Command Palette
Search for a command to run...
组合优化问题的神经证书定价方法
组合优化问题的神经证书定价方法
Jingyi Chen Xinyuan Zhang Xinwu Qian
摘要
组合优化问题之所以困难,是因为可认证的离散结构导致指数级搜索空间。人们需要遍历指数级数量的候选解来证明最优性,然而一旦给定路径、打包或覆盖的结构可行性,便可在多项式时间内验证。本研究提出神经证书定价方法,在无监督学习框架下利用这种不对称性。神经网络被训练用于预测证书层面的对偶价格,而结构化恢复层则构建诱导的原始边际。NCP可视为摊销分离:无需枚举违反的不等式,而是学习残差价格,通过其聚合效应影响恢复过程。当证书一致性条件成立时,恢复的边际具有全局可行性,局部理论表明预测价格的一阶误差仅导致目标值的二阶损失。在三类组合优化问题中,NCP要么大幅优于最先进的神经基线方法,要么以极少的计算时间达到相当性能,并展现出更强的分布外泛化能力。
一句话总结
莱斯大学的研究者提出了神经证书定价(NCP),这是一个无监督学习框架,能够预测证书级的对偶价格,并利用结构化恢复层摊销组合优化的分离过程,在满足证书一致性条件和一阶误差鲁棒性的前提下实现全局可行性,在三个问题类别上要么以大幅优势超越最先进的神经基线方法,要么以极小比例的计算时间达到相同水平,并展现出更强的分布外泛化能力。
核心贡献
- 神经证书定价(NCP)训练一个神经网络来预测证书级的对偶价格,并通过结构化恢复层以无监督方式生成可行的原始边缘分布;该过程是一种摊销分离,学习残差价格,其聚合效应在无需枚举被违反不等式的情况下进入恢复阶段。
- 局部稳定性结果证明,在证书一致性条件下,恢复是平滑的,预测价格中的一阶误差仅导致原始目标值在原始实现点附近的二阶退化。
- 在三个组合优化问题类别上,NCP 要么以大幅优势超越最先进的神经基线方法,要么以极小比例的计算时间达到相同水平,并展现出更强的分布外泛化能力。
引言
图上的组合优化支撑着网络系统中的决策,其中局部选择必须满足全局耦合约束,从而产生一个指数级的搜索空间。经典求解器依赖结构化搜索,而近期基于学习的方法则预测解的组成部分,如分数、策略或松弛边缘分布,将全局有效性的认证留给一个独立的下游解码或修复步骤。这种分离忽视了固有的不对称性:即使找到一个候选解是困难的,验证它却可以是高效的。作者提出了神经证书定价(NCP),这是一个无监督框架,学习为证书条件恢复层生成定价信号。通过在一个隔离局部一致性、证书诱导结构以及保留的耦合约束的边缘空间中表示离散对象,NCP 利用定价信号直接恢复一个证书一致的原始边缘分布,从而允许训练直接优化原始目标,无需标注解,并将认证从事后检查转变为一种完整的解机制。
