Command Palette
Search for a command to run...
MatAnyone 2:通过学习的质量评估器扩展视频抠图
MatAnyone 2:通过学习的质量评估器扩展视频抠图
Peiqing Yang Shangchen Zhou Kai Hao Qingyi Tao
摘要
视频抠图仍受限于现有数据集的规模与真实性。尽管利用分割数据可以增强语义稳定性,但缺乏有效的边界监督往往导致类似分割的抠图结果,缺少精细细节。为此,我们引入了一种学习的抠图质量评估器(MQE),它无需真值即可评估Alpha遮罩的语义和边界质量。该评估器生成像素级评价图,以识别可靠区域和错误区域,从而实现细粒度质量评估。MQE从两个方面扩展了视频抠图:(1)作为训练期间的在线抠图质量反馈,抑制错误区域,提供全面的监督;(2)作为离线数据筛选模块,通过结合领先视频与图像抠图模型的优势来提升标注质量,用于数据整理。这一过程使我们构建了一个大规模真实世界视频抠图数据集VMReal,包含2.8万个片段和240万帧。为应对长视频中的大幅外观变化,我们引入了一种参考帧训练策略,将超出局部窗口的长距离帧纳入有效训练。我们的MatAnyone 2在合成和真实世界基准上均达到了最先进性能,在所有指标上超越了此前的方法。
一句话总结
MatAnyone 2,由南洋理工大学和商汤科技团队提出的一种视频抠图框架,利用一个可学习的抠图质量评估器(MQE)在训练时提供像素级质量反馈,并构建了大规模真实场景数据集 VMReal,同时引入参考帧训练策略,在合成和真实场景基准上实现了最先进的性能。
核心贡献
- 一个可学习的抠图质量评估器(MQE),在无需真实值的情况下生成 alpha 抠图的逐像素质量图,联合评估语义准确性和边界细节。
- 利用 MQE 作为离线筛选工具,构建了 VMReal,这是第一个大规模真实场景视频抠图数据集,包含 28K 个片段和 2.4M 帧,具有多样且高质量的标注。
- 引入参考帧训练策略,将局部窗口之外的远距离帧纳入考虑,以应对大幅外观变化,最终得到的 MatAnyone 2 模型在合成和真实基准上均达到了最先进性能,在所有指标上超越之前的方法。
引言
