Command Palette
Search for a command to run...
EdgeBench:揭示从真实世界环境中学习的标度律
EdgeBench:揭示从真实世界环境中学习的标度律
摘要
预训练标度律表明,模型能力随数据和计算量的增加而可预测地提升。但部署后从真实世界环境中学习的过程仍远未被充分理解。通过分析智能体在134个真实世界任务中与环境交互的约38,000小时数据,我们首次发现,据我们所知,环境学习过程中的整体性能遵循对数S型标度律,且精度极高,达到R2=0.998。跨模型代际分析还显示,智能体的学习速度大约每三个月翻一番。这一发现源于EdgeBench,一个包含134个超长周期真实世界任务的套件,涵盖科学发现、软件工程、组合优化、专业知识工作、形式化数学和互动游戏等领域。每个任务在丰富的多层次反馈下,支持至少12小时的连续智能体操作,并经过大量专家努力构建。我们公开发布了51个任务及完整的评估框架,以加速对智能体如何从真实世界经验中学习的研究。
一句话总结
ByteDance Seed 的 EdgeBench 是一个包含 134 个真实世界任务的基准,覆盖科学发现、软件工程和交互游戏等领域,揭示了 agent 在环境学习中的性能遵循对数-sigmoid 缩放定律(R2=0.998),并且跨模型代际的学习速度每三个月翻一番,为部署后 agent 学习提供了首个实证缩放定律。
核心贡献
- 该论文提出了 EdgeBench,一个包含 134 个真实世界任务的基准,涵盖科学发现、软件工程、组合优化、专业知识工作、形式数学和交互游戏等领域,旨在衡量 agent 在长达一天的时间跨度内利用丰富的多层次反馈所实现的性能提升。
- 在这些多样化的长周期任务中,总体的 agent 性能随交互时间遵循对数-sigmoid 缩放定律,R² 达到 0.998,从而能够从早期轨迹预测后期性能。
- 跨近几代模型,前沿 agent 的学习速度大约每三个月翻一番,这表明环境学习是一个可测量且系统化的缩放对象。
引言
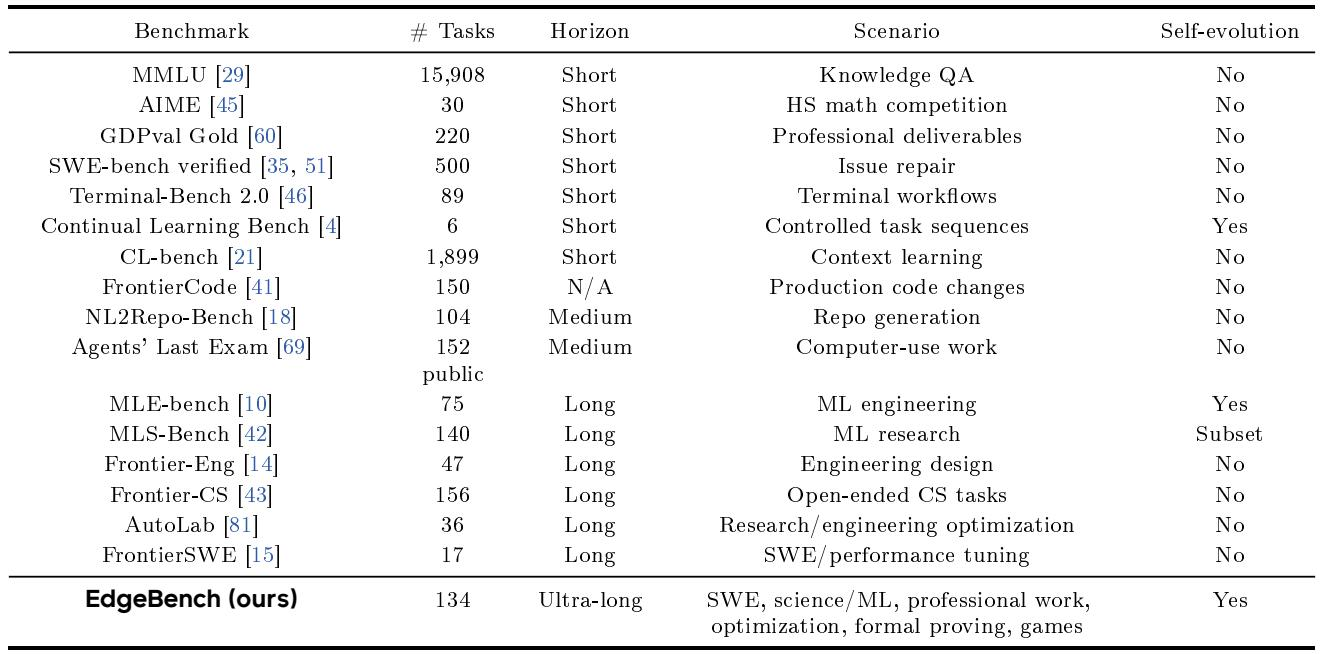