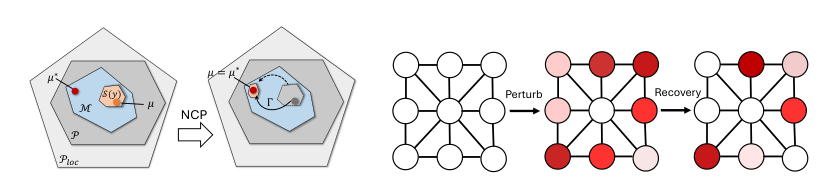
方法
作者提出了神经证书定价(NCP),这是一个通过学习的成本扰动来收紧可处理证书条件恢复,从而求解基于图结构的组合优化问题的框架。其出发点是自由能公式 p⋆(G)=minμ∈MGFG(μ),其中 MG 为精确边缘多面体,FG(μ)=⟨c,μ⟩−τHM(μ)。在 MG 上直接优化是难以处理的,而典型的松弛 PG(局部约束加一组显式全局耦合约束 AGμ≤bG)通常是松散的。关键的洞见在于,虽然刻画完整的多面体是困难的,但如果存在一个结构性证书 y∈YG 能够诱导出一个可处理的恢复集 SG(y)⊆Ploc(G),那么验证某个特定的边缘向量 μ 是否属于 MG 就要容易得多。对许多组合问题而言,这样的证书天然存在:节点势能诱导路由的无环序,缩减成本结构将分配限制在局部子问题上,冲突或团覆盖则简化了打包约束。当不存在显式耦合约束时,SG(y)⊆MG 直接成立;否则,AGμ≤bG 的对偶价格 λ≥0 将与 y 一起用于维持可行性。
NCP 以学习到的成本扰动 Γ∈R∣E∣ 增强了这一证书机制,该扰动扮演残差定价信号的角色,能够收紧仅靠拉格朗日乘子无法实现的恢复程度。对于一个固定的证书 y、对偶变量 λ 和扰动 Γ,原始恢复映射定义为
QG(Γ,y,λ)=argμ∈SG(y)min{FG(μ)+⟨Γ+AG⊤λ,μ⟩}.当 SG(y) 包含于 MG 时,每一个恢复得到的 μ^ 都会为原始问题提供一个有效的原始界 FG(μ^)。扰动 Γ 充当了那些从可处理恢复集中省略的有效不等式价格的替代。命题3.2对此进行了形式化:若证书 y 覆盖了一个最优解 μ∗,且被省略的不等式为 BGμ≤dG,则令 Γ∗=BG⊤z∗(其中 z∗ 为这些约束的 KKT 乘子)可保证 μ∗∈QG(Γ∗,y,λ∗)。因此,学习到一个合适的 Γ 原则上可以恢复精确的最优解。
为确保恢复映射的输出是一个可行的边缘分布,该框架要求满足证书一致性条件。令 CG 为一个证书读出映射,从边缘向量中提取证书。一对 (y,λ) 被称为在扰动 Γ 下的一致证书,如果
y=CG(μ^),AGμ^≤bG,λ≥0,λ⊤(AGμ^−bG)=0,其中 μ^=QG(Γ,y,λ)。命题3.3表明,在一致性条件下,μ^∈MG,且恢复点满足一个偏移最优性条件 FG(μ^)−FG(ν)≤⟨Γ,ν−μ^⟩ 对任意 ν∈SG(y)∩PG 成立。这将寻找良好扰动的问题转化为一个均衡约束问题:寻找 Γ,y,λ,在 y=CG(μ)、μ∈QG(Γ,y,λ) 以及 KKT 互补条件 0≤λ⊥bG−AGμ≥0 的约束下最小化 FG(μ)。这一 Oracle 刻画(OC)是一个双层规划;任何可行解都能提供一个原始界,因为 μ 是一个有效的边缘分布。
