Command Palette
Search for a command to run...
Ihr Sprachmodell ist sein eigener Kritiker: Verstärkungslernen mit Werteschätzung aus den internen Zuständen des Akteurs
Ihr Sprachmodell ist sein eigener Kritiker: Verstärkungslernen mit Werteschätzung aus den internen Zuständen des Akteurs
Yunho Choi Jongwon Lim Woojin Ahn Minjae Oh Jeonghoon Shim Yohan Jo
Zusammenfassung
Titel:Abstract: Reinforcement Learning mit überprüfbaren Belohnungen (RLVR) für große reasoning-Modelle basiert auf der Schätzung von Baselines zur Varianzreduktion, doch bestehende Ansätze haben einen hohen Preis: PPO erfordert einen Kritiker in der Größenordnung des Policy-Modells, während GRPO mehrere Rollouts pro Prompt benötigt, um seinen empirischen Gruppenmittelwert stabil zu halten. Wir stellen Policy Optimization with Internal State Value Estimation (POISE) vor, das eine Baseline zu vernachlässigbaren Kosten durch die Nutzung interner Signale des Policy-Modells erhält, die bereits während des Policy-Forward-Passes berechnet werden. Ein leichter Probe (Probe) sagt die erwartete überprüfbare Belohnung aus den versteckten Zuständen des Prompts und der generierten Trajektorie sowie Token-Entropie-Statistiken vorher und wird online zusammen mit dem Policy trainiert. Um die Unverzerrtheit der Gradienten trotz der Verwendung von trajektorienbedingten Merkmalen zu bewahren, führen wir eine Cross-Rollout-Konstruktion ein, die den Wert jedes Rollouts aus den internen Zuständen eines unabhängigen Rollouts vorhersagt. Da POISE den Prompt-Wert unter Verwendung nur eines einzelnen Rollouts schätzt, ermöglicht es eine höhere Prompt-Diversität bei einem festen Rechenbudget während des Trainings. Dies reduziert die Gradientenvarianz für ein stabileres Lernen und eliminiert zudem den Rechen-Overhead der Sampling-Kosten zur Erkennung von Prompts mit Null-Vorteil. Auf Qwen3-4B und DeepSeek-R1-Distill-Qwen-1.5B über mathematische Reasoning-Benchmarks hinweg erreicht POISE die gleiche Leistung wie DAPO, benötigt jedoch weniger Rechenressourcen. Darüber hinaus zeigt sein Werteschätzer eine ähnliche Leistung wie ein separates LLM-großer Wertmodell und verallgemeinert auf verschiedene überprüfbare Aufgaben. Durch die Nutzung der eigenen internen Repräsentationen des Modells ermöglicht POISE eine stabilere und effizientere Policy-Optimierung.
One-sentence Summary
The authors propose POISE, a reinforcement learning method that replaces external critics and multiple rollouts by training a lightweight online probe to predict verifiable rewards from a policy model's hidden states and token-entropy statistics, employing a cross-rollout construction to preserve gradient unbiasedness while reducing variance, enabling higher prompt diversity under fixed compute, and demonstrating efficacy on Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.
Key Contributions
- The paper introduces POISE, a reinforcement learning algorithm that estimates expected verifiable rewards using a lightweight probe trained on a policy model's internal hidden states and token-entropy statistics. To preserve gradient unbiasedness, the method employs a cross-rollout construction that predicts each trajectory's value from an independent rollout.
- This architecture eliminates the computational overhead of an LLM-scale critic and reduces the required rollouts per prompt to a single pair, enabling higher prompt diversity within a fixed compute budget. The continuous baseline also removes the need for additional sampling steps to detect and discard zero-advantage prompts.
- Experimental results show that POISE matches the performance of the state-of-the-art DAPO algorithm on mathematical reasoning benchmarks while requiring less compute. The estimator also generalizes to coding, tool-calling, and instruction-following tasks while maintaining performance comparable to full-scale value models.
Introduction
Large language models have achieved significant gains in complex reasoning through reinforcement learning with verifiable rewards, a process that depends on accurate baselines to stabilize training and reduce reward variance. Existing approaches face substantial computational bottlenecks, as PPO requires an LLM-scale critic that doubles memory consumption, while GRPO substitutes the critic with group-relative baselines that demand multiple rollouts, reducing prompt diversity and inflating gradient variance. To resolve these inefficiencies, the authors leverage the policy model's own internal hidden states and token entropy to train a lightweight probe that estimates expected rewards. This approach eliminates the need for heavy critics or large rollout groups, delivering stable, compute-efficient optimization that generalizes effectively across mathematical reasoning, coding, and instruction-following tasks.