大型语言模型越来越多地作为 agent 部署,必须通过交互适应真实世界任务,但先前的基准缺乏研究 agent 如何从环境中实际学习所需的长周期和丰富的多层次反馈。现有评估要么衡量短任务的静态终点,要么只提供狭窄的反馈,因而无法捕捉经验驱动改进的轨迹。作者提出了 EdgeBench,一个包含 134 个日尺度任务的基准,覆盖六个不同领域(从科学研究到软件工程),agent 在至少 12 小时内既接收本地测试结果,也接收提交触发的评判反馈。通过该基准和大约 38,000 小时的 agent 交互,他们首次发现环境学习随着交互时间遵循精确的对数-sigmoid 缩放定律,并且前沿 agent 的学习速度大约每三个月翻一番。
数据集
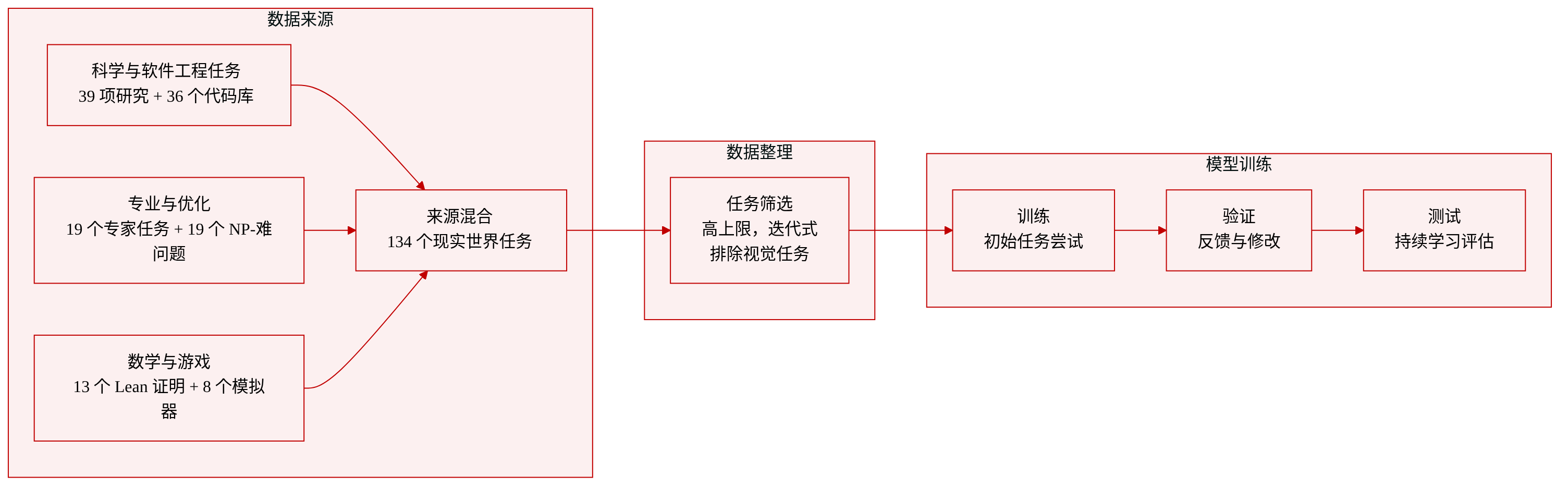
作者整理了 134 个真实世界任务,覆盖六个能力族,每个任务都具备两个特性:当前 agent 无法饱和的高性能上限,以及奖励持续学习而非单次完成的工作流。领域专家协作寻找并筛选了这些任务,有意排除了主要依赖视觉理解的任务(例如 GUI 操作),以便隔离迭代推理和学习能力。
数据集构成和来源
- 共计:134 个任务,横跨六个族。
- 来源真实:来自科研人员的研究数据、生产级代码库、专业白领交付成果、Lean 中的形式数学以及可玩的人类游戏。
- 筛选规则:任务必须具备尚未解决的高上限且支持迭代改进;视觉密集型任务被排除。
每个族的详细情况
- 科学问题和机器学习(39 个任务)。真实的研究数据和实验设置;agent 提出假设、选择模型、针对噪声观测进行验证并迭代优化。许多任务是开放式的,尚无已知最优解。
- 系统与软件工程(36 个任务)。生产级代码库;变更可能超过 10 万行代码。agent 必须在相互依赖的模块中推理,同时满足正确性和性能目标。
- 组合优化(19 个任务)。开放式、多数为 NP-难问题;精确方法难以求解,因此 agent 需要设计、调优和迭代启发式搜索策略。
- 专业知识工作(19 个任务)。来自金融、教育、医疗和法律领域的交付成果,相当于具备 3 年以上经验的专业人士工作约三天的工作量。许多任务包括结构化量规和模拟客户评审周期的多轮反馈,支持迭代修订。
- 形式数学与定理证明(13 个任务)。前沿难度的证明,需要大规模的 Lean 证明;多数为该基准全新创建。agent 会收到结构化的中间指导,并能逐步扩展部分证明。
- 交互游戏与模拟器(8 个任务)。真实人类游戏,具有巨大的状态空间和程序生成的变化。熟练的人类需要数十小时才能掌握;agent 必须通过高频交互在多个 episodes 中制定策略。
数据的使用方式
- 任务旨在进行持续学习评估:期望 agent 通过重复尝试、反馈和迭代优化实现改进,而不是单次推理。