NCP 通过训练一个神经网络 Γθ(G) 直接从实例 G 预测扰动,将这一搜索过程摊销到所有实例上。对于给定的 θ,前向传播通过一个带阻尼的投影不动点迭代来求解一致性系统。从一个初始证书猜测 z0=(y0,λ0) 开始,更新为
μt+1=QG(Γθ(G),yt,λt),zˉt+1=(CG(μt+1),Dρ(λt,μt+1)),zt+1=(1−α)zt+αzˉt+1,其中 Dρ(λ,μ)=ΠR+mG[λ+ρ(AGμ−bG)] 是一个投影对偶上升步,ρ>0 为步长,α∈(0,1] 为阻尼因子,可在不改变不动点的前提下稳定收敛。收敛后,恢复的边缘分布为 μθ(G)=QG(Γθ(G),y⋆,λ⋆),无监督训练损失简单地定义为
LNCP(θ)=EG∼D[FG(μθ(G))],在未受扰动的目标 FG 下进行评估(扰动仅在恢复和一致性内部使用)。梯度通过证书一致性不动点的隐式微分进行计算,从而避免了对多次迭代进行反向传播。
理论分析通过揭示一个有利的局部结构来支持这一学习方案。在一个满足严格互补条件且隐函数定理适用的正则 OC 解处,双层问题局部地简化为对 ΦG(Γ)=FG(μ^G(zΓ,Γ)) 的无约束光滑最小化,其中 zΓ 为一致性等式的隐式解。定理4.1表明,ΦG 的稳定点与局部等式约束 OC 的 KKT 稳定点重合。此外,定理4.2建立了二阶值稳定性:在一个稳定扰动附近,Γ 中 ε 量级的失配仅导致目标值 O(ε2) 的变化。推论4.3将相对于真实最优 p⋆(G) 的次优差距分解为结构性证书差距 Δcert 和局部优化残差。如果证书族与底层离散结构兼容,且网络在稳定点的邻域内学习到一个 Γ,则残差项为 O(ε2);当命题3.2的条件满足时,证书差距也随之消失。这一分析解释了 NCP 为何能够恢复近乎最优的原始界:训练目标集中在一个光滑的景观上,在该景观中,近似一致性只会转化为微小的值误差。
实验
在三个组合优化问题(最大独立集、广义分配和基本最短路径)上,于分布外条件下进行评估,NCP 展现出对变化目标的鲁棒性以及对更大规模实例的可扩展性,同时保持与单次传播方法相当的效率。消融研究证实,结构证书和学习到的扰动不可或缺,学习使原始间隔缩小到规范拉格朗日界以下。缩减后的目标在稳定扰动附近展现出二阶稳定性,与理论预测一致,支持稳定的优化过程。
在无权重的最大独立集基准测试上,NCP 实现了近乎最优的比例,几乎完全求解了大多数实例,同时推理时间接近最快的单次传播方法。与其他神经基线方法相比,NCP 在所有三类图上均保持鲁棒,尤其是在 IMDB 上,它以满分成绩匹配精确求解器 KaMIS,且延迟远低于扩散方法或迭代方法。NCP 在所有200个 IMDB 实例上恢复了精确解,与 KaMIS 持平,而 Erdos-Neural 仅求解了30个,Fast-T2T 求解了198个。在 TWITTER 上,NCP 以1.93毫秒的时间获得了0.9881的比例和120/196的精确求解数,优于 Erdos-Neural、DIFUSCO 和 Fast-T2T,同时比 DIFUSCO 快150倍以上。
