Command Palette
Search for a command to run...
ChordEdit:画像編集のためのワンステップ・低エネルギー輸送
ChordEdit:画像編集のためのワンステップ・低エネルギー輸送
Liangsi Lu Xuhang Chen Minzhe Guo Shichu Li Jingchao Wang Yang Shi
概要
1ステップのテキストから画像への生成(Text-to-Image: T2I)モデルの登場は、前例のない合成速度を実現した。しかし、テキストによる画像編集への応用は依然として大幅に制限されている。既存のトレーニングフリーな編集手法を1回の推論ステップに無理やり適用することは失敗に終わり、その結果、対象オブジェクトの著しい歪みと、編集対象外の領域における整合性の致命的な損失が生じる。これは、モデルの構造化フィールド(structured fields)における単純なベクトル演算が高エネルギーかつ erratic(規則的でない)な軌道を生成することに起因する。この問題に対処するため、本研究ではChordEditと呼ばれる、モデル非依存でトレーニングフリーかつinversion-freeな手法を提案する。本手法は、ソースとターゲットのテキストプロンプトによって定義されるソースおよびターゲット分布間の輸送問題として編集を再定義する。動的最適な輸送理論(dynamic optimal transport theory)を活用し、原理的かつ低エネルギーの制御戦略を導出する。この戦略は、内在的に安定した、平滑化され分散が低減された編集フィールドを生成し、このフィールドを1回の大きな積分ステップで横断することを可能にする。理論的根拠に裏打ちされ、実験的に検証された本アプローチにより、ChordEditは高速で軽量かつ高精度な編集を提供し、これらの難易度の高いモデルにおいて真のリアルタイム編集をようやく実現した。
One-sentence Summary
ChordEdit is a model-agnostic, training-free, and inversion-free method for one-step text-guided image editing that leverages dynamic optimal transport theory to recast editing as a transport problem between source and target distributions, deriving a low-energy control strategy that yields a stable editing field for single-step integration, enabling fast, precise real-time edits without object distortion or loss of consistency in non-edited regions.
Key Contributions
- ChordEdit is introduced as a model-agnostic, training-free, and inversion-free method that facilitates high-fidelity one-step editing for text-to-image models. This approach avoids severe object distortion and consistency loss associated with naive vector arithmetic by operating within the challenging single-step regime.
- Editing is recast as a transport problem between source and target distributions, leveraging dynamic optimal transport theory to derive a principled, low-energy control strategy. This strategy yields a smoothed, variance-reduced editing field constructed directly in the observable residual domain, which remains stable enough to be traversed in a single large integration step.
- Experimental validation confirms the method delivers fast, lightweight, and precise edits while achieving true real-time editing on challenging models. A four-way blind user study shows ChordEdit wins in Semantic Alignment at 42.5% and Preservation Quality at 48.3%, demonstrating its superior overall performance.
Introduction
One-step text-to-image models enable real-time synthesis, creating a demand for fast text-guided image editing. Existing training-free editors fail in this regime because naive vector arithmetic creates unstable control fields that distort objects and disrupt background consistency, while training-based alternatives sacrifice flexibility by requiring dedicated inversion networks. The authors introduce ChordEdit, a model-agnostic method that reformulates editing as a dynamic optimal transport problem to derive a stable Chord Control Field. This approach replaces erratic vector arithmetic and enables precise single-step edits without training or inversion.
Dataset
- The authors conduct empirical evaluation on the PIE-bench benchmark, which is a standard dataset for instruction-based image editing.
- The dataset comprises 700 samples distributed across 10 distinct editing categories.
- Each instance provides a source image, textual prompts, and a precise ground-truth mask delineating the edit region.
- Images are standardized to a resolution of 512×512.
- Performance is assessed along two axes: background fidelity and semantic alignment.
- Background fidelity is quantified using Peak Signal-to-Noise Ratio and Mean Squared Error computed on non-edited regions.
- Semantic alignment is measured via CLIP-Whole and CLIP-Edited scores to evaluate textual-visual consistency.
- For fair comparison of background fidelity, all methods are evaluated without the use of internal or external protective masks.