- 在专业知识工作等族的任务中,多轮结构化反馈模拟真实的评审循环,使 agent 能够从批评中学习。
- 在形式数学中,增量证明构建让 agent 能接受中间指导并扩展部分结果。
- 这些任务构成一个多样化的评估套件,其主要挑战是推理、规划以及从经验中学习,而非感知。
处理与整理选择
- 裁剪策略 / 元数据:未详细说明,但任务的构建方式旨在暴露原始的、真实世界的输入(研究数据、完整代码库、Lean 环境、游戏状态),并尽量减少简化。
- 过滤:搜索过程明确排除了视觉为瓶颈的任务,因此数据集最大限度地减少感知能力对推理评估的污染。
- 专家协作:每个任务都与领域专家一起寻找并审查,确保真实性和存在高性能上限。
方法
作者设计了 EdgeBench 作为专门衡量自主 agent 是否能在陌生的真实环境中从经验中学习的基准套件。其核心设计建立在两个方法学承诺上:超长周期的多样化任务和真实的多层次反馈。第一个原则通过一个包含 134 个任务、横跨六个能力族的任务分类来实施,每个任务都是一个日尺度的挑战,允许前沿模型至少交互 12 小时。这些延长的交互窗口是必要的,因为探索、策略修订和经验积累等学习行为需要相当长的时间范围才能显现;短周期任务往往依赖记忆的先验知识解决,而不是真正适应新异事物。
第二个原则通过一种结构化评估协议来实现,该协议为每个任务模拟一个隔离的现实世界片段。每个任务环境被分为一个私有工作环境和一个独立的评判环境。agent 与工作环境交互,接收本地、由 agent 驱动的反馈,这些反馈对应现实世界中的测试失败、实验结果和意外现象信号。为了获得评判者更丰富、权威的反馈,agent 必须提交解决方案,通过主动决策来获取质量更高的信号。同时,主端基础设施捕获完整的轨迹测量,从而精确研究 agent 性能如何在交互周期内演变。这一架构确保了反馈接近现实世界学习的复杂性,同时保持了实验控制。
在五个前沿 agent 和大约 38,000 小时的环境交互中收集的轨迹数据表明,从环境中学习遵循一种极其简单的缩放形式。当任务得分在基准上聚合并相对于对数交互时间绘制时,性能增长紧密地遵循一条对数-sigmoid 曲线。为解释这种经验规律,作者提出了一个理论模型,将环境学习视为在潜在任务图上的前沿扩展过程。
在此模型中,每个任务由一个图表示,其节点为带有权重 wi 和归一化权重 μi=wi/∑iwi 的得分单元。二元变量 ni(u)∈{0,1} 指示单元 i 在有效时间坐标 u 时是否被解锁,因此此时获得的归一化得分为
x(u)=∑iμini(u).
