Command Palette
Search for a command to run...
Selbstdistillierte agentic Verstärkungslernen
Selbstdistillierte agentic Verstärkungslernen
Zusammenfassung
Reinforcement Learning (RL) hat sich als zentrales Paradigma für das Post-Training von LLM-Agents etabliert, doch sein auf Trajektorien basierendes Belohnungssignal bietet nur eine grobe Supervision für Interaktionen über lange Horizonte. On-Policy Self-Distillation (OPSD) ergänzt RL, indem es eine dichte, Token-Ebene-Leitfaden von einem Lehrerzweig einführt, der mit privilegierten Kontextinformationen angereichert ist. Die Übertragung von OPSD auf Multi-Turn-Agents erweist sich jedoch als problematisch: Kumulative Multi-Turn-Instabilitäten destabilisieren die Supervision, während die fähigkeitsbedingte privilegierte Leitfaden eine asymmetrische Behandlung erfordert, da negative Ablehnungen durch den Lehrer aus unvollständiger Fähigkeitenabfrage oder -nutzung resultieren können. Wir stellen SDAR (Self-Distilled Agentic Reinforcement Learning) vor, das OPSD als gatedes auxiliary Ziel behandelt, während RL als primäres Optimierungsgerüst beibehalten wird. SDAR bildet abgekoppelte Token-Ebene-Signale in ein Sigmoid-Gate ab, verstärkt die Distillation auf vom Lehrer genehmigten positiven Lücken-Tokens und dämpft sanft negative Lehrer-Ablehnungen. Über die Qwen2.5- und Qwen3-Familien hinweg auf ALFWorld, WebShop und Search-QA verbessert SDAR GRPO erheblich (+9,4 % auf ALFWorld, +7,0 % auf Search-QA, +10,2 % auf WebShop-Acc), vermeidet die Instabilität von naivem GRPO+OPSD und übertrifft konsistent hybride RL--OPSD-Baselines über verschiedene Modellskalen hinweg.
One-sentence Summary
SDAR (Self-Distilled Agentic Reinforcement Learning) stabilizes multi-turn LLM agents by treating On-Policy Self-Distillation as a gated auxiliary objective that maps token-level signals to a sigmoid gate, reinforcing positive token guidance and attenuating negative rejections to enable the Qwen2.5 and Qwen3 families to substantially outperform GRPO across ALFWorld, WebShop, and Search-QA while avoiding the instability of naive GRPO+OPSD.
Key Contributions
- SDAR introduces a self-distilled agentic reinforcement learning framework that treats on-policy self-distillation as a gated auxiliary objective to stabilize multi-turn policy optimization.
- The method maps detached token-level signals through a sigmoid gate to selectively amplify distillation on teacher-endorsed positive-gap tokens while softly attenuating negative teacher rejections arising from imperfect skill retrieval.
- Evaluations across the Qwen2.5 and Qwen3 families on ALFWorld, WebShop, and Search-QA demonstrate consistent improvements over GRPO and hybrid RL-OPSD baselines, achieving accuracy gains of up to 10.2% without the training instability of naive distillation approaches.
Introduction
Post-training large language models as autonomous agents for multi-turn interactions relies heavily on reinforcement learning, yet trajectory-level rewards provide only coarse supervision for complex sequential decision-making. Prior attempts to inject dense token-level guidance through On-Policy Self-Distillation fail in multi-turn settings because compounding instabilities destabilize training and privileged teacher signals create asymmetric trust issues when negative feedback stems from imperfect skill retrieval. To resolve this, the authors introduce SDAR, which treats self-distillation as a gated auxiliary objective while keeping reinforcement learning as the primary optimization backbone. By mapping token-level teacher-student gaps into a sigmoid gate, the method amplifies learning on endorsed steps and softly attenuates negative rejections, delivering stable training and substantial performance gains across standard agentic benchmarks.
