Command Palette
Search for a command to run...
Jenseits des Reasonings: Reinforcement Learning erschließt parametrisches Wissen in LLMs
Jenseits des Reasonings: Reinforcement Learning erschließt parametrisches Wissen in LLMs
Wanli Yang Hongyu Zang Junwei Zhang Wenjie Shi Du Su Jingang Wang Xueqi Cheng Fei Sun
Zusammenfassung
Reinforcement Learning (RL) hat im Bereich des Reasonings mit Large Language Models (LLMs) bemerkenswerte Erfolge erzielt, doch die Frage, ob es auch die direkte Abrufbarkeit parametrischen Wissens verbessern kann, bleibt offen. Wir untersuchen diese Frage in einem kontrollierten Zero-Shot-, One-Hop-Setting für Closed-Book-Frage-Antwort-Aufgaben (QA) ohne Chain-of-Thought, wobei ausschließlich auf binäre Korrektheitsbelohnungen trainiert und eine Deduplizierung auf Faktenebene zwischen Trainings- und Testdaten angewendet wird, um sicherzustellen, dass die Verbesserungen einen verbesserten Abruf und nicht Reasoning oder Auswendiglernen widerspiegeln. Über drei Modellfamilien und mehrere faktische QA-Benchmarks hinweg erzielt RL durchschnittliche relative Gewinnsteigerungen von etwa 27 % und übertrifft dabei sowohl Trainings- als auch Inferenzzeit-Baselines. Mechanistisch verteilt RL die Wahrscheinlichkeitsmasse primär über bestehendes Wissen neu, anstatt neue Fakten zu erwerben, und verschiebt korrekte Antworten aus der Wahrscheinlichkeitsverteilung mit niedriger Wahrscheinlichkeit in zuverlässige Greedy-Generationen. Unsere Studie zur Datenattribution zeigt, dass die schwierigsten Beispiele am informativsten sind: jene, deren Antworten in 128 Proben vor dem RL nie erscheinen (nur etwa 18 % der Trainingsdaten), treiben etwa 83 % des Gewinns voran, da seltene korrekte Rollouts während des Trainings weiterhin auftreten und verstärkt werden. Zusammenfassend erweitern diese Erkenntnisse die Rolle von RL über das Reasoning hinaus und positionieren es als Werkzeug zum Freischalten latenten parametrischen Wissens, anstatt es zu erwerben.
One-sentence Summary
By applying fact-level train-test deduplication and binary correctness rewards within a controlled zero-shot, one-hop, closed-book question-answering framework, reinforcement learning achieves approximately 27% average relative gains across multiple model families and benchmarks, redistributing probability mass over existing parametric knowledge rather than acquiring new facts to unlock latent recall without chain-of-thought reasoning and repositioning the technique as a powerful tool for factual accuracy beyond complex reasoning.
Key Contributions
- This work introduces a controlled zero-shot, one-hop, closed-book question answering framework that isolates direct parametric knowledge recall using binary correctness rewards and strict fact-level train-test deduplication. The design explicitly prevents performance gains from reflecting chain-of-thought reasoning or memorization artifacts.
- Mechanistic analysis demonstrates that reinforcement learning enhances factual recall by redistributing probability mass across existing parametric knowledge rather than acquiring new information. This training dynamic amplifies rare correct rollouts to shift accurate answers from the low-probability output tail into reliable greedy generations.
- Evaluations across three model families and multiple factual question answering benchmarks show that this approach achieves approximately 27% average relative gains over established baselines. Data attribution analysis further reveals that difficult examples comprising only 18% of the training data drive approximately 83% of the total performance improvement.
