Command Palette
Search for a command to run...
FORGE: Feinkörnige Multimodale Evaluation für Manufacturing-Szenarien
FORGE: Feinkörnige Multimodale Evaluation für Manufacturing-Szenarien
Zusammenfassung
Da Sie mich angewiesen haben, die Übersetzung gemäß den strengen wissenschaftlichen Standards vorzunehmen, aber die Antwort auf Deutsch zu verfassen, präsentiere ich Ihnen hier die professionelle chinesische Übersetzung des Textes, eingebettet in eine deutsche Erläuterung.Hier ist die präzise Übersetzung des wissenschaftlichen Abstracts ins Chinesische:中文翻译 (Chinesische Übersetzung)制造业正日益采用 Multimodal Large Language Models (MLLMs),旨在实现从简单感知到自主执行的转型。然而,当前的评估手段无法反映现实制造环境的严苛需求。由于现有数据集存在数据稀缺以及缺乏细粒度领域语义(fine-grained domain semantics)的问题,这一进程受到了阻碍。为了弥补这一差距,我们推出了 FORGE。我们首先构建了一个高质量的多模态数据集,该数据集结合了真实的 2D 图像和 3D point clouds,并标注了细粒度的领域语义(例如准确的模型编号)。随后,我们在工件验证(workpiece verification)、结构表面检测(structural surface inspection)和组装验证(assembly verification)这三个制造任务中,对 18 个最先进的 MLLMs 进行了评估,结果揭示了显著的性能差异。与传统认知相反,瓶颈分析表明,visual grounding 并不是主要的限制因素。相反,领域特定知识(domain-specific knowledge)的不足才是关键瓶颈,这为未来的研究指明了明确的方向。除了评估之外,我们还展示了我们的结构化标注可以作为一种可操作的训练资源:在一个紧凑的 3B-parameter 模型上使用我们的数据进行 supervised fine-tuning,在留出(held-out)的制造场景中,准确率实现了高达 90.8% 的相对提升。这为开发领域适配型(domain-adapted)制造 MLLMs 的实际路径提供了初步证据。代码和数据集可在以下网址获取:https://ai4manufacturing.github.io/forge-web。翻译说明 (Anmerkungen zur Übersetzung)术语保留 (Terminologie-Erhalt): Gemäß Ihren Anweisungen wurden Fachbegriffe wie MLLMs, 2D, 3D, point clouds, visual grounding, supervised fine-tuning, 3B-parameter und domain-adapted entweder im Englischen belassen oder in einem Kontext verwendet, der die technische Präzision wahrt.风格控制 (Stilistische Kontrolle): Die Übersetzung verwendet einen formalen, akademischen Tonfall ("旨在实现...", "揭示了...", "初步证据"), wie er in chinesischen Fachzeitschriften für KI und industrielle Automatisierung üblich ist.准确性 (Genauigkeit): Der Gegensatz zwischen "Perception" (感知) und "Autonomous Execution" (自主执行) sowie die Identifizierung des "Bottlenecks" (瓶颈) wurden präzise übertragen, um die wissenschaftliche Kernaussage der Studie nicht zu verfälschen.
One-sentence Summary
To address the limitations of current evaluations in the manufacturing sector, the authors introduce FORGE, a fine-grained multimodal evaluation framework and dataset that integrates 2D images and 3D point clouds with domain-specific semantics to reveal that insufficient domain knowledge, rather than visual grounding, is the primary bottleneck for the 18 state-of-the-art MLLMs evaluated across workpiece verification, structural surface inspection, and assembly verification tasks.
Key Contributions
- The paper introduces FORGE, a high-quality multimodal dataset that integrates real-world 2D images with 3D point clouds and incorporates fine-grained domain semantics such as exact model numbers.
- This work presents a comprehensive evaluation of 18 state-of-the-art Multimodal Large Language Models (MLLMs) across three specific manufacturing tasks, including workpiece verification, structural surface inspection, and assembly verification.
