HyperAI
HyperAI
メイン
ホーム
GPU
コンソール
ドキュメント
料金
パルス
ニュース
リソース
論文
ノートブック
データセット
Wiki
ベンチマーク
SOTA
LLMモデル
GPUランキング
コミュニティ
イベント
ユーティリティ
検索
概要
利用規約
プライバシーポリシー
日本語
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
サインイン
HyperAI
Papers
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
HyperAI
HyperAI
メイン
ホーム
GPU
コンソール
ドキュメント
料金
パルス
ニュース
リソース
論文
ノートブック
データセット
Wiki
ベンチマーク
SOTA
LLMモデル
GPUランキング
コミュニティ
イベント
ユーティリティ
検索
概要
利用規約
プライバシーポリシー
日本語
HyperAI
HyperAI
Toggle Sidebar
⌘
K
Command Palette
Search for a command to run...
サインイン
HyperAI
Papers
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文
LLaDA2.1:トークン編集によるテキスト拡散の高速化
拡散モデル
LLM
Tiwei Bie, Maosong Cao, Xiang Cao, et al.
FlowベースのGRPOにおけるステップワイズおよび長期的サンプリング効果のモデリングによるスパース報酬の軽減
拡散モデル
画像生成
Yunze Tong, Mushui Liu, Canyu Zhao, et al.
再帰的深度VLA:潜在反復推論を用いた視覚言語行動モデルのテスト時計算スケーリングの陰的実現
マルチモーダル
LLM
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, et al.
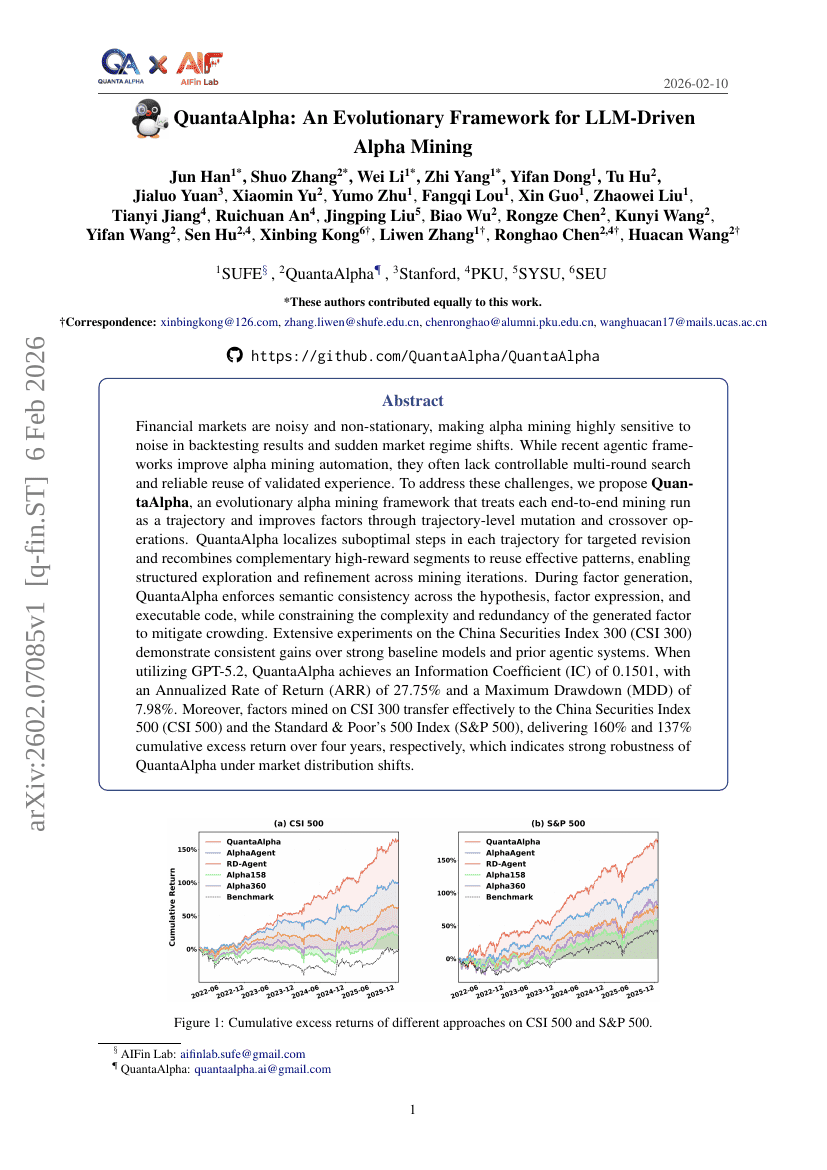
QuantAlphaAlpha:LLM駆動型アルファマイニングのための進化的フレームワーク
金融
LLM
Jun Han, Shuo Zhang, Wei Li, et al.
