Command Palette
Search for a command to run...
PixelRefer:面向任意粒度的时空目标指称统一框架
PixelRefer:面向任意粒度的时空目标指称统一框架
Yuqian Yuan Wenqiao Zhang Xin Li Shihao Wang Kehan Li Wentong Li Jun Xiao Lei Zhang Beng Chin Ooi
摘要
多模态大语言模型在开放世界视觉理解中展现出强大的通用能力。然而,现有模型大多侧重于整体场景级理解,往往忽视了对细粒度、以目标为中心的推理需求。本文提出PixelRefer,一个统一的区域级多模态大语言模型框架,能够在图像和视频中,针对用户指定的区域实现高级细粒度理解。受大语言模型注意力主要集中在目标级标记这一观察的启发,我们设计了一种尺度自适应目标标记器,从自由形式的区域中生成紧凑且语义丰富的目标表示。分析表明,全局视觉标记主要在大语言模型的早期层中发挥作用,这促使我们设计了PixelRefer-Lite这一高效变体,其采用以目标为中心的注入模块,将全局上下文预先融合到目标标记中。由此得到的轻量级纯目标框架大幅降低了计算成本,同时保持了高语义保真度。为促进细粒度指令微调,我们构建了PixelRefer-2.2M,一个高质量的以目标为中心的指令数据集。在多项基准上的广泛实验验证了PixelRefer以更少的训练样本实现了领先性能,而PixelRefer-Lite则在效率显著提升的同时提供了有竞争力的精度。
一句话总结
浙江大学、达摩院、阿里巴巴集团等提出 PixelRefer,一个统一的多模态框架,通过使用尺度自适应对象分词器(Scale-Adaptive Object Tokenizer, SAOT)生成紧凑且语义丰富的对象表示,并在 PixelRefer-Lite 中采用以对象为中心的注入模块进行高效的全局上下文预融合,从而在图像和视频中实现细粒度的时空对象指代,在所整理的 PixelRefer-2.2M 数据集上以更少的训练样本超越了先前方法。
核心贡献
