Command Palette
Search for a command to run...
AUTOMEM:自动化学习记忆作为一项认知技能
AUTOMEM:自动化学习记忆作为一项认知技能
Shengguang Wu Hao Zhu Yuhui Zhang Xiaohan Wang Serena Yeung-Levy
摘要
记忆专长是一项可习得的技能:知道编码什么、何时检索以及如何组织知识——认知科学中称之为元记忆。我们将这一视角引入大语言模型,把记忆管理视为可训练的技能。我们将文件系统操作提升为与任务操作同等的第一类记忆动作,让模型自行决定如何管理其记忆。这种记忆技能沿两个轴提升:支持它的结构(提示、文件模式、动作词汇),以及运用它的模型熟练度。两个轴都难以手动优化:长程任务中的情节运行数千步,一次记忆失误可能潜伏很久才显现,使得人工审查完整轨迹不可行。我们提出AUTOMEM框架,自动化两个轴的优化。在第一个循环中,我们自举记忆结构:让智能体执行任务,记录并归纳简洁的记忆模式。在第二个循环中,智能体自身做出的良好记忆决策从众多情节中被识别出来,并用作训练信号直接提升模型的记忆熟练度。在三个程序生成的长程游戏(Crafter、MiniHack和NetHack)中,仅优化记忆——不修改模型的任务动作行为——就将基础智能体的性能提升了约2-4倍,使一个32B开放权重模型接近前沿系统如Claude Opus 4.5和Gemini 3.1 Pro Thinking的表现。我们的结果表明,记忆管理是一项可独立学习的技能,且是在长程任务上获得大幅增益的高杠杆目标。
一句话总结
斯坦福大学研究人员提出AUTOMEM,该框架将记忆管理视为一项可学习的认知技能,通过两个迭代循环自动完成记忆结构设计和模型熟练度的优化,在程序生成的长时序游戏Crafter、MiniHack和NetHack上性能提升约 ∼2–4×,并使一个32B开源权重模型能够与Claude Opus 4.5和Gemini 3.1 Pro Thinking等前沿系统竞争。
核心贡献
- AUTOMEM是一个框架,它自动化地沿着两个轴优化LLM agent的记忆技能:记忆结构(提示词、文件模式、动作词汇)以及模型在记忆决策上的熟练度。
- 该框架采用双循环设计,其中一个循环使用强大的LLM来审查完整的长时序轨迹,并迭代地修订记忆脚手架;第二个循环从许多幕次中提取成功的记忆决策作为训练信号,以锐化agent的记忆熟练度,而不改变其任务-动作行为。
- 在Crafter、MiniHack和NetHack上,仅通过AUTOMEM优化记忆就能实现2到4倍的性能提升,将32B开源权重模型提升到可媲美Claude Opus 4.5和Gemini 3.1 Pro Thinking的水平,这表明记忆管理是一项可独立学习的、高杠杆的技能。
引言