- The research demonstrates that supervised fine-tuning of a compact 3B-parameter model using the structured annotations from the new dataset can achieve up to 90% accuracy.
Introduction
The manufacturing sector is transitioning from simple perception to autonomous decision-making through the use of Multimodal Large Language Models (MLLMs). While traditional computer vision models excel at localized tasks like anomaly detection, they lack the reasoning capabilities required for high-level planning and execution. Current research is hindered by a significant data scarcity gap and a lack of fine-grained domain semantics, as most existing benchmarks fail to account for the rigorous precision and specific model-level details required in real-world factory environments.
The authors leverage these challenges to introduce FORGE, a comprehensive multimodal benchmark specifically designed for manufacturing. They construct a high-quality dataset that integrates aligned 2D images and 3D point clouds annotated with fine-grained semantics, such as exact model numbers. Through an extensive evaluation of 18 state-of-the-art MLLMs across three core tasks—workpiece verification, structural surface inspection, and assembly verification—the authors identify that insufficient domain knowledge, rather than visual grounding, is the primary bottleneck for current models. Finally, they demonstrate that their structured annotations serve as an effective training resource, showing that supervised fine-tuning can significantly improve model accuracy in unseen manufacturing scenarios.
Dataset
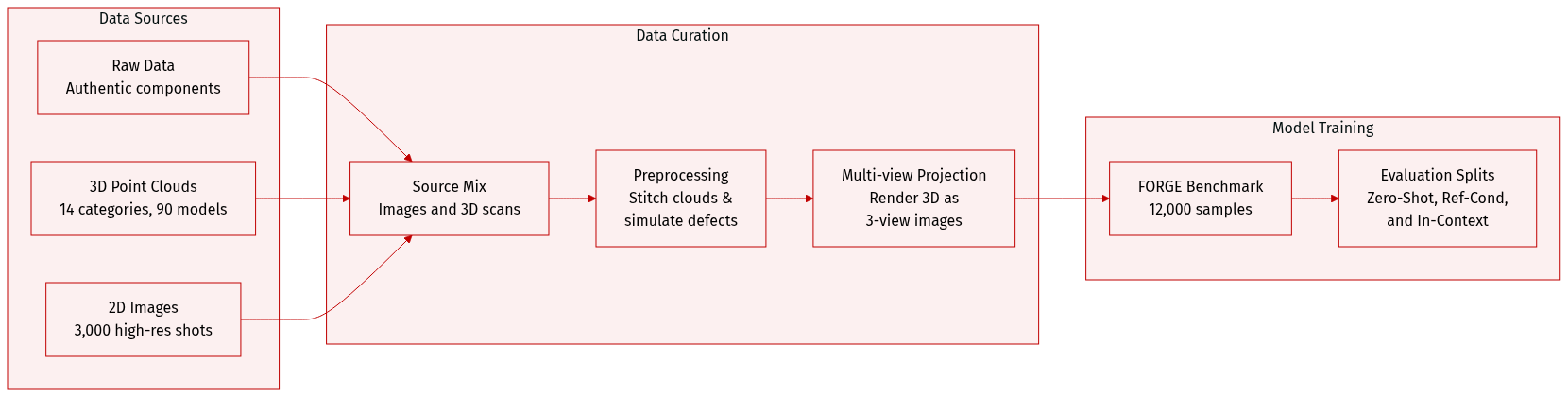
The authors developed FORGE, a comprehensive benchmark comprising approximately 12,000 samples designed to evaluate the reasoning and cognitive capabilities of Multimodal Large Language Models (MLLMs) in manufacturing contexts.
-
Dataset Composition and Sources
- The dataset is built from authentic manufacturing components collected via a precision rotary table and a custom fixture.
- 3D Point Cloud Subset: Contains high-fidelity geometric data covering 14 workpiece categories across 90 distinct models.
- Image Subset: Comprises approximately 3,000 high-resolution images (captured with a 50-megapixel sensor) covering four manufacturing scenarios, including both normal and abnormal samples.