Method
The authors address the challenge of image editing in one-step diffusion models by reframing the problem within the context of conditional probability flow. A pre-trained text-to-image model induces a conditional probability flow with a drift v(xt,t,c), defined by the ordinary differential equation:
dtdxt=v(xt,t,c).Given source and target prompts csrc and ctar, the goal is to transport an initial image xsrc to an edited image xtar. Ideally, this is achieved by modifying the source flow with the instantaneous residual:
Δv(xt,t) = v(xt,t,ctar)−v(xt,t,csrc).While this simple drift strategy works for multi-step generation where errors can be corrected iteratively, it fails catastrophically in one-step settings. In distilled models, the naive field Δv(xt,t) is often high-energy and irregular. A single integration step using this field accumulates significant error, causing the generated image to deviate significantly from the target.
As shown in the figure below:
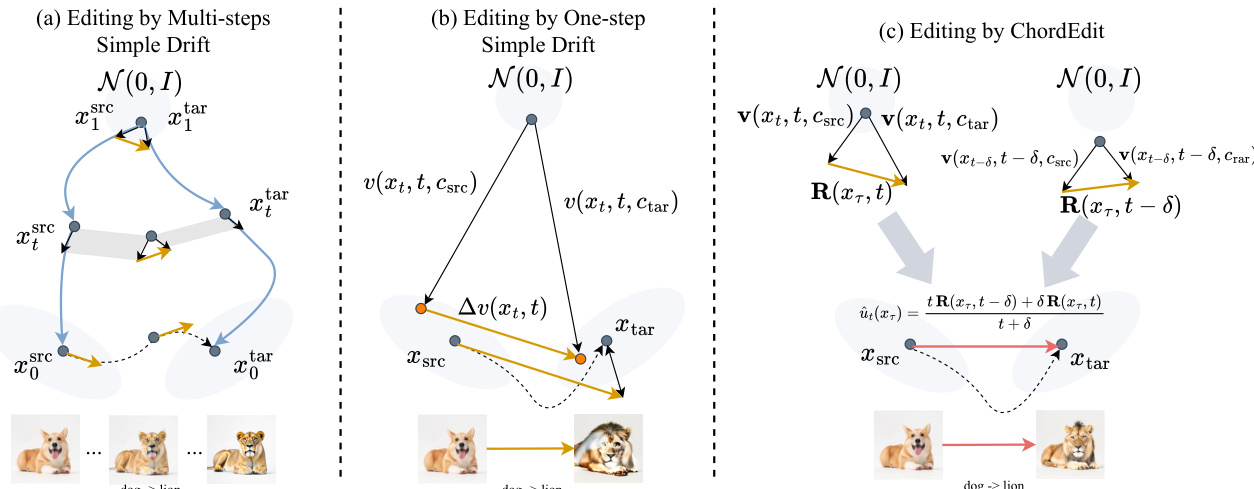
The figure contrasts three editing paradigms. Panel (a) illustrates conventional multi-step editing, where iterative application of the drift ensures a stable trajectory. Panel (b) demonstrates the failure of naive one-step simple drift, where the erratic underlying path leads to a poor final result. Panel (c) depicts the proposed ChordEdit method, which derives a stable, low-energy Chord Control Field to facilitate accurate, single-step transport.
To achieve this stability, ChordEdit treats the editing field as an estimation problem. Since the ideal field is unknown, the authors define an observable proxy field R(xτ,t) based on the model's output at noisy states. This observable acts as a noisy measurement of the true editing vector field ut. To resolve the instability of this naive proxy, the authors derive a locally smoothed estimator u^t by minimizing a convex quadratic surrogate that balances a recursive energy prior against agreement with new measurements.
By applying first-order causal approximations, the practical Chord Control Field is computed as a weighted average of the observable fields at time t and a previous time step t−δ:
u^t(xτ)=t+δtR(xτ,t−δ)+δR(xτ,t).This formulation effectively acts as a causal one-sided kernel smoothing of the naive field. Theoretically, this averaging provides critical numerical stability by acting as an L2-contraction, which suppresses high-energy spikes. Furthermore, it tightens the consistency proxy for explicit Euler integration, thereby reducing the local truncation error and ensuring the global error bound is minimized for a single step.
The complete ChordEdit algorithm operates as follows. First, the Chord Control Field u^ is computed using the observable residuals at times t and t−δ. The image is then transported in a single step using this smoothed field. Finally, an optional proximal refinement step can be applied. This refinement is a single forward pass using only the target prompt to amplify target semantics without requiring re-inversion, effectively separating structure-preserving transport from semantic enhancement.