Method
The authors leverage the policy model's internal state signals to construct a low-cost, unbiased baseline for reinforcement learning with verifiable rewards (RLVR), forming the core of their proposed method, POISE. The framework is built on the insight that a lightweight probe can predict the expected verifiable reward directly from the policy model's hidden states, which are already computed during the forward pass, eliminating the need for an auxiliary value network or extensive rollout groups. As shown in the figure below, the process begins with the policy model generating two independent rollouts, y(1) and y(2), for each prompt x. During the forward pass, the model's internal states are extracted, specifically the hidden states from the last ten prompt tokens and the last ten reasoning tokens, which are then pooled to form the feature representation ϕ(x,y(i)) for each rollout. These features, along with token-entropy statistics, serve as inputs to a lightweight value estimator gf.
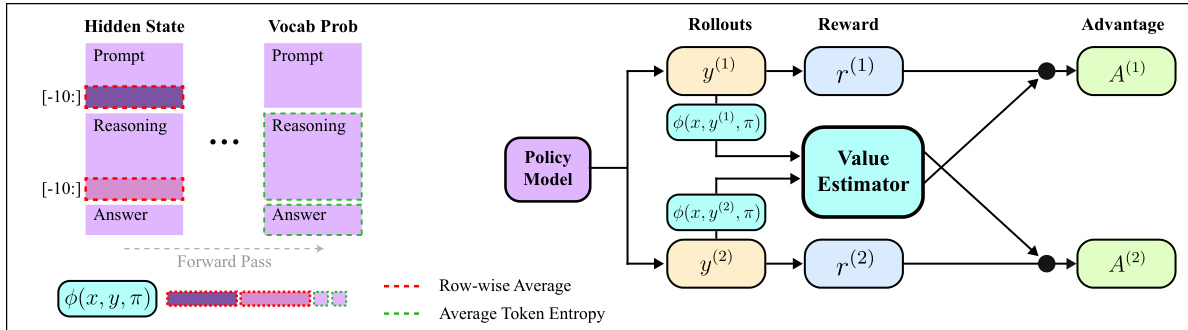
The value estimator is trained online, using a trajectory buffer to stabilize training against policy drift. For each prompt with two rollouts, the estimator is trained on a regression task where the target for the feature of rollout i is the reward of the other rollout, R(i)=R(x,y(j)), j=i. This cross-rollout construction ensures that the baseline used for each rollout's advantage computation is derived from an independent sample, preserving the conditional independence required for an unbiased gradient estimator. The baseline for rollout i is predicted as b(i)(x)=gf(ϕ(j)), j=i, leading to the cross-rollout advantages A(i)(x)=R(x,y(i))−b(i)(x). These advantages are then used in a PPO-style clipped surrogate objective to update the policy parameters θ. This design allows POISE to achieve stable learning by enabling higher prompt diversity for a fixed compute budget, as it requires only a single rollout per prompt for value estimation, thereby reducing gradient variance.
Experiment
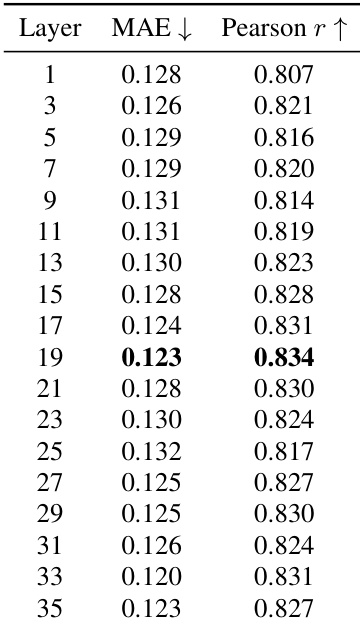
Experiments were conducted on Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.5B models trained on mathematical reasoning data and evaluated across multiple olympiad-level benchmarks against the state-of-the-art DAPO algorithm. Benchmark evaluations validate that replacing group-relative baselines with a lightweight internal state value estimator yields comparable reasoning performance while significantly reducing training time and stabilizing optimization through lower gradient variance. Further analysis of the value estimator confirms that it reliably tracks evolving policy rewards, consistently reduces advantage variance, and generalizes across diverse domains and model scales to match or surpass separately trained critic models. These findings collectively validate that a model's internal activations provide a robust and computationally efficient signal for reliable value estimation in reinforcement learning with verifiable rewards.