视频抠图对于视觉特效和视频编辑至关重要,但由于模糊的边界、缺失区域和跟踪不稳定性,仍然具有挑战性。一个核心瓶颈是现有抠图数据集规模有限且真实性不足:目前最大的数据集仅包含约 800 个合成序列,远小于分割数据集,而基于合成的数据增强会引入光照不一致和不自然边缘,造成与真实素材之间的域差异。以往尝试通过预训练或联合训练引入分割先验的方法难以迁移精细边界细节;预训练特征在稀缺的抠图数据上微调时会退化,而使用掩码监督的联合训练往往产生边界质量较差的类分割输出。作者们通过引入一个可学习的抠图质量评估器(MQE)来解决这些问题,该评估器无需真实 alpha 抠图即可评估语义准确性和边界保真度。利用该评估器作为在线指导信号和离线筛选模块,他们构建了 VMReal,一个包含约 28,000 个片段的大规模真实场景视频抠图数据集,并提出了一种参考帧训练策略以处理长时间外观变化。这些贡献构成了 MatAnyone 2,显著提升了语义稳定性、边缘锐度和真实场景泛化能力。

数据集
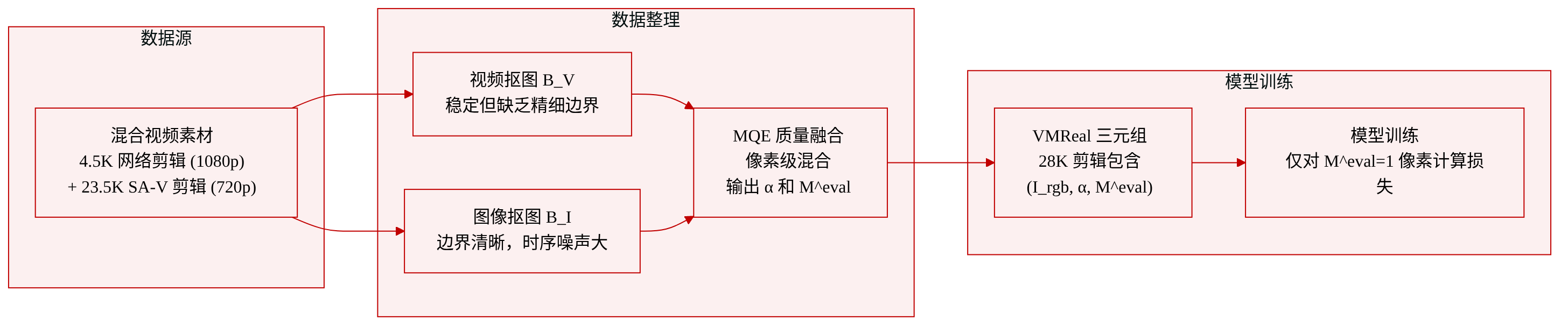
作者们构建了 VMReal,一个大规模真实场景视频抠图数据集,通过由学习的 MQE(抠图质量评估器)引导的双分支流水线自动标注。该数据集包含约 28,000 个片段(240 万帧),比之前的视频抠图数据集大约 35 倍。
- 组成和来源 VMReal 由两个子集构成:
- 一个包含 4,500 个片段的高质量子集,来源于视频素材网站和 YouTube,以 1080p 分辨率录制,具有丰富的细粒度头发细节(以人为主的场景)。
- 其余片段来自 SA‑V 数据集,滤除了以人为主的子集后,通常为 720p 分辨率;这些片段提供了多样化的场景、运动和光照条件,以补充以肖像为主的子集。
- 自动标注流水线 对于每个视频,两个分支生成互补的 alpha 预测:
- 分支 B_V(视频抠图模型,例如 MatAnyone)提供时间上稳定的抠图结果,但有时会丢失精细边界细节。
- 分支 B_I(图像抠图模型,例如 MattePro,由 SAM2 逐帧掩码引导)生成锐利的边界,但缺乏时间一致性。
- 预训练的 MQE 充当质量仲裁者,生成逐像素评估图 M_V^eval 和 M_I^eval,指示可靠区域。融合掩码 M^fuse = M_I^eval ⊙ (1 − M_V^eval) 识别出 B_V 不可靠而 B_I 置信的像素。经过高斯平滑后,最终 alpha 混合为:α = α_V ⊙ (1 − M^fuse) + α_I ⊙ M^fuse。融合后的评估图 M^eval = M_V^eval ∪ M_I^eval 标记所有值得信赖的像素。