作者们针对固定大小上下文窗口对大型语言模型(LLM)造成的瓶颈,将外部记忆管理视为一项可独立训练的技能,而非固定的架构模块。以往的工作通常将检索机制或静态缓冲区硬编码入系统,但在跨越数万个步骤的幕次中,人工手动优化记忆行为是不可行的。作者们将文件系统操作提升为一级动作,并引入AUTOMEM,该框架中的一个元LLM通过审查完整的幕迹来自动改进记忆脚手架(提示词、文件模式及验证逻辑)以及agent的参数化记忆熟练度,具体通过针对性微调一个专用记忆专家来实现,从而在长时序游戏环境中带来2到4倍的性能增益。
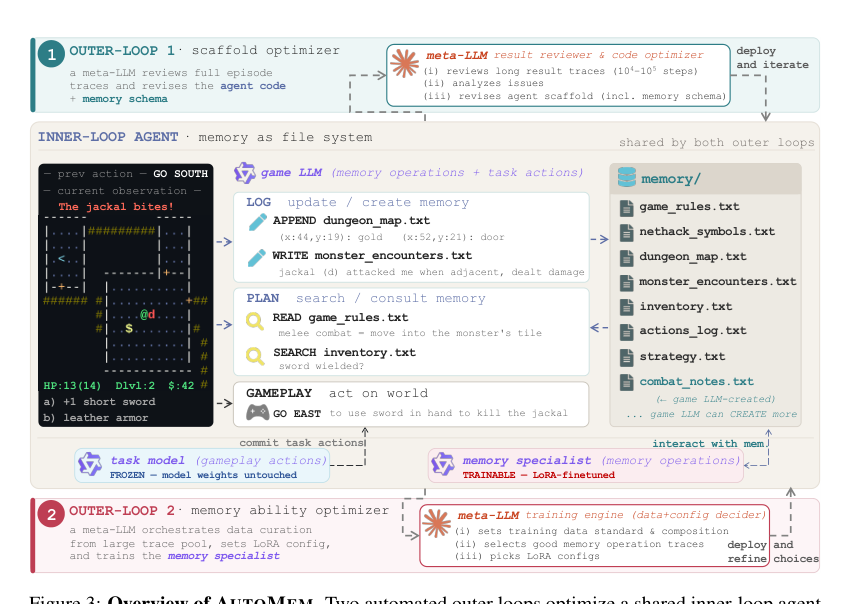
方法
作者们提出AUTOMEM,一个沿着结构和熟练度两个轴自动化记忆技能优化的框架。这通过两个顺序的外部循环实现,它们作用于共享的内循环agent。
内循环由一个LLM agent执行长时序任务的每个幕次。该agent配备了一个磁盘上的文件目录作为其外部记忆。在每一步中,agent运行两个例程。LOG例程确定关于环境对上一个动作的响应,哪些信息值得记录,比如追加到现有文件、创建新文件或重写条目。PLAN例程确定当前需要回忆什么来采取行动,通过跨文件搜索、读取特定条目,并提交下一个世界动作。通过将文件系统操作提升为模型动作空间中的一级记忆动作,记忆变成了一项可学习的技能,而非固定机制。
第一个外部循环优化支撑记忆技能的结构。agent脚手架,包括代码、提示词、文件模式和动作词汇,由元LLM迭代修订。由于记忆决策的后果在长时序任务中往往延迟出现,优化信号必须是轨迹级别的。元LLM被提供完整的幕次轨迹,包括每一步的日志、产生的记忆目录以及agent代码本身。它充当代码审查者,识别脚手架上导致失败的点。例如,元LLM可能发现一个无界地图文件正在累积重复条目,并响应引入基于坐标键的去重格式。
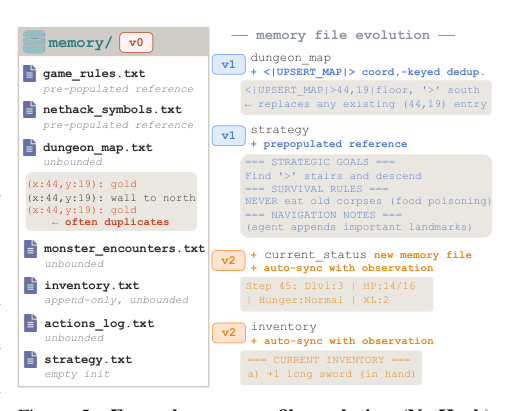
每次迭代都以测量到的改进为准入条件。重写的agent在与前一版本相同的固定种子上运行,只有平均进度提升时才保留修订。大致收敛后(通常经过几次迭代),脚手架已经吸收了代码修订所能表达的内容。
在脚手架优化之后,模型在参数层面导航其记忆的能力成为剩下的瓶颈。第二个外部循环通过训练模型的记忆熟练度来解决这一问题。元LLM充当训练引擎,端到端地编排监督训练过程。它读取内循环agent代码和一个幕迹池,推导出选择标准并生成监督训练数据。训练集中的每个样例都是由内循环模型在一个幕次中生成的逐字文本。元LLM选择哪些响应需要强化,充当对模型自身行为的过滤器。
为了确保训练有效吸收这些精选数据,元LLM训练引擎将数据选择逻辑、数据组合和LoRA训练配置作为一个整体决策来联合编排,并在多次迭代试验中优化这三者。因为记忆是可分离的技能,所以将其作为一个独立目标进行训练,而不是对完整幕次进行微调。在推理时,内循环运行两个共享单一对话历史的模型实例。记忆专家,即经过LoRA微调的副本,处理LOG例程以及PLAN例程中关于记忆查询的部分。游戏模型,即未修改的基础模型,负责提交世界动作。这种分离确保训练信号专注于记忆操作行为,同时保留基础模型产生规范格式世界动作的能力。