Method
The proposed method, SDAR, integrates on-policy self-distillation (OPSD) as a carefully controlled auxiliary objective within a verifier-driven reinforcement learning framework for training multi-turn language agents. The overall architecture, illustrated in the framework diagram, consists of two primary components: a GRPO-based reinforcement learning backbone and an OPSD module that operates in parallel. The GRPO component optimizes the student policy using task-outcome signals derived from environment rewards, computing sequence-level advantages and applying standard policy optimization techniques. The OPSD component, in contrast, leverages a self-teacher mechanism that conditions on privileged training-only context, such as retrieved skills, to provide token-level guidance. This guidance is not applied uniformly but is selectively modulated through a token-level gating mechanism, which ensures that distillation signals are only injected when they are reliable and beneficial.
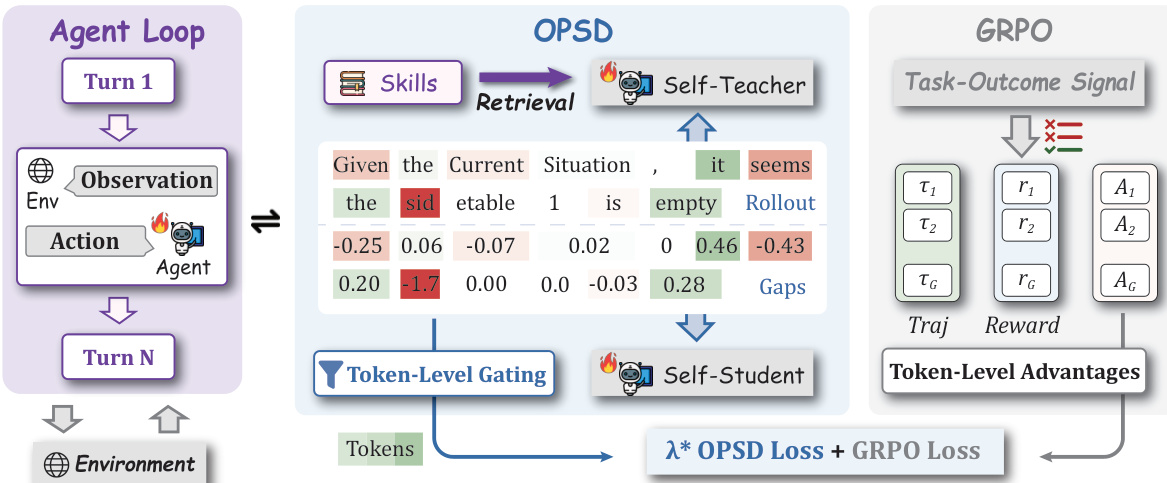
The core of the OPSD module is the token-level loss, which is derived from the reverse KL divergence between the student's and the self-teacher's conditional token distributions at each position t. To avoid the computational expense of full-vocabulary summation, a single-sample estimate is used, resulting in the Teacher-Student log-probability gap, Δt=logπT(yt∣st+)−logπθ(yt∣st), which serves as a direct measure of the discrepancy between the two models. This raw gap is then passed through a sigmoid function to produce a bounded gate gt=σ(βΔt), which acts as a confidence weight. This transformation ensures that the gradient updates are smooth and bounded, preventing the instability that arises from uncontrolled, high-variance updates, especially during early training or under severe teacher-student mismatch. The gate is detached from gradients to act as a pure confidence weight, avoiding any self-referential optimization pathways that could introduce instability. The final token-level loss is the product of this gate and the gap, and the overall OPSD objective is obtained by averaging this loss across all valid tokens in the trajectory.
The framework incorporates an adaptive, smooth gating mechanism to address the asymmetric trust in privileged guidance and the instability of multi-turn OPSD. Three distinct gating strategies are instantiated: entropy gating, which targets positions where the student is most uncertain; gap gating, which assigns larger weights to positive-gap tokens endorsed by the teacher while attenuating negative-gap tokens; and soft-OR gating, which combines both student uncertainty and teacher-student gap as an alternative strategy. This design allows for a dynamic, self-paced curriculum operating at the finest possible granularity—the individual token level—where each token can decide the intensity of its own supervision. The overall training objective is a weighted sum of the standard GRPO loss and the SDAR loss, ensuring that the verifier-driven RL policy loss remains untouched and thus preserves the semantics and unbiasedness of the RL advantage.