Introduction
Large language models rely on direct factual recall, yet they frequently fail to surface information that is already encoded in their parameters, creating a persistent gap between what models know and what they can express. While reinforcement learning has successfully optimized multi-step reasoning, prior efforts to improve factual recall depend on inference-time prompting or training-time alignment methods that either fail to generalize to unseen queries or require explicit reasoning chains. The authors leverage reinforcement learning with binary correctness rewards to test whether RL can directly optimize non-reasoning knowledge retrieval. They demonstrate that RL significantly improves closed-book factual accuracy by redistributing the model's output distribution, effectively pulling already-encoded but low-probability answers into reliable greedy generations. Their findings show that RL unlocks latent parametric knowledge rather than acquiring new facts, with the hardest training examples driving the majority of performance gains.
Dataset
- Dataset Composition and Sources: The authors evaluate their approach using four factual question answering benchmarks: Natural Questions, TriviaQA, PopQA, and SimpleQA.
- Subset Details and Splits: For Natural Questions and TriviaQA, which originally contain over 80,000 training examples each, the authors randomly sample 10,000 instances for training and reserve a small validation portion. They repurpose the original validation splits as test sets because Natural Questions lacks an official test set and TriviaQA test annotations are not publicly available. For PopQA and SimpleQA, which only provide single evaluation sets, the authors randomly partition the data into training, validation, and test subsets.
- Processing and Metadata Construction: To ensure rigorous evaluation, the authors implement an LLM-based deduplication pipeline that compares test questions against candidate training examples. The model generates structured JSON metadata containing an
is_containedflag and a reasoning field to distinguish between exact factual paraphrases and cases where answers match but subject entities differ. This filtering process removes redundant semantic overlaps while preserving factual generalization examples. - Usage and Evaluation Strategy: The curated splits are used for both model training and benchmark evaluation. For assessment, the authors employ an LLM-as-a-Judge framework that compares predicted answers against gold targets. The evaluation prompts enforce strict binary scoring (1.0 for correct, 0.0 for incorrect) based on semantic equivalence, with all outputs constrained to numerical values to standardize grading across the benchmarks.
Method
The authors leverage a reinforcement learning (RL) framework to enhance direct factual recall in large language models (LLMs), focusing on zero-shot, one-hop, closed-book question answering without intermediate reasoning steps. The problem formulation restricts the model to generate concise answers directly, ensuring that any improvements are attributable to enhanced factual recall rather than reasoning capabilities. The model, parameterized by πθ, produces an answer a∼πθ(⋅∣q) for a given query q, with correctness determined by a binary indicator E(a,a∗). The training process employs Group Relative Policy Optimization (GRPO), which eliminates the need for a separate value network by computing advantages through relative reward comparisons within groups of rollouts. This approach is particularly suited to the outcome-based nature of factual recall, where the reward is binary and based on correctness.

As shown in the figure below, the direct factual QA setup uses a prompt that instructs the model to generate a single, concise answer without reasoning steps. This non-Chain-of-Thought (non-CoT) constraint is designed to isolate the effect of factual recall from reasoning traces. In contrast, the CoT setup includes a prompt that encourages step-by-step reasoning before producing a final answer, which is used as a baseline to assess the impact of reasoning on performance.
The reward function in the RL process is binary, assigning a reward of 1 for a correct answer and 0 otherwise. Correctness is evaluated using LLM-based semantic verification rather than exact string matching, which prevents sparsity and ensures that semantically correct answers are appropriately recognized. This verification process is detailed in Appendix D. The RL training maintains a unified hyperparameter configuration across all model-dataset combinations to ensure robustness and generalizability. Specifically, the learning rate is set to 1×10−6, with a global batch size of 128 and 8 training epochs. The policy objective includes a KL divergence regularization coefficient of β=0.001 and a PPO clip ratio of ϵ=0.2. Rollout generation uses vLLM with a temperature of T=1.0, top-k=−1, top-p=1.0, and a group size of n=5 samples per query.

