Command Palette
Search for a command to run...
EdgeTAM:端侧可追踪任意模型
EdgeTAM:端侧可追踪任意模型
摘要
在分割任意模型(SAM)的基础上,SAM 2通过记忆库机制进一步将能力从图像扩展到视频输入,相较于以往方法取得了显著性能,成为视频分割任务的基础模型。本文旨在使SAM 2更加高效,甚至能在移动设备上运行,同时保持可比的性能。尽管已有一些工作针对SAM进行优化以提升效率,我们发现它们对SAM 2并不充分,因为这些工作都聚焦于压缩图像编码器,而我们的基准测试显示,新引入的记忆注意力模块同样是延迟瓶颈。基于这一观察,我们提出了EdgeTAM,利用一种新颖的2D空间感知器来降低计算成本。具体而言,所提出的2D空间感知器通过一个包含固定可学习查询集的轻量级Transformer,对密集存储的帧级记忆进行编码。考虑到视频分割是一个密集预测任务,我们发现保持记忆的空间结构至关重要,因此将查询拆分为全局级和块级组。我们还提出了一种蒸馏流水线,在不增加推理开销的情况下进一步提升性能。最终,EdgeTAM在DAVIS 2017、MOSE、SA-V验证集和SA-V测试集上分别取得87.7、70.0、72.3和71.7的J&F分数,同时在iPhone 15 Pro Max上以16 FPS运行。
一句话总结
来自Meta Reality Labs、南洋理工大学和上海人工智能实验室的研究人员提出了EdgeTAM,一种高效的设备端Track Anything模型,通过引入新颖的2D Spatial Perceiver来降低内存注意力瓶颈的计算成本,使用拆分的全局和patch级可学习查询保持空间结构,并采用蒸馏训练流程,在DAVIS 2017、MOSE、SA-V验证集和SA-V测试集上分别达到87.7、70.0、72.3和71.7的J&F,同时在iPhone 15 Pro Max上以16 FPS运行。
核心贡献
- 延迟分析表明,在SAM 2中,内存注意力模块(而非图像编码器)是计算的主要瓶颈。
- 2D Spatial Perceiver将密集的帧级内存编码为一组紧凑的可学习查询,这些查询被分为全局组和patch组,保留了空间结构以降低交叉注意力成本,同时保持相当的性能。
- 蒸馏训练流程对齐图像和视频分割特征与SAM 2的特征,在不增加推理开销的前提下提升准确性;EdgeTAM在DAVIS 2017上达到87.7 J&F,在MOSE上达到70.0,在SA-V验证/测试集上达到72.3/71.7,并在iPhone 15 Pro Max上以16 FPS运行。
引言