Experiment
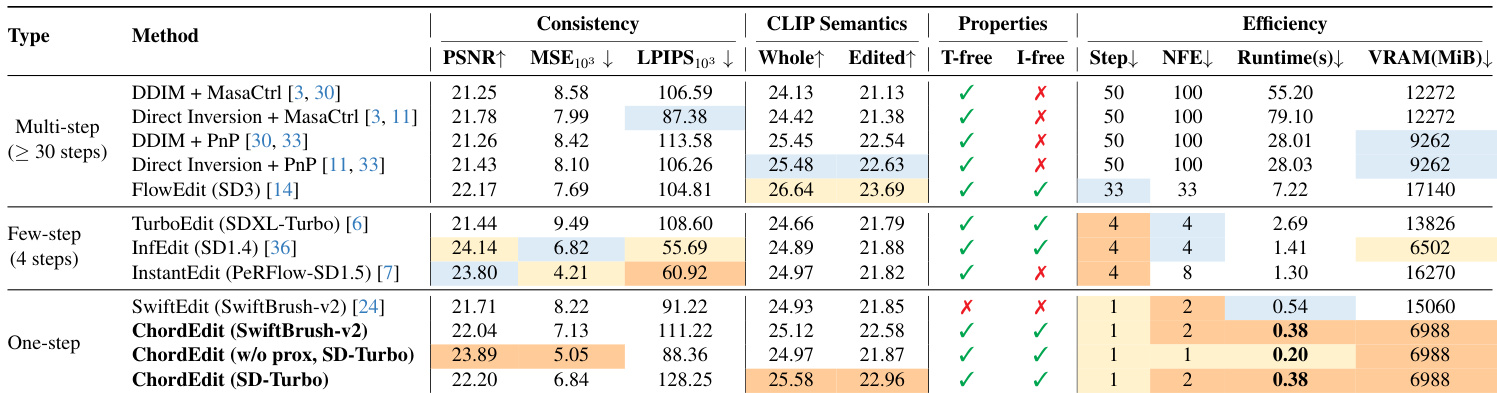
Evaluation on the PIE-bench dataset and various T2I models demonstrates that ChordEdit achieves leading efficiency and competitive quality via a training-free and inversion-free design. Ablation studies confirm that the proposed Chord Control Field stabilizes the editing process by reducing energy variance, which prevents the background artifacts and identity failures common in naive baselines. Finally, a user study reinforces these quantitative findings by showing that participants consistently prefer ChordEdit over existing methods for its superior balance of semantic alignment and background preservation.
The authors present ChordEdit, a one-step image editing framework that achieves state-of-the-art efficiency while maintaining competitive editing quality. The results indicate that the method significantly reduces runtime and VRAM usage compared to multi-step and few-step baselines, while offering both training-free and inversion-free properties. The data suggests a modular design where the base transport step ensures high consistency, and an optional refinement step boosts semantic alignment. ChordEdit operates in a single step, achieving drastically lower runtime and VRAM consumption than multi-step competitors. The method achieves superior background preservation scores compared to other one-step and few-step baselines. ChordEdit uniquely combines training-free and inversion-free properties with high semantic fidelity.
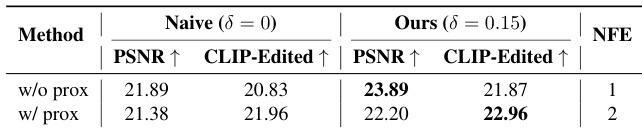
The the the table presents an ablation study comparing a naive baseline against the proposed method, specifically analyzing the impact of a proximal refinement step on performance. The results demonstrate that the proposed approach consistently outperforms the baseline in both background preservation and semantic alignment. Furthermore, the addition of the refinement step enhances semantic fidelity while maintaining a favorable balance with structural consistency. The proposed method achieves superior background preservation and semantic alignment compared to the naive baseline across all configurations. Incorporating the proximal refinement step significantly improves semantic alignment scores, demonstrating a trade-off with background consistency. The method without refinement operates with a single function evaluation, prioritizing high-fidelity transport over maximum semantic strength.