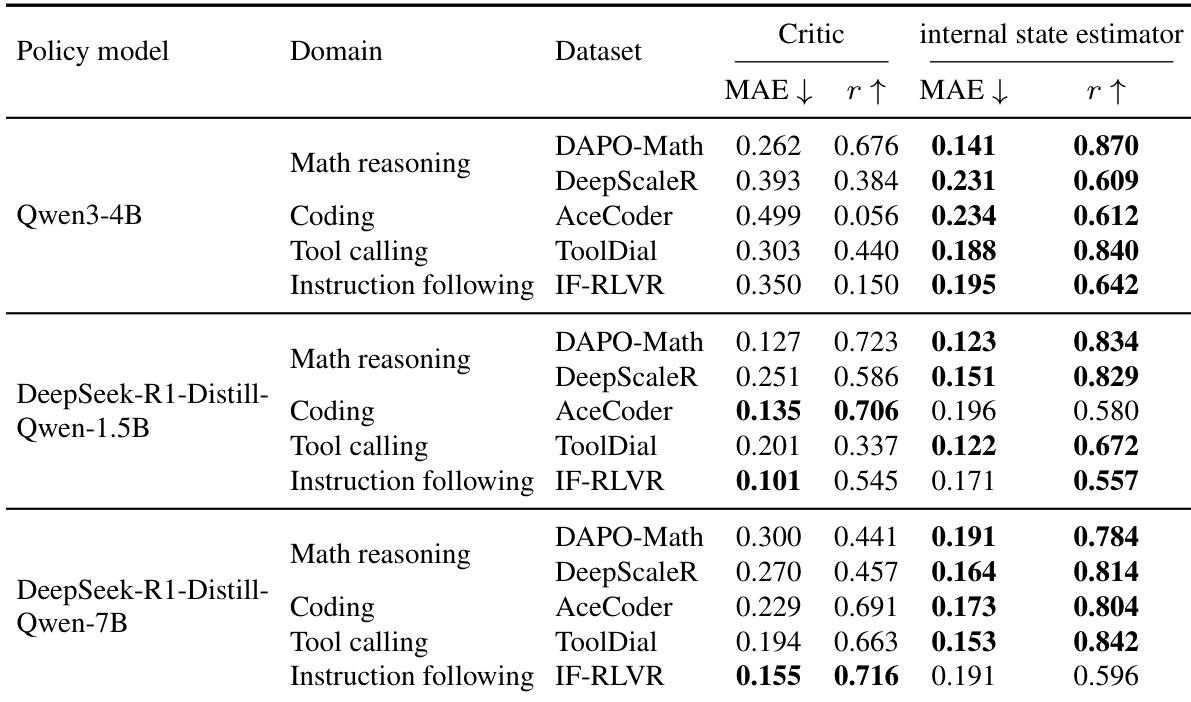
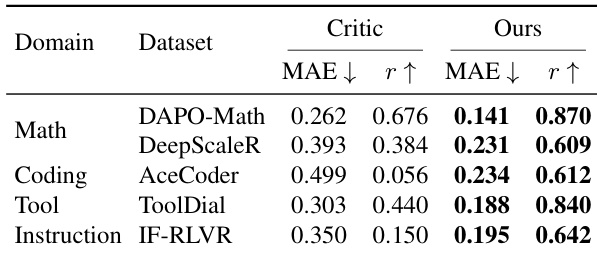
The authors compare a lightweight internal state value estimator against a separately trained critic model across multiple domains and policy models. Results show that the internal state estimator achieves competitive or better performance in terms of mean absolute error and Pearson correlation, particularly on coding and instruction-following tasks, while requiring significantly less computational overhead. The estimator remains stable and well-calibrated to the evolving policy across different model scales and domains. The internal state estimator achieves competitive or better performance than a full-scale critic model across multiple domains and model sizes. The estimator shows strong generalization, particularly on coding and instruction-following tasks, where it outperforms the critic in correlation and reduces error. The estimator remains stable and well-calibrated to the evolving policy during training, with consistent performance across different model scales and domains.
