Command Palette
Search for a command to run...
Vorhersage von Entscheidungen von KI-Agents aus begrenzter Interaktion durch Text-Tabellarische Modellierung
Vorhersage von Entscheidungen von KI-Agents aus begrenzter Interaktion durch Text-Tabellarische Modellierung
Eilam Shapira Moshe Tennenholtz Roi Reichart
Zusammenfassung
KI-Agents verhandeln und transaktieren in natürlicher Sprache mit unbekannten Gegenübern: ein Käufer-Bot, der mit einem unbekannten Verkäufer konfrontiert ist, oder ein Einkaufsassistent, der mit einem Lieferanten verhandelt. Bei solchen Interaktionen sind die LLMs, Prompts, Steuerlogiken und regelbasierten Fallback-Mechanismen des Gegenübers verborgen, während jede Entscheidung monetäre Konsequenzen haben kann. Wir untersuchen, ob ein Agent die nächste Entscheidung eines unbekannten Gegenübers aus wenigen Interaktionen vorhersagen kann. Um Störfaktoren durch das Logging in der realen Welt zu vermeiden, studieren wir dieses Problem in kontrollierten Verhandlungs- und Aushandlungsspielen und formulieren es als zieladaptierte Text-Tabellen-Vorhersage: Jeder Entscheidungspunkt ist eine Tabellenzeile, die den strukturierten Spielzustand, die Angebotsverlauf und den Dialog kombiniert, während K vorherige Spiele desselben Ziel-Agents, d. h. des zu modellierenden Gegenübers, im Prompt als beschriftete Adaptionsbeispiele bereitgestellt werden. Unser Modell basiert auf einem tabellarischen Foundation-Modell, das Zeilen unter Verwendung von Spielzustandsmerkmalen und LLM-basierten Textrepräsentationen darstellt, und fügt LLM-as-Observer als zusätzliche Repräsentation hinzu: Ein kleines, eingefrorenes LLM liest den Zustand und den Dialog zum Zeitpunkt der Entscheidung; seine Antwort wird verworfen, und sein versteckter Zustand wird zu einer entscheidungsorientierten Merkmalsdarstellung, wodurch das LLM zu einem Encoder und nicht zu einem direkten Few-Shot-Vorhersagemodell wird. Das Training erfolgte an 13 Frontier-LLM-Agents, und das Testen an 91 zurückgehaltenen, scaffolding-basierten Agents. Das vollständige Modell übertrifft direkte LLM-as-Predictor-Prompts und Spiel+Text-Merkmals-Baselines. Innerhalb dieses tabellarischen Modells tragen Observer-Merkmale über die anderen Merkmalsansätze hinaus bei: Bei K=16 verbessern sie die AUC der Antwortvorhersage um etwa 4 Punkte in beiden Aufgaben und reduzieren den Fehler der Angebotsvorhersage im Verhandlungskontext um 14 %. Diese Ergebnisse zeigen, dass die Formulierung der Gegenüber-Vorhersage als zieladaptierte Text-Tabellen-Aufgabe eine effektive Adaptation ermöglicht und dass verborgene LLM-Repräsentationen entscheidungsrelevante Signale offenbaren, die durch direktes Prompting nicht sichtbar werden.
One-sentence Summary
The authors propose a target-adaptive text-tabular framework that incorporates an LLM-as-Observer module to convert frozen language model hidden states into decision-oriented features, enabling the model, trained on 13 frontier LLM agents and evaluated on 91 held-out counterparts, to improve response-prediction AUC by approximately 4 points and reduce bargaining offer error by 14% at K=16 prior games.
Key Contributions
- This work formulates few-shot prediction of unfamiliar language-based agents as a target-adaptive text-tabular task, utilizing K prior interactions as labeled examples to enable adaptation without accessing hidden prompts or control logic.
- It introduces an LLM-as-Observer mechanism that processes public decision-time states and dialogue through a frozen small language model, extracting hidden states as decision-oriented features for a tabular predictor rather than relying on direct few-shot prompting.
- The study introduces a 91-agent university-hackathon dataset to evaluate cross-population transfer from frontier models to scaffolded agents, demonstrating that the proposed architecture outperforms direct prompting baselines and that Observer features improve response-prediction AUC by approximately four percentage points while reducing bargaining offer-prediction error by 14%.
