HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

人間とAIの補完性:拡張された監視のための目標

GPTOpt:効率的なLLMベースのブラックボックス最適化へ向けて




























人間とAIの補完性:拡張された監視のための目標
GPTOpt:効率的なLLMベースのブラックボックス最適化へ向けて
VFXMaster:文脈学習を活用した動的ビジュアルエフェクト生成の解明
プロセスマイニングを用いた推論対応型GRPO
ループ型言語モデルを用いた潜在的推論のスケーリング
ReForm:予測的有限列最適化を用いた反映型オートフォーマライゼーション
Video-Thinker:強化学習を活用した「動画を用いた思考」の促進
JanusCoder:コードインテリジェンスのための基盤的視覚・プログラマティックインターフェースへ向けて
MCP-Flow:大規模言語モデルエージェントが現実世界の多様でスケーラブルなMCPツールを習得するのを支援する
OmniCast:時間スケールにわたる気象予測のためのマスクされた潜在拡散モデル
動画生成のための均一離散拡散とメトリック経路
Game-TARS:スケーラブルな汎用マルチモーダルゲームエージェントのための事前学習基盤モデル
ロボオムニ:オムニモーダルな文脈における能動的ロボット操作
AgentFold:能動的コンテキスト管理を備えた長期予測Webエージェント
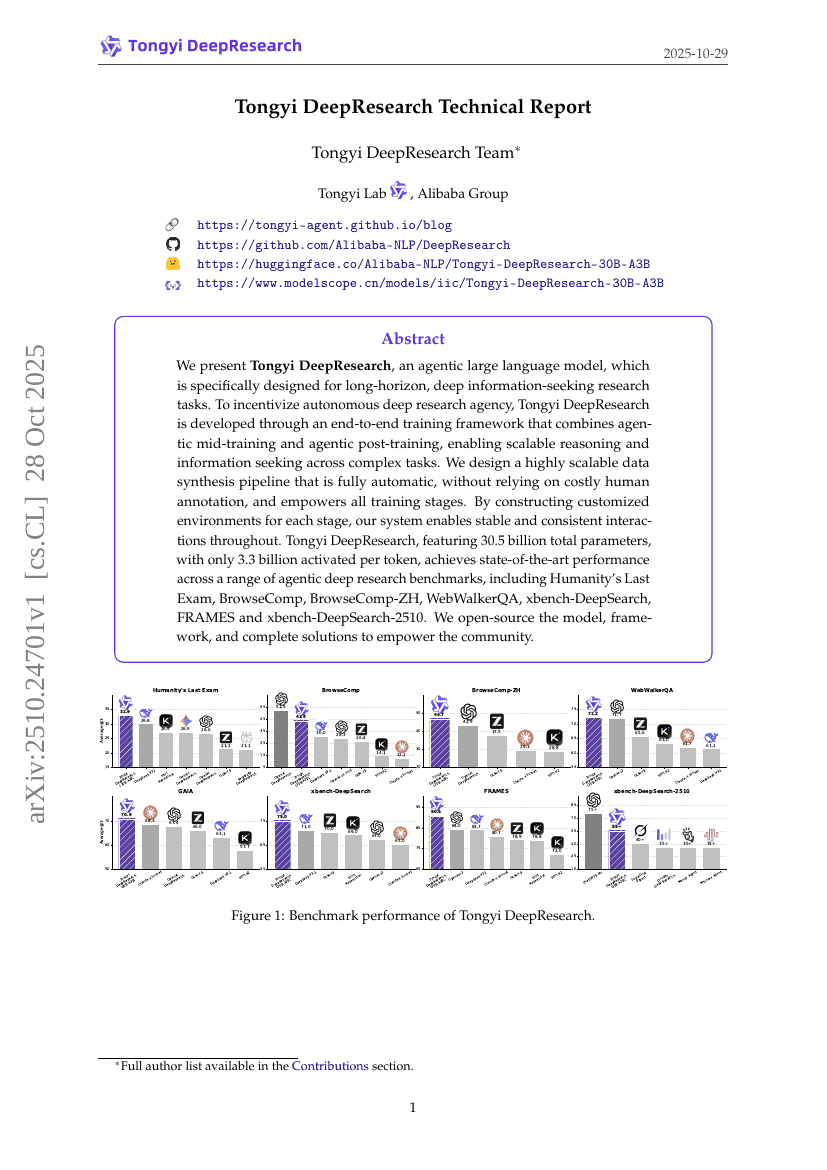
通義ディープリサーチ 技術報告
InteractComp:曖昧なクエリを用いた検索エージェントの評価
VLM-SlideEval:PPTにおける構造的理解力および摂動感受性に関するVLMの評価
TeraSim-World:エンドツーエンド自動運転向け世界規模の安全関連データ合成
ラックヘッドアンカリング:音声駆動型人間アニメーションにおけるキャラクター個体性の保持
VITA-E:同時視覚、聴覚、発話および行動を伴う自然なエンボディドインタラクション
FARMER:画素上におけるフロー自己回帰型トランスフォーマー
データエージェントに関する総説:新たなパラダイムか、過大評価されたブームか?
ReCode:包括する粒度制御のための計画と実行の統一
コンチェルト:2次元-3次元連合自己教師学習が空間表現を生み出す
マゼラン:潜在空間探索および新規性生成のための誘導付きMCTS
DEEDEE:分布外動態の高速かつスケーラブルな検出
トークン順列を用いたスパーサーなブロックスパース注意力
AGIの定義
ノイズ除去から精緻化へ:視覚言語拡散モデルのための補正フレームワーク
