HyperAI
Command Palette
Search for a command to run...
Papers
最新のAIトレンドを把握するための、日々更新される最先端AI研究論文

Brain-IT:脳相互作用トランスフォーマーを用いたfMRIからの画像再構成

モダリティの衝突時:単モダリティ推論の不確実性がMLLMsにおける好ましさの動態を支配するメカニズム



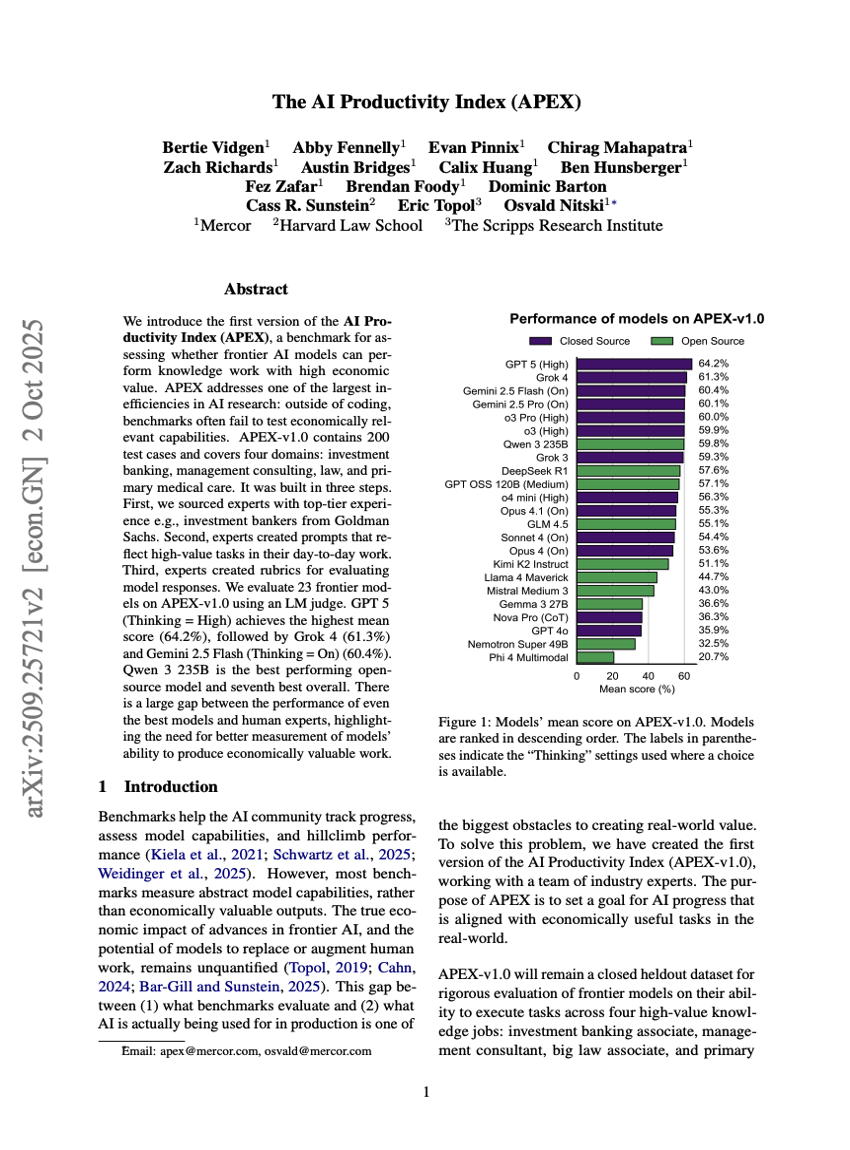

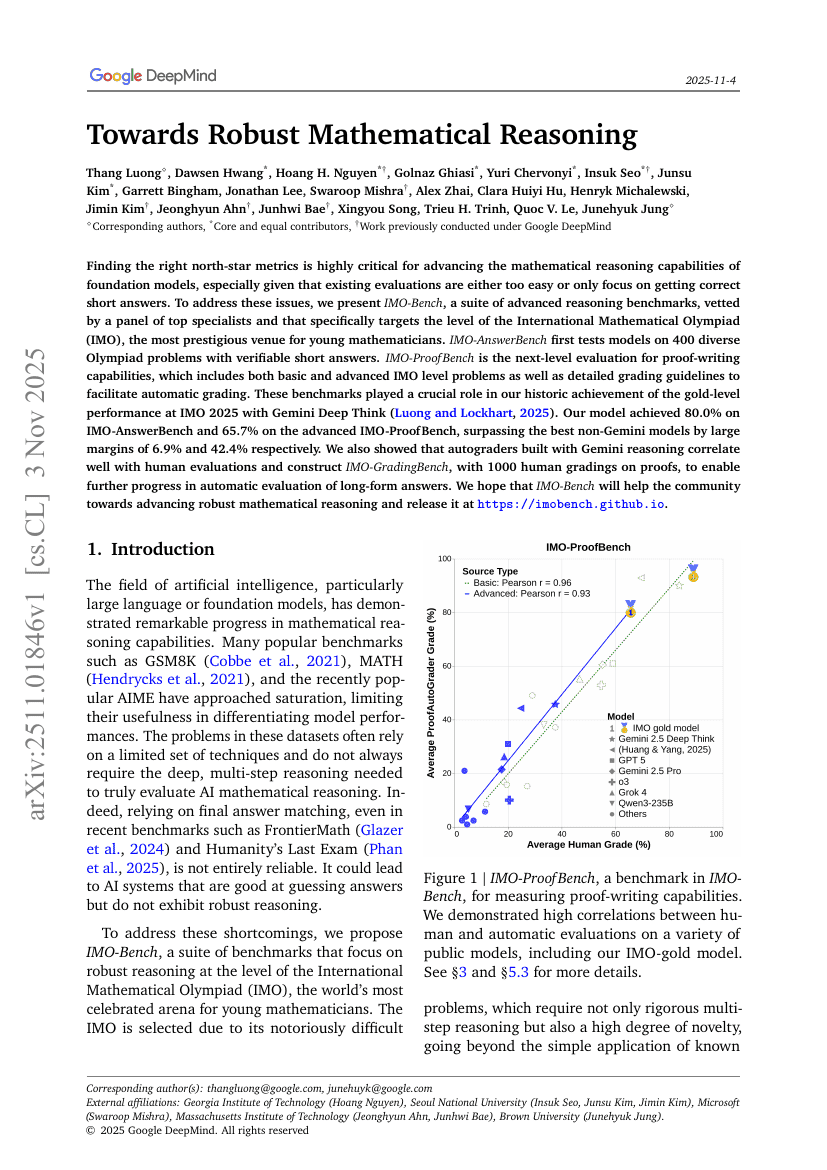

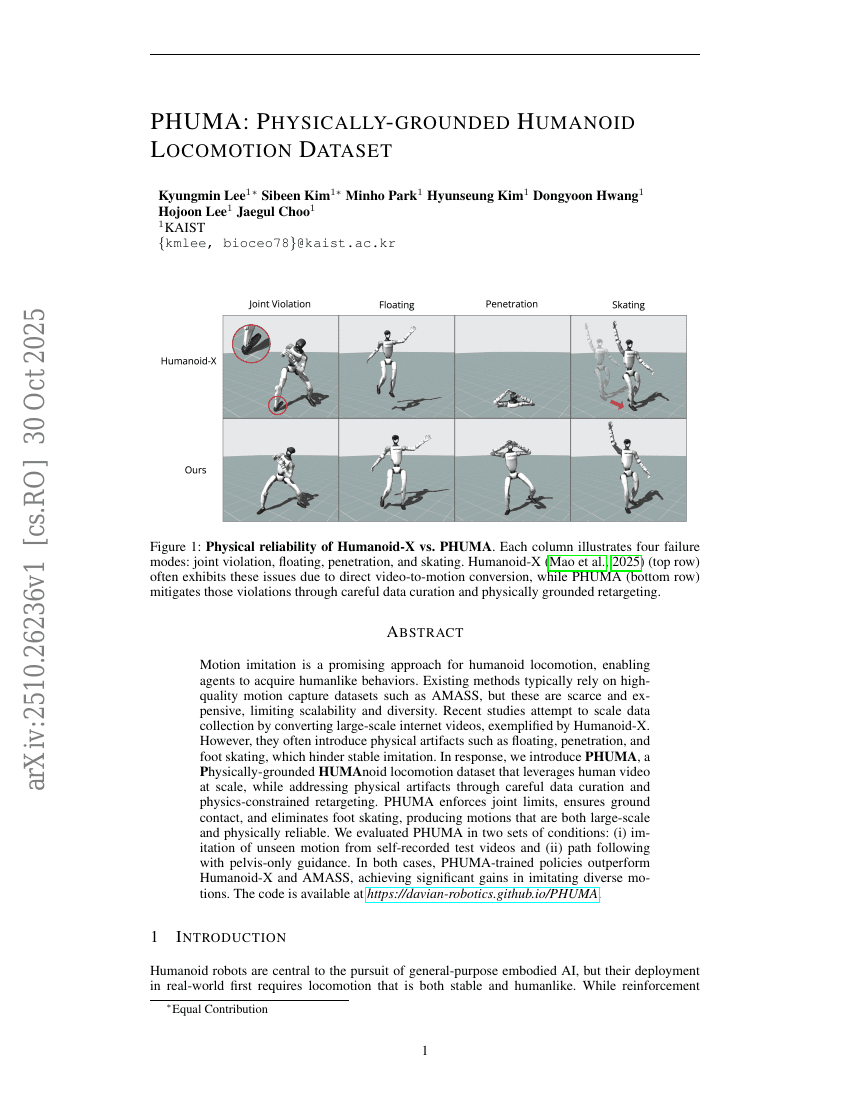
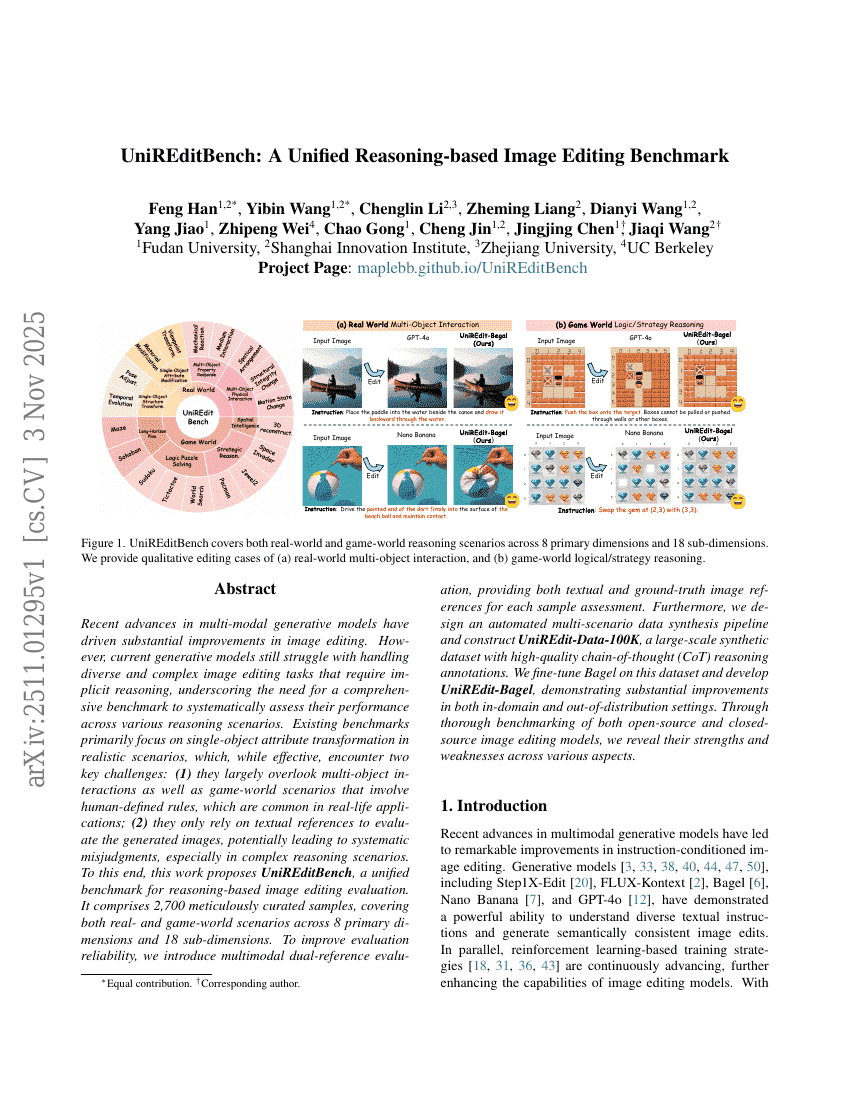



















Brain-IT:脳相互作用トランスフォーマーを用いたfMRIからの画像再構成