边带有非负权重 Kij,量化一个已解锁的源单元 j 对目标单元 i 解锁的促进程度。因此,一个锁定的单元 i 会体验到一个影响场
hi(u)=∑jKijnj(u).
假设锁定单元按照与该场成正比的速率随机解锁,则在当前状态下预期的得分增长速率为
dudE[x(u)∣n(u)]=η∑i∈L(u)∑j∈U(u)μiKij,(2)
这正是从已解锁单元集合 U(u) 到锁定单元集合 L(u) 的加权前沿切割。因此,进展由未解锁知识可以传播的边界大小驱动。
然后运用平均场近似,假设在宏观层面上每一个解锁-锁定切割的行为都近似为乘积测度:
∑i∈L∑j∈UμiKij≈κμ(L)μ(U).
令 μ(A)=∑i∈Aμi,可得预期得分的简单微分方程:
dudx=βx(1−x),β=ηκ.(3)
因子 x 代表已解锁的得分质量,它提供了可复用的能力,而 1−x 代表锁定的质量,衡量剩余的提升机会。
为将图坐标 u 与真实时间关联,作者论证在自相似图结构下 u 按 logt 增长:如果任务难度的每次附加增长都会暴露图中成倍增加的部分,那么遍历图所需的搜索量随难度呈指数扩张,因此在时间 t 达到的难度尺度与对数成正比。将 u∼logt 代入式(3),得到可观测时间上的动力学
dlogtdx=βx(1−x).(4)
分离变量并积分,得到 logt 的逻辑函数:
x(t)=1+(tmid/t)β1,⟹S(t)=1+(tmid/t)βSmax.
拟合速率 β 刻画了对数时间下的有效前沿传播速度:较大的 β 使得从低到高表现的过渡更陡峭,而较小的 β 则将进展分散到更多倍的时间上。上限 Smax 表示可观测范围内可达到的得分支撑,而非绝对的性能上界。
个别任务可能因有限的得分单元而出现平台期和突然的跳跃,但基准级的聚合曲线平滑了这些波动。在分块切割混合、平均跳跃噪声消失、中点对齐和速度集中的温和假设下,任务平均得分 xM(u) 依概率收敛到单一的对数-sigmoid。这一框架为缩放定律提供了一个机制性解释,将其视为结构化任务图上前沿扩展的宏观标志,并将环境学习与预训练性能扩展所观察到的相同数学形式联系起来。
实验
EdgeBench 在 134 个多样化的真实世界任务上评估了五个前沿模型,采用双循环协议:agent 在本地迭代并向隐藏的评判者提交,从而能够在 12 小时的时间跨度内衡量学习情况。关键发现是,agent 通过环境交互实现的性能提升遵循精确的对数-sigmoid 缩放定律,该定律在众多任务中涌现,并与预训练趋势相呼应。学习速度大约每三个月翻一番,累积的经验比单纯重复采样更有价值,更长的上下文窗口能带来持续增益。案例分析揭示,agent 通过稀疏但结构化的“诊断-编辑-评估”循环实现改进:首先使问题可衡量,然后分解失败并针对瓶颈进行攻关。