Segment Anything Model 2 (SAM 2)通过维护一个密集的内存库来实现可提示的视频分割,该内存库捕获来自过去帧的帧级特征和对象指针。然而,当前帧特征与这些密集编码的内存之间的交叉注意力造成了计算瓶颈,使得设备端推理不可行。以往仅加速SAM图像编码器的方法未能解决这一问题,因为在SAM 2中,即使编码器被大幅压缩,内存注意力模块仍主导着延迟。作者提出了EdgeTAM,通过2D Spatial Perceiver来应对这一瓶颈:一个轻量级模块将内存特征图压缩为一组更小的token,同时保留其2D空间结构。结合从原始SAM 2教师模型的特征式知识蒸馏流程,EdgeTAM在性能上匹配或超过规模大得多的模型,并在移动设备上以16 FPS运行,成为首个用于统一视频分割和跟踪的设备端模型。

数据集
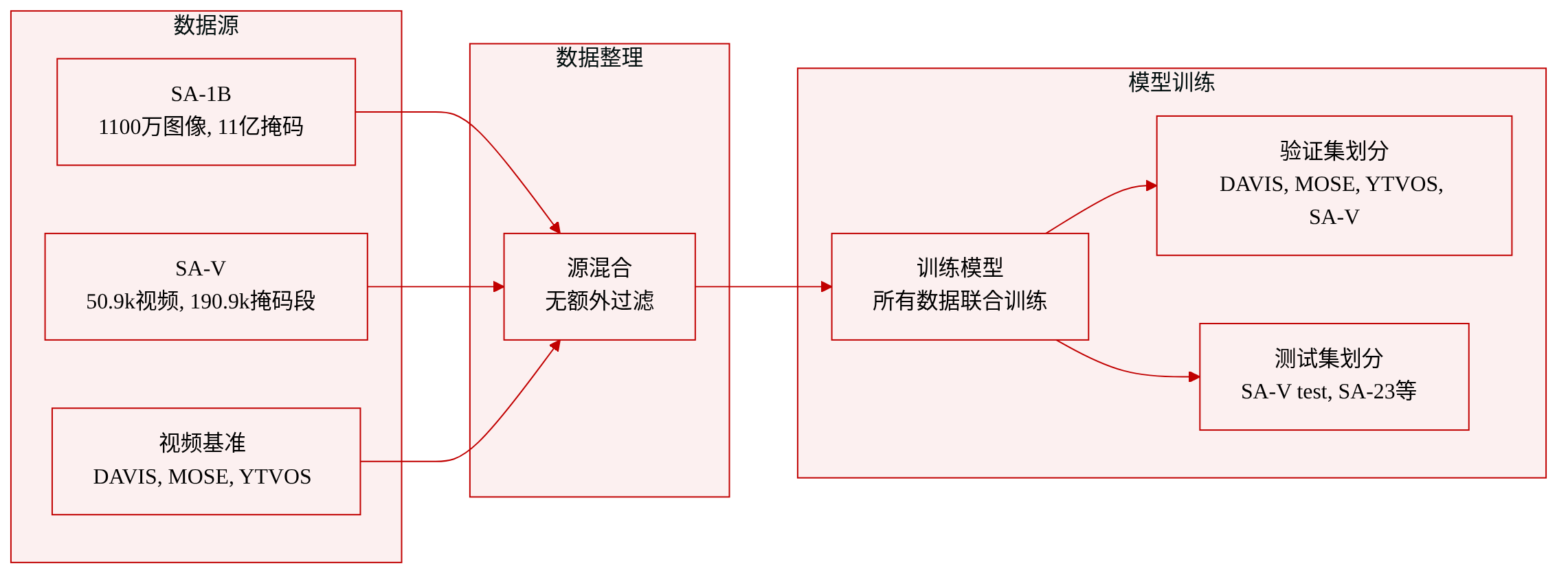
数据集构成与使用
作者从图像和视频分割数据集中构建了一个训练集合,并在多种设置下进行评估,以覆盖可提示和半监督任务。
- 训练数据
- SA-1B – 包含1100万张图像,标注了11亿个部分级和物体级掩码;平均分辨率为3300 × 4950像素。它是目前最大的图像分割数据集。
- SA-V – 包含5.09万个视频,有19.09万个masklet标注。视频平均时长14秒,重采样至24 FPS,标注帧率为6 FPS。场景分为54%室内和46%室外。其中,155/150个视频被保留作为验证/测试集,贡献了293/278个masklet,这些masklet经人工挑选以突显快速运动、复杂遮挡和物体消失等挑战。
- DAVIS、MOSE、YTVOS – 已有的视频目标分割基准,与SA-1B和SA-V一起被纳入训练混合数据。
除了原始数据集准备过程外,没有提及额外的过滤或裁剪策略。所有训练子集被联合用于训练模型;论文未披露这些数据集的混合比例或自定义处理步骤。
- 评估数据
- 可提示视频分割 (PVS) – 在9个数据集上进行零样本评估(在线和离线模式)。指标:J&F和G。
- 图像上的Segment Anything (SA) – 在SA-23上进行评估,这是一个包含23个开源数据集的集合,涵盖视频帧(被当作静态图像处理)和专用的图像分割集。指标:mIoU。
- 半监督视频目标分割 (VOS) – 在DAVIS 2017、MOSE、YouTubeVOS以及具有挑战性的SA-V验证/测试集的验证划分上测量性能,在这些任务中提供第一帧的真值掩码。指标:J&F和G。
方法
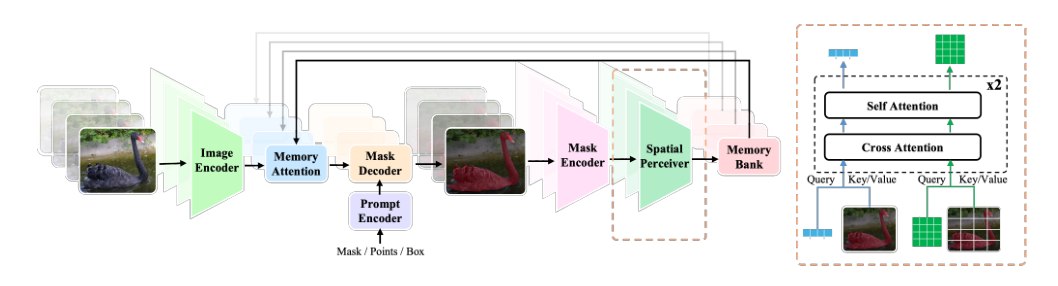