ステップバイステップ、チャンクごとに最適化:テキストから画像生成におけるチャンクレベルGRPO
ビデオ・アス・プロンプト:ビデオ生成における統一された意味制御
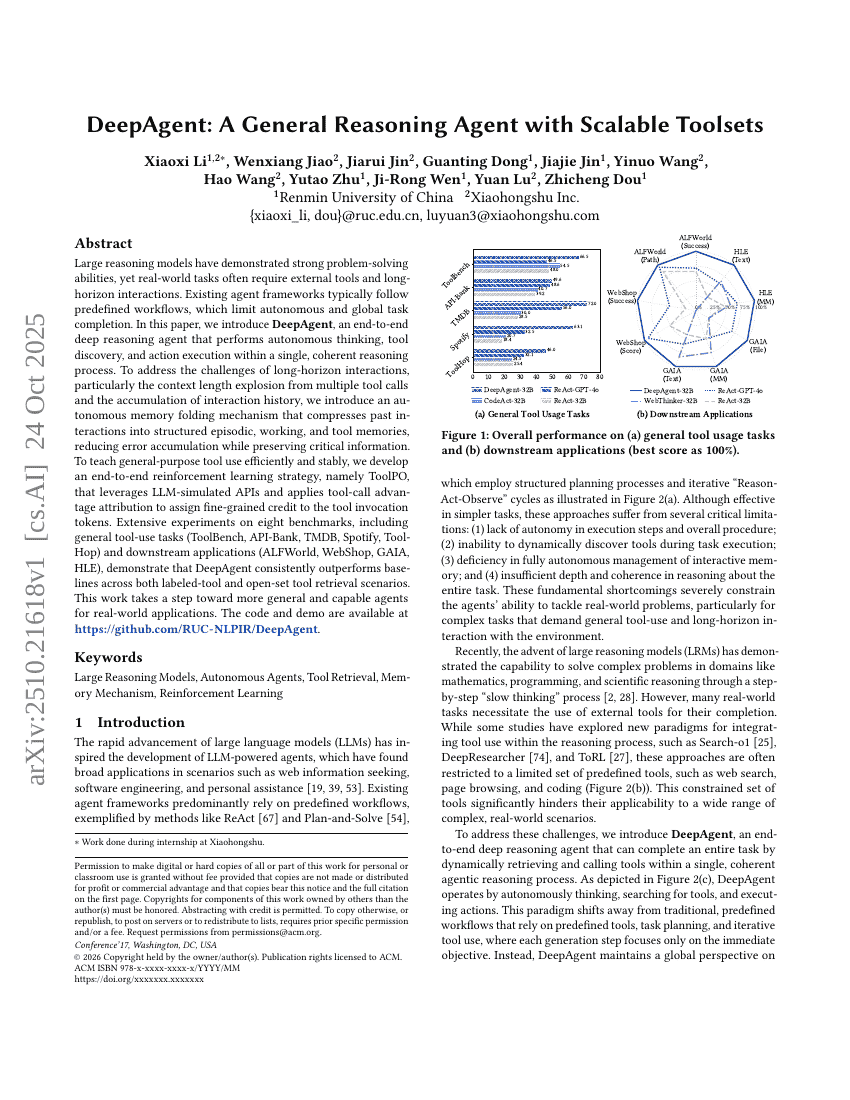
DeepAgent:スケーラブルなツールセットを備えた汎用推論エージェント
VFXMaster:文脈学習を活用した動的ビジュアルエフェクト生成の解明
プロセスマイニングを用いた推論対応型GRPO
ループ型言語モデルを用いた潜在的推論のスケーリング
ReForm:予測的有限列最適化を用いた反映型オートフォーマライゼーション
Video-Thinker:強化学習を活用した「動画を用いた思考」の促進
JanusCoder:コードインテリジェンスのための基盤的視覚・プログラマティックインターフェースへ向けて
MCP-Flow:大規模言語モデルエージェントが現実世界の多様でスケーラブルなMCPツールを習得するのを支援する
OmniCast:時間スケールにわたる気象予測のためのマスクされた潜在拡散モデル
動画生成のための均一離散拡散とメトリック経路
Game-TARS:スケーラブルな汎用マルチモーダルゲームエージェントのための事前学習基盤モデル
ロボオムニ:オムニモーダルな文脈における能動的ロボット操作
AgentFold:能動的コンテキスト管理を備えた長期予測Webエージェント
通義ディープリサーチ 技術報告
InteractComp:曖昧なクエリを用いた検索エージェントの評価
VLM-SlideEval:PPTにおける構造的理解力および摂動感受性に関するVLMの評価
TeraSim-World:エンドツーエンド自動運転向け世界規模の安全関連データ合成
ラックヘッドアンカリング:音声駆動型人間アニメーションにおけるキャラクター個体性の保持
VITA-E:同時視覚、聴覚、発話および行動を伴う自然なエンボディドインタラクション
FARMER:画素上におけるフロー自己回帰型トランスフォーマー
データエージェントに関する総説:新たなパラダイムか、過大評価されたブームか?
ReCode:包括する粒度制御のための計画と実行の統一
コンチェルト:2次元-3次元連合自己教師学習が空間表現を生み出す
マゼラン:潜在空間探索および新規性生成のための誘導付きMCTS
DEEDEE:分布外動態の高速かつスケーラブルな検出
トークン順列を用いたスパーサーなブロックスパース注意力
AGIの定義
ノイズ除去から精緻化へ:視覚言語拡散モデルのための補正フレームワーク
ステップバイステップ、チャンクごとに最適化:テキストから画像生成におけるチャンクレベルGRPO
ビデオ・アス・プロンプト:ビデオ生成における統一された意味制御
DeepAgent:スケーラブルなツールセットを備えた汎用推論エージェント