- PixelRefer 是一个统一的区域级多模态大语言模型,使用尺度自适应对象分词器(SAOT)从自由形式的区域中生成紧凑且语义丰富的对象表示,实现了跨图像和视频的细粒度时空以对象为中心的理解。
- 一种高效变体 PixelRefer-Lite 包含一个以对象为中心的注入模块,该模块将全局视觉上下文预融合至 object tokens 中,形成了一个仅对象框架,在保持高语义保真度的同时大幅降低了计算成本。
- 所整理的一个以对象为中心的指令数据集 PixelRefer-2.2M 用于支持训练。实验表明,PixelRefer 在从图像描述到复杂推理的任务上以更少的训练样本取得了领先性能,而 PixelRefer-Lite 则在提供有竞争力的准确率的同时带来了显著的效率提升。
引言
多模态大语言模型 (MLLMs) 实现了强大的整体视觉理解能力,但往往忽略了细粒度的、以对象为中心的理解,而这对于具身智能和医学诊断等应用至关重要。先前的区域级推理方法受到模糊的视觉标记、重复编码导致的计算低效或仅专注于图像描述而牺牲了 MLLMs 通用性的限制。作者提出 PixelRefer,一个统一的框架,将紧凑、语义丰富的区域表示注入通用的 MLLM 主干,以支持跨图像和视频的广泛的以对象为中心的指代任务。其方法的核心是一个尺度自适应对象分词器,能够从自由形式的区域中产生精确的 object tokens。对注意力模式的实证分析促成了 PixelRefer-Lite,一个高效的仅对象变体,它将全局视觉上下文预融合到 object tokens 中,显著降低了计算成本。作者进一步引入了一个所整理的指令数据集 PixelRefer-2.2M,并展示了其在更高数据效率下的最优性能。
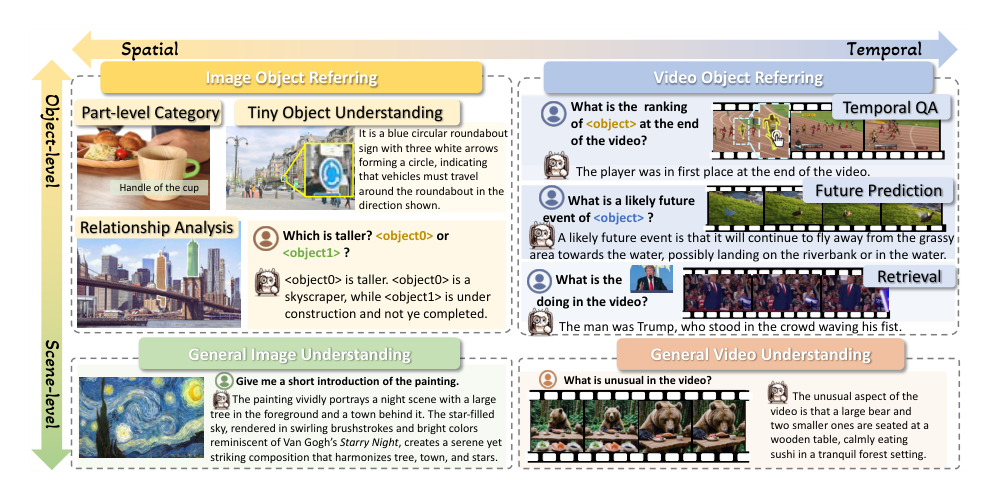
数据集
作者整理了一个多样化的开源数据集集合,并将其组织为两个互补的阶段用于模型训练:
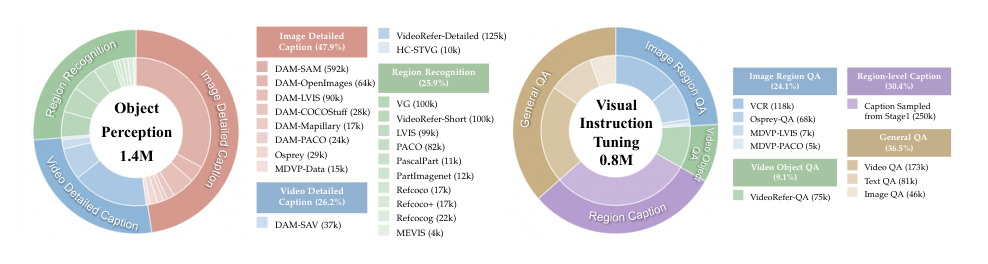
基础对象感知(140 万个样本) 用于在指令微调之前加强细粒度的区域对齐。它包含三个子集:
