Command Palette
Search for a command to run...
ASPIRE:面向机器人的智能体技能发现
ASPIRE:面向机器人的智能体技能发现
摘要
传统机器人编程极具挑战性:需要协调多模态感知、处理复杂的物理接触动力学,并应对多样化的环境配置与执行失败。我们提出ASPIRE(通过迭代机器人探索的智能体技能编程),这是一种面向机器人的持续学习系统,在代码即策略的范式中自主编写并优化机器人控制程序,同时将经验积累为可复用的技能库。ASPIRE能够自动发现可跨多任务、仿真与真实环境以及不同机器人形态复用的技能。不同于依赖固定的人工设计流程,ASPIRE运行在一个开放式学习循环中,包含三个关键组件:(1)一个闭环机器人执行引擎,提供细粒度的多模态轨迹(如感知叠加、抓取候选、运动轨迹和碰撞反馈),使智能体能够自主诊断失败、合成修复并验证结果;(2)一个持续扩展的技能库,将经过验证的修复提炼为可复用、可迁移的机器人知识;(3)一个进化搜索过程,生成多样化的任务序列和控制程序,并系统性地调试它们,以探索超越单一轨迹优化的可能性。随着ASPIRE遇到更多任务,其不断增长的技能库使适应速度越来越快。因此,ASPIRE在扰动下的操作任务(LIBERO-Pro)上超越先前方法高达77%,在Robosuite的双臂交接任务上超越72%,在长周期家庭任务(BEHAVIOR-1K)上超越高达32%。积累的技能库进一步实现了强大的零样本泛化能力:在代表性的未见长周期任务(LIBERO-Pro Long)上,ASPIRE取得了31%的成功率,大幅优于先前方法4%的成功率,尽管后者严重依赖测试时推理和重试。最后,在仿真中发现的技能初步展示了从仿真到真实的迁移能力,尽管机器人形态和API不同,仍显著减少了真实机器人编程的工作量。
一句话总结
NVIDIA 等人提出 ASPIRE,这是一个自主式技能发现系统,通过闭环多模态轨迹、持续进化的技能库和进化搜索,自主优化机器人控制程序,在操作任务(LIBERO-Pro)上实现高达 77% 的改进,在 Robosuite 双臂交接任务上达 72%,在长时程家务任务(BEHAVIOR-1K)上达 32%,在 LIBERO-Pro Long 任务上零样本成功率达 31%(此前方法为 4%),并实现了初步的从仿真到真实迁移。
核心贡献
- ASPIRE 的闭环机器人执行引擎融合细粒度多模态轨迹(感知叠加、抓取候选、运动轨迹、碰撞反馈),以自主诊断失败并合成程序修复,将在扰动下的操作任务(LIBERO-Pro)性能提升至多 77%。
- 持续扩展的技能库将经过验证的程序修复提炼为可复用、可迁移的机器人知识,赋予其强零样本泛化能力,在未见过的长时程任务(LIBERO-Pro Long)中成功率达到 31%,而此前方法仅为 4%。
- 进化搜索过程生成多样的任务序列与控制程序,系统性地调试,其收益超越了单轨迹优化,在 Robosuite 双臂交接任务上提升至多 72%,在长时程家务任务(BEHAVIOR-1K)上提升至多 32%。
