HyperAI
Command Palette
Search for a command to run...
论文
每日更新的前沿人工智能研究论文,帮助您紧跟最新的人工智能趋势

守护AI智能体:面向多层智能体红队测试的统一框架

DataComp-VLM:面向视觉语言模型的改进开放数据集

























守护AI智能体:面向多层智能体红队测试的统一框架
DataComp-VLM:面向视觉语言模型的改进开放数据集
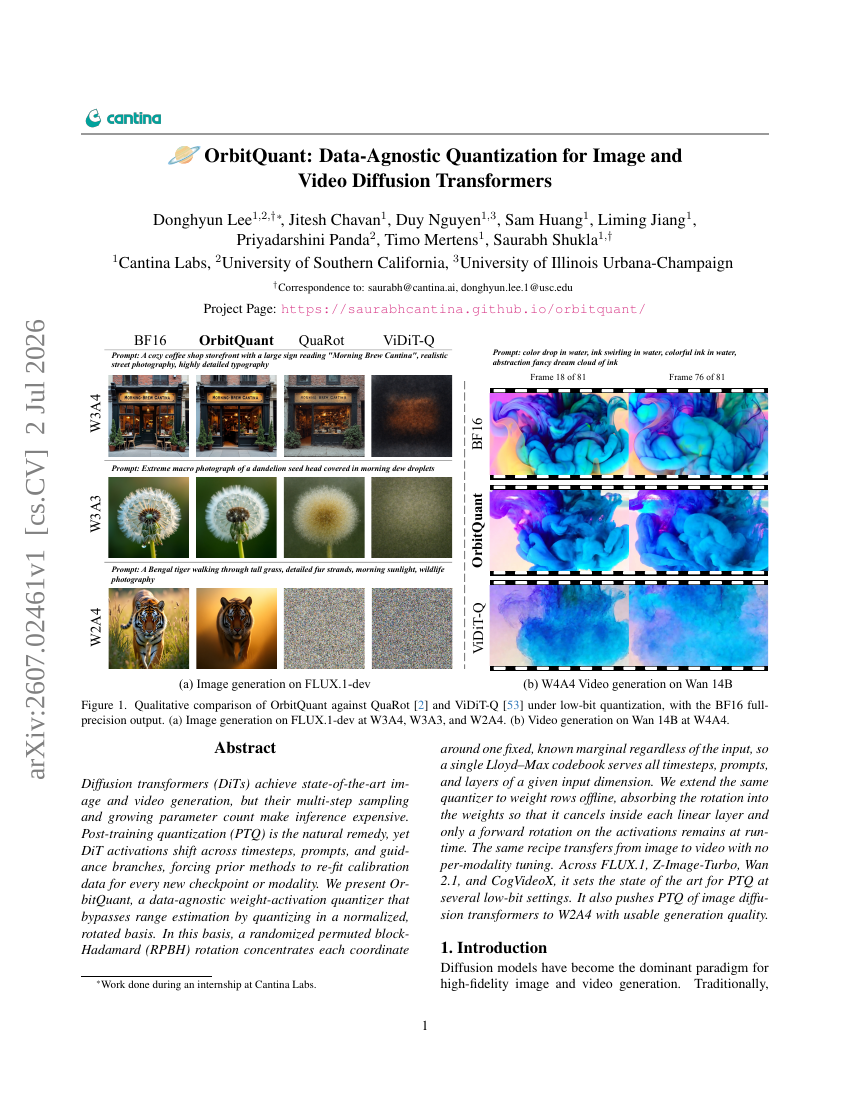
OrbitQuant:面向图像与视频扩散Transformer的数据无关量化方法
