Command Palette
Search for a command to run...
Qwen-Image-VAE-2.0 Technischer Bericht
Qwen-Image-VAE-2.0 Technischer Bericht
Zusammenfassung
Wir präsentieren Qwen-Image-VAE-2.0, eine Suite von hochkomprimierenden Variational Autoencodern (VAEs), die bedeutende Fortschritte sowohl in der Rekonstruktionsgenauigkeit als auch in der Diffusierbarkeit erzielen. Um die Rekonstruktionsengpässe bei hoher Kompression zu adressieren, setzen wir eine verbesserte Architektur ein, die Global Skip Connections (GSC) und erweiterte Latent-Kanäle umfasst. Darüber hinaus skalieren wir das Training auf Milliarden von Bildern und integrieren eine synthetische Rendering-Engine, um die Leistung in textreichen Szenarien zu verbessern. Um die Konvergenzprobleme des hochdimensionalen Latent-Raums zu bewältigen, implementieren wir eine verbesserte semantische Ausrichtungsstrategie, um den Latent-Raum für Diffusionsmodellierung besonders geeignet zu machen. Zur Optimierung der Recheneffizienz nutzen wir ein asymmetrisches und auf Attention verzichtendes Encoder-Decoder-Backbone, um den Codierungsaufwand zu minimieren. Wir präsentieren eine umfassende Bewertung von Qwen-Image-VAE-2.0 auf öffentlichen Rekonstruktions-Benchmarks. Um die Leistung in textreichen Szenarien zu evaluieren, schlagen wir OmniDoc-TokenBench vor, einen neuen Benchmark, der eine vielfältige Sammlung realer Dokumente mit spezialisierten, auf OCR basierenden Bewertungsmetriken kombiniert. Qwen-Image-VAE-2.0 erreicht state-of-the-art Rekonstruktionsleistungen und demonstriert außergewöhnliche Fähigkeiten sowohl in allgemeinen Domänen als auch in textreichen Szenarien bei hohem Kompressionsverhältnis. Darüber hinaus zeigen Downstream-DiT-Experimente, dass unsere Modelle eine überlegene Diffusierbarkeit besitzen und die Konvergenz im Vergleich zu bestehenden Hochkompressions-Baselines signifikant beschleunigen. Diese Ergebnisse etablieren Qwen-Image-VAE-2.0 als führendes Modell mit hoher Kompression, überlegener Rekonstruktion und außergewöhnlicher Diffusierbarkeit.
One-sentence Summary
The Qwen team introduces Qwen-Image-VAE-2.0, a high-compression variational autoencoder suite that integrates global skip connections, expanded latent channels, an asymmetric attention-free backbone, and an enhanced semantic alignment strategy to optimize reconstruction and diffusion compatibility, while scaling training to billions of images and incorporating a synthetic rendering engine to achieve state-of-the-art performance across general and text-rich domains, as validated on public benchmarks and the novel OmniDoc-TokenBench alongside accelerated convergence in downstream DiT experiments.
Key Contributions
- Qwen-Image-VAE-2.0 introduces an f16 and f32 high-compression VAE architecture utilizing global skip connections and expanded latent channels to preserve fine-grained details. An asymmetric, attention-free encoder-decoder backbone minimizes encoding overhead to facilitate efficient native high-resolution generation.
- A staged semantic alignment strategy leverages DINOv2 intermediate features to accelerate diffusion transformer convergence in high-dimensional latent spaces. This training paradigm transitions from strict alignment to balanced reconstruction and generation optimization, resolving diffusability bottlenecks.
- The model achieves state-of-the-art reconstruction fidelity across public benchmarks, with exceptional performance in text-rich document scenarios. Evaluation using the proposed OmniDoc-TokenBench and downstream DiT experiments confirms significantly accelerated convergence compared to existing high-compression baselines.