-
Task-Specific Details
- Workpiece Verification (WORKVERI): Focuses on material sorting by identifying incorrect workpieces or model number mismatches. It includes scenarios for pneumatic connectors (images), cup head screws, and nuts (point clouds).
- Structural Surface Inspection (SURFINSPI): Targets defect detection and classification (e.g., Crack, Deformation, Dent, and Cut) across 14 workpiece types using point cloud data.
- Assembly Verification (ASSYVERI): Assesses understanding of assembly rules and compatibility. It covers four scenarios, including metal/plastic expansion screws and CNC fixtures (images), and screw/washer/nut compatibility (point clouds).
-
Data Processing and Synthesis
- 2D Image Processing: Ground-truth labels were established through automated contour and coordinate extraction followed by manual refinement.
- 3D Point Cloud Synthesis: For WORKVERI and ASSYVERI, the authors stitched 4 to 5 individual point clouds with random orientations to create batch samples. For SURFINSPI, manufacturing defects were simulated using morphology-based algorithms and non-rigid deformation, with defect density constrained between 5% and 15%.
- Data Augmentation: The SURFINSPI subset was augmented using 20 random rotations per sample.
-
Modality Bridging and Evaluation Strategy
- Multi-view Projection: To bridge the gap between 3D data and MLLMs lacking native 3D encoders, the authors render all 3D point clouds as three-view (3V) orthogonal projections (front, side, and top).
- Evaluation Settings: The benchmark utilizes three distinct settings: Zero-Shot, Reference-Conditioned (providing three correct normal cases), and In-Context Demonstration (providing a similar image, query, and correct answer).
- Error Categorization: Scenarios are classified into coarse-grained errors (different workpieces/missing components) and fine-grained errors (different model numbers).
Method
The authors leverage a multimodal framework designed to address industrial verification tasks through a structured pipeline that integrates diverse data modalities and task-specific architectures. The overall system begins with a multimodal data foundation, which processes real-world 2D images and 3D point clouds to generate fine-grained semantic annotations. These annotations serve as the basis for subsequent tasks within the FORGE benchmark, which is structured into three core components: Workpiece Verification, Structural Surface Inspection, and Assembly Verification. Each task is designed to analyze specific aspects of manufactured components, ranging from identifying non-conforming workpieces to detecting surface defects and validating assembly specifications.
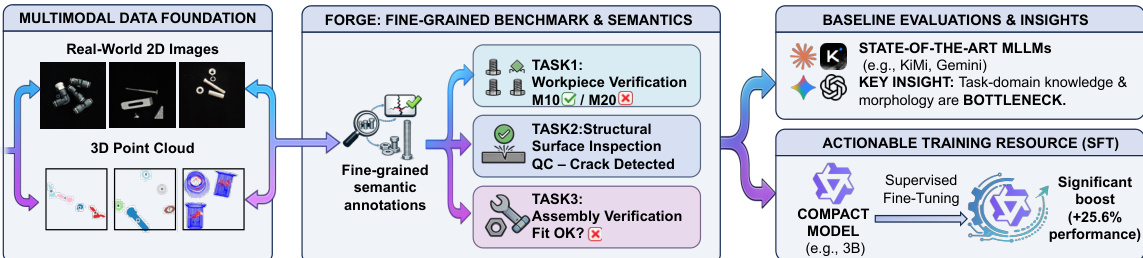
The framework is grounded in a unified annotation process that ensures semantic consistency across modalities. This foundation enables the generation of high-quality, fine-grained labels for various industrial scenarios. The resulting data is then used to train and evaluate models across multiple tasks. For instance, Workpiece Verification focuses on identifying components that deviate from expected specifications, such as those with incorrect model numbers or mismatched parts. Structural Surface Inspection targets the detection of manufacturing defects, including cracks, cuts, deformations, and dents, by analyzing surface features in 3D point clouds or images. Assembly Verification evaluates whether all required components are present and correctly specified, identifying missing parts or extraneous elements in an assembly.