モダリティギャップ駆動型部分空間アライメント訓練パラダイム:マルチモーダル大規模言語モデル向け
マルチモーダル
マルチモーダル表現
Xiaomin Yu, Yi Xin, Wenjie Zhang, et al.
MOVA:スケーラブルかつ同期的な動画・音声生成へ向けて
動画生成
マルチモーダル
SII-OpenMOSS Team, Donghua Yu, Mingshu Chen, et al.
MemoryLLM:即插即用の解釈可能な順方向メモリを備えたトランスフォーマー
Transformer
LLM
Ajay Jaiswal, Lauren Hannah, Han-Byul Kim, et al.
DreamDojo:大規模なヒューマンビデオから得た汎用ロボットワールドモデル
マルチモーダル
ビデオ理解
Shenyuan Gao, William Liang, Kaiyuan Zheng, et al.
F-GRPO:明白なことを学ばせすぎず、まれなことを忘れさせないために
強化学習
LLM
Daniil Plyusov, Alexey Gorbatovski, Boris Shaposhnikov, et al.
MSign:安定ランク回復による大規模言語モデルの学習不安定を防止する最適化手法
モデル学習
LLM
Lianhai Ren, Yucheng Ding, Xiao Liu, et al.
AudioSAE:スパース自己符号化器を用いた音声処理モデルの理解に向けて
音声および音声処理
ディープラーニング
Georgii Aparin, Tasnima Sadekova, Alexey Rukhovich, et al.
大規模言語モデルの強化学習ファインチューニングにおけるエントロピー動態について
強化学習
LLM
Shumin Wang, Yuexiang Xie, Wenhao Zhang, et al.
オデッセイアリーナ:ロングホライズン、アクティブかつ誘導的インタラクションにおける大規模言語モデルのベンチマーク
エージェント
LLM
Fangzhi Xu, Hang Yan, Qiushi Sun, et al.
Baichuan-M3:信頼性のある医療意思決定のための臨床質問モデリング
LLM
医学
Baichuan-M3 Team, Chengfeng Dou, Fan Yang, et al.
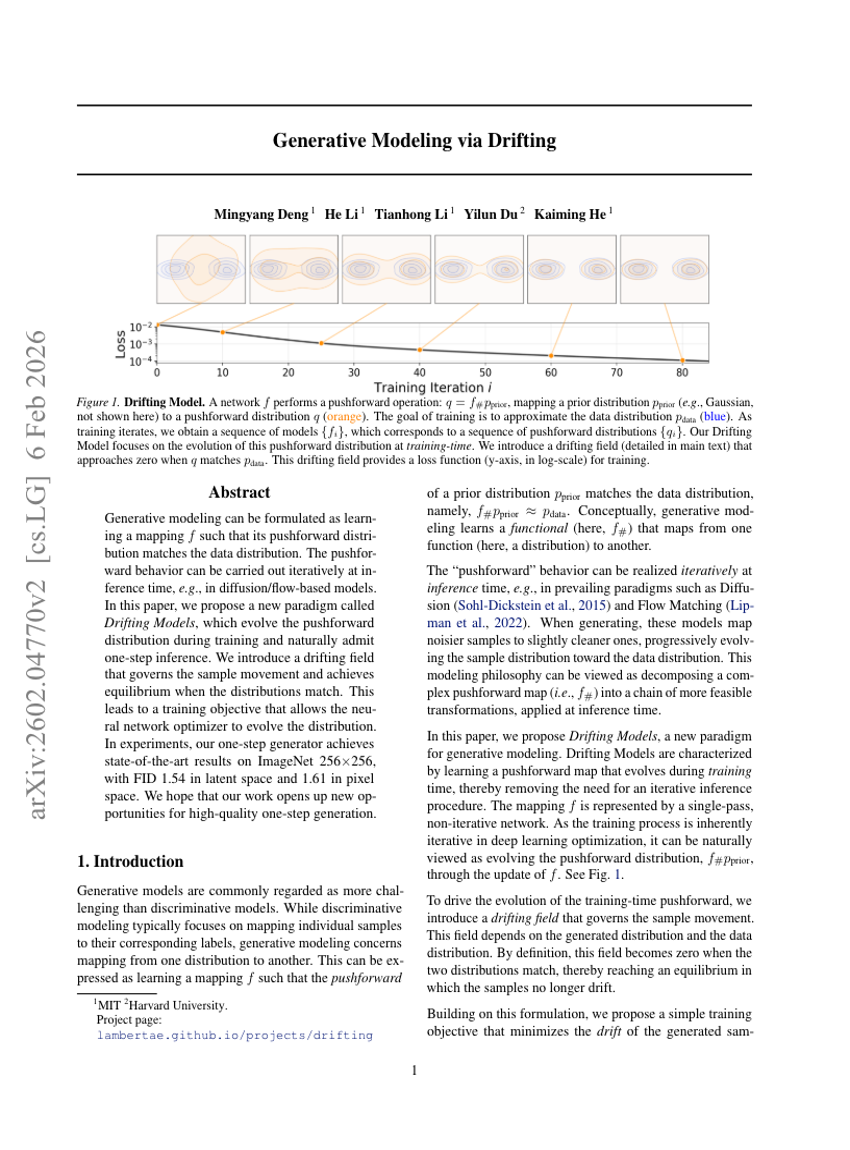
拡散を用いた生成モデリング
拡散モデル
画像生成
Mingyang Deng, He Li, Tianhong Li, Kaiming He
AlphaEdit:言語モデル向けのノルム空間制約付き知識編集
LLM
テキスト生成
Junfeng Fang, Houcheng Jiang, Kun Wang, et al.