Introduction
Latent Diffusion Models depend on Variational Autoencoders to compress images into a latent space, but the industry standard eightfold compression creates severe computational bottlenecks as modern Diffusion Transformers scale quadratically with token count. Moving to higher compression ratios is critical for efficient native high-resolution synthesis, yet prior methods face a persistent trade-off between compression efficiency, reconstruction fidelity, and latent space diffusability. Higher compression typically degrades fine details, especially in text-heavy content, while expanding latent channels to compensate often yields unstructured distributions that stall diffusion model convergence. The authors leverage a global skip connection architecture, specialized document-focused data curation, and a staged semantic alignment strategy using DINOv2 features to overcome these limitations. This approach delivers leading reconstruction quality and rapid downstream generative compatibility, effectively resolving the traditional trade-off between compression ratio, image fidelity, and training efficiency.
Dataset
-
Dataset Composition and Sources
- The authors build a multi-source training corpus that combines billions of general-domain images, a curated collection of real-world text-rich document screenshots, and a synthetic text-rendering pipeline.
- The evaluation benchmark, OmniDoc-TokenBench, is extracted from the OmniDocBench document parsing dataset and contains approximately 3,000 text-heavy document images spanning nine categories including academic papers, slides, textbooks, and financial reports.
-
Key Details for Each Subset
- The main training corpus covers diverse categories, resolutions, and aspect ratios, with low-quality samples pruned using clarity and blur filters to remove edge artifacts and compression noise.
- The text-rich real-world subset applies an OCR filter to prioritize high character density and includes screenshots of academic papers, presentation slides, posters, and complex web pages.
- The synthetic subset supports English and Chinese text, renders characters at multi-granular sizes between 5 and 20 pixels, and places text over randomly sampled general-domain backgrounds to improve real-world generalization.
- The benchmark subset maintains a balanced English and Chinese distribution, enforces strict character count limits, and removes duplicates and visually degraded samples.
-
Data Usage and Training Strategy
- The authors use the filtered real-world and synthetic datasets to train the VAE, ensuring the model learns high-fidelity signals and captures fine stroke details under varying compression settings.
- OmniDoc-TokenBench serves exclusively as an evaluation benchmark rather than a training set.
- Model performance is measured by running full-page OCR on both original and reconstructed images and computing the Normalized Edit Distance to quantify page-level document readability without requiring word-level bounding boxes.
-
Processing and Curation Pipeline
- Text blocks are cropped from the top-left corner of each document and resized to 256 by 256 pixels, with reference font sizes set to 16 pixels for Chinese and 10 pixels for English.
- Content filtering relies on PP-OCRv5 to retain only samples containing 200 to 600 characters for Chinese and 300 to 600 characters for English.
- Deduplication is performed using character-level n-gram overlap thresholds of 0.2 for intra-page comparisons and 0.3 for intra-category comparisons, keeping only the sample with the highest character count in overlapping groups.
- A final human inspection step manually removes blurred, visually redundant, or excessively blank samples to ensure benchmark quality.
Method
The authors leverage a high-compression Variational Autoencoder (VAE) framework designed to achieve both efficient downstream diffusion modeling and high reconstruction fidelity. The overall architecture operates under the principle of maximizing information capacity within the latent space despite aggressive spatial compression. Given an input image I∈RH×W×3, the VAE maps it to a latent representation z∈RfH×fW×C, where f is the spatial compression ratio and C is the channel dimension. This results in a sequence length of L=HW/f2 for the downstream Diffusion Transformer (DiT). To mitigate the quadratic computational complexity of DiT, the authors adopt high compression ratios of f16 and f32, which significantly reduce training costs. To counteract the information loss inherent in such high compression, they increase the channel dimension C, thereby maintaining the total information bottleneck N(z)=CHW/f2.