引言
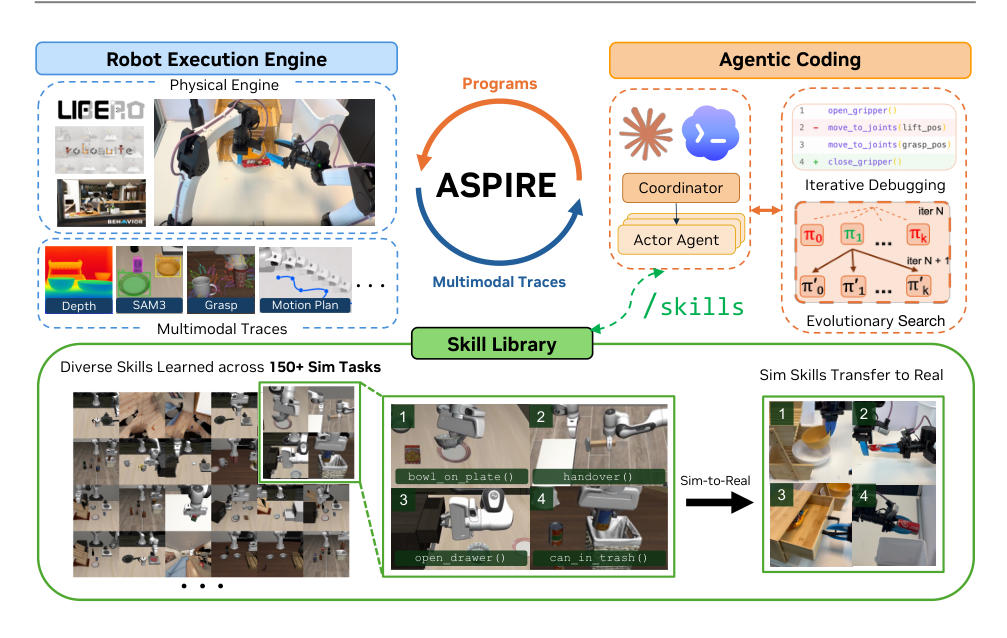
作者致力于构建能够随时间不断改进的机器人编程 agent,而不仅仅是解决单一任务。现有的“代码即策略”系统将感知、规划和控制原语组合成可执行程序,但它们依赖于粗粒度的任务级反馈,难以诊断程序在所有交互组件中失败的原因。此外,这些 agent 在每次任务后都会丢弃修复和恢复策略,无法积累经验。作者引入 Aspire,一个自我改进的机器人系统,通过提供带逐原语多模态轨迹的闭环执行引擎、一个存储已验证修复以供未来复用的持续扩充技能库,以及一个探索多样化修复的进化搜索过程,克服了这些局限。Aspire 的主要贡献在于实现自主的持续学习,其中调试知识跨任务复合,带来显著的性能提升以及长时程和真实世界操作中的零样本迁移。
方法
作者提出 Aspire,一个通过三个核心组件形成开放式学习循环的系统:一个机器人执行引擎、一个技能库和一个进化搜索过程。随着系统遇到更多任务,其技能库不断增长,使未来任务可以继承累积的修复和可复用策略。
Aspire 采用协调器-执行器架构。中央协调器管理共享技能库,并将执行器 coding agent 分派给各个任务。每个执行器在机器人执行引擎中编写、执行、诊断和修复机器人程序。执行器之间不交换完整的对话历史或原始 rollout 轨迹。相反,可迁移的经验被提炼到技能库中,使每个执行器的上下文窗口能够聚焦于任务规格、当前程序以及与当前失败相关的结构化执行轨迹。
参考框架图:
机器人执行引擎将固定的反馈通道转变为开放式调试环境。它记录感知、规划和控制调用的逐原语多模态轨迹,将轨迹暴露给 coding agent,并执行 agent 编写的修复以进行闭环验证。对于每个原语调用,轨迹存储被调用的 API、输入和输出、返回状态以及相关的多模态证据,如 RGB 关键帧、叠加层、抓取候选、物体位姿和运动规划结果。agent 不会接收完整的视频帧;引擎保存每个原语调用前后时刻的帧以及相应的叠加层和返回值,使 agent 能够聚焦于与失败相关的调用周围的证据。
如下图所示:

此调试示例说明了原语轨迹如何定位失败。自我视角的关键帧显示机器人找到了收音机,但反复无法靠近它。原语轨迹显示感知成功并返回了收音机位姿,但反复的导航调用返回规划错误。通过检查导航返回值及相关日志,agent 发现生成的导航目标离桌子边缘过近,触发了碰撞避免。然后,agent 用多角度接近例程修补程序,该例程在收音机周围采样替代导航目标,成功完成抓取。
程序失败在不同任务中反复出现,但可复用的知识很少是整个任务程序。Aspire 的技能库存储异构的修复知识,包括定位启发式、感知提示、抓取约束、导航恢复策略、运动原语、场景理解例程和调试工作流。技能从经过验证的修复中归纳得出:coding agent 从执行轨迹诊断失败,修补程序,在调试配置上验证修复,协调器仅将可复用的模式收纳入共享技能库。
每个技能以紧凑的上下文指导形式存储,包括失败特征、何时应用的条件、修复策略以及一个代表性的代码草图。