对数-sigmoid 形式在三参数 S 形曲线族和对数线性基线中实现了最低的 RMSE(0.390),尽管其他 sigmoid 曲线(对数-probit、对数-Gompertz、Weibull CDF)几乎一样好(0.398–0.404)。所有 S 形曲线都显著优于对数线性基线(0.717),表明学习轨迹具有稳健的 sigmoid 性质。对数-sigmoid 拟合最佳,RMSE 为 0.390,略微领先于其他 sigmoid 族。对数-probit、对数-Gompertz 和 Weibull CDF 的 RMSE 值几乎无法区分(0.398–0.404)。与对数线性基线相比,所有 S 形曲线的误差均减少约 45%。

总体结果显示清晰的层级:一个模型在每个时间预算下和所有 12 小时类别的平均值中都处于领先,紧随其后的是一个接近的对手,并与其他参赛者之间存在巨大差距。提交效率分析表明,更高的性能与更有效的提交相关联,但领先模型的优势并非来自更高的提交频率——它的提交次数比第二名少,这凸显了有意识的、反馈引导的改进比单纯追求提交数量更重要。领先模型在 2 到 12 小时的整个窗口内始终保持优势,并且在最终检查点优势略微扩大。在 12 小时时,第二名仅在游戏类别中具有竞争力,差距可忽略不计;在其他类别中,领先模型保持舒适的领先。具有更高有效提交率的模型通常表现更好,但最高的有效提交率并不转化为最佳最终得分,揭示提交质量和改进幅度比提交频率更重要。较弱的模型往往过度信任本地代理信号,或在反馈已排除某一方向后仍进行广泛探索,降低了采样效率;而较强的模型则保留可行的基线、进行聚焦的修改,并利用反馈保留成果或回滚失败。
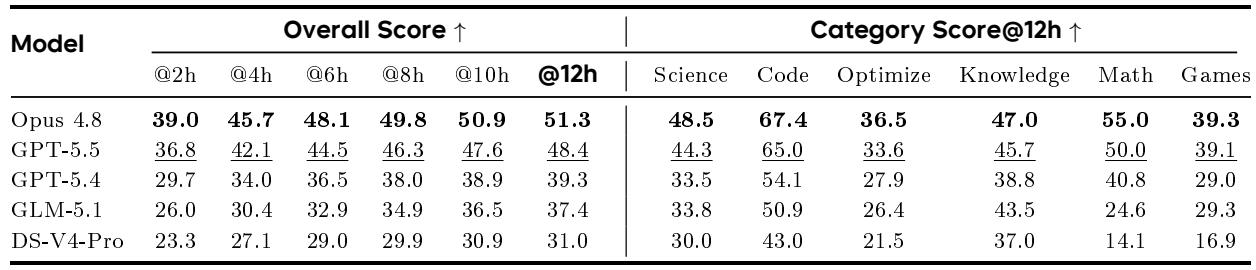
随着时间推移,能够跨运行积累经验的 agent 相比同样预算的基线逐渐获得越来越大优势。早期优势很小,但到 12 小时时变得显著,反映出结构化的失败驱动搜索过程将大量探索性尝试转化为少数高影响力的改进。有经验 agent 与基线之间的性能差距从 2 小时的微小差距扩大到 12 小时时超过 6 个点的明显优势。224 次提交中只有 27 次提升了最好成绩,然而这种稀疏的诊断-编辑-评估循环在 agent 识别并攻击主要瓶颈时产生了累积增益。

大多数代表性基准评估的是静态任务完成情况,并不衡量随时间或样本数的自我进化,仅有一个例外明确地对照资源轴跟踪性能。相比之下,在持续任务上赋予 agent 迭代的诊断-编辑-评估循环,会展现出结构化、不均衡的改进,显示出独特的问题解决阶段,将许多失败的尝试转化为少量的累积增益。在调查的七个基准中,只有一个通过对照资源轴绘制性能来跟踪自我进化,其他则评估单次任务求解,缺乏这种持续度量。在一次 12 小时运行中,agent 通过稀疏、结构化的提交从 42.8 提高到 67.0:224 次提交中只有 27 次提高了最好成绩,进展呈现出不同的阶段,如使任务可衡量、分解错误、聚焦主要瓶颈以及修复残存问题。
跨实验的评估表明,学习轨迹具有稳健的 sigmoid 性质,对数-sigmoid 拟合优于线性基线,突显了改进的非线性特征。模型竞赛进一步显示,持久的领先地位来自深思熟虑、反馈引导的改进,而非提交频率,最佳 agent 将稀疏、高影响力的编辑转化为累积增益。对迭代 agent 行为和基准设计的分析表明,大多数静态基准未能捕捉自我进化,而结构化的诊断-编辑-评估循环驱动了阶段性、聚焦瓶颈的进展,这种进展随时间积累优势。