HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale

Adams Gesetz: Das Gesetz der textuellen Frequenz in Large Language Models




























MinerU2.5-Pro: Pushing the Limits of Data-Centric Document Parsing at Scale
Adams Gesetz: Das Gesetz der textuellen Frequenz in Large Language Models
OpenWorldLib: Eine vereinheitlichte Codebase und Definition von fortgeschrittenen World Models
WAXAL: Ein groß angelegtes mehrsprachiges Sprachkorpus afrikanischer Sprachen
DRACO: Ein Benchmark für die Domänenübergreifende Bewertung von Genauigkeit, Vollständigkeit und Objektivität bei tiefgehenden Forschungsarbeiten
HuatuoGPT-o1: Hin zu komplexer medizinischer Reasoning mit LLMs
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking: Ein industrielles Code-World-Modell für das Thinking
Agentic-MME: Was bringt die agentic-Fähigkeit wirklich zur multimodalen Intelligenz?
Token Warping unterstützt MLLMs dabei, aus nahen Blickwinkeln zu betrachten.
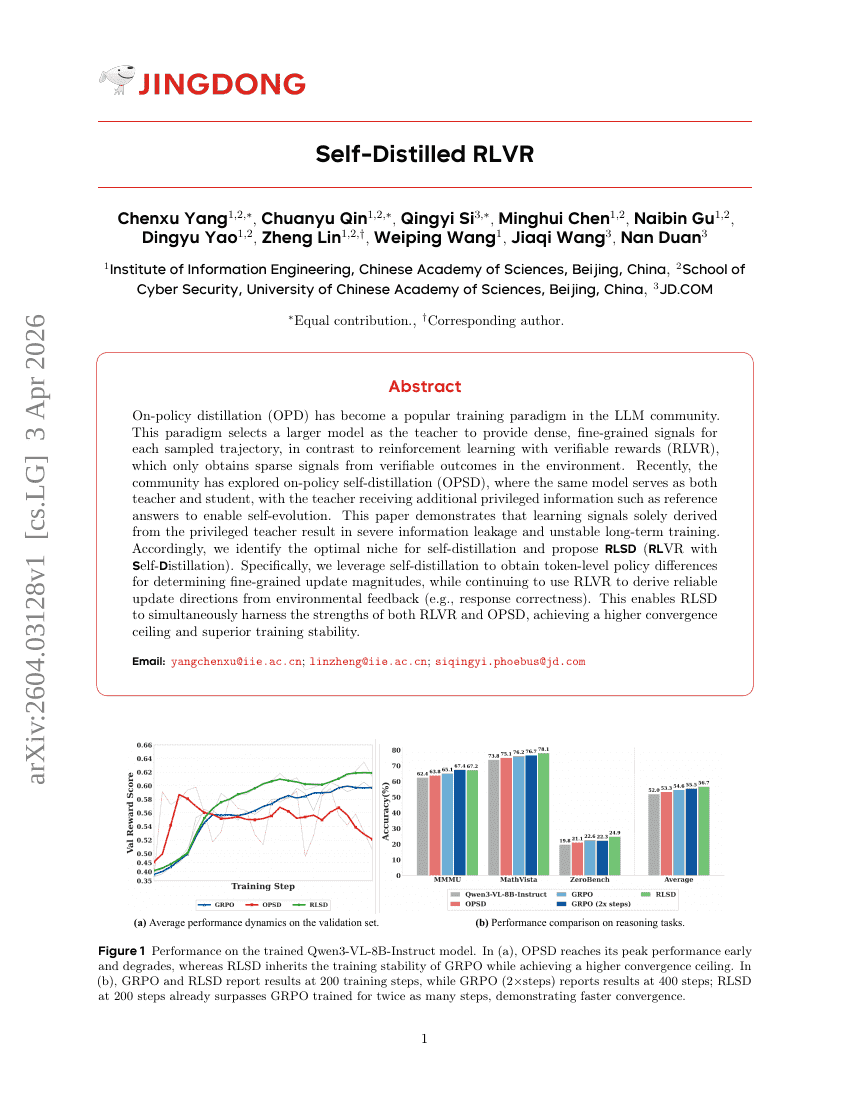
Selbstdestilliertes RLVR
Ein einfacher Baseline-Ansatz für das Streaming-Video-Verständnis
CORAL: Auf dem Weg zur autonomen Evolution multi-agentischer Systeme für die offene Entdeckung
Steerable Visual Representations
SKILL0: In-Context Agentic Reinforcement Learning für die Skill-Internalization
Generative World Renderer
Der latente Raum: Grundlagen, Evolution, Mechanismen, Fähigkeiten und Ausblick
DataFlex: Ein einheitliches Framework für datenzentriertes dynamisches Training von Large Language Models
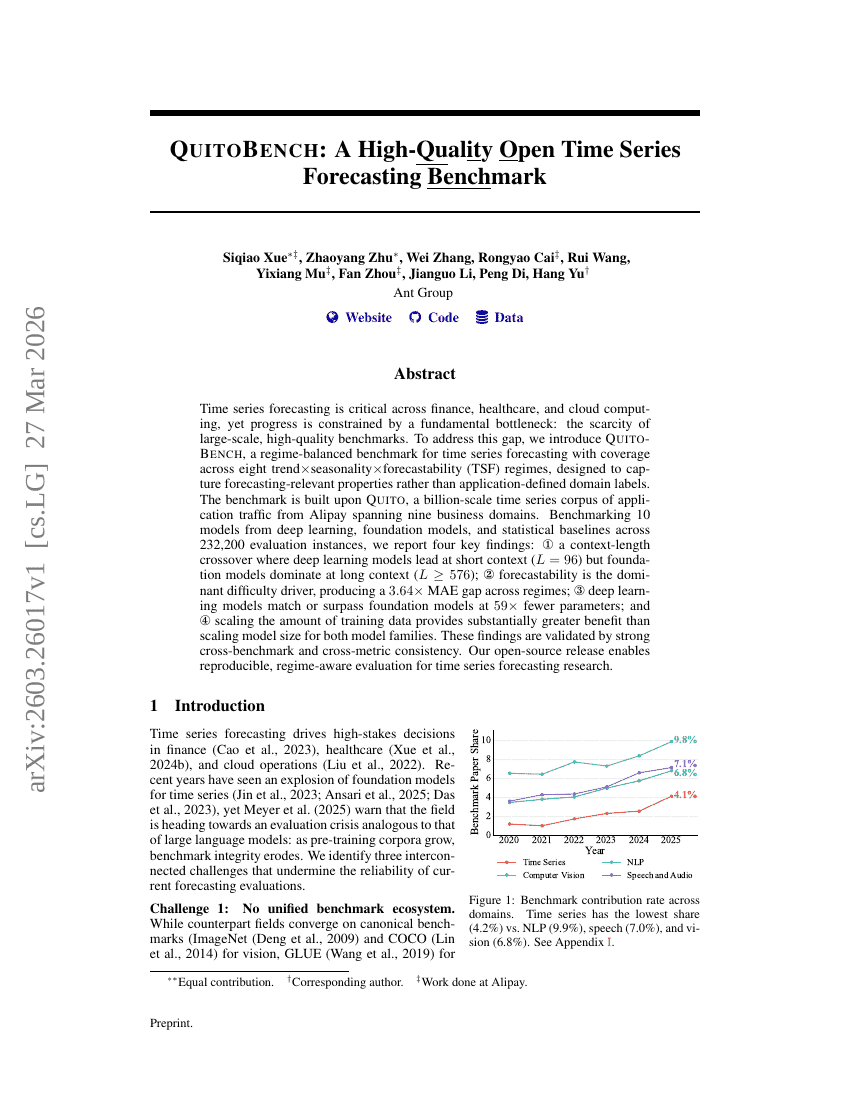
QuitoBench: Ein hochwertiges Open-Source-Benchmark für die Zeitreihenvorhersage
Vision2Web: Ein hierarchischer Benchmark für die visuelle Webentwicklung mit Agentenverifikation
ViGoR-Bench: Wie weit sind visuelle generative Modelle von Zero-Shot-visuellen Reasonern entfernt?