VLA-Corrector:面向自适应动作视野的轻量级检测与修正推理框架
Embodied.cpp:面向异构机器人的具身AI模型可移植推理运行时
优化训练策略的幻象:单调推理策略——大语言模型强化学习的真正目标
GeneBench-Pro:评估基因组学、定量生物学与转化生物医学中的多阶段统计推理
立场:AI/ML深度伪造研究与AI生成的非自愿亲密影像(AIG-NCII)存在错位
理解Grokking:岭回归中可证明的Grokking现象
扩散模型一致性的随机矩阵理论视角
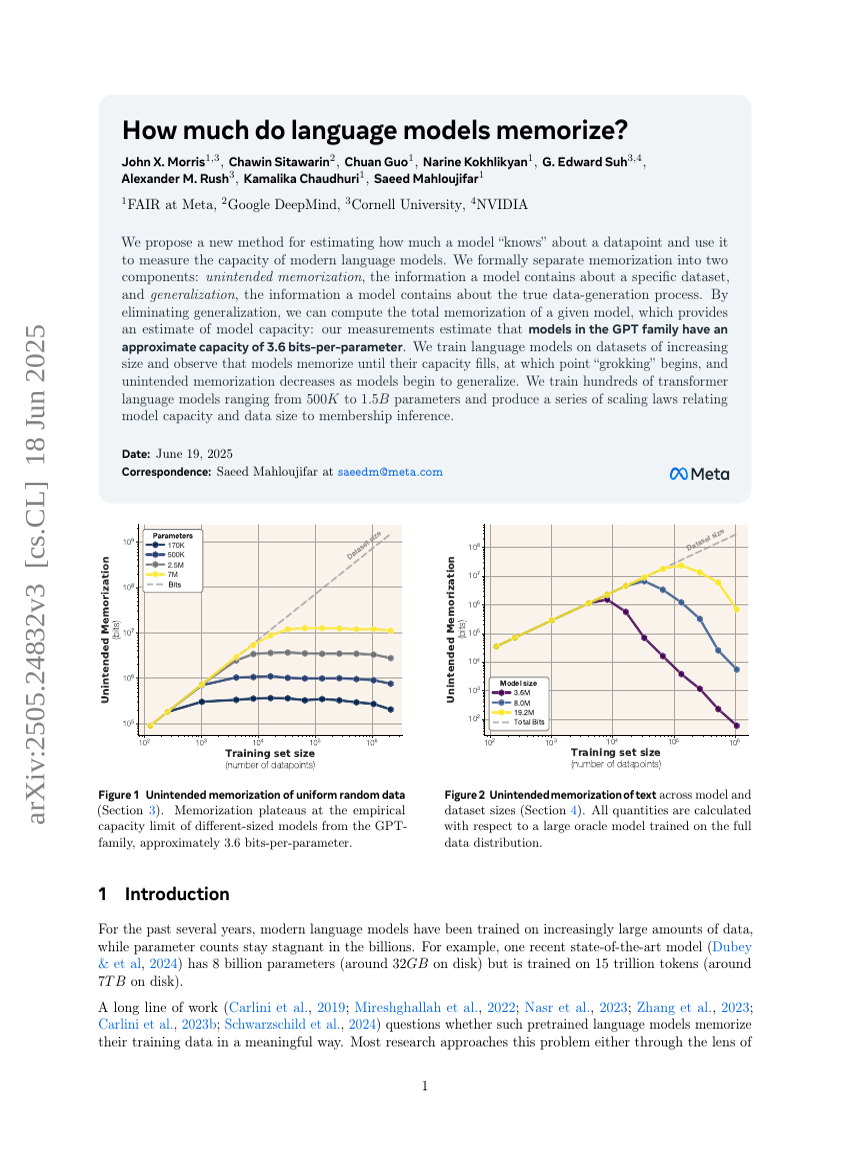
语言模型记忆了多少?