- 区域识别 – 将来自 LVIS、Visual Genome、RefCOCO/RefCOCO+ 的对象级标注与部件级数据集(PACO、Pascal-Part、PartImageNet)相结合,以实现从整体对象到部件的层次化学习,加上来自 VideoRefer-Short 描述和 MEVIS 的时间线索用于动态场景。
- 区域图像详细描述 – 汇总了基于 SAM、OpenImages、LVIS、COCO-Stuff、Mapillary、PACO 构建的密集描述样本,以及来自 Osprey-caption 和 MDVP-Data 的更丰富的叙述。
- 区域视频详细描述 – 利用自行构建的 VideoRefer-Detailed 描述、DAM-SAV 和 HC-STVG,为视频提供时间和上下文监督。
视觉指令微调(80 万个样本) 旨在教会模型基于视觉输入的指令遵循和推理能力。子集如下:
- 图像区域问答 – 包含 Osprey-QA、MDVP-LVIS、MDVP-PACO(均使用 GPT-4/GPT-4o 标注),加上用于在视觉上下文中进行常识和因果推理的 VCR。
- 视频对象问答 – 通过 multi-agent pipeline 构建的 75K 个 VideoRefer-QA 样本,提供以对象为中心的问答对,需要跨时间推理对象的身份、属性和交互。
- 区域描述 – 从基础对象感知数据中采样的 25 万个区域描述,衔接感知预训练和指令微调。
- 通用问答 – 从 LLaVA-Video 和 LLaVA-OV 中采样的开放式查询,以将指令遵循能力拓展到非区域任务。
该数据用于模型训练的视觉指令微调阶段(第二阶段),首先应用基础感知数据以灌输鲁棒的区域理解,随后应用指令微调数据以使模型具备多样化的推理和描述能力。
方法
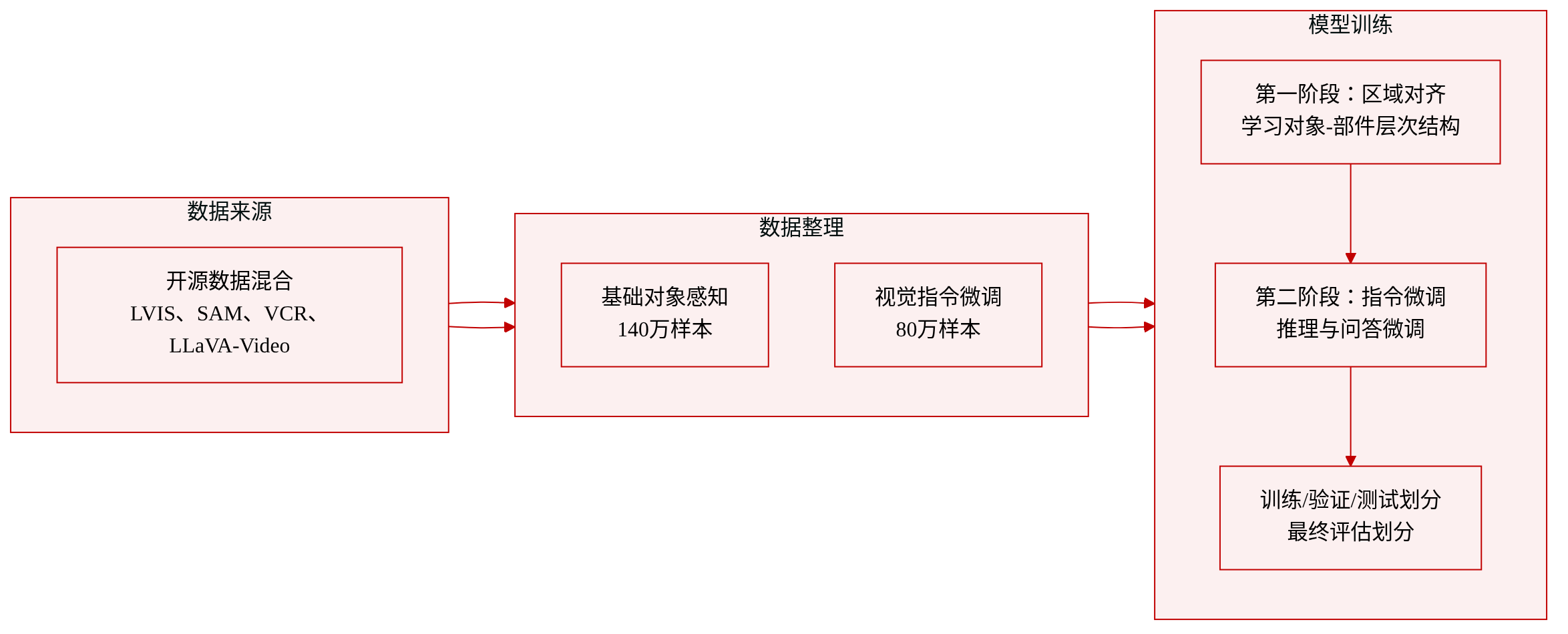
作者对跨 LLM 层的注意力分布进行了实证分析,以理解 object tokens 如何被使用。如下图所示,在所有层中,答案 token 对 object tokens 的注意力始终强于对全局视觉 token 的注意力,这表明 object tokens 是用于问答的主要语义锚点。