作者将提出的模型构建在Segment Anything Model 2 (SAM 2)之上,该模型包含四个主要组件:图像编码器Eimg、掩码解码器D、内存编码器Emem和内存注意力模块A。图像编码器利用分层主干网络(Hiera)输出步长为4、8和16的特征图:
{F4,F8,F16}=Eimg(I)
其中I表示当前帧输入。然后,特征F16通过内存注意力模块A与前T帧的内存特征{M1,M2,…,MT}进行融合,该模块作为一堆Transformer块运行。在此配置中,F16作为查询,而按时间拼接的内存特征作为键和值:
FM=A(F16,M1,M2,…,MT)
随后,掩码解码器D编码用户提示,并利用提示嵌入P和图像特征FM,F4,F8解码掩码预测O:
O=D(FM,F4,F8,P)
最后,F16和O被融合并由内存编码器Emem编码,以先进先出的方式更新内存库:
MT+1=Emem(F16,O)
为了将这一架构适配到移动设备,作者最初探索了朴素的修改,例如将重型图像编码器替换为紧凑的主干网络(RepViT-M1),并将内存注意力块的数量从4个减少到2个。
然而,基准测试显示,内存注意力仍然是一个显著的延迟瓶颈。内存注意力的计算复杂度为O(TCH2W2),涉及大量矩阵乘法,移动设备处理这些运算效率低下。由于减少内存帧数T会损害时序一致性,作者提出在执行内存注意力之前,先在空间上对内存进行总结,以利用视频中的冗余信息。
他们首先引入了一个Global Perceiver,受Perceiver架构的启发,将密集的内存特征Mt∈RC×H×W压缩为一小组向量Gt∈RC×Ng。这是通过可学习的潜在变量Zg,利用单头交叉注意力(CA)后接自注意力(SA)实现的:
Zg′=CA(Q(Zg),K(Mt+p),V(Mt+p)) Gt=SA(Zg′)
这种方法将复杂度降低到O(TCHWNg)。然而,由于输出不保持其空间结构,它缺乏密集预测任务(如视频目标分割)所需的显式位置信息。
为了解决这个问题,作者提出了2D Spatial Perceiver。该模块共享相同的架构,但为可学习的潜在变量Zl分配了空间先验,并约束每个潜在变量仅关注一个局部窗口。内存特征图被分割成不重叠的patch:
Mt′=window-partition(Mt) Zl′=CA(Q(Zl),K(Mt′),V(Mt′)),Lt′=SA(Zl′) Lt=window_unpartition(Lt)+p′
全局和2D spatial perceiver的输出在展平维度上连接。这种组合设计将总的内存注意力复杂度降低为O(TCHW(Ng+Nl))。
训练过程遵循一个蒸馏流程,分为图像分割预训练(Simg)和视频分割训练(Svid)阶段。