モダリティの衝突時:単モダリティ推論の不確実性がMLLMsにおける好ましさの動態を支配するメカニズム
VLAを盲目にしない:OOD一般化のための視覚表現の整合
視覚化が推論の第一歩であるとき:視覚的連鎖思考のためのベンチマークMIRA
VCode:記号的視覚表現としてのSVGを用いたマルチモーダルコーディングベンチマーク
AI生産性指数(APEX)
フレーム連鎖:フレーム認識型推論による多モーダルLLMにおける動画理解の進展
ロバストな数学的推論への道
将来の宇宙基盤型で高スケーラビリティを備えたAIインフラシステム設計へ
PHUMA:物理的基盤を有する人型歩行データセット
UniREditBench:統合的推論ベース画像編集ベンチマーク
テスト時計算最適スケーリングの一般化:最適化可能なグラフとして
UniLumos:物理的に妥当なフィードバックを用いた高速かつ統一的な画像・動画の再照明
視覚モデルがグラフ構造理解に持つ見過ごされている力
すべての活性化を強化:1兆規模のオープン言語基盤への汎用推論モデルのスケーリング
NOBLE - 生物学的洞察を埋め込んだ潜在埋め込みを有するニューラルオペレーターによる生物学的ニューロンモデルにおける実験変動の捉え方
グリア:人間の知性を模倣した自動システム設計・最適化向けAI
コンテキスト工学2.0:コンテキスト工学のコンテキスト
空間的SSRL:自己教師付き強化学習を活用した空間理解の向上
連続型自己回帰言語モデル
πextttRL:フローに基づく視覚言語行動モデルに対するオンラインRLファインチューニング
INTとFPの比較:微細な低ビット量子化フォーマットに関する包括的研究
ThinkMorph:マルチモーダル交差連鎖推論における出現的性質
OS-Sentinel:現実的なワークフローにおけるハイブリッド検証を活用した安全強化型モバイルGUIエージェントの実現
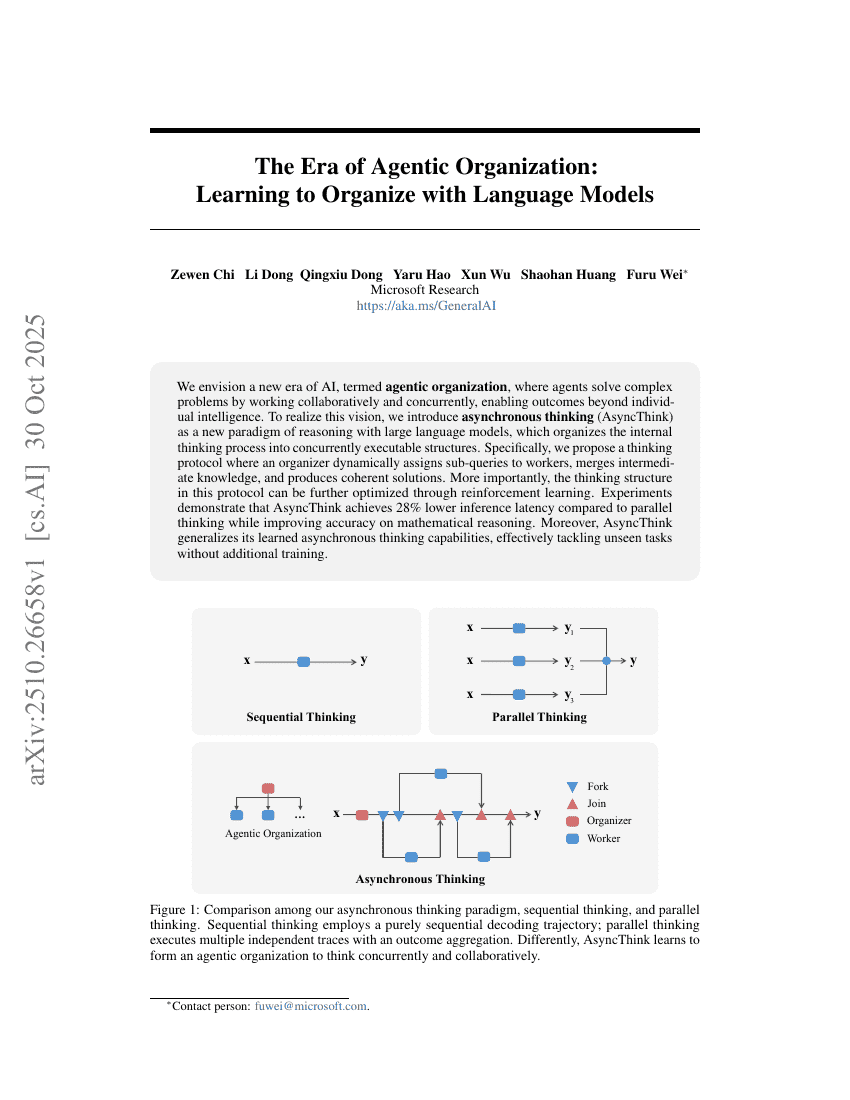
エージェント組織の時代:言語モデルによる組織化の学び
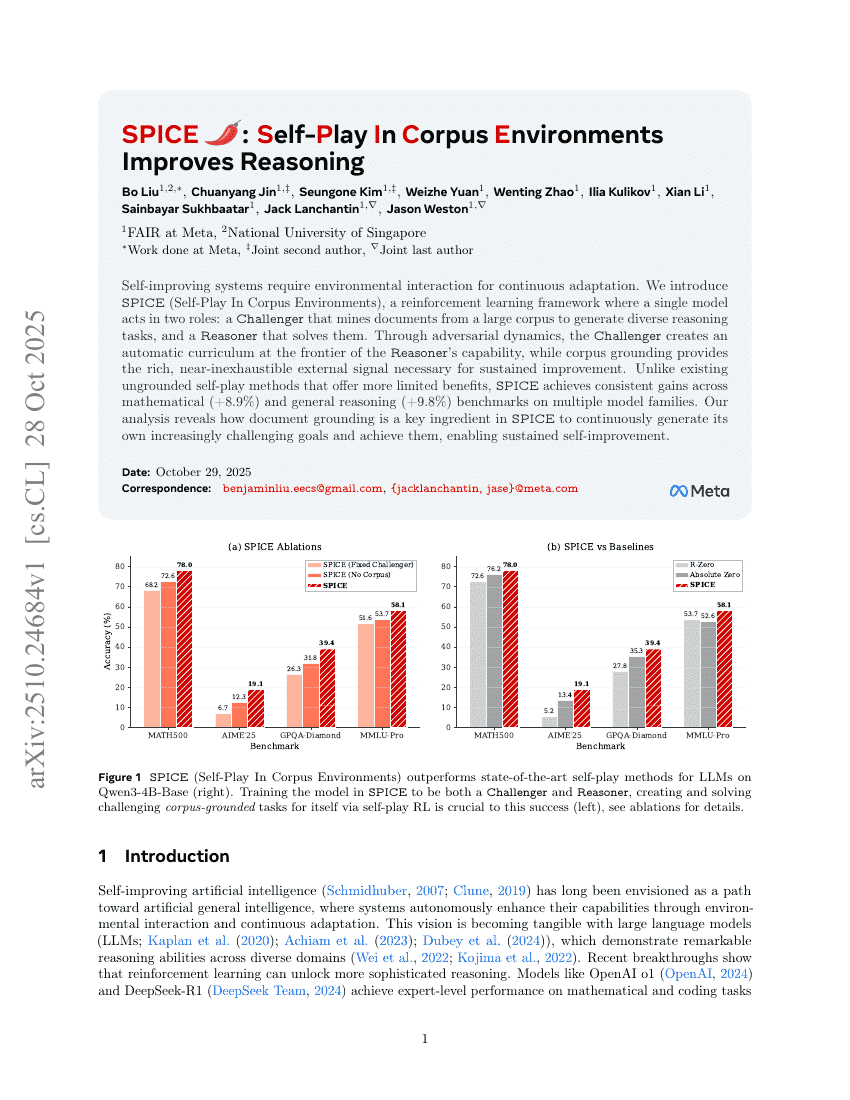
