Command Palette
Search for a command to run...
視覚的に考える、文章的に推論する:ARCにおける視覚言語連携
視覚的に考える、文章的に推論する:ARCにおける視覚言語連携
Beichen Zhang Yuhang Zang Xiaoyi Dong Yuhang Cao Haodong Duan Dahua Lin Jiaqi Wang
概要
最小限の例から抽象的推論を行う能力は、GPT-5やGrok 4などの先端的基礎モデルにとって依然として解決されていない核心的な課題である。これらのモデルは、わずかな例から構造的な変換規則を推論する能力に欠けており、これは人間の知能の主要な特徴の一つである。人工汎用知能(AGI)のための抽象化と推論コーパス(Abstraction and Reasoning Corpus for Artificial General Intelligence, ARC-AGI)は、この能力を厳密に検証するための信頼性の高いテストベッドを提供しており、概念的な規則の誘導および新規タスクへの転移を要求する。しかし、既存の大多数の手法はARC-AGIを単にテキストベースの推論問題として扱っており、人間がこうしたパズルを解く際に視覚的抽象化に大きく依存しているという事実を無視している。本研究の初期実験から明らかになったのは、ARC-AGIのグリッドを単純に画像に変換すると、規則の正確な実行が不正確になるため、性能が低下するという逆説的な現象である。この結果、我々は中心的な仮説を提示する:視覚と言語は、異なる推論段階において補完的な強みを有する。すなわち、視覚は全体的なパターンの抽象化と検証に優れ、言語は記号的な規則の定式化と精密な実行に長けている。この知見に基づき、以下の2つの協調的戦略を提案する:(1)視覚-言語協調推論(Vision-Language Synergy Reasoning, VLSR):ARC-AGIの問題をモダリティに整合した部分タスクに分解するアプローチ;(2)モダリティ切替自己補正(Modality-Switch Self-Correction, MSSC):言語ベースの推論の誤りを、視覚による検証によって内発的に補正する仕組み。広範な実験により、本手法が、多様な主要モデルおよび複数のARC-AGIタスクにおいて、テキストのみのベースラインと比較して最大4.33%の性能向上を達成することが示された。本研究の結果は、将来の基礎モデルが汎用的で人間のような知能を実現するためには、視覚的抽象化と言語的推論を統合することが不可欠であることを示唆している。ソースコードは近日中に公開予定である。
Summarization
Researchers from The Chinese University of Hong Kong and Shanghai AI Laboratory introduce Vision-Language Synergy Reasoning (VLSR) and Modality-Switch Self-Correction (MSSC) to address the ARC-AGI benchmark, effectively combining visual global abstraction with linguistic symbolic execution to outperform text-only baselines in abstract reasoning tasks.
Introduction
The Abstraction and Reasoning Corpus (ARC-AGI) serves as a critical benchmark for Artificial General Intelligence, assessing a model's ability to "learn how to learn" by identifying abstract rules from minimal examples rather than relying on memorized domain knowledge. While humans naturally rely on visual intuition to solve these 2D grid puzzles, existing state-of-the-art approaches process these tasks purely as text-based nested lists. This text-centric paradigm overlooks vital spatial relationships such as symmetry and rotation, yet naive image-based methods also fail due to a lack of pixel-perfect precision. Consequently, models struggle to balance the global perception needed to understand the rule with the discrete accuracy required to execute it.
The authors propose a novel methodology that integrates visual and textual modalities based on their respective strengths. They decompose abstract reasoning into two distinct stages, utilizing visual inputs to summarize transformation rules and textual representations to apply those rules with element-wise exactness.
Key innovations and advantages include:
- Vision-Language Synergy Reasoning (VLSR): A framework that dynamically switches modalities, employing visual grids to extract global patterns and textual coordinates to execute precise manipulations.
- Modality-Switch Self-Correction (MSSC): A verification mechanism that converts text-generated solutions back into images, allowing the model to visually detect inconsistencies that are invisible in text format.
- Versatile Performance Gains: The approach functions as both an inference strategy and a training paradigm, delivering significant accuracy improvements across flagship models like GPT-4o and Gemini without requiring external ground truth.
Dataset
Based on the provided text, the authors employ a specific processing strategy to visualize data as follows:
- Matrix-to-Image Conversion: The authors convert input-output matrices into color-coded 2D grids to preserve 2D spatial information and offer a global view of the data.