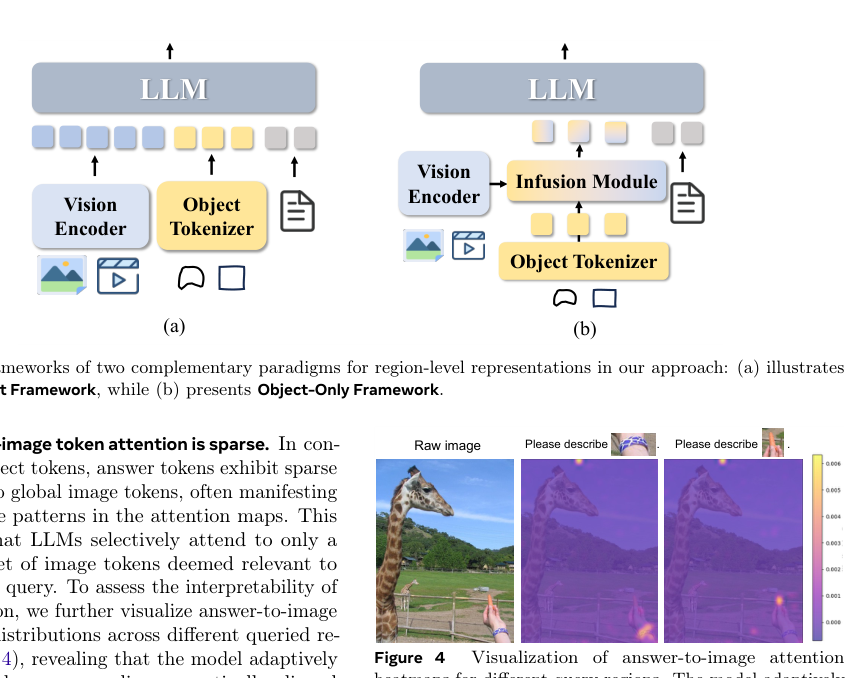
此外,答案 token 对全局图像 token 的注意力是稀疏的。为了评估这种选择的可解释性,作者可视化了在不同查询区域上的答案到图像的注意力分布,揭示出模型自适应地突出显示语义对齐的对象区域,同时偶尔会从更广泛的空间上下文中引入上下文线索。
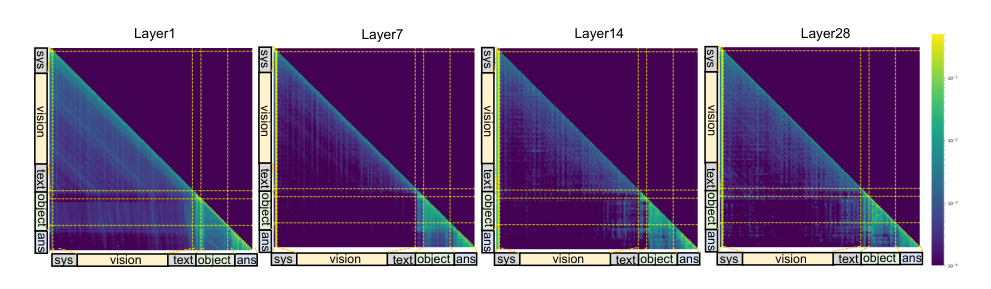
基于这些见解,作者提出了两个互补的范式:基于视觉-对象框架的 PixelRefer 和基于仅对象框架的 PixelRefer-Lite。视觉-对象框架包含一个视觉编码器、一个对象分词器、一个文本分词器和一个遵循指令的 LLM。给定一个视频 V∈RN×H×W×C,视觉编码器 Ev 提取一个特征图 Z,将时空场景级信息编码为视觉 token TZ。对于一组用户指定的区域 R={R1,R2,…,Rn},对象分词器 ER 生成 object tokens TR=ER(R,Z)。这些 token 被联合输入到 LLM 中:Y=Φ(TZ,TR,TX)。
为了在不同尺度上生成准确的 object tokens,作者引入了一个尺度自适应对象分词器 (SAOT)。与朴素的池化策略不同,SAOT 动态调整区域尺度以处理尺度变化并保留空间上下文。
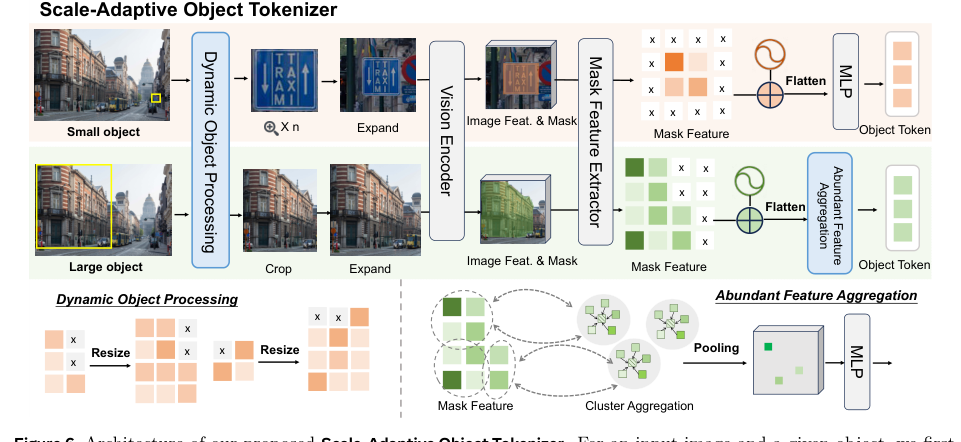
给定一张输入图像 I∈R3×HI×WI 和一个二进制掩码 M,该方法计算一个缩放比例 s: s=⎩⎨⎧∣M∣Ω⋅100,∣M∣Ω⋅n,1,if ∣M∣>100⋅Ωelseif ∣M∣<n⋅Ωotherwise 其中 ∣M∣ 是前景像素的数量,Ω 是 patch 的大小,n 是每个对象的 token 数量。小对象被放大,大对象被缩小。应用上下文填充,并提取被掩码的空间特征 FM=FR⊙M。引入相对位置编码以减轻定位歧义: FMP=(FM+Linear(pi,j))[M=1] 为了减少大区域或同质区域中的冗余,作者采用了一种使用 k-means 聚类的丰富特征聚合策略。