Introduction
As AI agents increasingly conduct natural language negotiations with unfamiliar counterparts, accurately forecasting their next moves becomes essential for managing financial risk in automated commerce. Real-world transaction data remains largely inaccessible, and conventional direct-prompting approaches struggle to adapt quickly to new agents without exposing their internal prompts or control logic. To overcome these barriers, the authors leverage a target-adaptive text-tabular framework that treats a handful of prior interactions as labeled examples for rapid model adaptation. They construct a tabular predictor that combines structured game variables, dialogue embeddings, and a novel LLM-as-Observer module, which repurposes a frozen language model's internal hidden states as decision-oriented features. This design enables robust few-shot generalization to unseen agents and consistently surpasses direct prompting baselines by reliably extracting behavioral signals that standard generation methods overlook.
Dataset
-
Dataset Composition and Sources The authors compile a cross-population dataset using the GLEE benchmark, a simulation framework for two-player, sequential, language-based economic games. The dataset pairs a training source population with a held-out target population to evaluate whether decision predictors can transfer across different axes of agent heterogeneity.
-
Key Details for Each Subset
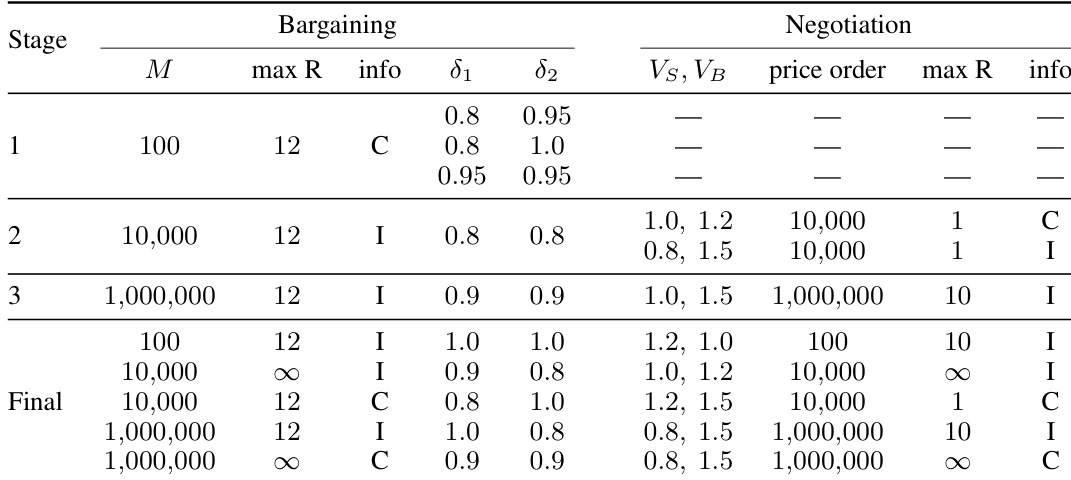
- GLEE Frontier-LLM Tournament (Training Source): Sourced from a round-robin tournament featuring 13 frontier LLMs from six providers. It contains approximately 64,000 games and 197,000 accept or reject decisions. Agents vary solely in their underlying model and play 960 configurations spanning bargaining and negotiation games with systematically varied horizons, discount factors, valuations, and communication regimes.
- University Hackathon (Held-out Target): Sourced from a December 2025 competitive hackathon. It contains 4,921 games and 11,341 decisions across 91 distinct team-stage agents. All agents are restricted to the Gemini 2.5 Flash or Flash-Lite API but differ in scaffolding techniques like control logic and prompting pipelines. The subset filters for free-text enabled configurations and treats each team-stage iteration as a separate agent.
-
Data Usage and Processing The authors structure the data for two prediction tasks: response prediction (binary classification for accept or reject decisions) and proposal prediction (regression for normalized offer values). For evaluation, they allocate K previously observed games to inform predictions while testing on held-out games. The target agent is never queried at inference time, and predictors receive only publicly observable state information. The study employs a strict source-to-target split for cross-population transfer evaluation rather than mixing the populations.
-
Metadata Construction and Processing Details Each decision point is formatted into a text-tabular row containing the public game configuration, offer history, dialogue context, and the target agent's next move. The authors mask private values in information-imperfect configurations to prevent data leakage. Game metadata, including payoff parameters and configuration flags, is extracted from config.json files and used to systematically control experimental conditions. Frozen LLM observer hidden states are also appended to each row to augment the tabular features.
Method
The authors leverage a target-adaptive tabular learning framework to predict the next decision of an unseen language-based agent from a small number of observed interactions. This approach diverges from direct imitation by an LLM, instead treating the problem as a tabular prediction task conditioned on both a large source population and the target’s few labeled examples. The framework combines structured game-state features, a dialogue representation, and a decision-oriented hidden state from a frozen LLM, referred to as the Observer, into a multimodal tabular row. This row serves as input to a tabular predictor that adapts to the target agent by conditioning on both the source population and the target’s observed games.
