Command Palette
Search for a command to run...
ActiveGlasses: Erlernen von Manipulation durch Active Vision aus egozentrischen menschlichen Demonstrationen
ActiveGlasses: Erlernen von Manipulation durch Active Vision aus egozentrischen menschlichen Demonstrationen
Yanwen Zou Chenyang Shi Wenyu Yu Han Xue Jun Lv Ye Pan Chuan Wen Cewu Lu
Zusammenfassung
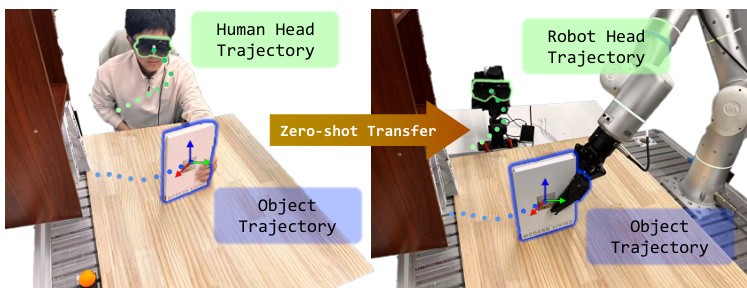
Die groß angelegte Erfassung von Robotendaten unter realen Bedingungen ist eine Grundvoraussetzung für den Einsatz von Robotern im Alltag. Bestehende Pipelines stützen sich jedoch häufig auf spezialisierte Handgeräte, um die Diskrepanz zwischen der menschlichen Morphologie und der robotergestützten Verkörperung (embodiment gap) zu überbrücken. Dies erhöht nicht nur die Belastung für die Bediener und schränkt die Skalierbarkeit ein, sondern erschwert auch die Erfassung der natürlich koordinierten Wahrnehmungs- und Manipulationsabläufe menschlicher Interaktionen. Diese Herausforderung erfordert ein natürlicheres System, das menschliche Manipulations- und Wahrnehmungsverhaltensweisen originalgetreu erfassen kann und gleichzeitig einen Zero-Shot-Transfer auf Roboterplattformen ermöglicht.Wir stellen ActiveGlasses vor, ein System zum Erlernen der Roboter-Manipulation aus egozentrischen menschlichen Demonstrationen mittels active vision. Eine an einer Smart-Glass montierte Stereokamera dient dabei als einziges Wahrnehmungsgerät sowohl für die Datenerfassung als auch für die policy inference: Der Bediener trägt sie während der Demonstrationen mit bloßen Händen, und dieselbe Kamera wird während des Einsatzes an einem 6-DoF-Perzeptionsarm montiert, um die aktive menschliche Wahrnehmung (active vision) zu reproduzieren. Um den Zero-Shot-Transfer zu ermöglichen, extrahieren wir Objekttrajektorien aus den Demonstrationen und verwenden eine objektzentrierte Punktwolken-Policy (object-centric point-cloud policy), um die Manipulation und die Kopfbewegungen gemeinsam vorherzusagen.Bei mehreren anspruchsvollen Aufgaben, die Okklusionen und präzise Interaktionen beinhalten, erreicht ActiveGlasses einen Zero-Shot-Transfer mit active vision, übertrifft bei identischem Hardware-Setup konsistent starke Baselines und generalisiert über zwei verschiedene Roboterplattformen hinweg.
One-sentence Summary
ActiveGlasses is a system that learns robot manipulation from ego-centric human demonstrations using smart glasses and an object-centric point-cloud policy to jointly predict manipulation and head movement, enabling zero-shot transfer of coordinated perception-manipulation behaviors across multiple robot platforms.
Key Contributions
- The paper introduces ActiveGlasses, a system that utilizes smart glasses with a mounted stereo camera to capture human manipulation and perception behaviors through natural, ego-centric demonstrations.
- The method employs an object-centric point-cloud policy that extracts object trajectories to jointly predict both manipulation actions and head movements, enabling the robot to reproduce human-like active vision.