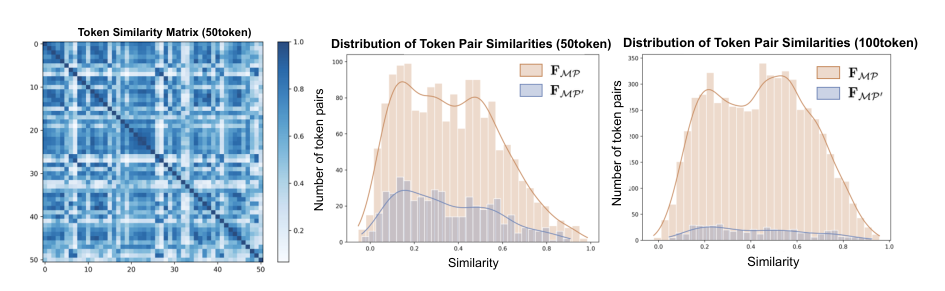
保留每个簇 Ci 的平均嵌入:FMP′=∣Ci∣1∑j∈CiFMPj。然后,一个 MLP 生成最终的 object tokens。
由于对全局视觉 token 的注意力集中在早期 LLM 层,作者提出 PixelRefer-Lite 以减少计算开销。仅对象框架包含一个轻量级注入模块,用于将全局视觉上下文 TZ 集成到 object tokens TR 中:TO=Ψ(TR,TZ)。细化后的 token 被解码为 Y=Φ(TO,TX)。以对象为中心的注入 (OCI) 模块使用一个两步交叉注意力策略。局部到对象注意力注入来自局部扩展区域的细粒度嵌入,而全局到对象注意力则以场景级嵌入为条件调整 object tokens。对于视频,时间戳嵌入被前置到 object tokens 之前。
作者采用了一个两阶段的训练过程。首先,使用共计 140 万个样本的基础对象感知数据(涵盖区域识别、区域图像详细描述和区域视频详细描述)来加强细粒度区域对齐。
其次,使用 80 万个样本进行视觉指令微调,包括图像区域问答、视频对象问答、区域描述和通用问答,赋予模型遵循指令和推理的能力。
实验
实验评估了 PixelRefer,一个基于 VideoLLaMA 3 并配备尺度自适应对象分词器的模型,在包括类别识别、描述和问答在内的图像和视频区域理解任务上的表现。结果在细粒度基准上展示了最优性能,而仅对象框架在计算成本大幅降低的同时,准确率损失极小。消融研究验证了分词器的自适应缩放、以对象为中心的上下文注入以及多样化训练数据对于鲁棒区域级感知的益处。
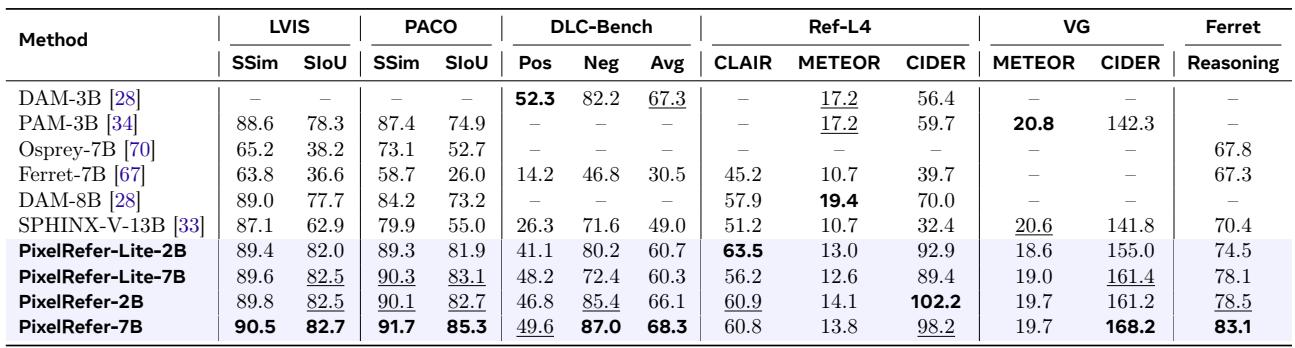