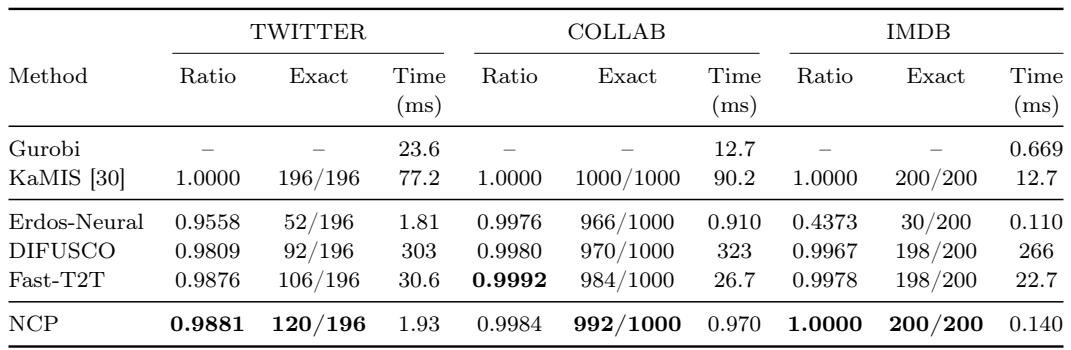
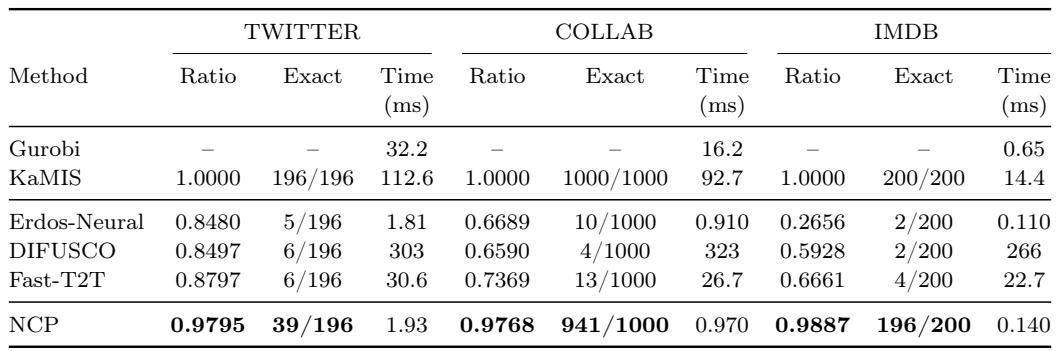
在加权最大独立集任务上,NCP 在三项基准测试中均保持了0.97以上的近似比例,并在大多数实例中恢复了精确解。神经基线方法 Erdos-Neural、DIFUSCO 和 Fast-T2T 在更大的图 COLLAB 和 IMDB 上性能急剧下降,而 NCP 保持鲁棒,并在亚毫秒到低毫秒时间内完成推理。NCP 分别达到了0.9795(TWITTER)、0.9768(COLLAB)和0.9887(IMDB)的比例,并分别精确求解了39/196、941/1000和196/200个实例。在 COLLAB 和 IMDB 上,Erdos-Neural 的比例降至0.67和0.27,DIFUSCO 降至0.66和0.59,Fast-T2T 降至0.74和0.67,显示出这些方法对加权目标的脆弱性。NCP 在 TWITTER 上的推理时间不到2毫秒,COLLAB 上不到1毫秒,IMDB 上为0.14毫秒,将高求解质量与单次传播般的速度结合在一起。
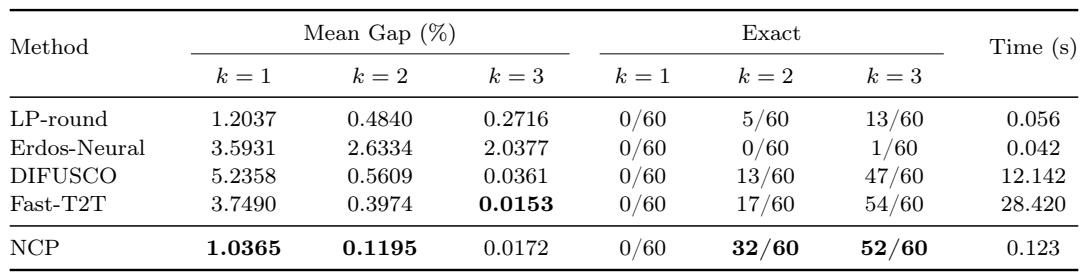
在 GAP 基准测试上,NCP 在 top-1 和 top-2 掩码上实现了最低的平均最优性差距,优于 LP-round 基线。对于 top-3 掩码,其差距与最佳竞争者几乎持平,但运行时间缩短了两个数量级以上。该方法在 k=2 时比其他神经方法精确求解了更多实例,表明其学习到的证书生成了一个包含近乎最优 LP 解的紧凑候选集。NCP 在 k=1 和 k=2 时实现了最佳平均差距,在 k=3 时其差距与 Fast-T2T 几乎相同,但运行速度快200倍以上。在 k=2 时,NCP 精确求解了60个实例中的32个,而 Fast-T2T 为17个,DIFUSCO 为13个。NCP 在所有 k 值上均较 LP-round 持续改进,证明了其学习证书的价值。
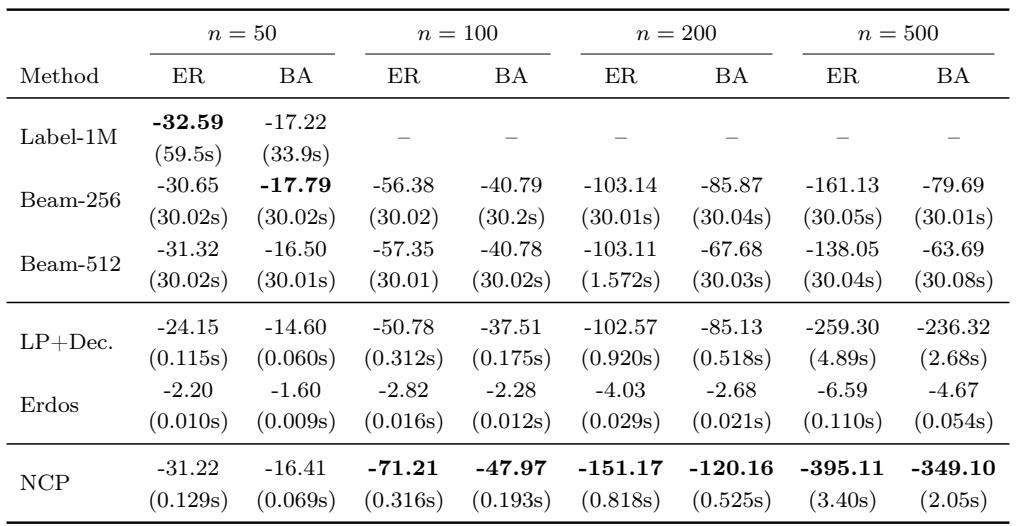