- Experimental results demonstrate that the system achieves zero-shot transfer across two different robot platforms and consistently outperforms strong baselines in challenging tasks involving occlusion and precise interaction.
Introduction
Scaling robot deployment requires large-scale real-world data collection, yet current imitation learning pipelines often rely on heavy handheld devices or VR headsets that impose physical burdens on operators and fail to capture natural human perception. While existing methods use wrist-mounted cameras, they lack the ability to perform human-like active sensing, and previous attempts to use smart glasses often treat head movements as noise rather than a useful signal for task completion. The authors leverage a smart glasses-based system called ActiveGlasses to collect ego-centric human demonstrations that incorporate both manipulation and active vision. By extracting object trajectories and utilizing an object-centric point-cloud policy, the authors enable a robot to jointly predict manipulation actions and 6-DoF head movements, achieving zero-shot transfer across different robotic platforms.
Dataset
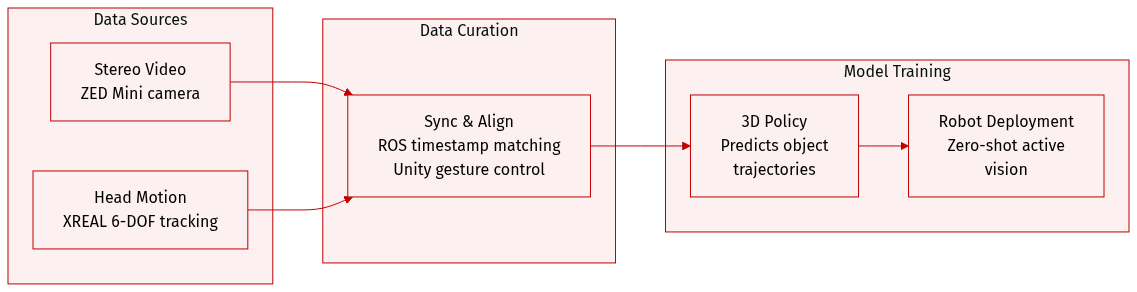
The authors utilize a custom-collected dataset designed to capture egocentric stereo video and 6-DOF head movement data. The dataset details are as follows:
- Data Sources and Hardware: The collection system integrates XREAL Air 2 Ultra glasses with a ZED Mini stereo camera. The XREAL glasses provide high-frequency 6-DOF pose tracking for head movements, while the ZED Mini serves as the primary source for stereo video streams.
- Data Composition: Each recorded episode consists of synchronized stereo camera frames and 6-DOF head poses. The authors use the XREAL system for motion tracking rather than the ZED Mini IMU due to its superior sampling frequency and stability.
- Processing and Synchronization: Data timestamps are aligned using the Robot Operating System (ROS). To facilitate data collection, the authors developed a Unity-based user interface that detects user gestures to signal the start and end of each episode, providing audio feedback to the operator.
- Usage in Model Training: The data is used to train an object-centric 3D policy. This policy is designed to predict future 6-DOF object trajectories in task space. During inference, the trained policy is deployed zero-shot on a 6-DOF robotic arm that synchronously executes the recorded head motions to reproduce active vision.