The authors evaluate their method, POISE, on mathematical reasoning benchmarks using two model scales, demonstrating performance comparable to a state-of-the-art baseline while achieving faster training and more stable optimization. The approach replaces group-relative baseline estimation with a lightweight internal state value estimator, which is trained online and remains calibrated to the evolving policy throughout training. The estimator uses features from the policy's hidden states and entropy, and its design is robust to variations in hyperparameters and probe architecture. POISE achieves performance comparable to a state-of-the-art RL algorithm while using a lightweight internal state value estimator. The method trains faster and exhibits more stable optimization compared to the baseline, with lower gradient norms throughout training. The internal state value estimator remains calibrated to the evolving policy and provides consistent variance reduction in advantage computation.
The authors evaluate a lightweight internal state value estimator against a separately trained critic across multiple domains and policy models. Results show that the proposed estimator achieves competitive or superior performance in terms of both mean absolute error and Pearson correlation, particularly in non-math domains, while requiring significantly less computational overhead. The estimator remains stable and well-calibrated throughout training, demonstrating its effectiveness in providing reliable value signals for reinforcement learning. The proposed estimator achieves competitive or better performance than a larger critic model across multiple domains, especially in coding and instruction-following tasks. The estimator maintains stable performance with lower computational cost by using only internal state features from the policy's forward pass. The estimator shows consistent calibration and variance reduction during training, indicating its reliability as a baseline for policy optimization.
The authors evaluate their method, POISE, on olympiad-level mathematical reasoning benchmarks using two model scales, Qwen3-4B and DeepSeek-R1-Distill-Qwen-1.5B, comparing it against the DAPO baseline. Results show that POISE achieves comparable or slightly better performance than DAPO on most benchmarks, with improvements on specific tasks, while also demonstrating faster training and more stable optimization. The method uses a lightweight internal state value estimator to provide a stable baseline, reducing training variance and requiring less computational time. POISE achieves performance comparable to or slightly better than DAPO on multiple mathematical reasoning benchmarks across different model scales. POISE reduces training time and improves optimization stability by using a lightweight internal state value estimator that provides a stable baseline. The internal state estimator remains calibrated to the evolving policy and reduces reward variance, leading to more stable training dynamics.
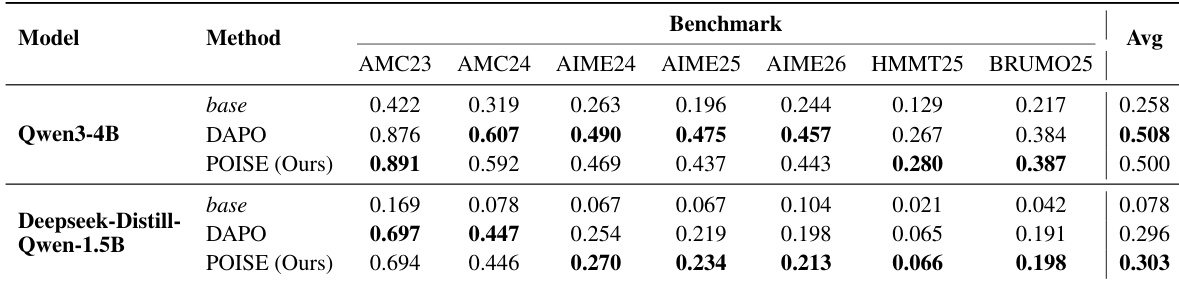
{"summary": "The authors analyze the impact of different transformer layer indices on the performance of their value estimator, which uses internal state features to predict verifier rewards. The results show that performance varies with the layer choice, with layer 19 achieving the lowest mean absolute error and the highest Pearson correlation, indicating it provides the most accurate and well-correlated predictions. The estimator's performance remains relatively stable across adjacent layers, suggesting robustness to layer selection.", "highlights": ["Layer 19 achieves the best balance of low mean absolute error and high Pearson correlation for the value estimator.", "Performance remains stable across layers, with minimal variation in error and correlation around the optimal layer.", "The estimator's accuracy is sensitive to layer choice but maintains strong performance across a range of layers."]
The experiments evaluate a lightweight internal state value estimator against a separately trained critic model and state-of-the-art reinforcement learning baselines across diverse domains, model scales, and transformer layer configurations. These evaluations validate the estimator's predictive accuracy, computational efficiency, and alignment with evolving training policies. Qualitative results indicate that the proposed approach consistently matches or surpasses heavier baselines while significantly reducing computational overhead and training duration. Furthermore, the estimator demonstrates robust calibration, stable optimization dynamics, and reliable variance reduction across varied tasks and architectural settings.