在 ER 和 BA 图上,NCP 在小规模时达到了接近密集标注方法的路径成本,并且随着图规模的增大,始终优于 LP+Dec. 和束搜索基线。其运行时间保持在几秒以内,远快于标注方法和束搜索,后者每个实例需要数十秒。性能差距随着图的增大而扩大,反映了学习证书结构的可扩展性。在 n=50 时,NCP 的成本仅略落后于 Label-1M(例如,在 ER 上为 -31.22 对 -32.59),而推理时间则从数十秒缩短到不足0.13秒。在标注方法不可行的大图上,NCP 在所有可扩展方法中始终实现了最佳的路径成本,大幅超越 LP+Dec. 和束搜索。随着图规模的增大,NCP 相对于 LP+Dec. 的优势更加显著:在 ER 上 n=500 时,NCP 获得的成本为 -395.11,而 LP+Dec. 仅为 -259.30。
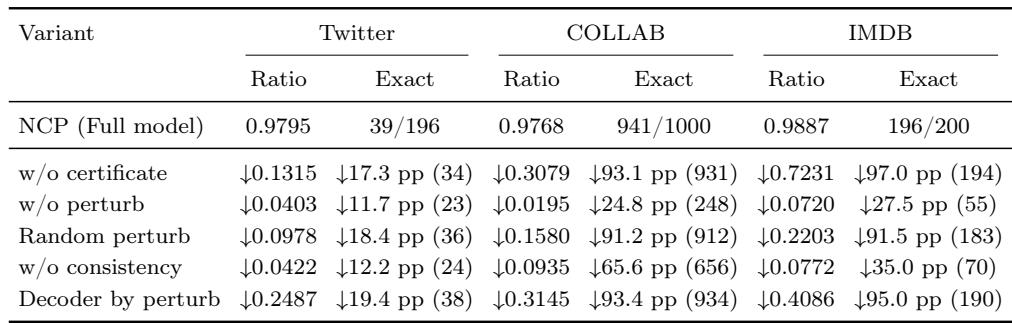
在加权最大独立集上对 NCP 各组件进行的消融实验表明,结构证书是不可或缺的:在 IMDB 和 COLLAB 上去除它导致了最大幅度的性能下降,比例下降幅度高达0.724,几乎所有精确解都丢失了。直接从扰动中恢复原始解(Decoder by perturb)在 Twitter 上造成了最大幅度的比例退化,在 COLLAB 上与去除证书的效果相当,这证实了原始信号是通过学习到的映射重建的,而非仅从 Γ 获得。学习到的证书扰动优于随机扰动,去除一致性损失会显著降低精确求解数量,凸显了证书一致性的重要性。去除结构证书使 IMDB 上的比例下降了0.724,COLLAB 上下降了0.308,精确求解数分别从196降至2、从941降至10。直接从 Γ 解码使 Twitter 上的比例下降了0.249,IMDB 上下降了0.409,在 Twitter 上造成了最大幅度的比例损失,在 IMDB 上将精确求解数从196降至6。随机化扰动使 COLLAB 上的精确求解数减少了912,IMDB 上减少了183,表现不如学习到的证书扰动,表明结构化扰动至关重要。完全去除扰动(w/o perturb)导致的退化(COLLAB 上精确解减少248)比随机扰动更温和,但仍然损害性能,凸显了学习自适应的必要性。消融证书一致性导致 COLLAB 上精确解减少656,IMDB 上减少70,远差于去除扰动,表明一致性指导了有效的原始恢复。
评估涵盖最大独立集(无权重和加权)、GAP 基准测试以及合成图上的路径规划,通过与精确求解器和神经基线的对比,验证了 NCP 的求解质量和速度。NCP 始终实现了近乎最优的结果,经常与精确求解器持平,同时保持了单次传播般的推理速度,并且在其他基于学习的方法性能急剧下降的更大规模和加权实例上保持鲁棒。学习到的结构证书对性能至关重要,消融实验证实去除它或绕过原始恢复会大幅降低准确率,而一致性损失进一步稳定了学习过程。总体而言,NCP 在多样的组合优化任务上提供了一种准确性、速度和可扩展性的强有力组合。