13パラメータにおける推論の学習
Reasoning
インテリジェントな質問応答
John X. Morris, Niloofar Mireshghallah, Mark Ibrahim, et al.
DFlash:フラッシュ予測デコードのためのブロック拡散
LLM
拡散モデル
Jian Chen, Yesheng Liang, Zhijian Liu
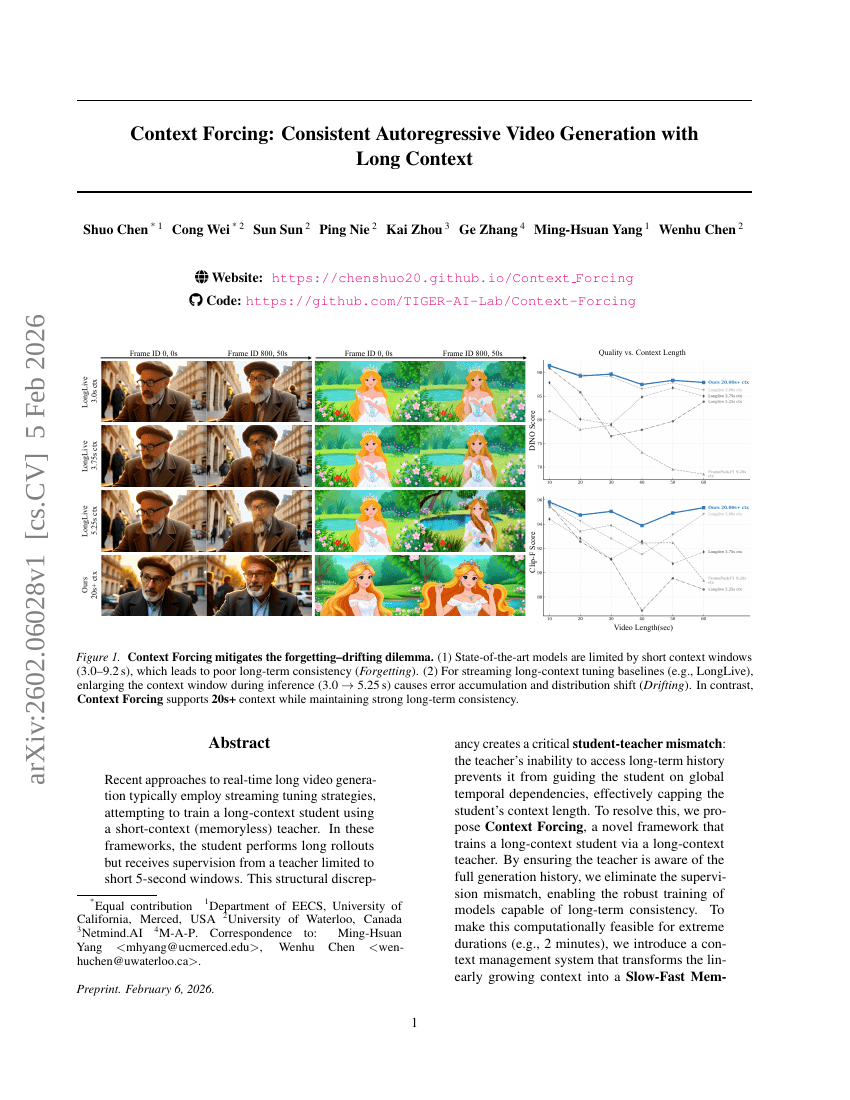
コンテキストフォースティング:長文コンテキストを用いた一貫性のある自己回帰型動画生成
動画生成
拡散モデル
Shuo Chen, Cong Wei, Sun Sun, et al.