SPICE:コーパス環境下における自己対戦が推論能力を向上させる
Surfer 2:次世代のクロスプラットフォームコンピュータ利用エージェント
ロボット制御における拡散モデルの適用条件の探求
エージェントはウェブを制覇できるか? ChatGPT Atlasエージェントのウェブゲームにおけるフロンティアを探る
Kimi Linear:表現力と効率性を兼ね備えたアテンションアーキテクチャ
Emu3.5:ネイティブなマルチモーダルモデルは世界の学習者である
マニュアルデコードの終焉:本格的エンド・ツー・エンド言語モデルへ
VLAを盲目にしない:OOD一般化のための視覚表現の整合
視覚化が推論の第一歩であるとき:視覚的連鎖思考のためのベンチマークMIRA
VCode:記号的視覚表現としてのSVGを用いたマルチモーダルコーディングベンチマーク
AI生産性指数(APEX)
フレーム連鎖:フレーム認識型推論による多モーダルLLMにおける動画理解の進展
ロバストな数学的推論への道
将来の宇宙基盤型で高スケーラビリティを備えたAIインフラシステム設計へ
PHUMA:物理的基盤を有する人型歩行データセット
UniREditBench:統合的推論ベース画像編集ベンチマーク
テスト時計算最適スケーリングの一般化:最適化可能なグラフとして
UniLumos:物理的に妥当なフィードバックを用いた高速かつ統一的な画像・動画の再照明
視覚モデルがグラフ構造理解に持つ見過ごされている力
すべての活性化を強化:1兆規模のオープン言語基盤への汎用推論モデルのスケーリング
NOBLE - 生物学的洞察を埋め込んだ潜在埋め込みを有するニューラルオペレーターによる生物学的ニューロンモデルにおける実験変動の捉え方
グリア:人間の知性を模倣した自動システム設計・最適化向けAI
コンテキスト工学2.0:コンテキスト工学のコンテキスト
空間的SSRL:自己教師付き強化学習を活用した空間理解の向上
連続型自己回帰言語モデル
πextttRL:フローに基づく視覚言語行動モデルに対するオンラインRLファインチューニング
INTとFPの比較:微細な低ビット量子化フォーマットに関する包括的研究
ThinkMorph:マルチモーダル交差連鎖推論における出現的性質
OS-Sentinel:現実的なワークフローにおけるハイブリッド検証を活用した安全強化型モバイルGUIエージェントの実現
エージェント組織の時代:言語モデルによる組織化の学び
SPICE:コーパス環境下における自己対戦が推論能力を向上させる
Surfer 2:次世代のクロスプラットフォームコンピュータ利用エージェント
ロボット制御における拡散モデルの適用条件の探求
エージェントはウェブを制覇できるか? ChatGPT Atlasエージェントのウェブゲームにおけるフロンティアを探る
Kimi Linear:表現力と効率性を兼ね備えたアテンションアーキテクチャ
Emu3.5:ネイティブなマルチモーダルモデルは世界の学習者である
マニュアルデコードの終焉:本格的エンド・ツー・エンド言語モデルへ