Refer to the framework diagram  . The model operates in two primary configurations: a baseline text-tabular setup and an augmented version that includes the Observer representation. In both cases, the predictor receives a multimodal input vector constructed from three distinct feature modalities. The tabular predictor, implemented as TabPFN, processes this input to produce either a classification (accept/reject) or regression (proposal) output.
. The model operates in two primary configurations: a baseline text-tabular setup and an augmented version that includes the Observer representation. In both cases, the predictor receives a multimodal input vector constructed from three distinct feature modalities. The tabular predictor, implemented as TabPFN, processes this input to produce either a classification (accept/reject) or regression (proposal) output.
The first modality consists of structured game-state features, which encode the strategic context of the interaction. For bargaining games, this includes configuration-level parameters such as the total amount to divide, discount factors, and game horizon, as well as per-round summaries of prior offers and decisions. For negotiation games, the features include seller and buyer valuations, reference prices, and outside-option payoffs. These features provide the predictor with direct access to the incentives and history that shape rational behavior.
The second modality is a dialogue representation derived from the natural language exchanges in the game. The authors use a sentence encoder to process all messages exchanged up to the current decision point, reducing the resulting high-dimensional embeddings to a lower-dimensional vector via PCA. This representation captures the semantic context of the conversation but is not explicitly trained to predict strategic decisions.
The third modality, the Observer representation, is generated by a small, frozen LLM that processes the current public game state and dialogue. The LLM is prompted to predict the next decision, but its output is discarded; instead, an internal hidden state is extracted as a decision-oriented feature. This representation captures information relevant to the decision-making process that may not be accessible through the LLM’s generated output. The Observer is never fine-tuned and does not receive the target’s prompt or past games, ensuring that adaptation occurs solely within the tabular predictor.
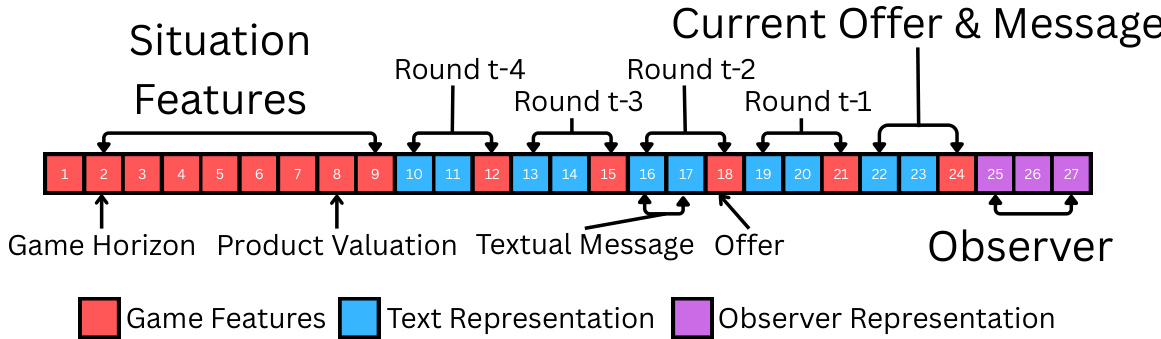 As shown in the figure below, the multimodal tabular row is structured such that the game-state features and dialogue representation are concatenated with the Observer hidden state. The row also includes an agent-identity indicator, which is a one-hot vector specifying the source or target agent. This indicator allows the tabular predictor to distinguish between population-level patterns and target-specific behaviors, particularly important when conditioning on both source and target data.
As shown in the figure below, the multimodal tabular row is structured such that the game-state features and dialogue representation are concatenated with the Observer hidden state. The row also includes an agent-identity indicator, which is a one-hot vector specifying the source or target agent. This indicator allows the tabular predictor to distinguish between population-level patterns and target-specific behaviors, particularly important when conditioning on both source and target data.
The tabular predictor performs inference by conditioning on the full set of labeled examples from the source population and the target’s K observed games. This joint conditioning enables the model to combine broad statistical regularities from the source population with specific adaptation signals from the target’s limited history. The model is used for both classification and regression tasks, with task-specific adjustments to the prompt suffix for the Observer to ensure appropriate feature extraction. For proposal prediction, the target variable is normalized to a unit scale and then inverted to recover the original monetary value, with different normalization schemes applied for bargaining and negotiation games. The model’s performance is evaluated using median R2 to mitigate the influence of heavy-tailed distributions in per-agent prediction accuracy.