Method
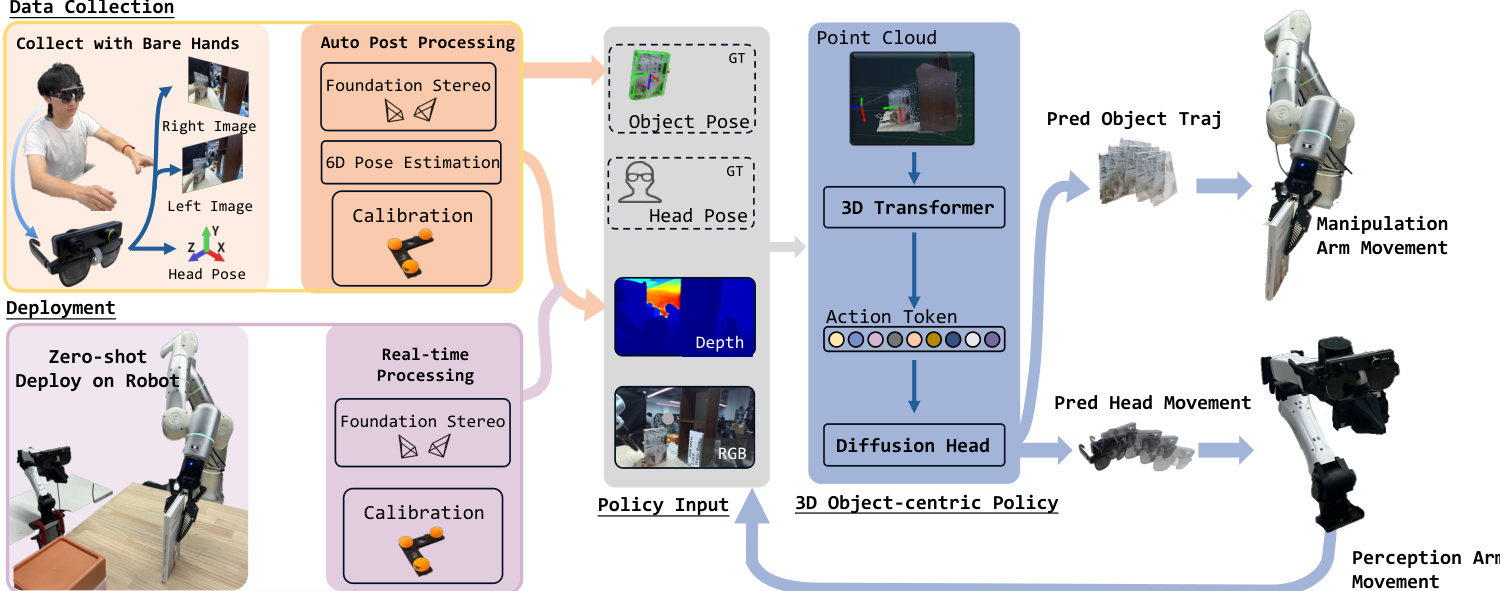
The authors leverage a multi-stage pipeline to process stereo video and head trajectory data into a unified representation suitable for policy learning, enabling zero-shot transfer from human demonstrations to robotic execution. The overall framework begins with data collection using a ZED Mini stereo camera mounted on smart glasses, as shown in the figure below. The system processes left-eye and right-eye video streams along with the head trajectory to generate per-frame depth maps, object and hand masks, and ground-truth object trajectories in the camera frame. This data is then used to calibrate the system and transform the reconstructed point cloud into a consistent world frame.
Depth estimation is performed using FoundationStereo on each stereo image pair to generate depth maps, which are back-projected into a camera-frame point cloud. To eliminate human-specific artifacts, the operator’s hands are segmented using Grounded-SAM, and their corresponding points are removed from the point cloud. The manipulated object is segmented using SAM2 to obtain a mask, which is then used in conjunction with the depth map and left-view image to estimate the object’s 6-DoF pose via FoundationPose. This yields the object trajectory in the camera frame, which is enhanced with a geometric prior from the object mesh.
Calibration is achieved by placing three orange spheres on the tabletop to define a planar coordinate system. Using the first frame, the 3D positions of the sphere centers are computed from their pixel locations and depth values, enabling the construction of a world frame with axes derived from the relative positions of the spheres. The initial camera-to-world transformation is computed, and subsequent transformations are propagated using head-pose relative motion, ensuring the point cloud remains in a unified world frame throughout the episode.
The policy design operates in three stages: pre-grasp, motion planning, and termination. For motion planning, the authors adopt an object-centric policy that takes the world-frame point cloud as input and predicts both the target object trajectory and the robot's head movement. As shown in the framework diagram, the policy employs a 3D Transformer to process the point cloud and generate action tokens, which are then fed into two diffusion heads. One head predicts the absolute object trajectory to maintain task focus, while the other predicts the relative head movement trajectory to prevent inverse kinematics failures due to varying initial states. The policy output includes a termination signal, with the last five frames of each episode labeled as task completion.