混淆图集:用欺骗探针映射RLVR中诚实的涌现位置
立场:对齐社区正在无意间构建审查工具包
扩散模型与对数凹分布的高精度采样
AgenticDataBench:面向数据智能体的综合评测基准
多分辨率流匹配:通过分阶段采样实现无需训练的扩散加速
跃变为混合注意力模型
EvoPolicyGym:评估交互式环境中的自主策略演化能力
AgenticSTS:面向长周期LLM智能体的有界记忆测试平台
程序即权重:一种面向模糊函数的编程范式
MatAnyone 2:通过学习的质量评估器扩展视频抠图
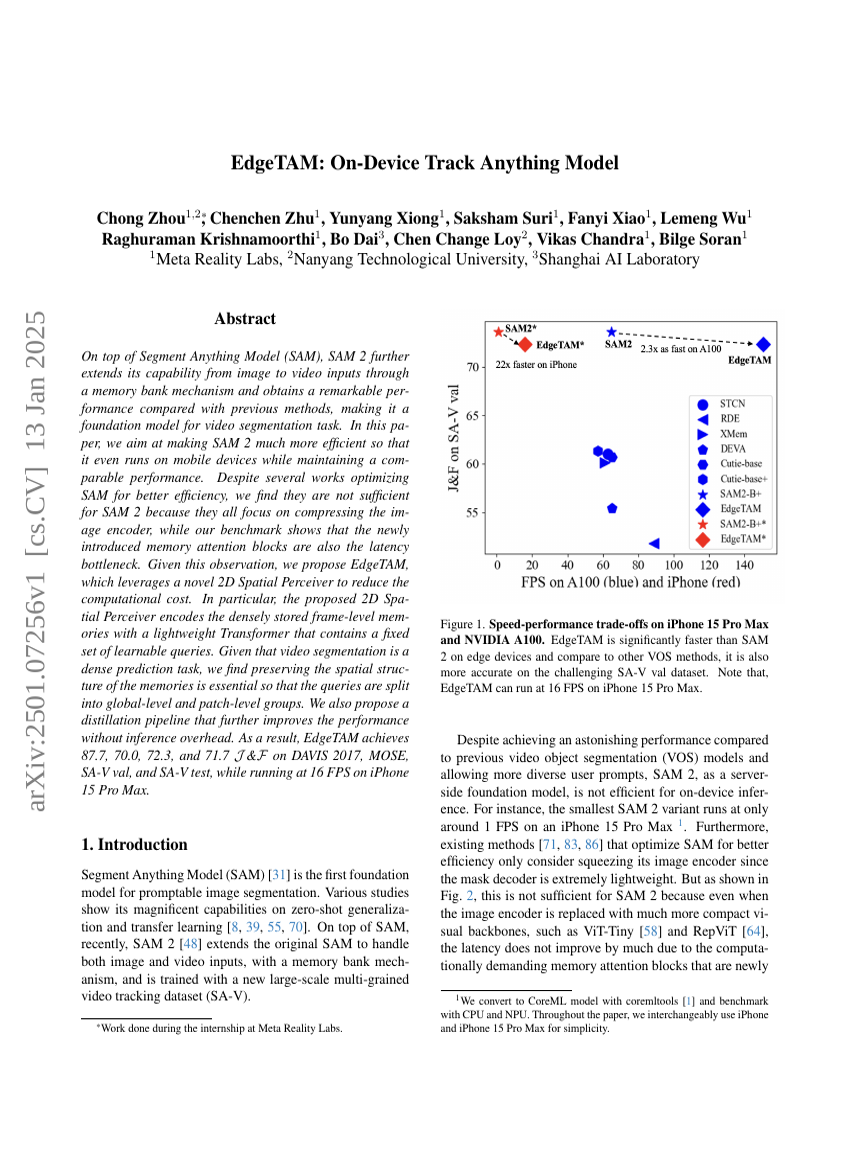
EdgeTAM:端侧可追踪任意模型
PixelRefer:面向任意粒度的时空目标指称统一框架
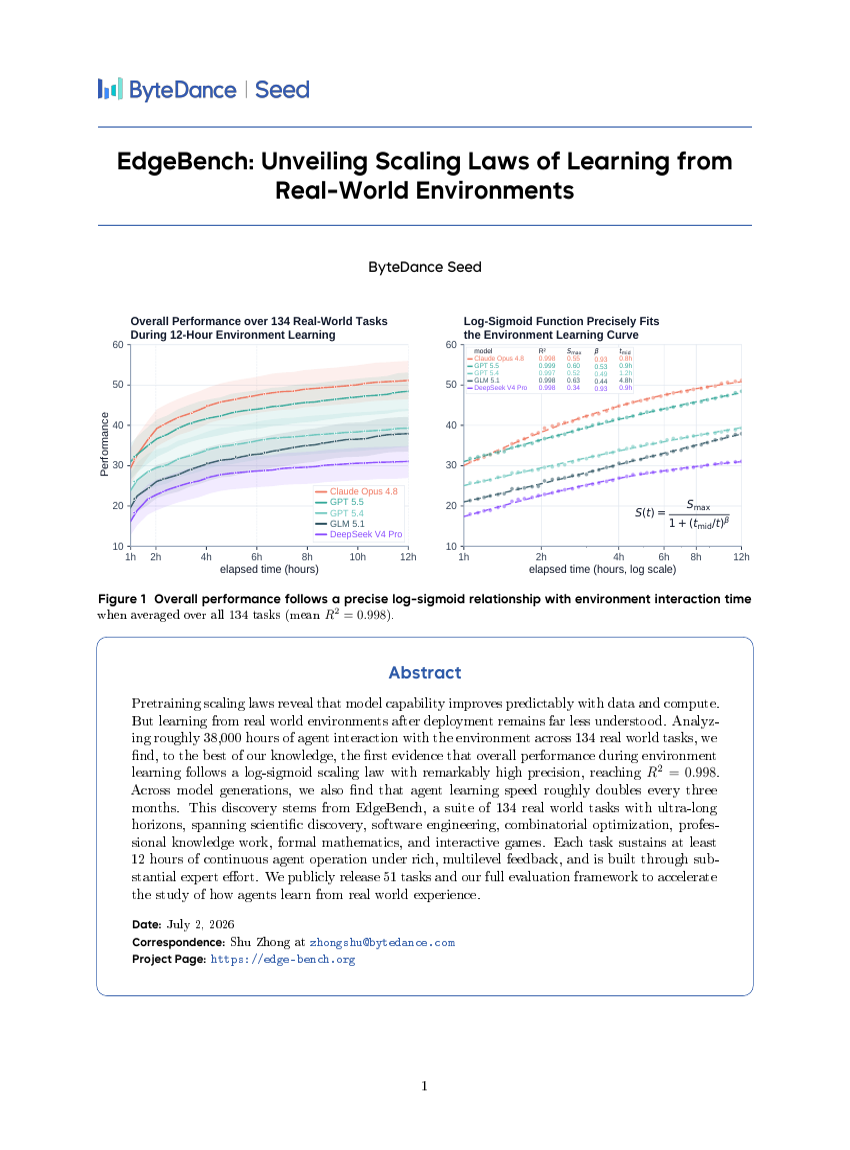
EdgeBench:揭示从真实世界环境中学习的标度律
ASPIRE:面向机器人的智能体技能发现
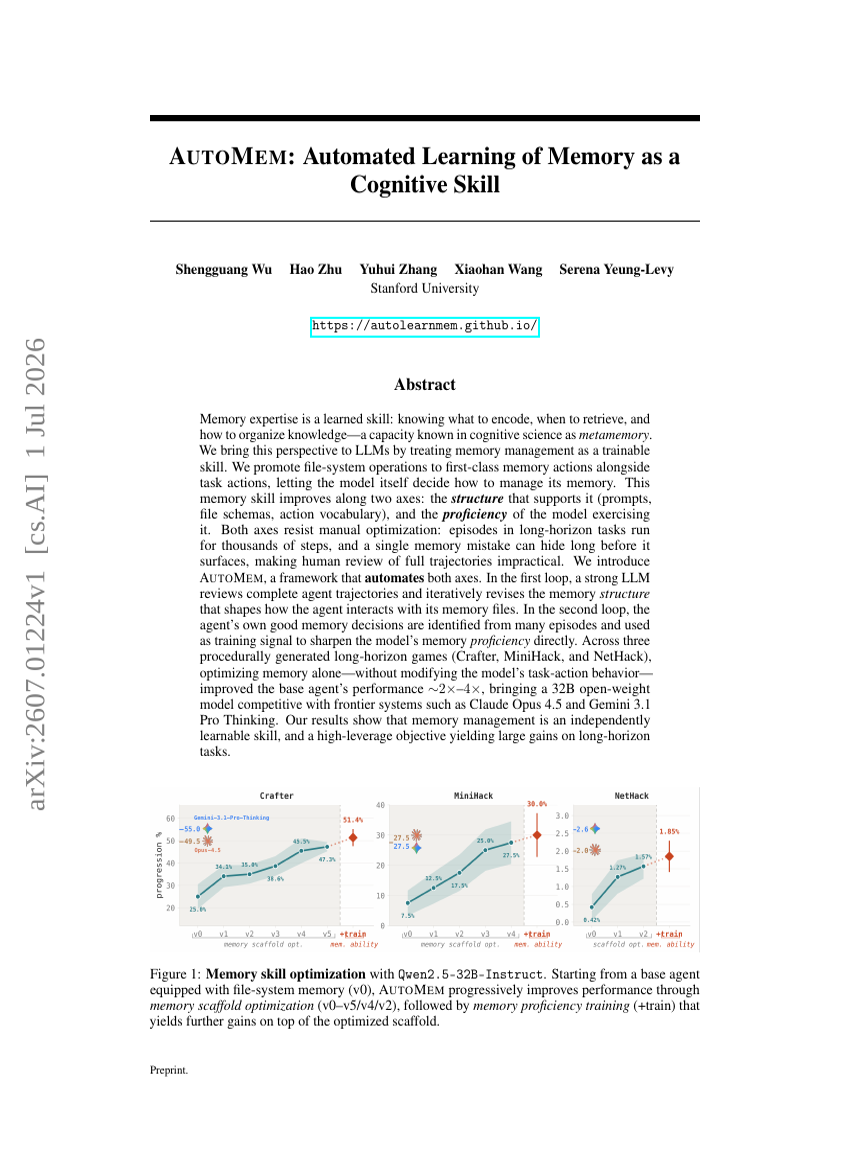