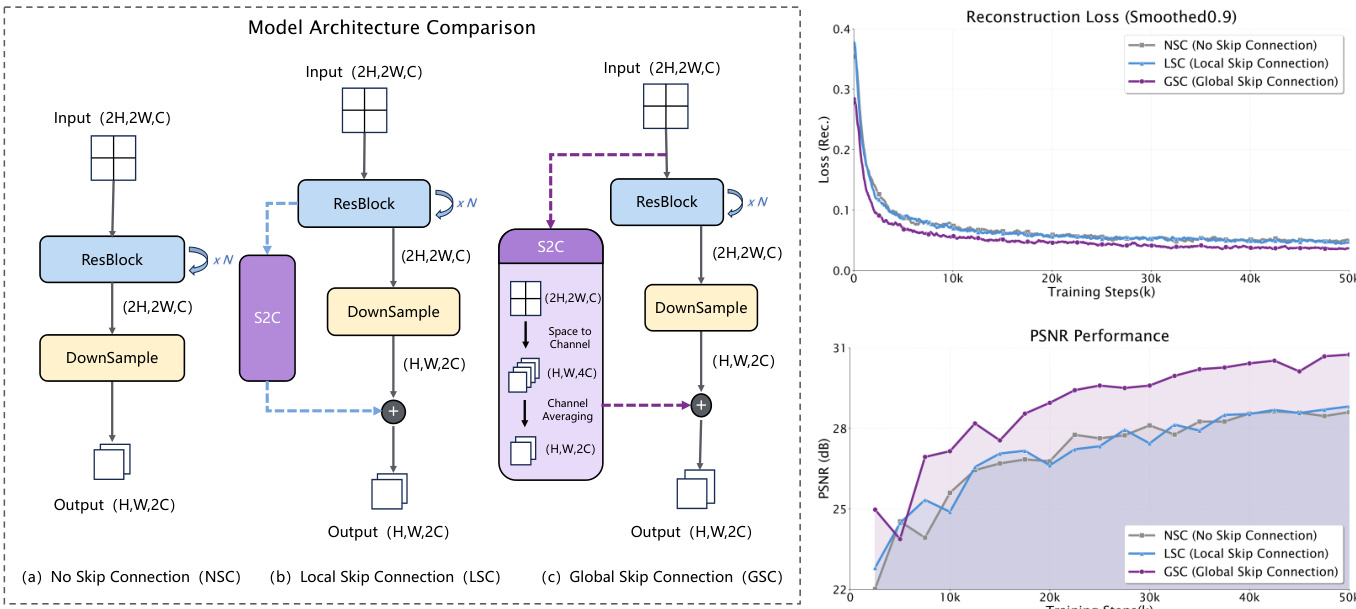
Refer to the framework diagram, which illustrates the core architectural innovations. The primary challenge addressed is the preservation of fine-grained detail during aggressive downsampling. To solve this, the authors introduce the Global Skip Connection (GSC), a residual path that bypasses the initial downsampling layers. As shown in the figure, this is implemented by using a space-to-channel (S2C) operation followed by reshaping, which effectively folds spatial information from the input image into the channel dimension, feeding it directly into the deeper latent space. This design contrasts with the No Skip Connection (NSC) and Local Skip Connection (LSC) configurations, where information is lost or only locally preserved during downsampling. The ablation study presented in the figure demonstrates that GSC significantly accelerates convergence and improves reconstruction performance, as evidenced by lower reconstruction loss and higher PSNR values.
To optimize computational efficiency, the model employs an attention-free backbone. For an input of sequence length N, the computational complexity of self-attention scales quadratically as O(N2), while convolution scales as O(N⋅k2). This quadratic scaling creates a severe throughput and memory bottleneck for high-resolution images. The authors observed no significant performance degradation when removing attention modules and thus adopted a backbone based on ResBlocks and downsampling layers to ensure scalability and training efficiency. Furthermore, the architecture is asymmetric: a lightweight encoder is used to minimize encoding overhead and reduce training latency for the downstream DiT, while a heavyweight decoder ensures high-fidelity reconstruction and preserves intricate image details.