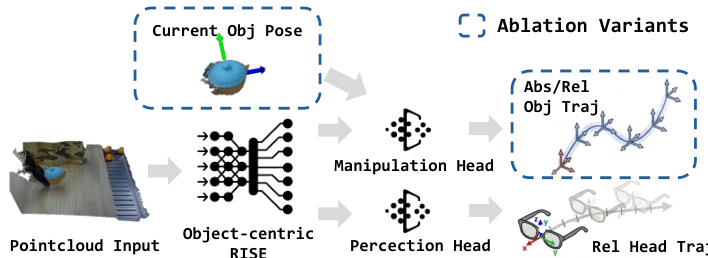
The final actions are derived by transforming the predicted object pose into the end-effector frame using camera calibration. The ablation study highlights the importance of using an absolute representation for object trajectory and a relative one for head movement, as shown in the figure below. This design ensures robustness and generalization across different initial configurations and viewpoints.
Experiment
The experiments evaluate the ActiveGlasses system through real-world tasks involving occlusion and precision, such as book placement and bread insertion, to validate its scalability, active vision capabilities, policy design, and cross-embodiment potential. Results demonstrate that bare-hand data collection with head-mounted glasses is more efficient and user-friendly than traditional teleoperation, while active vision significantly improves success rates in occluded scenarios compared to fixed camera setups. Furthermore, the object-centric 3D policy enables successful zero-shot transfer across different robotic platforms by predicting object trajectories rather than specific joint movements.
The experiment evaluates different policy designs for object trajectory prediction, comparing absolute and relative representations with and without current object pose conditioning. Results show that absolute trajectory prediction performs better than relative, and adding current pose as a condition degrades performance. Absolute trajectory prediction outperforms relative prediction in policy performance. Including current object pose as a conditioning signal reduces policy effectiveness. Relative trajectory prediction leads to performance drops and increased system complexity.

The authors evaluate ActiveGlasses on three real-world tasks involving occlusion and precision manipulation. Results show that ActiveGlasses achieves higher success rates compared to baselines across all tasks and stages, particularly in scenarios requiring active vision. The system demonstrates robust performance in handling occluded and distant visual inputs. ActiveGlasses outperforms baselines in all tasks and stages, especially in occluded scenarios. The method achieves higher success rates in tasks requiring active vision compared to fixed camera setups. ActiveGlasses shows consistent performance across different robotic platforms, demonstrating cross-embodiment capabilities.

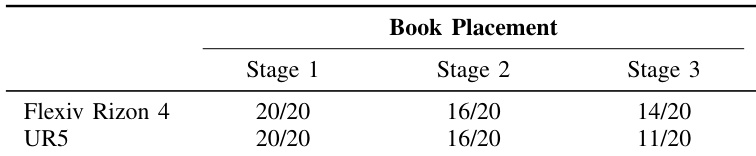
The authors compare the performance of two robotic arms on the book placement task across three stages. Results show that both robots achieve similar success rates in the initial stages, but the UR5 exhibits more failures in the final stage, likely due to workspace limitations. Both robots perform equally well in the first two stages of book placement. The UR5 shows lower success rates in the final stage compared to Flexiv Rizon 4. Performance differences are attributed to workspace constraints of the UR5 robot.
The experiments evaluate policy design choices for trajectory prediction, the effectiveness of ActiveGlasses in real-world manipulation tasks, and the cross-embodiment performance of different robotic arms. Findings indicate that absolute trajectory representations outperform relative ones, while ActiveGlasses demonstrates superior robustness in occluded scenarios and across various robotic platforms. Additionally, while different robotic arms perform similarly in initial task stages, workspace constraints can lead to performance variations in later stages.