Experiment
The evaluation leverages three open-source LLM families across multiple factual QA benchmarks to compare reinforcement learning against supervised fine-tuning, preference optimization, and inference-time scaling strategies under strict data deduplication. Experimental validation confirms that on-policy exploration paired with contrastive feedback uniquely enhances direct factual recall, consistently surpassing both offline training baselines and test-time sampling techniques. Qualitative analysis demonstrates that reinforcement learning operates as a latent knowledge optimizer by systematically redistributing probability mass to repair and amplify suppressed parametric signals, with training improvements primarily driven by initially inaccessible examples. These findings collectively establish that reinforcement learning generalizes robustly across model architectures, datasets, and algorithmic variants to enhance factual recall without relying on chain-of-thought reasoning or external knowledge injection.
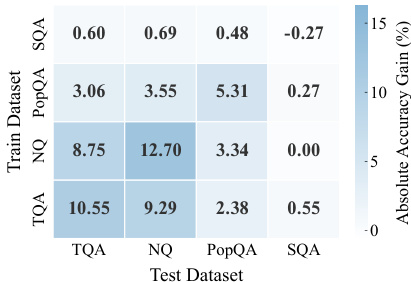
The authors compare various training methods for improving factual recall in large language models across multiple benchmarks and model families. Results show that reinforcement learning consistently outperforms other approaches, including supervised fine-tuning and test-time scaling, by significantly increasing accuracy across diverse datasets and model architectures. The gains are primarily driven by enhancing the accessibility of latent knowledge that was previously difficult to retrieve, rather than introducing new facts. Reinforcement learning delivers substantial and consistent improvements in factual recall across all evaluated models and benchmarks compared to alternative training and inference methods. The primary mechanism of RL is the redistribution of probability mass, making previously suppressed correct answers more accessible in both greedy and stochastic decoding. Training on examples that are initially inaccessible to the model yields the strongest learning signals, indicating that RL effectively amplifies latent knowledge rather than relying on easily retrievable facts.
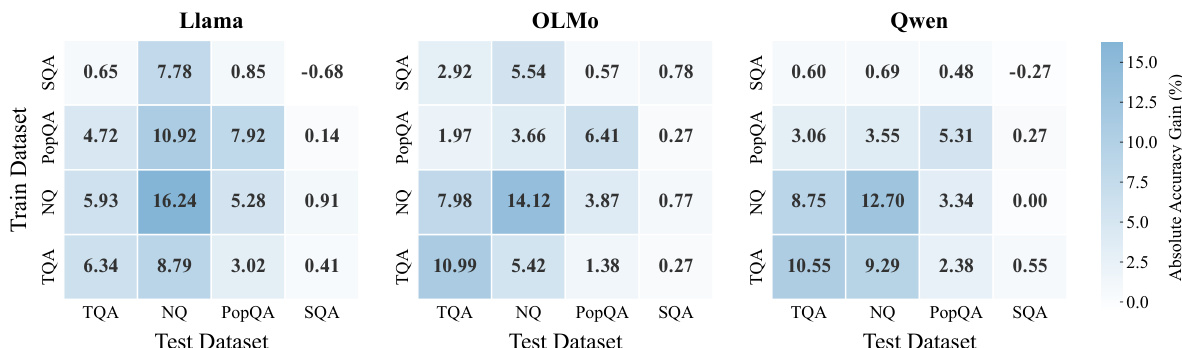
{"summary": "The authors investigate the effectiveness of reinforcement learning (RL) in improving direct factual recall across multiple large language models and benchmarks. Results show that RL consistently outperforms alternative training and inference-time methods, achieving substantial gains in accuracy by enhancing the model's ability to retrieve latent factual knowledge that was previously difficult to access. The improvements are robust across different models, datasets, and training configurations, with RL particularly effective at recovering facts that were initially inaccessible under standard decoding.", "highlights": ["RL significantly outperforms supervised fine-tuning, preference optimization, and rejection sampling, demonstrating its superiority in enhancing factual recall.", "RL improves factual recall by redistributing probability mass, making previously suppressed correct answers more accessible under both greedy and stochastic decoding.", "The most valuable training signals come from facts the model cannot recall initially, indicating RL's ability to amplify latent knowledge rather than relying on readily accessible information."]