PixelRefer 模型在多样化的图像级区域理解基准上取得了最优结果,在部件级类别识别、详细描述和短语级描述方面表现出色。最大的 PixelRefer-7B 在 PACO 和 DLC-Bench 上创下新高,而轻量级变体则以显著优势超越了之前的顶级模型,尤其是在语义 IoU 和 CIDER 分数方面。短语级描述在 VG 和 Ref-L4 上显示出巨大改进,突显了其强大的细粒度区域描述能力。在包含对象和小的部件级区域的具有挑战性的 PACO 基准测试中,PixelRefer-7B 的语义 IoU 相较于之前的最佳模型提高了超过 10 个百分点,即使是轻量级版本也超越了之前的最先进技术。PixelRefer-2B 在 Ref-L4 上的 zero-shot 短语描述评估中,CIDER 得分相对之前最佳提高了 32%,而最大模型在 VG 上的 CIDER 得分更是早期方法的两倍以上。
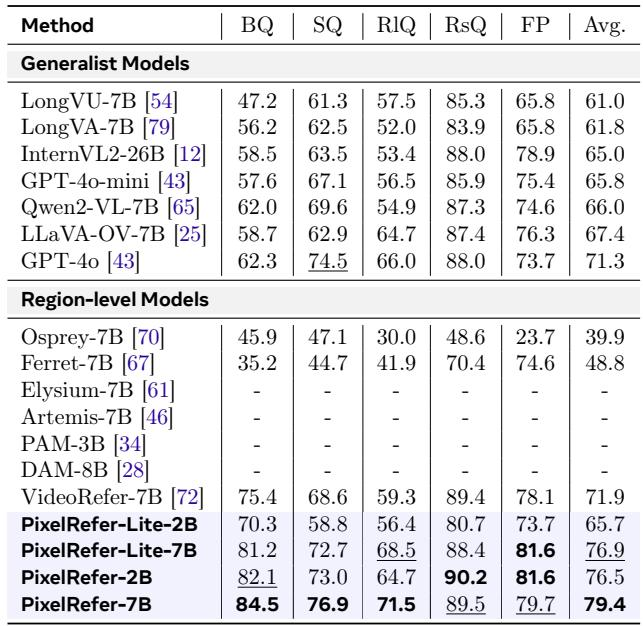
在 VideoRefer-BenchD 上使用单帧掩码的通才模型中,GPT-4o 取得了最高平均分,在动作、时间和整体描述方面表现出色。InternVL2-26B 在空间描述上领先但总分位居第二,而 Qwen2-VL-7B、LLaVA-OV-7B 和 LongVA-7B 的分数紧随其后并聚集在一起。InternVL2-26B 在空间描述中取得了最高分 (3.55),优于 GPT-4o (3.34) 和其他通才模型。GPT-4o 在参与比较的通才模型中获得了最高的平均性能 (2.95),并在动作描述、时间描述和整体描述上排名第一。
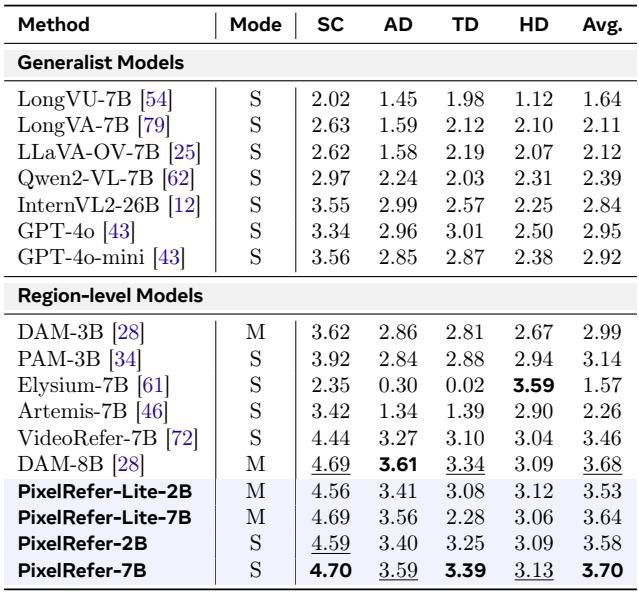
在 HC-STVG 视频描述基准上,PixelRefer-7B 在所有指标上超越了先前的最佳方法 DAM-8B,CIDER 提升了 6.1 个点,幅度尤为显著。轻量级变体 PixelRefer-Lite-7B 在效率更高的同时,取得了可比的性能。PixelRefer-7B 的 CIDER 达到了 97.4,超过了 DAM-8B 的 91.0,并且在 METEOR、BLEU@4、ROUGE-L 和 SPICE 上均有持续提升。先前方法中的 3B 参数模型 PAM-3B 在 METEOR (23.3) 上领先,但在 CIDER (70.3) 上得分较低,揭示了 PixelRefer 能够解决的一个指标权衡问题。