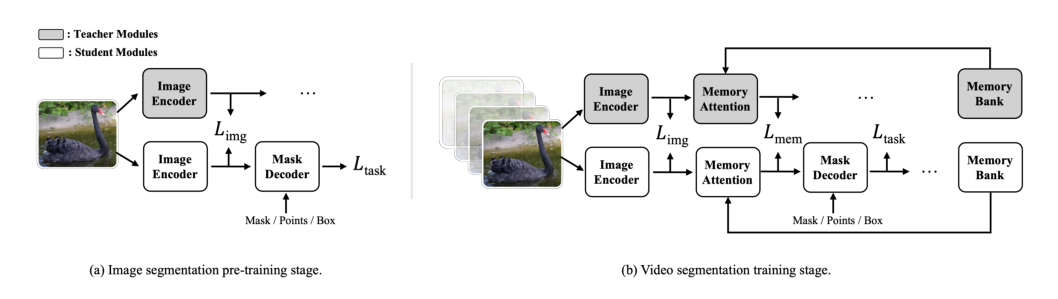
在图像预训练阶段Simg,作者采用任务特定的损失函数Ltask(dice损失、focal损失和L1损失),并使用MSE损失Limg对齐教师模型和学生模型之间的图像编码器特征图(F16)。预训练损失公式为:
Lsam=Ltask(O,GT)+γ⋅Limg(F16t,F16s)
在视频训练阶段Svid,任务特定损失中增加了用于遮挡预测的BCE损失。为确保学生模型的内存相关模块获得足够的监督,引入了额外的MSE损失Lmem,以对齐来自教师和学生的内存注意力输出FM。总损失变为:
Lsam2=Ltask(O,GT)+α⋅Limg(F16t,F16s)+β⋅Lmem(FMt,FMs)
实验
EdgeTAM在可提示视频分割(在线/离线模式)、图像segment anything以及半监督视频目标分割等任务上进行了评估,涉及多个数据集,包括SA-V、DAVIS、MOSE和YTVOS。该模型展示了很强的零样本性能:它超越了之前的可提示视频方法,实现了与规模大得多的SAM变体相当的图像分割精度,并匹配或超过了专用的VOS模型,同时保持紧凑和快速,适合设备端部署。消融实验证实,2D Spatial Perceiver、蒸馏以及所选的编码器-注意力配置对于这种效率-精度权衡至关重要,定性分析显示EdgeTAM在很大程度上复现了SAM 2的行为,但在快速运动和遮挡的情况下,偶尔会继承其跟踪粒度失败的问题。
EdgeTAM仅使用公开数据,就达到了与SAM和SAM 2相当的零样本分割精度,并且随着额外的点击变得更加有竞争力。在五个输入点的情况下,它超越了图像专用的SAM-H(81.7 vs 81.3 mIoU),并在iPhone上提供实时推理(40.4 FPS),使得单个设备端模型可以同时用于图像和视频分割。具备五次点击的EdgeTAM达到81.7 mIoU,优于SAM-H(81.3),并匹配了在SA-1B上训练的SAM 2,无需访问SAM 2的内部数据。在iPhone上,EdgeTAM以40.4 FPS运行,比SAM 2的1.3 FPS快30倍以上,适合实时设备端使用。
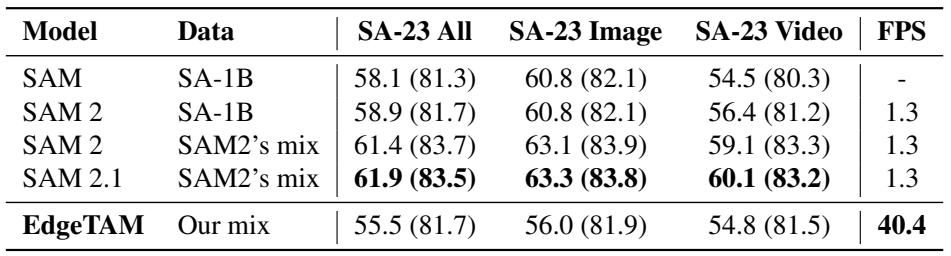