MemSkill:自己進化型エージェントにおける記憶スキルの学習と進化
エージェント
LLM
Haozhen Zhang, Quanyu Long, Jianzhu Bao, et al.
長さバイアスのないシーケンス方策最適化:RLVRにおける応答長さの変動の解明と制御
強化学習
LLM
Fanfan Liu, Youyang Yin, Peng Shi, et al.
スパイラーデンス:階層的適応スクリーニングを用いた効率的なエージェント防御のための内在的リスクセンシング
エージェント
LLM
Zhenxiong Yu, Zhi Yang, Zhiheng Jin, et al.
CAR-bench:現実世界の不確実性下におけるLLMエージェントの一貫性および限界認識能力の評価
LLM
エージェント
Johannes Kirmayr, Lukas Stappen, Elisabeth André
WeDLM:高速推論を実現するための拡散言語モデルと標準的な因果アテンションの調和
拡散モデル
LLM
Aiwei Liu, Minghua He, Shaoxun Zeng, et al.
Fun-ASR 技術報告
LLM
音声認識
Keyu An, Yanni Chen, Zhigao Chen, et al.
Geminiを活用した科学研究の加速:事例研究と一般的な手法
サイエンスのためのAI
LLM
David P. Woodruff, Vincent Cohen-Addad, Lalit Jain, et al.
戦略入札を用いた小規模エージェントのスケーリング
エージェント
LLM
Lisa Alazraki, William F. Shen, Yoram Bachrach, et al.
バイブAIGC:エージェント統合によるコンテンツ生成の新たなパラダイム
エージェント
マルチモーダル
Jiaheng Liu, Yuanxing Zhang, Shihao Li, et al.
PaperSearchQA:RLVRを用いた科学論文における検索と推論の学習
検索拡張生成
サイエンスのためのAI
James Burgess, Jan N. Hansen, Duo Peng, et al.
EgoActor:視覚言語モデルを活用した空間認識型自己中心行動へのタスク計画の根拠化による人間型ロボット向けアプローチ
マルチモーダル
視覚質問応答
Yu Bai, MingMing Yu, Chaojie Li, et al.
A-RAG:階層的リトリーブインターフェースを活用したエージェント型リトリーブ増強生成のスケーラビリティ向上
検索拡張生成
エージェント
Mingxuan Du, Benfeng Xu, Chiwei Zhu, et al.
Quant VideoGen:2ビットKVキャッシュ量子化を用いた自己回帰型長時間動画生成
動画生成
拡散モデル
Haocheng Xi, Shuo Yang, Yilong Zhao, et al.
1
2
3
4
49
LLaDA2.1:トークン編集によるテキスト拡散の高速化
拡散モデル
LLM
Tiwei Bie, Maosong Cao, Xiang Cao, et al.
FlowベースのGRPOにおけるステップワイズおよび長期的サンプリング効果のモデリングによるスパース報酬の軽減
拡散モデル
画像生成
Yunze Tong, Mushui Liu, Canyu Zhao, et al.
再帰的深度VLA:潜在反復推論を用いた視覚言語行動モデルのテスト時計算スケーリングの陰的実現
マルチモーダル
LLM
Yalcin Tur, Jalal Naghiyev, Haoquan Fang, et al.
QuantAlphaAlpha:LLM駆動型アルファマイニングのための進化的フレームワーク
金融
LLM
Jun Han, Shuo Zhang, Wei Li, et al.
モダリティギャップ駆動型部分空間アライメント訓練パラダイム:マルチモーダル大規模言語モデル向け
マルチモーダル
マルチモーダル表現
Xiaomin Yu, Yi Xin, Wenjie Zhang, et al.
MOVA:スケーラブルかつ同期的な動画・音声生成へ向けて
動画生成
マルチモーダル
SII-OpenMOSS Team, Donghua Yu, Mingshu Chen, et al.
MemoryLLM:即插即用の解釈可能な順方向メモリを備えたトランスフォーマー
Transformer
LLM
Ajay Jaiswal, Lauren Hannah, Han-Byul Kim, et al.
DreamDojo:大規模なヒューマンビデオから得た汎用ロボットワールドモデル
マルチモーダル
ビデオ理解
Shenyuan Gao, William Liang, Kaiyuan Zheng, et al.