The training process is designed to be simple yet effective, focusing on high-fidelity reconstruction and semantic alignment. The total training loss Ltotal is formulated as a combination of pixel-level L1 reconstruction loss Lrecon, perceptual loss Llpips, and a semantic alignment loss Lalign. The authors remove the conventional Kullback-Leibler (KL) divergence loss and adversarial GAN loss to achieve better performance and training stability. The KL loss is removed because it restricts latent capacity and competes with the semantic alignment objective, while the GAN loss is deemed unnecessary for large-scale training where Lrecon and Llpips are sufficient to produce sharp reconstructions. This simplified objective streamlines optimization and accelerates training. The training strategy is multi-stage, beginning with low-resolution images to ensure stable convergence, then progressively scaling to 2K resolution with diverse aspect ratios. A separate phase integrates real-world text-rich samples and synthetic text data to refine character recognition. Finally, semantic alignment is calibrated from a strict initial phase to a balanced one, ensuring the latent space is both semantically aligned and capable of high-quality pixel-level reconstruction.
Experiment
The evaluation framework combines standard pixel-based reconstruction metrics with a novel OCR-derived edit distance measure to rigorously assess both visual fidelity and text legibility across high-compression benchmarks. Experimental results demonstrate that the proposed architecture significantly outperforms existing models by preserving crisp character boundaries, accurate spacing, and fine stroke details even under extreme compression where competitors experience severe degradation. Furthermore, downstream diffusion training and large-scale foundation model integration validate that the learned latent space maintains exceptional semantic coherence and structural stability, successfully enabling high-fidelity generation and complex compositional tasks without traditional performance trade-offs.