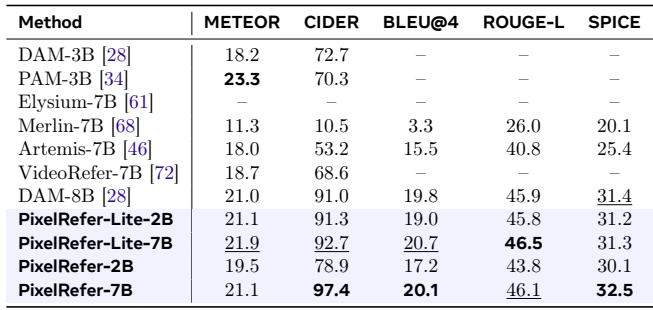
PixelRefer 在 VideoRefer-BenchQ 视频问答基准上设立了新的最优水平,在所有模型中取得了最高的平均准确率。它超越了开源通才模型以及像 GPT-4o 这样的闭源系统,在推理和未来预测问题上表现出尤为强劲的结果。这些性能提升突显了该模型在回答关于所指视频区域的动态、上下文感知查询方面的卓越能力。PixelRefer 在 VideoRefer-BenchQ 上的平均准确率超过闭源模型 GPT-4o 8.1 个百分点。它在所有问题类型上都取得了领先的分数,尤其是在推理问题上达到 89.5%,在未来预测问题上达到 79.7%。
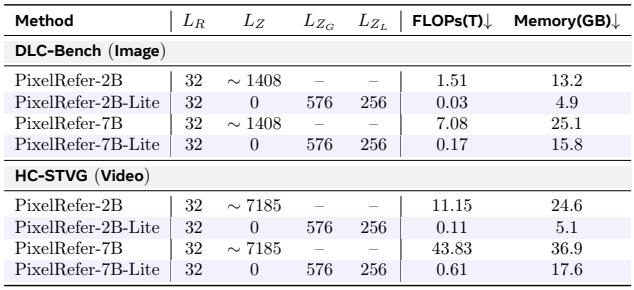
应用仅对象框架可以大幅降低计算量和内存使用,其效率提升在不同模型规模以及图像和视频设置下均保持一致。Lite 变体将 FLOPs 降低了大约两个数量级,同时内存使用量降至完整模型需求的一小部分,使得该方法具有高度可扩展性。使用 PixelRefer-2B-Lite 的视频推理仅消耗 0.11T FLOPs 和 5.1 GB 内存,而标准 2B 模型则需 11.15T FLOPs 和 24.6 GB,分别大约降低了 99% 和 79%。这种效率模式在各规模下均成立:PixelRefer-7B-Lite 在图像上实现了 0.17T FLOPs 和 15.8 GB,而完整的 7B 模型则为 7.08T FLOPs 和 25.1 GB。
PixelRefer 模型在一系列广泛的区域级理解任务上进行了评估,包括图像部件识别、短语描述、视频描述和视频问答。最大的 PixelRefer-7B 建立了新的最先进结果,超越了开源通才模型以及像 GPT-4o 这样的闭源系统,在细粒度描述和推理方面具有显著优势。使用仅对象框架构建的轻量级变体在保持有竞争力的性能的同时,将计算成本降低了大约两个数量级,展示了该方法的可扩展性和效率。