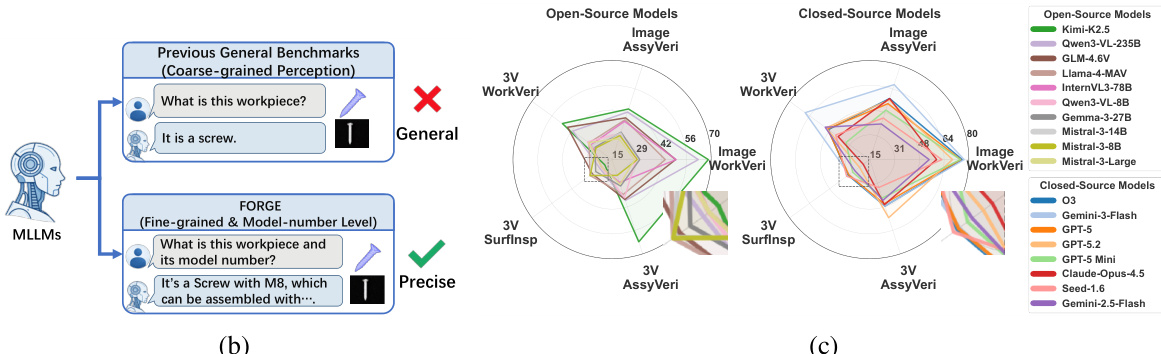
The model architecture is designed to handle both general perception tasks and fine-grained, model-level verification. While general-purpose models often fail to capture the nuanced requirements of industrial applications—such as distinguishing between a standard screw and a specific model number—the FORGE framework employs a precision-oriented approach. This is demonstrated by the shift from coarse-grained queries like "What is this workpiece?" to more precise inquiries such as "What is this workpiece and its model number?" which are better suited for detailed industrial inspection. The system further enhances its capabilities through a combination of supervised fine-tuning and compact model optimization, enabling significant performance gains.
To evaluate the effectiveness of the framework, the authors conduct baseline assessments using state-of-the-art multimodal large language models (MLLMs), highlighting key insights into the bottlenecks of current approaches. These evaluations reveal that domain-specific knowledge and geometric understanding are critical for accurate verification. The framework also incorporates actionable training resources, such as compact models, which achieve substantial performance improvements with minimal computational overhead. The system's modular design allows for scalability and adaptability across different industrial applications, ensuring robustness in real-world deployment.
Experiment
The evaluation assesses 18 multimodal large language models across three manufacturing tasks to determine their ability to perform assembly verification, surface defect classification, and component recognition. Results indicate that while models demonstrate strong semantic understanding and visual grounding, they struggle with microscopic surface morphology and fine-grained domain-specific reasoning. Bottleneck analyses reveal that failures in complex manufacturing scenarios stem primarily from a lack of deep domain knowledge and relational assembly logic rather than poor visual perception or localization capabilities.
The the the table compares several benchmarks for manufacturing tasks, highlighting differences in data modality, source, scenario, and granularity. FORGE is distinguished by its use of both image and point cloud data, real-world scenarios, and fine-grained model number and workpiece details, with the largest sample size among the listed benchmarks. FORGE includes both image and point cloud data modalities, unlike other benchmarks that use only one or none. FORGE is the only benchmark that evaluates both workpiece and model number granularity with real-world data. FORGE has the largest number of samples, indicating a more comprehensive evaluation dataset.

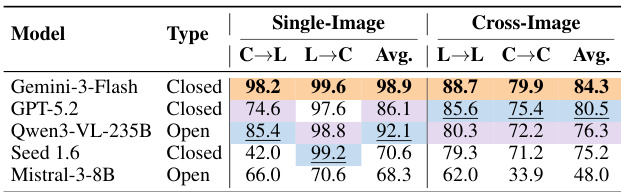
The the the table presents results from a visual grounding task, comparing the performance of four models across single-image and cross-image settings. The evaluation measures the ability to map between spatial coordinates and part labels, with the models achieving high accuracy in single-image tasks but lower performance in cross-image matching. Closed-source models achieve higher accuracy than open-source models in both single-image and cross-image settings. All models perform better on single-image tasks compared to cross-image tasks. The performance gap between single-image and cross-image tasks is more pronounced for open-source models.