The authors evaluate the reconstruction and diffusability of Qwen-Image-VAE-2.0 across different compression settings, comparing it to existing baselines on standard benchmarks. Results show that Qwen-Image-VAE-2.0 achieves state-of-the-art performance in both pixel-level reconstruction and text fidelity, particularly under high compression ratios, and demonstrates superior latent space diffusability for downstream generative tasks. The model outperforms competitors at equivalent compression levels, with notable gains in text preservation and generation quality. Qwen-Image-VAE-2.0 achieves superior text fidelity and reconstruction quality compared to baselines at equivalent compression ratios, especially under extreme compression settings. The model demonstrates strong diffusability, enabling high-quality image generation with faster convergence and better performance in downstream tasks. Qualitative results confirm that Qwen-Image-VAE-2.0 preserves fine details and text legibility even at high compression levels, outperforming existing methods in both visual and semantic coherence.
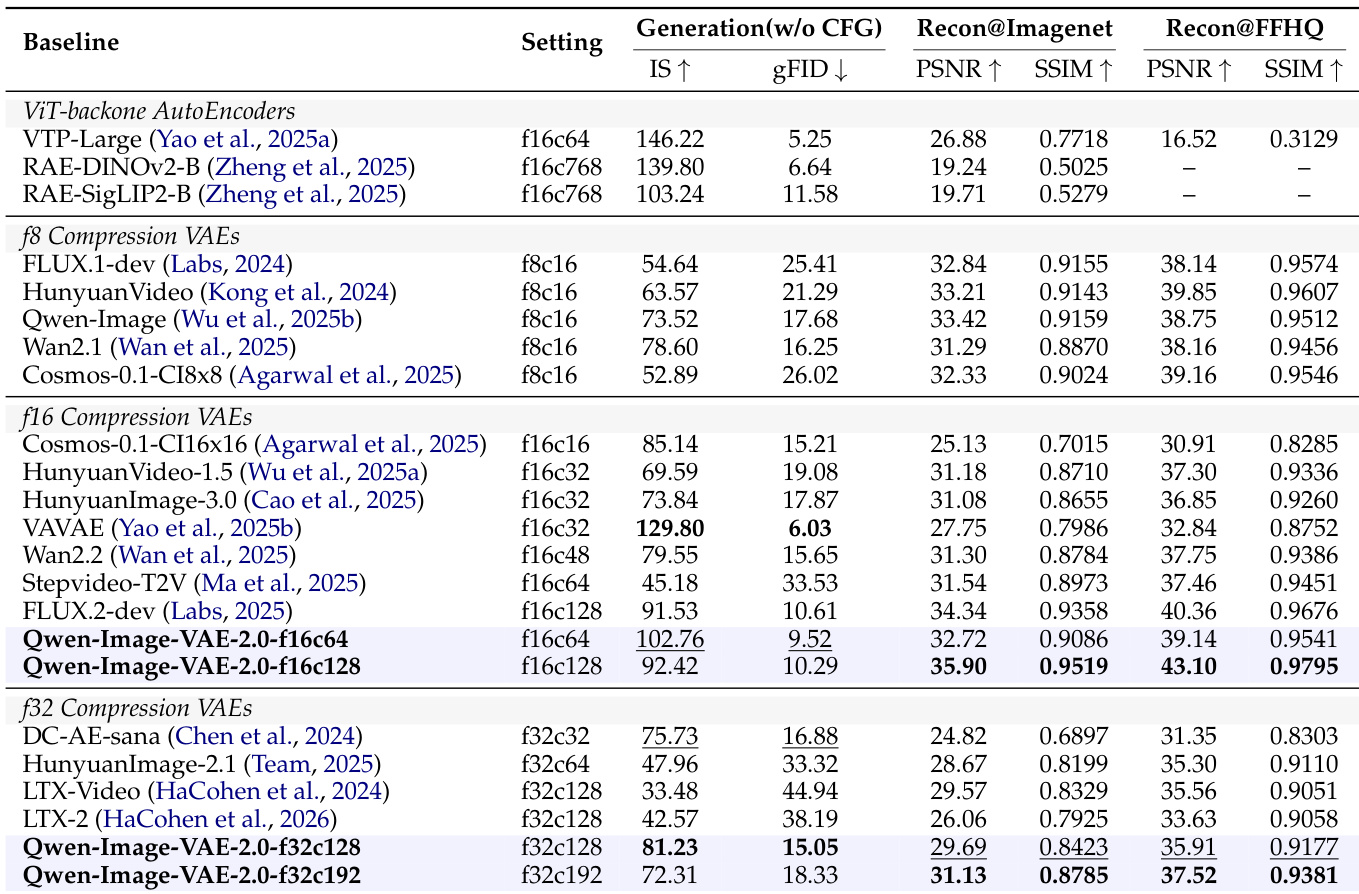
The authors evaluate the reconstruction performance of Qwen-Image-VAE-2.0 across different compression settings, comparing it against various baselines on standard benchmarks. Results show that Qwen-Image-VAE-2.0 achieves state-of-the-art performance in both pixel-level reconstruction and text fidelity, particularly under high compression ratios, with superior results in metrics such as SSIM, PSNR, and NED compared to existing methods. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction fidelity in both low and high compression settings, outperforming established baselines. The model demonstrates superior text fidelity under extreme compression, maintaining high NED scores where competitors fail. Qwen-Image-VAE-2.0 exhibits strong diffusability, enabling high-quality image generation and supporting large-scale text-to-image synthesis.