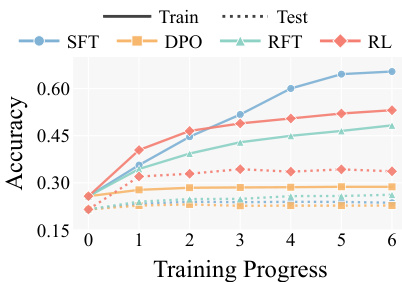
{"summary": "The authors compare reinforcement learning (RL) against various training and inference-time baselines for improving factual recall in large language models. Results show that RL consistently outperforms other methods, achieving significant and sustained improvements in accuracy across multiple benchmarks and models. The gains are attributed to RL's ability to amplify latent knowledge by redistributing probability mass, making previously inaccessible facts more reliably retrievable.", "highlights": ["RL achieves substantially higher accuracy than all baseline methods across multiple benchmarks and models.", "RL improves factual recall by redistributing probability mass, making suppressed knowledge more accessible without injecting new facts.", "The benefits of RL are robust across different datasets, model architectures, and training algorithms, indicating a generalizable optimization mechanism."]
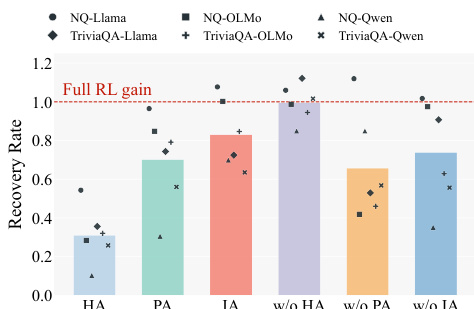
The authors compare reinforcement learning (RL) against various training and test-time baselines to evaluate its effectiveness in improving direct factual recall across multiple large language models and datasets. Results show that RL consistently outperforms all baselines, including supervised fine-tuning, rejection sampling, and test-time scaling methods, delivering substantial and robust accuracy gains. The improvement is not limited to in-domain settings but transfers across different datasets and model architectures, indicating a general enhancement of factual recall capability. Reinforcement learning achieves the highest accuracy across all tested models and benchmarks, significantly outperforming other training methods. RL improves factual recall in a way that test-time scaling strategies like majority voting or chain-of-thought prompting cannot replicate. The gains from RL are robust across different datasets, model sizes, and architectures, and are driven by the model's ability to recover facts that were previously inaccessible under standard decoding.
The authors evaluate the impact of different reward metrics on factual recall accuracy in reinforcement learning experiments across three language models. Results show that using an LLM-based judge for reward assignment yields significant improvements over both the pre-RL baseline and an exact-match reward metric, with the highest gains observed on the Qwen model. The findings indicate that the choice of reward function critically influences the effectiveness of RL in enhancing factual recall. LLM-based reward assignment leads to substantial accuracy improvements over both pre-RL and exact-match reward settings. The Qwen model achieves the highest accuracy under LLM-judge reward, demonstrating model-specific variations in RL effectiveness. Exact-match rewards result in minimal gains compared to LLM-based rewards, highlighting the importance of semantic evaluation in RL training.
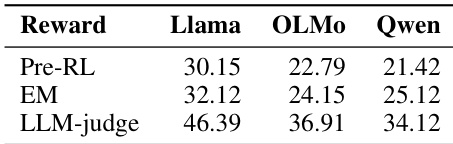
The authors evaluate reinforcement learning against multiple training and inference-time baselines across diverse large language models and datasets to assess its impact on factual recall. The first set of experiments validates that reinforcement learning consistently outperforms alternative approaches by redistributing probability mass to retrieve previously inaccessible latent knowledge rather than introducing new facts. The second experiment validates that semantic reward assignment using an LLM-based judge significantly enhances training effectiveness compared to rigid exact-match criteria. Overall, these findings establish reinforcement learning as a robust and generalizable method for amplifying factual recall across varying model architectures and decoding strategies.