- 每帧存储为三元组 (I_rgb, α, M^eval)。
-
数据使用方式 作者们仅在 VMReal 上训练,避免与分割数据联合训练。损失仅在 M^eval = 1 的像素上计算,因此监督集中在高置信区域,忽略不确定或低质量区域。该策略保留了精细边界细节,并防止产生类分割的伪影。
-
其他处理细节 除原生源格式外,不进行裁剪或分辨率更改。逐帧评估图作为内置元数据用于像素级损失掩码,无需手动清洗。
方法
作者们提出 MatAnyone 2 以解决先前视频抠图方法的局限性,特别是语义准确性和边界保真度之间的权衡。之前的工作 MatAnyone 通过与分割数据联合训练改进了抠图。然而,分割数据仅能为非边界区域提供可靠监督,导致边界约束薄弱和类分割的抠图结果。为解决此问题,作者们引入了一个新颖的抠图质量评估器(MQE),可在无需抠图真值的情况下为两个区域提供有效监督。
参考下方框架图对比训练流程:
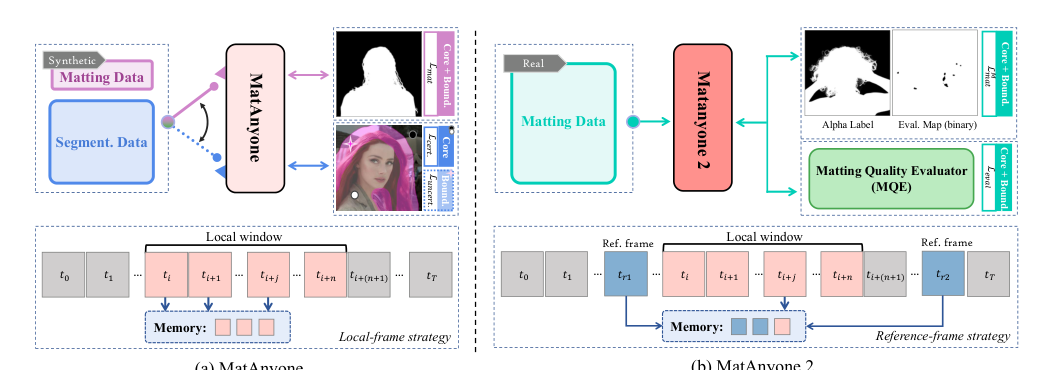
所提出的架构从合成抠图和分割数据转向由 MQE 引导的真实抠图数据。这种方法使模型能够实现更高的语义准确性,同时保留精细边界细节。如下方的视觉对比所示,MatAnyone 2 在保留发丝等精细细节和避免类分割边界方面显著优于先前方法,同时在具有挑战性的光照条件下表现出更强的鲁棒性。
在线抠图质量指导 作者们利用学习的 MQE 模型作为训练期间的动态反馈信号。对于每个输入帧,MQE 生成概率图 Peval(0),指示 alpha 预测中像素级错误的似然。该图作为惩罚掩码,引导网络抑制错误区域。在线指导损失定义为:
Leval=∥Peval(0)∥1
该损失鼓励更低的错误概率,与先前方法中使用的弱无监督损失相比,为边界区域提供了更有效且稳定的学习信号。
离线逐像素选择与数据筛选 除了在线指导,作者们还利用 MQE 通过自动双分支标注流水线构建大规模真实场景视频抠图数据集 VMReal。手动标注成本过高,因此该流水线组合了两个互补分支。第一分支(BV)使用视频抠图模型以确保稳定的时间一致性和鲁棒的结构。第二分支(BI)使用由分割掩码引导的图像抠图模型,以产生更锐利的边界细节。