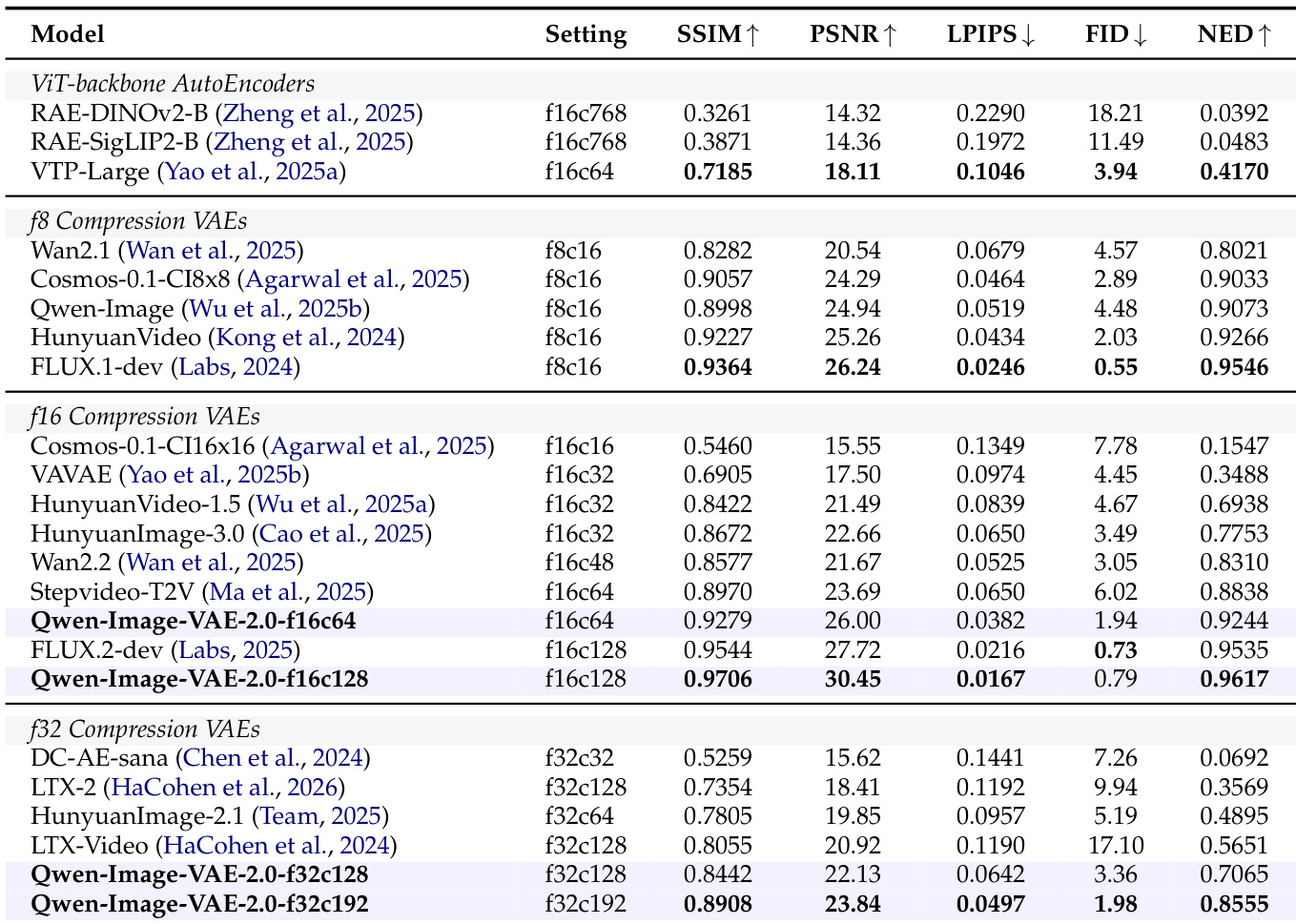
The authors evaluate the reconstruction performance of Qwen-Image-VAE-2.0 on standard benchmarks, demonstrating state-of-the-art results in both pixel-level fidelity and text preservation under various compression settings. The models achieve superior performance compared to existing baselines, particularly in high-compression scenarios, and exhibit strong diffusability in downstream generative tasks. Qwen-Image-VAE-2.0 achieves state-of-the-art reconstruction fidelity across different compression tiers, outperforming existing methods at both low and high compression ratios. The models demonstrate exceptional text fidelity, maintaining high character-level accuracy even under extreme compression, as measured by the NED metric. The learned latent space shows strong diffusability, enabling high-quality image generation and supporting complex compositional constraints in large-scale text-to-image systems.

The authors evaluate Qwen-Image-VAE-2.0 across multiple compression settings on standard benchmarks to assess its reconstruction fidelity, text preservation, and latent space diffusability for downstream generative tasks. Comparisons against established baselines demonstrate that the model consistently achieves state-of-the-art performance, particularly under high compression ratios where it successfully retains fine visual details and maintains high text legibility. Furthermore, the learned latent representation exhibits strong diffusability, enabling high-quality image synthesis with improved convergence and robust handling of complex compositional constraints in large-scale text-to-image pipelines.