实验
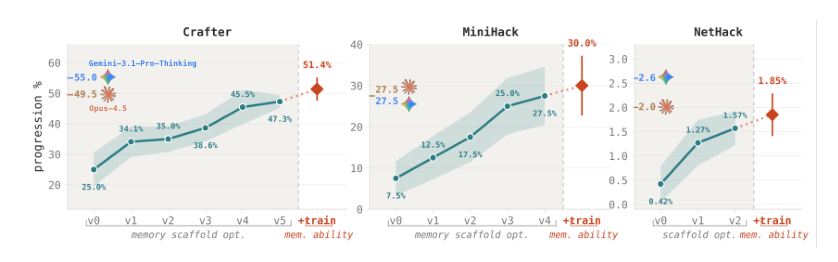
实验评估了一个Qwen2.5-32B-Instruct agent在三个程序生成的长时序游戏上的表现,其中仅通过修订提示词和外部记忆模式的脚手架优化(无需任何模型权重改变)就将任务进度提高了三倍以上,性能优于更大模型和标准上下文窗口方法。再加上独立的记忆熟练度训练循环进一步提升性能,使开源agent达到了与前沿专有系统竞争的水平。定性分析表明,优化后的脚手架减少了浪费的任务重复和冗余记忆操作,同时压缩了上下文;并且经过训练的专家内化了“先查询后写入”模式,改善了记忆使用,显示出记忆管理是长时序agent行为的一个高效轴。
从具有基本上下文管理的32B开源权重模型开始,优化agent的记忆脚手架使长时序游戏的进度率翻倍或三倍,加上记忆训练循环则带来进一步的互补增益,使模型接近前沿专有系统。这些改进来自结构性变化,它们将冗余日志减少了95%,并通过训练模型在写入前先查询已有记忆,减少了记忆浪费。仅脚手架优化就将Crafter的进度率提升1.9倍,MiniHack提升3.7倍,NetHack提升3.7倍。同时进行脚手架优化和记忆训练后,32B模型在Crafter上达到51.4%,MiniHack上达到30.0%,NetHack上达到1.9%,与Claude-Opus-4.5(49.5%、27.5%、2.0%)相当。演变后的记忆结构将每步记忆增长从138个字符减少到6个字符(减少95%),消除了无界的追加式日志膨胀。
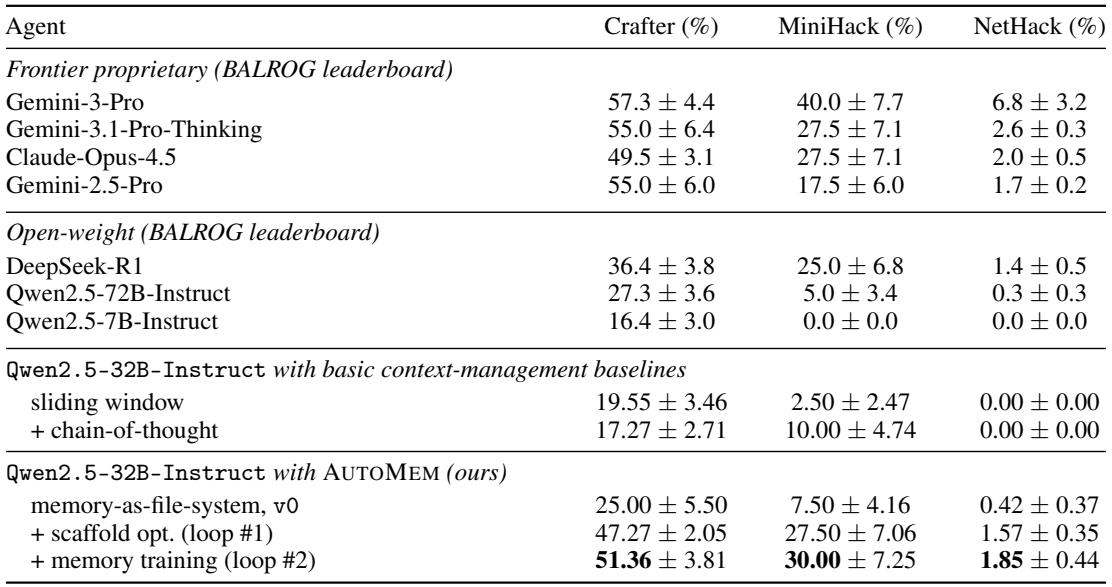
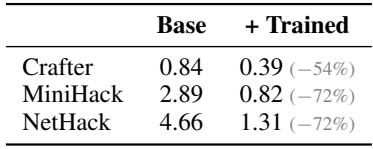
训练一个记忆专家显著减少了每次搜索对应的记忆写入,养成了“先查询后写入”的纪律。专家在追加新内容前会搜索现有文件,将写入与搜索之比在Crafter上降低了一半以上,在MiniHack和NetHack上降低了70%以上。这种内化的模式与优化后的脚手架结构记忆相补充,带来了更高效且目标导向的agent行为。训练专家后,写入与搜索之比在Crafter上从0.84降至0.39,MiniHack上从2.89降至0.82,NetHack上从4.66降至1.31。专家在写入前持续搜索记忆,避免了盲目追加,并将冗余日志减少了最多72%。
优化agent的记忆脚手架并训练记忆专家在写入前查询记忆,极大地提升了长时序任务的性能,使32B开源权重模型接近前沿专有系统。仅重构记忆就消除了每步日志膨胀的95%,并提升了进度率,而记忆训练通过养成有纪律的“先查询后写入”模式,将冗余写入减少了一半以上。