如下图所示,MQE 作为质量仲裁者融合这些预测:
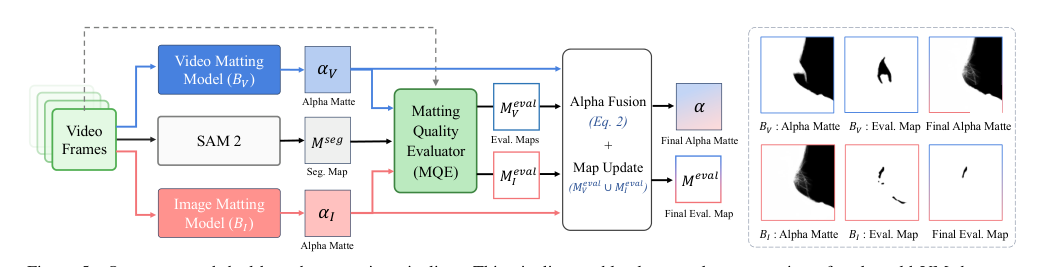
系统为两个分支生成评估图 MVeval 和 MIeval。它以来自 BV 的稳定预测为基础,并在 BV 不可靠(MVeval=0)而 BI 可靠(MIeval=1)的区域选择性地集成 BI 的边界细节。计算融合掩码 Mfuse=MIeval⊙(1−MVeval),并用高斯模糊平滑以避免伪影。最终融合 alpha 抠图通过下式获得:
α=αV⊙(1−Mfuse)+αI⊙Mfuse
这种统一训练方案使用三元组 ⟨Irgb,α,Meval⟩,其中抠图损失仅在可靠区域(Meval=1)上计算。
长视频的参考帧策略 在长视频中,目标外观可能显著变化。先前依赖记忆传播的方法往往无法抠出新增部分,因为训练被限制在短序列(局部窗口)内。简单扩展窗口会增加内存消耗。为解决此问题,作者们提出一种参考帧策略,将远距离参考帧引入到超出局部训练窗口的记忆中。这扩展了时间上下文,且不增加额外内存开销。为了进一步增强,使用了随机丢弃增强来遮蔽 RGB 和 alpha 图中的块,减轻对历史记忆的过度依赖。该策略有效应对大幅外观变化,使模型能够稳健地识别新增目标区域,如下图所示。

实验
为改进视频抠图,本文引入了一个逐像素抠图质量评估器(MQE),它利用分割指导和 DINOv3 特征可靠地识别预测 alpha 抠图中的错误区域。该 MQE 实现了在线训练监督和大规模真实场景视频抠图数据集(VMReal)的构建,从而产生了 MatAnyone 2 模型。MatAnyone 2 在合成和真实基准上均实现了最先进的性能,提供了卓越的语义鲁棒性、精细边界细节和时间一致性。消融研究证实,在线 MQE 指导和 VMReal 上的训练显著提高了抠图质量,特别是在诸如复杂光照和风中飘动的头发等挑战性条件下。
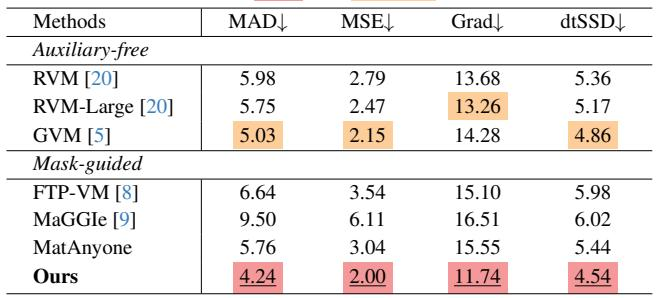
