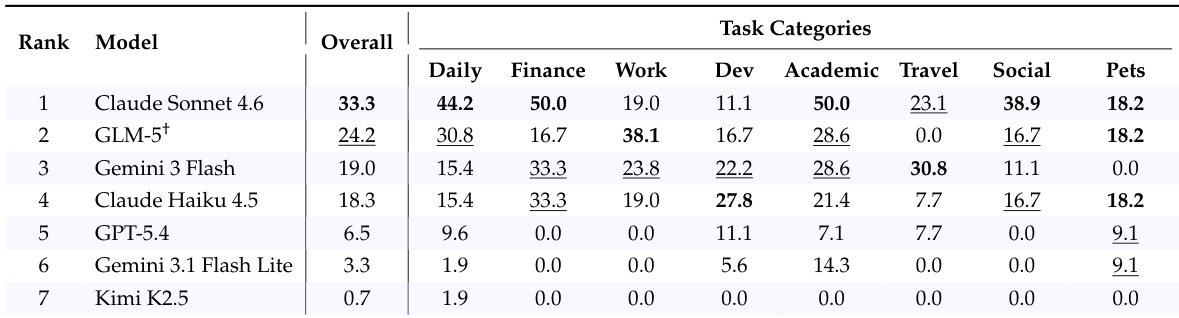
The authors evaluate seven frontier AI models on CLAWBENCH, a benchmark of real-world web tasks, and report overall and category-specific success rates. Results show that the strongest model achieves only moderate success overall, with significant variation across task categories, indicating persistent challenges in real-world web interaction. The top model achieves a 33.3% overall success rate on real-world web tasks Performance varies widely across task categories, with no model excelling uniformly Even the best-performing model shows substantial room for improvement in most domains
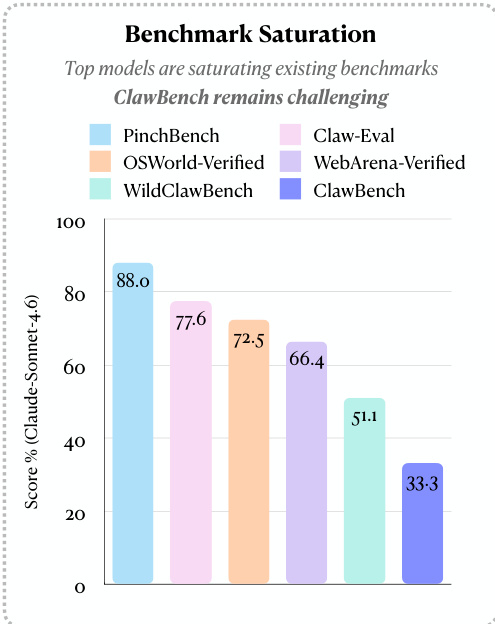
The authors compare model performance across different benchmarks, showing that top models achieve high scores on established benchmarks but significantly lower scores on CLAWBENCH. This indicates that CLAWBENCH remains challenging despite model improvements on other platforms. Top models achieve high success rates on established benchmarks but much lower rates on CLAWBENCH CLAWBENCH presents a more difficult evaluation due to real-world web complexity Performance varies across benchmarks, with CLAWBENCH showing the lowest scores for the same models
The authors evaluate seven frontier models on the CLAWBENCH benchmark, which assesses AI agents on real-world web tasks. Results show that the top-performing model achieves a success rate of 33.3%, with significant variation across models and task categories. Claude Sonnet 4.6 achieves the highest success rate among the evaluated models. Performance varies widely across models, with the top model outperforming others by a substantial margin. Model strengths differ by task category, indicating uneven competence across domains.
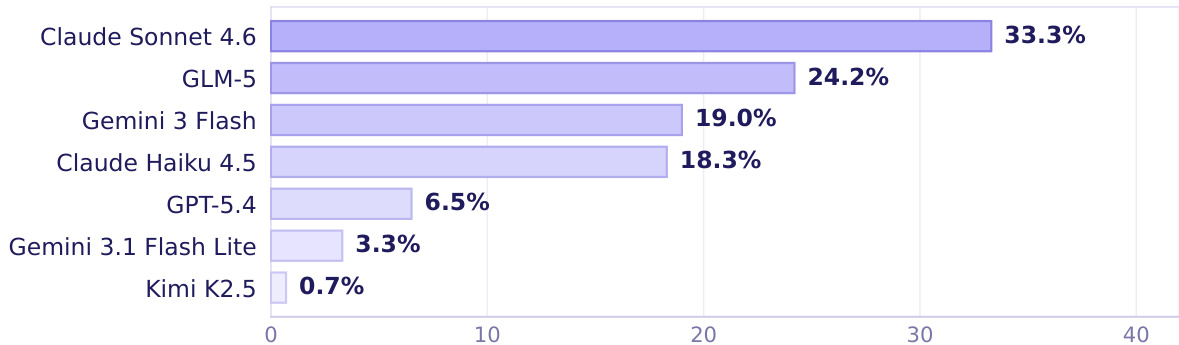
The authors evaluate several frontier AI models using CLAWBENCH, a benchmark designed to assess task completion within complex, live web environments rather than traditional sandboxed settings. The results demonstrate that current models struggle significantly with real-world web interactions, performing much worse on this benchmark than on established offline platforms. Even the strongest models show inconsistent success across different task categories, highlighting a substantial gap in the ability of AI agents to handle everyday online workflows.