Experiment
Evaluated across household task planning, search-augmented question answering, and web-based shopping benchmarks, the experiments compare SDAR against training-free, post-training, and hybrid baselines to assess its ability to reconcile reinforcement learning with privileged knowledge distillation. Main results validate that the method successfully internalizes external skills rather than relying on them at inference, demonstrating superior generalization and stability compared to naive hybrid approaches. Training dynamics and robustness tests further confirm that the adaptive gating mechanism autonomously filters out negative teacher signals during optimization, maintaining consistent performance improvements across varying skill retrieval qualities. Finally, ablation studies verify that token-level gap gating and reverse KL objectives are essential for selectively reinforcing beneficial guidance without destabilizing the core reinforcement learning process.
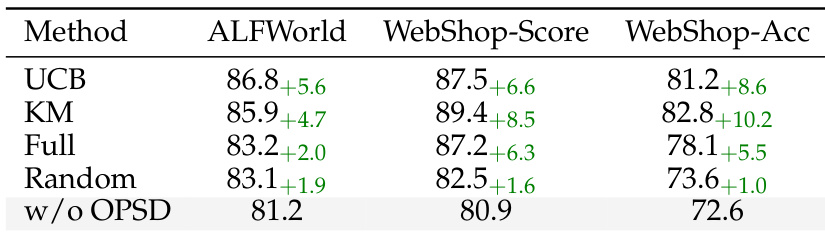
The authors evaluate the robustness of their method across different skill retrieval strategies, showing that all retrieval methods consistently outperform the baseline without privileged knowledge distillation. Even with low-quality retrieval, the method achieves gains, and performance improves as retrieval quality increases, indicating that the benefits stem from the gating mechanism rather than retrieval fidelity alone. All skill retrieval methods consistently outperform the baseline without privileged knowledge distillation. Performance improvements increase with retrieval quality, but gains are maintained even with low-quality retrieval. The method's effectiveness is attributed to its gating mechanism rather than the quality of retrieved skills.
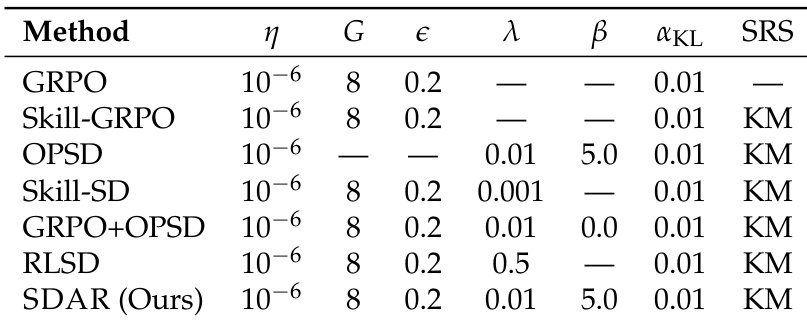
The authors compare their method SDAR against several baselines across different training configurations, focusing on hyperparameter settings for various methods including GRPO, Skill-GRPO, OPSD, Skill-SD, and RLSD. The the the table shows that SDAR uses a similar learning rate and group size as other methods but incorporates a distillation coefficient and gate sharpness parameter not present in the baselines, indicating a more complex optimization setup. All methods use the same skill retrieval strategy, suggesting a consistent approach to skill integration. SDAR uses a distillation coefficient and gate sharpness parameter not found in the baseline methods. All methods share the same learning rate and group size, indicating consistent training setup. The skill retrieval strategy is identical across all methods, emphasizing a uniform approach to skill integration.
The authors evaluate SDAR on three benchmarks—ALFWorld, Search-QA, and WebShop—across multiple model sizes, demonstrating consistent performance improvements over baselines. Results show that SDAR achieves the best or second-best results across most settings, with stable gains and strong generalization, particularly on smaller models. The method successfully internalizes privileged knowledge without relying on external skills at inference, and its adaptive gating mechanism enables robust training dynamics by selectively incorporating teacher guidance. SDAR achieves the best or second-best performance across all benchmarks and model sizes, outperforming both pure RL and hybrid baselines. The method internalizes privileged knowledge effectively, surpassing skill-augmented baselines even without external skills at inference. SDAR demonstrates robust training dynamics through a gating mechanism that selectively incorporates teacher guidance, ensuring stable optimization.