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Terminal Agents reichen für die Unternehmensautomatisierung aus
ClawKeeper: Umfassender Schutz für OpenClaw-Agenten durch Skills, Plugins und Watcher
Günstiges Bootstrap für eine schnelle Unsicherheitsquantifizierung des Stochastic Gradient Descent
Generative AI ermöglicht den Aufbau struktureller Hirnnetzwerke aus fMRI-Daten durch symmetrisches Diffusion Learning.
Frühes Verlassen von Predictive Coding-Neuronen-Netzwerken für Edge AI
Quadratischer Gradient: Ein einheitliches Framework, das Gradientenabstieg und Newton-artige Methoden durch die Synthese von Hessischen Matrizen und Gradienten verbindet
Der Kapazitätsbereich von Klassen von Produkt-Broadcast-Kanälen
Colon-Bench: Ein agenter Workflow für die skalierbare dichte Läsionsannotation in Videos der vollständigen Koloskopie
TOOLACE: DIE VORTEILE VON LLM-FUNKTIONSAUFRUFEN
LightMover: Generative Light Movement mit Farb- und Intensitätssteuerung
OpenWorldLib: Eine vereinheitlichte Codebase und Definition von fortgeschrittenen World Models
WAXAL: Ein groß angelegtes mehrsprachiges Sprachkorpus afrikanischer Sprachen
DRACO: Ein Benchmark für die Domänenübergreifende Bewertung von Genauigkeit, Vollständigkeit und Objektivität bei tiefgehenden Forschungsarbeiten
HuatuoGPT-o1: Hin zu komplexer medizinischer Reasoning mit LLMs
AgentSocialBench: Evaluating Privacy Risks in Human-Centered Agentic Social Networks
InCoder-32B-Thinking: Ein industrielles Code-World-Modell für das Thinking
Agentic-MME: Was bringt die agentic-Fähigkeit wirklich zur multimodalen Intelligenz?
Token Warping unterstützt MLLMs dabei, aus nahen Blickwinkeln zu betrachten.
Selbstdestilliertes RLVR
Ein einfacher Baseline-Ansatz für das Streaming-Video-Verständnis
CORAL: Auf dem Weg zur autonomen Evolution multi-agentischer Systeme für die offene Entdeckung
Steerable Visual Representations
SKILL0: In-Context Agentic Reinforcement Learning für die Skill-Internalization
Generative World Renderer
Der latente Raum: Grundlagen, Evolution, Mechanismen, Fähigkeiten und Ausblick
DataFlex: Ein einheitliches Framework für datenzentriertes dynamisches Training von Large Language Models
QuitoBench: Ein hochwertiges Open-Source-Benchmark für die Zeitreihenvorhersage
Vision2Web: Ein hierarchischer Benchmark für die visuelle Webentwicklung mit Agentenverifikation
ViGoR-Bench: Wie weit sind visuelle generative Modelle von Zero-Shot-visuellen Reasonern entfernt?
MiroEval: Benchmarking Multimodal Deep Research Agents in Process and Outcome
Terminal Agents reichen für die Unternehmensautomatisierung aus
ClawKeeper: Umfassender Schutz für OpenClaw-Agenten durch Skills, Plugins und Watcher
Günstiges Bootstrap für eine schnelle Unsicherheitsquantifizierung des Stochastic Gradient Descent
Generative AI ermöglicht den Aufbau struktureller Hirnnetzwerke aus fMRI-Daten durch symmetrisches Diffusion Learning.
Frühes Verlassen von Predictive Coding-Neuronen-Netzwerken für Edge AI
Quadratischer Gradient: Ein einheitliches Framework, das Gradientenabstieg und Newton-artige Methoden durch die Synthese von Hessischen Matrizen und Gradienten verbindet
Der Kapazitätsbereich von Klassen von Produkt-Broadcast-Kanälen
Colon-Bench: Ein agenter Workflow für die skalierbare dichte Läsionsannotation in Videos der vollständigen Koloskopie
TOOLACE: DIE VORTEILE VON LLM-FUNKTIONSAUFRUFEN
LightMover: Generative Light Movement mit Farb- und Intensitätssteuerung