如下图所示:

技能库在异构类别间增长。对于前面提到的收音机任务,收入的技能是一个导航恢复模式,而不是一个完整的拾取收音机程序。这种表示形式使未来的执行器能够复用经过验证的修复,而不是通过测试时推理重新发现它们,支持向更难仿真任务的零样本迁移,并提供了一种机制,使选定的仿真发现技能能够跨形态泛化并迁移到真实机器人。执行器报告结构化发现,总结失败模式、已验证修复和潜在的可迁移修复模式。协调器审核这些发现,验证是否遵守允许的 API 策略,并仅将通过调试验证的可复用修复提升到共享技能库中。
仅依靠轨迹引导的调试可能陷入局部修复循环,agent 反复修补同一失败策略,而不是探索根本上不同的任务解决方法。Aspire 使用进化搜索来拓宽可执行机器人程序的探索,促进多样化的修复假设和任务策略。在每轮中,基于技能库,coding agent 提出一组 k 个候选程序,条件基于表现最好的先前程序以及先前评估的失败轨迹。每个候选程序在机器人执行引擎中执行,产生任务结果以及新的诊断轨迹。下一轮则基于表现最好的程序及其剩余的失败模式进行,使搜索能够探索不同的策略,而不是反复优化同一个解。搜索的目标是机器人程序本身。通过闭环执行选择候选,并在搜索结束后,将可泛化到环境变化和任务中的已验证修复收纳入技能库。当候选程序解决了调试配置或搜索预算耗尽时,搜索终止。
实验
在仿真操作基准测试中,Aspire 显著优于代码即策略基线和端到端 VLA 策略,尤其在物体、目标和空间扰动下以及在长时程任务中。零样本迁移实验表明,在短时程任务上积累的技能库持续有益于未见过的长时程组合。跨形态的真实机器人技能迁移降低了调试成本并提高了成功率,证实了源于失败的修复可以泛化到仿真特有代码之外。消融研究确定机器人执行引擎是性能的主要贡献者,进化搜索在困难案例中提供了额外收益。
在所有任务中,检索仿真发现的技能始终减少了真实机器人程序合成的调试 token 成本。对成功率的影响因任务而异:碗的放置两种设置都成功,苏打罐举起显著改善,而抽屉操作仅在提供技能指导时才达成成功。这些发现表明,源于失败的技能提供了可复用的上下文指导,可跨形态和 API 变更迁移。技能检索降低了每个任务的总 token 使用量,其中苏打罐举起的相对降幅最大(接近一个数量级)。没有技能时,抽屉操作消耗大量 token 预算,且从未生成成功程序;有了技能,成功率达到 11/20,同时 token 用量大大减少。碗的放置两种条件下均实现完美成功,但技能指导仍减少了调试 token 数量。使用技能时,苏打罐举起成功率从 13/20 提升到 19/20,同时 token 成本大幅下降。

检索仿真发现的技能始终减少了真实机器人程序合成的调试 token 成本,其中苏打罐举起的相对降幅最大。成功率有不同程度提升:碗的放置两种设置均成功,苏打罐举起显著改善,抽屉操作仅在技能指导下才成功。这些源于失败的技能提供了可复用的上下文指导,可跨形态和 API 变更迁移,使得原本无法解决的任务能够经济高效地完成。