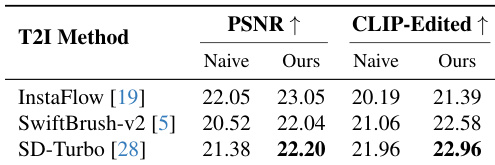
The the the table compares the proposed ChordEdit method against a naive baseline across three Text-to-Image models: InstaFlow, SwiftBrush-v2, and SD-Turbo. Results indicate that the proposed method consistently achieves higher scores in both background preservation and semantic alignment compared to the naive approach. This demonstrates the effectiveness of the Chord Control Field in stabilizing the editing process without requiring model-specific training. The proposed method consistently outperforms the naive baseline in both background preservation and semantic alignment across all tested models. Performance improvements are observed in both PSNR and CLIP-Edited scores for every model configuration listed. The results validate the method's robustness and model-agnostic applicability across different Text-to-Image architectures.
The authors evaluate ChordEdit against multi-step, few-step, and one-step image editing methods, demonstrating that their training-free approach achieves state-of-the-art efficiency and competitive editing quality. The results indicate that ChordEdit significantly reduces runtime and VRAM usage compared to complex multi-step baselines while maintaining superior background preservation and semantic alignment. ChordEdit achieves the fastest runtime and lowest step count among the compared methods, operating with significantly lower VRAM requirements. In the one-step category, the proposed method outperforms naive baselines by maintaining high structural fidelity and avoiding the artifacts associated with unstable single-step edits. The method demonstrates consistent performance across different model backbones, showing robust semantic alignment and preservation capabilities.
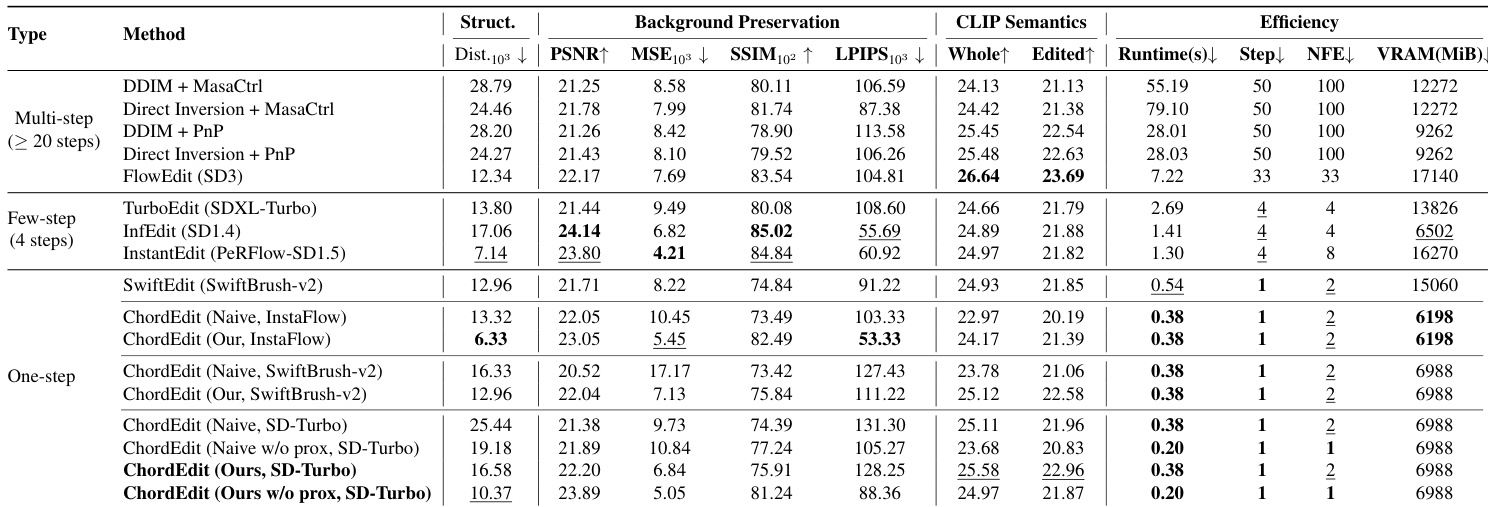
The evaluation compares ChordEdit against multi-step baselines and naive approaches across multiple Text-to-Image architectures to assess efficiency and editing quality. Results demonstrate that the proposed method achieves significant reductions in runtime and VRAM usage while maintaining superior background preservation and semantic alignment. An ablation study highlights that an optional refinement step further enhances semantic fidelity while balancing structural consistency, validating the framework as a robust, training-free solution for single-step image editing.