仅使用SA-V和SA-1B训练的EdgeTAM,在零样本设置下在MOSE、DAVIS和YTVOS上匹配或超过了之前的视频目标分割模型,展现出强大的泛化能力。在SA-V上,它超越了除SAM 2和SAM 2.1之外的所有对比方法,而其设计优先考虑边缘设备上的低延迟,而非高GPU吞吐量。在零样本设置下,EdgeTAM在MOSE、DAVIS和YTVOS上与那些在特定数据集上训练的最先进的VOS模型相比,性能相当或更优。在SA-V验证和测试集上,EdgeTAM超越了除SAM 2和SAM 2.1之外的所有比较方法,其推理速度优化针对边缘设备,这些设备上GPU流多处理器利用率仍较低。
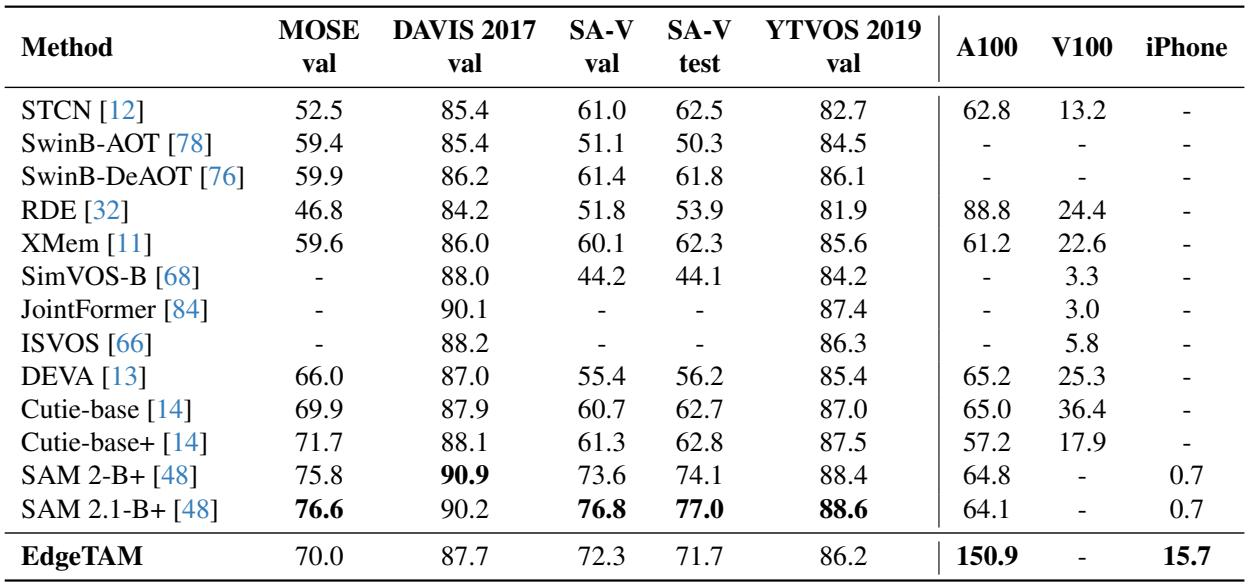
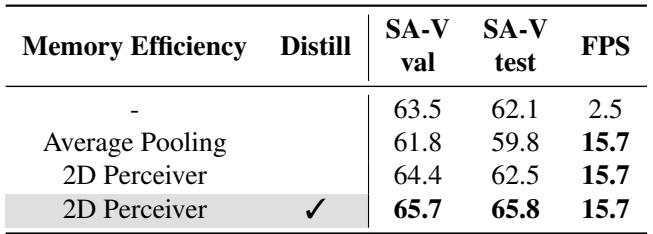
2D Spatial Perceiver取代了内存下采样,在加速推理的同时提高了相对于基线和平均池化的准确性。蒸馏进一步提升了性能,且同时使用全局和2D latents获得了最佳的速度-精度权衡。最佳配置使用RepViT-M1和两个内存注意力块,2D Perceiver内部的自注意力增强了特征交互。2D Perceiver将基线速度提升了6.3倍,且在SA-V上性能优于平均池化。对2D Perceiver添加蒸馏可使SA-V验证集J&F提升1.3,SA-V测试集提升3.3。同时采用全局和2D latents在保持更优性能的同时实现了最高加速。RepViT-M1搭配两个内存注意力块在主干网络和块数量的选择中提供了最佳权衡。2D Perceiver中的自注意力通过让不重叠的局部patch共享信息来改善结果。
EdgeTAM在不同提示类型下实现了有竞争力的零样本视频目标分割精度,超越了之前基于SAM的内存方法,并接近SAM 2和SAM 2.1的性能。随着额外点击提示的增加,与SAM 2的差距缩小,甚至在五次点击时超越SAM 2,突显了其利用细粒度用户引导的强大能力。尽管针对边缘设备进行了优化,该模型在多个视频数据集上展现了稳健的泛化能力。在三次点击下,EdgeTAM (72.7)在零样本分割中超过了SAM + Cutie (70.1)和SAM + XMem++ (68.4),几乎匹配SAM 2 (73.2)。在五次点击下,EdgeTAM (75.5)略微超过SAM 2 (75.4),表明更精细的提示输入可以弥补更大模型的架构优势。

EdgeTAM仅使用公开数据训练,就在图像和视频上实现了有竞争力的零样本分割精度,匹配了SAM和SAM 2,甚至在额外点击提示下超越了SAM-H。针对设备端推理进行了优化,它在移动硬件上实时运行,并对多个视频目标分割基准具有很强的泛化能力。通过逐步的用户引导,该模型可以超越像SAM 2这样更大的架构,展示了对细粒度输入的有效利用。其设计(包括2D Spatial Perceiver和蒸馏)在不依赖专有数据集的情况下,实现了良好的速度-精度权衡。