F-GRPO:明白なことを学ばせすぎず、まれなことを忘れさせないために
強化学習
LLM
Daniil Plyusov, Alexey Gorbatovski, Boris Shaposhnikov, et al.
MSign:安定ランク回復による大規模言語モデルの学習不安定を防止する最適化手法
モデル学習
LLM
Lianhai Ren, Yucheng Ding, Xiao Liu, et al.
AudioSAE:スパース自己符号化器を用いた音声処理モデルの理解に向けて
音声および音声処理
ディープラーニング
Georgii Aparin, Tasnima Sadekova, Alexey Rukhovich, et al.
大規模言語モデルの強化学習ファインチューニングにおけるエントロピー動態について
強化学習
LLM
Shumin Wang, Yuexiang Xie, Wenhao Zhang, et al.
オデッセイアリーナ:ロングホライズン、アクティブかつ誘導的インタラクションにおける大規模言語モデルのベンチマーク
エージェント
LLM
Fangzhi Xu, Hang Yan, Qiushi Sun, et al.
Baichuan-M3:信頼性のある医療意思決定のための臨床質問モデリング
LLM
医学
Baichuan-M3 Team, Chengfeng Dou, Fan Yang, et al.
拡散を用いた生成モデリング
拡散モデル
画像生成
Mingyang Deng, He Li, Tianhong Li, Kaiming He
AlphaEdit:言語モデル向けのノルム空間制約付き知識編集
LLM
テキスト生成
Junfeng Fang, Houcheng Jiang, Kun Wang, et al.
13パラメータにおける推論の学習
Reasoning
インテリジェントな質問応答
John X. Morris, Niloofar Mireshghallah, Mark Ibrahim, et al.
DFlash:フラッシュ予測デコードのためのブロック拡散
LLM
拡散モデル
Jian Chen, Yesheng Liang, Zhijian Liu
コンテキストフォースティング:長文コンテキストを用いた一貫性のある自己回帰型動画生成
動画生成
拡散モデル
Shuo Chen, Cong Wei, Sun Sun, et al.
MemSkill:自己進化型エージェントにおける記憶スキルの学習と進化
エージェント
LLM
Haozhen Zhang, Quanyu Long, Jianzhu Bao, et al.
長さバイアスのないシーケンス方策最適化:RLVRにおける応答長さの変動の解明と制御
強化学習
LLM
Fanfan Liu, Youyang Yin, Peng Shi, et al.
スパイラーデンス:階層的適応スクリーニングを用いた効率的なエージェント防御のための内在的リスクセンシング
エージェント
LLM
Zhenxiong Yu, Zhi Yang, Zhiheng Jin, et al.
CAR-bench:現実世界の不確実性下におけるLLMエージェントの一貫性および限界認識能力の評価
LLM
エージェント
Johannes Kirmayr, Lukas Stappen, Elisabeth André
WeDLM:高速推論を実現するための拡散言語モデルと標準的な因果アテンションの調和
拡散モデル
LLM
Aiwei Liu, Minghua He, Shaoxun Zeng, et al.
Fun-ASR 技術報告
LLM
音声認識
Keyu An, Yanni Chen, Zhigao Chen, et al.
Geminiを活用した科学研究の加速:事例研究と一般的な手法
サイエンスのためのAI
LLM
David P. Woodruff, Vincent Cohen-Addad, Lalit Jain, et al.
戦略入札を用いた小規模エージェントのスケーリング
エージェント
LLM
Lisa Alazraki, William F. Shen, Yoram Bachrach, et al.
バイブAIGC:エージェント統合によるコンテンツ生成の新たなパラダイム
エージェント
マルチモーダル
Jiaheng Liu, Yuanxing Zhang, Shihao Li, et al.
PaperSearchQA:RLVRを用いた科学論文における検索と推論の学習
検索拡張生成
サイエンスのためのAI
James Burgess, Jan N. Hansen, Duo Peng, et al.
EgoActor:視覚言語モデルを活用した空間認識型自己中心行動へのタスク計画の根拠化による人間型ロボット向けアプローチ
マルチモーダル
視覚質問応答
Yu Bai, MingMing Yu, Chaojie Li, et al.
A-RAG:階層的リトリーブインターフェースを活用したエージェント型リトリーブ増強生成のスケーラビリティ向上
検索拡張生成
エージェント
Mingxuan Du, Benfeng Xu, Chiwei Zhu, et al.
Quant VideoGen:2ビットKVキャッシュ量子化を用いた自己回帰型長時間動画生成
動画生成
拡散モデル
Haocheng Xi, Shuo Yang, Yilong Zhao, et al.
1
2
3
4
49