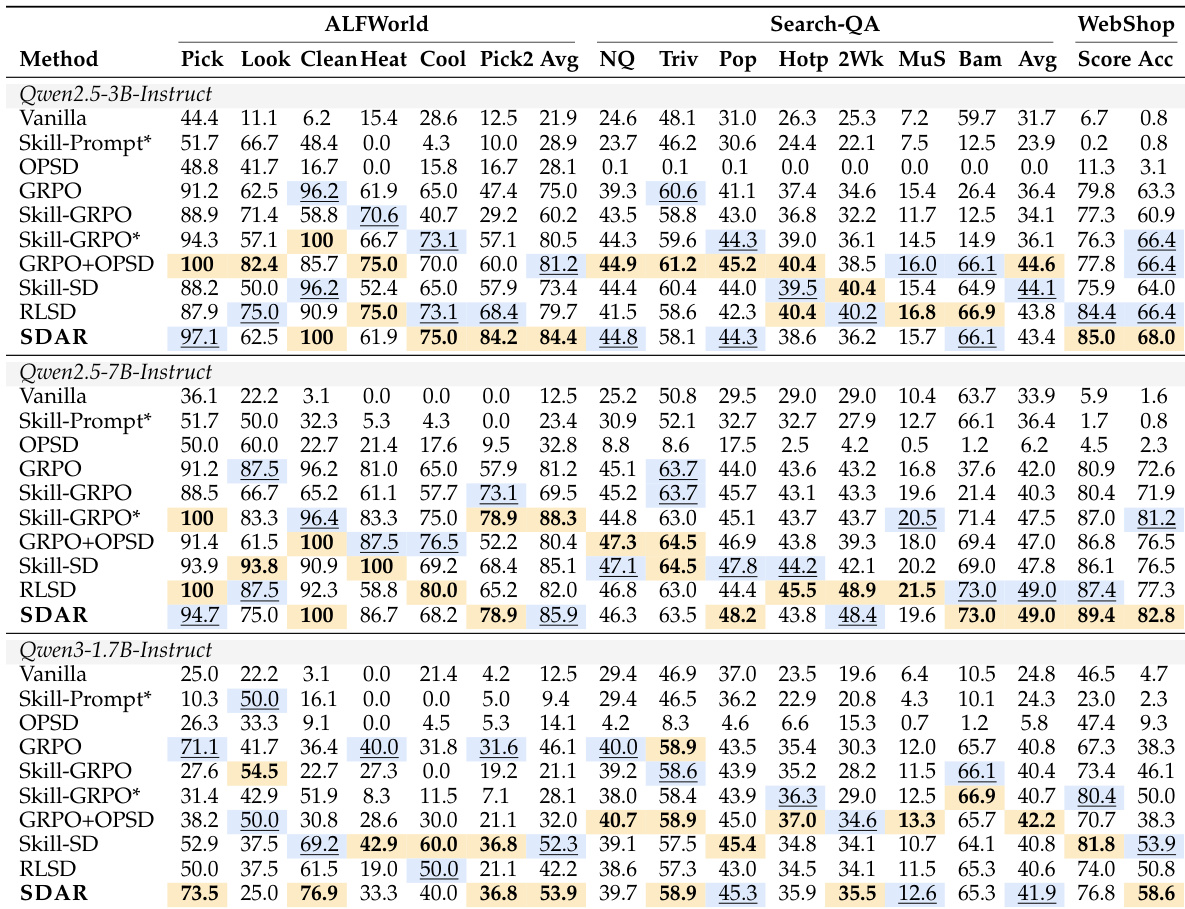
The authors evaluate SDAR across three benchmarks and multiple model sizes, comparing it against standard reinforcement learning and hybrid baselines under uniform training configurations. One experiment validates the method's robustness to skill retrieval quality, demonstrating that performance improvements persist even when retrieved skills are suboptimal. A second assessment confirms that the approach consistently matches or exceeds baseline results while successfully internalizing privileged knowledge without requiring external skills during inference. Collectively, these findings indicate that the adaptive gating mechanism effectively balances teacher guidance with student optimization, enabling stable training dynamics and strong generalization across diverse tasks.