在 VideoMatte 基准上,所提出的纯 CNN 方法在所有指标上均优于所有先前方法,尽管仅使用第一帧掩码且无扩散先验。相对于先前最佳的掩码引导模型,它将梯度和连通性错误降低了超过 20%,并且比依赖于逐帧实例掩码或基于扩散先验的方法具有更好的时间连贯性和语义准确性。在 VideoMatte 上取得了最低的 MAD、MSE、Grad、dtSSD 和 Conn,标志着在所有比较方法中整体性能最佳。与领先的掩码引导 MatAnyone 模型相比,Grad 和 Conn 错误分别降低了 27.1% 和 22.4%。在使用标准 CNN 和第一帧实例掩码的情况下,优于基于扩散的 GVM 和逐帧掩码引导的 MaGGIe。
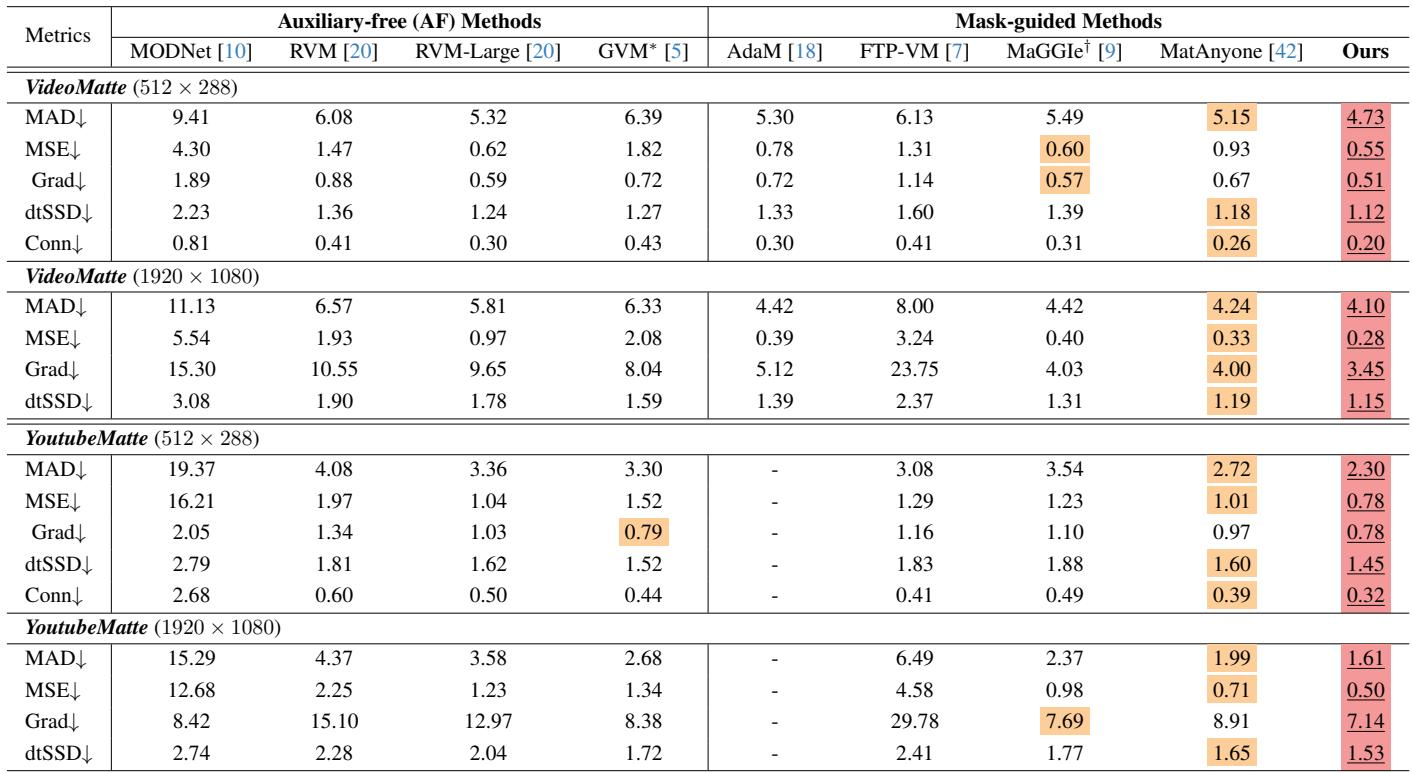
在真实场景 CRGNN 数据集上,所提出的 MatAnyone 2 在所有四个指标上均达到了最佳性能,较之前的 MatAnyone 大幅提升了语义准确性、精细细节和时间一致性。GVM 的扩散先验产生了有竞争力的结果,但 MatAnyone 2 在每项指标上仍优于它。无辅助的方法落后于掩码引导方法。MatAnyone 2 在 MAD、MSE、Grad 和 dtSSD 上得分最高,在该真实基准上超越了所有比较方法。GVM 由于其扩散先验表现出强性能,但 MatAnyone 2 在所有指标上均超过它,包括细节保真度(Grad)和时间连贯性(dtSSD)。相对于 MatAnyone,新模型显示出显著改进,证实了在风中头发和复杂光照等挑战性真实条件下增强的语义准确性和更精细的抠图细节。
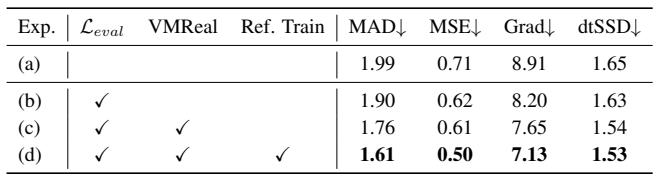
添加在线抠图质量指导比基线减少了语义和边界错误。引入 VMReal 数据集进一步提升了时间一致性和细节保真度,而参考帧训练策略在不增加内存代价的情况下带来了额外的语义鲁棒性。仅在线指导降低了 MAD、MSE 和梯度误差,显示出改进的语义准确性和边缘细节保真度。使用 VMReal 和参考帧策略的组合训练带来了最低的 MAD 和 MSE,表明对外观变化具有强鲁棒性,并且时间质量稳定。
MatAnyone 2 是一个纯 CNN 模型,仅使用第一帧实例掩码,在合成 VideoMatte 和真实 CRGNN 基准上进行了评估。它超越了所有先前方法,包括基于扩散和逐帧掩码引导的方法,提供了更好的语义准确性、精细细节保真度和时间一致性。消融研究表明,在线抠图质量指导、VMReal 数据集和参考帧训练策略各自都能减少语义和边界错误,同时提高鲁棒性,组合使用则带来最强的时间质量和外观稳定性。