Experiment
The study evaluates cross-population transfer by training on frontier LLM agents and testing on held-out hackathon participants, using varying adaptation examples to validate whether a target-adaptive tabular framework leveraging frozen LLM latent states outperforms both structured feature baselines and direct few-shot prompting. Qualitative analysis reveals that extracting reusable representations from intermediate model layers consistently yields stronger response and proposal predictions than relying solely on game features or direct LLM inference. Direct prompting proves particularly unreliable for numerical forecasting due to inherent autoregressive decoding limitations, whereas the tabular formulation effectively decodes stable strategic signals, establishing a robust and provider-agnostic approach to agent adaptation.
The authors evaluate a target-adaptive text-tabular model against direct prompting and reduced tabular baselines in a cross-population transfer setting. Results show that the Observer-augmented model consistently outperforms both the LLM-as-Predictor and the game+text features baseline, with improvements becoming more pronounced as the number of adaptation examples increases. The Observer hidden states provide a significant boost in response prediction, particularly in bargaining, and offer a more stable and reliable signal than the LLM's direct output logits. The Observer-augmented model achieves higher performance than both the LLM-as-Predictor and game+text features baseline across all conditions and both task families. The Observer hidden states provide a substantial improvement over the game+text features baseline, especially in response prediction and when fewer adaptation examples are available. The direct output logits from the LLM are less effective than the hidden state representation, indicating that the predictive signal resides in the latent space rather than the model's final output.
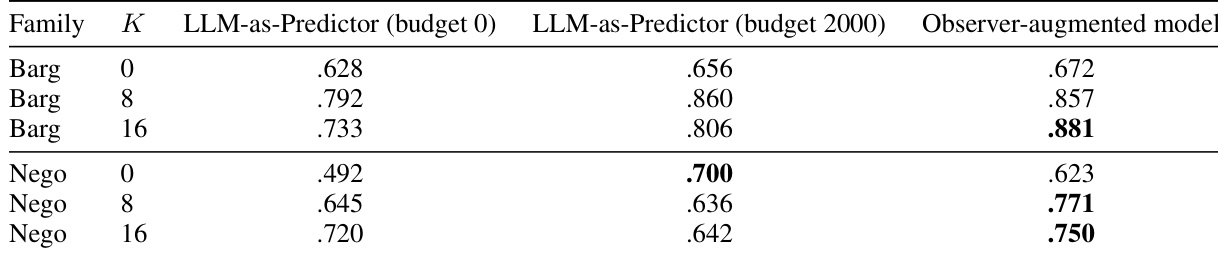
The authors evaluate a target-adaptive text-tabular model against baselines including direct LLM prompting and reduced tabular models, focusing on cross-population transfer. Results show that incorporating Observer hidden states consistently improves performance over game+text features, particularly in response prediction, while the benefit for proposal prediction is more pronounced in bargaining than in negotiation. The Observer's hidden states provide a stable and robust signal across different LLM providers and layers, outperforming direct LLM outputs. Observer hidden states significantly improve response prediction over game+text features and direct LLM prompting across all settings. Proposal prediction benefits from Observer features in bargaining but not in negotiation, indicating task-specific utility. The predictive advantage of Observer hidden states is consistent across different LLM providers and stable across mid-to-late layers.
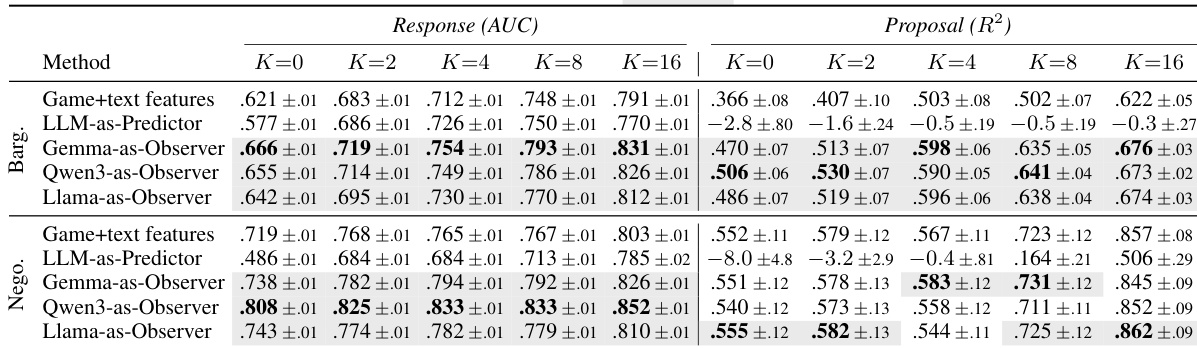
The authors evaluate a target-adaptive text-tabular model that incorporates Observer hidden states from frozen LLMs to improve prediction performance in cross-population transfer settings. Results show that using Observer representations consistently enhances response prediction across different LLM providers and adaptation levels, while the benefit for proposal prediction is more pronounced in bargaining than in negotiation. The performance gains are stable across mid-to-late layers of the LLMs and outperform direct LLM prompting, which is particularly weak for numerical offer prediction. Observer hidden states provide consistent improvements in response prediction across different LLM providers and adaptation levels. The benefit of Observer representations is stronger in bargaining than in negotiation for proposal prediction. Direct LLM prompting performs poorly for numerical offer prediction, while the text-tabular approach with Observer features yields superior results.