AUTOMEM:自动化学习记忆作为一项认知技能
解码工作定律:基于裕度控制、可证明精确的压缩几何空间连接
组合优化问题的神经证书定价方法
自主实验室协调器的最优资源利用
TERA:一个基于统一泰勒模型的可达性分析框架
感知以推理:解耦感知与推理实现细粒度视觉推理
基于Trie的级联IR管道高效实验计划
OrbitQuant:面向图像与视频扩散Transformer的数据无关量化方法
VLA-Corrector:面向自适应动作视野的轻量级检测与修正推理框架
Embodied.cpp:面向异构机器人的具身AI模型可移植推理运行时
优化训练策略的幻象:单调推理策略——大语言模型强化学习的真正目标
GeneBench-Pro:评估基因组学、定量生物学与转化生物医学中的多阶段统计推理
立场:AI/ML深度伪造研究与AI生成的非自愿亲密影像(AIG-NCII)存在错位
理解Grokking:岭回归中可证明的Grokking现象
扩散模型一致性的随机矩阵理论视角
语言模型记忆了多少?
混淆图集:用欺骗探针映射RLVR中诚实的涌现位置
立场:对齐社区正在无意间构建审查工具包
扩散模型与对数凹分布的高精度采样
AgenticDataBench:面向数据智能体的综合评测基准
多分辨率流匹配:通过分阶段采样实现无需训练的扩散加速
跃变为混合注意力模型
EvoPolicyGym:评估交互式环境中的自主策略演化能力
AgenticSTS:面向长周期LLM智能体的有界记忆测试平台
程序即权重:一种面向模糊函数的编程范式
MatAnyone 2:通过学习的质量评估器扩展视频抠图
EdgeTAM:端侧可追踪任意模型
PixelRefer:面向任意粒度的时空目标指称统一框架
EdgeBench:揭示从真实世界环境中学习的标度律
ASPIRE:面向机器人的智能体技能发现
AUTOMEM:自动化学习记忆作为一项认知技能
解码工作定律:基于裕度控制、可证明精确的压缩几何空间连接
组合优化问题的神经证书定价方法
自主实验室协调器的最优资源利用
TERA:一个基于统一泰勒模型的可达性分析框架
感知以推理:解耦感知与推理实现细粒度视觉推理
基于Trie的级联IR管道高效实验计划