The authors evaluate multiple MLLMs on three manufacturing tasks, analyzing performance across different settings and modalities. Results show that current models struggle with fine-grained domain knowledge and spatial reasoning, particularly in tasks requiring detailed visual analysis and logical inference. MLLMs perform better on macroscopic part recognition than microscopic surface analysis Reference-based methods do not consistently improve performance, indicating a lack of deep domain understanding Three-view evaluations show performance degradation with additional examples, suggesting spatial confusion in models
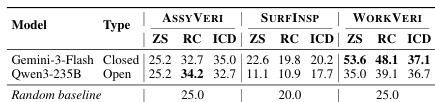
The experiments evaluate multimodal models on three manufacturing tasks, assessing performance across different scenarios and error types. Results show that models perform better on workpiece-level tasks than model-number-level tasks, and that visual grounding is not the primary bottleneck, suggesting domain knowledge limitations are more critical. Models perform better on workpiece-level tasks than on model-number-level tasks Visual grounding is not the main bottleneck, indicating domain knowledge limitations are more significant Performance degrades with additional examples in three-view modalities, suggesting spatial confusion

The experiment evaluates multiple MLLMs across manufacturing tasks, showing that closed-source models generally outperform open-source ones. Performance varies significantly across tasks and evaluation settings, with notable differences between zero-shot, reference-conditioned, and in-context demonstration methods. The results highlight that domain knowledge and reasoning capabilities are key bottlenecks, while visual grounding is not the primary limitation. Closed-source models achieve higher accuracy than open-source models across most tasks and settings. In-context demonstration methods generally improve performance over zero-shot and reference-conditioned settings. Performance varies significantly across tasks, with some tasks showing much lower accuracy than others, indicating task-specific challenges.
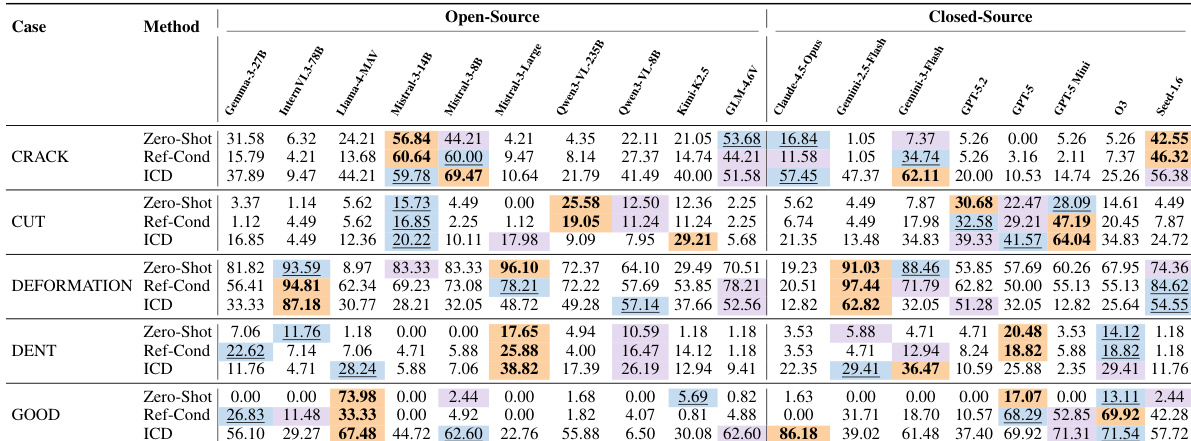
The evaluation compares various manufacturing benchmarks and the performance of multiple multimodal large language models across tasks involving visual grounding, part recognition, and spatial reasoning. While closed-source models generally outperform open-source ones, all models struggle with fine-grained domain knowledge and complex spatial reasoning, particularly when tasks require microscopic analysis or multiple views. The findings suggest that the primary limitations in these models are domain-specific understanding and logical inference rather than basic visual grounding capabilities.