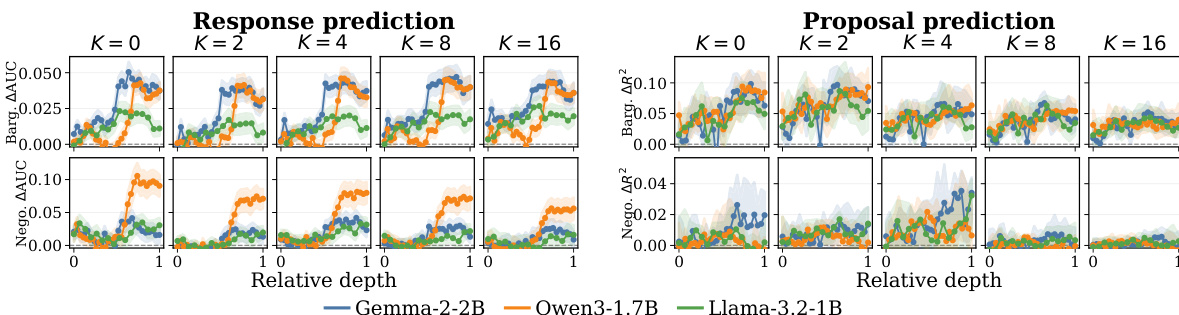
The authors evaluate a target-adaptive text-tabular model against baselines that use direct prompting or reduced tabular features, focusing on cross-population transfer from a frontier LLM tournament to hackathon agents. Results show that incorporating Observer hidden states significantly improves response prediction across both bargaining and negotiation tasks, particularly at higher adaptation example counts, while the gains for proposal prediction are more pronounced in bargaining. The Observer's hidden state representation consistently outperforms the LLM's direct output probabilities, indicating that the tabular model better decodes strategic signals from the latent space than the LLM's own prediction head. Observer hidden states provide a consistent improvement over game+text features for response prediction across both bargaining and negotiation tasks. The Observer's hidden state representation is more effective than the LLM's direct output probabilities for both response and proposal prediction. The benefits of the Observer are robust across different LLM providers and stable across mid-to-late layers of the model.
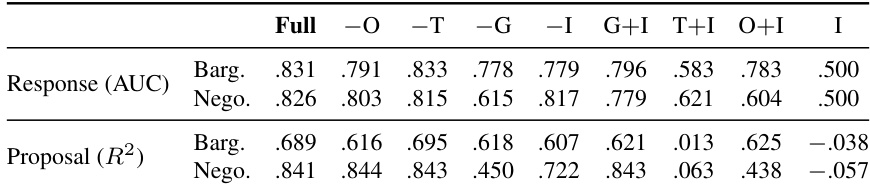
The authors evaluate a target-adaptive text-tabular model against baselines that use direct prompting or reduced tabular features, focusing on cross-population transfer from a frontier LLM tournament to held-out hackathon agents. Results show that incorporating Observer hidden states improves prediction performance over game+text features and direct LLM prompting, particularly in response prediction and proposal prediction for bargaining, where structured history alone is insufficient. The gains are consistent across different LLM providers and stable across mid-to-late layers of the models. Observer hidden states provide consistent improvements over game+text features and direct LLM prompting in both response and proposal prediction. The Observer effect is more pronounced in bargaining than in negotiation, where structured game features are already strong. The predictive signal from the Observer is stable across different LLM providers and mid-to-late layers, indicating it is an intrinsic property of the hidden states rather than an artifact of layer selection.
The authors evaluate a target-adaptive text-tabular model that integrates frozen LLM hidden states against direct prompting and reduced tabular baselines in cross-population transfer settings involving bargaining and negotiation tasks. Results demonstrate that leveraging these latent representations consistently yields more stable and reliable predictive signals than direct model outputs or structured game features, particularly for response prediction and proposal generation in bargaining scenarios. The findings confirm that the predictive advantage of the Observer architecture is robust across different language models and internal layers, indicating that strategic behavioral information is effectively encoded in intermediate representations rather than final output probabilities.