- Color Mapping: Each numerical value is mapped to a specific color to create distinct visual elements:
- 0: Black
- 1: Blue
- 2: Red
- 3: Green
- 4: Yellow
- 5: Grey
- 6: Pink
- 7: Orange
- 8: Light blue
- 9: Brown
- Structural Formatting: White dividing lines are inserted between the colored elements (small squares) to clearly indicate specific numbers and define the structure within each block.
Method
The authors leverage a two-phase framework that strategically combines visual and textual modalities to address the challenges of reasoning over structured grid-based tasks in the ARC-AGI benchmark. This approach, termed Vision-Language Synergy Reasoning (VLSR), decomposes the task into two distinct subtasks: rule summarization and rule application, each optimized for the strengths of a specific modality. The overall framework is designed to overcome the limitations of purely textual approaches, which often fail to capture the inherent 2D structural information of the input matrices.
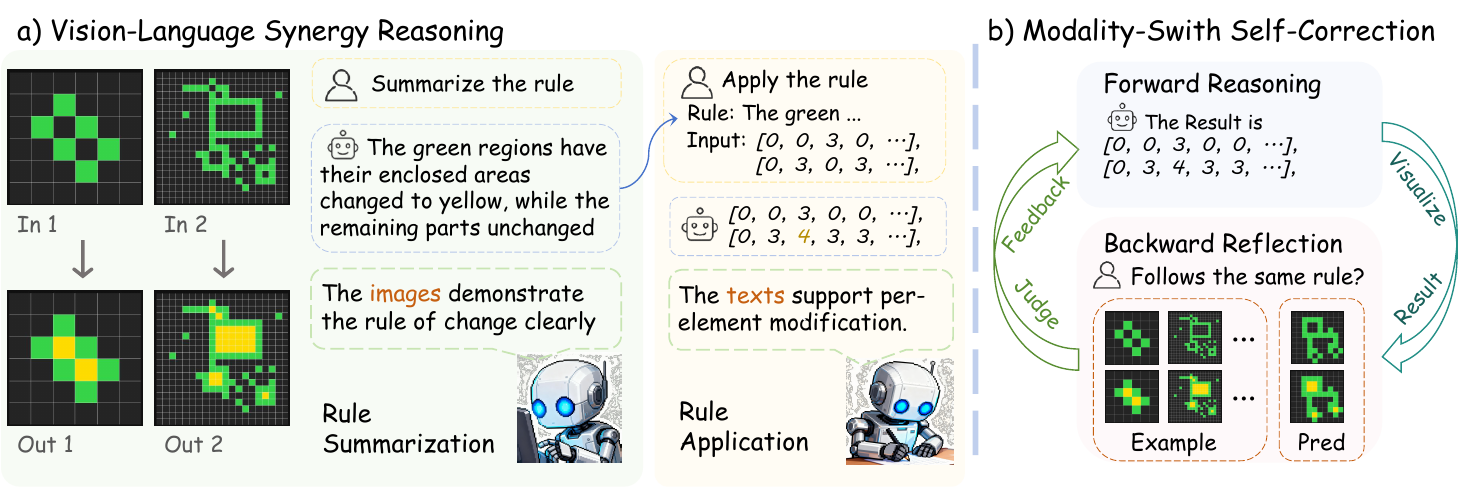 As shown in the figure below, the first phase, Vision-Language Synergy Reasoning, begins by converting all provided input-output example pairs into their visual representations. Each matrix m is transformed into an image i=V(m), where each cell value is mapped to a distinct color, creating a grid layout that preserves the spatial relationships between elements. This visual representation is then fed to a large vision-language model (LVLM) to perform rule summarization. The model analyzes the visual patterns across the examples to derive an explicit transformation rule, rpred, expressed in natural language. This phase leverages the model's ability to perform global pattern recognition and understand 2D structural relationships, which is crucial for identifying complex spatial transformations.
As shown in the figure below, the first phase, Vision-Language Synergy Reasoning, begins by converting all provided input-output example pairs into their visual representations. Each matrix m is transformed into an image i=V(m), where each cell value is mapped to a distinct color, creating a grid layout that preserves the spatial relationships between elements. This visual representation is then fed to a large vision-language model (LVLM) to perform rule summarization. The model analyzes the visual patterns across the examples to derive an explicit transformation rule, rpred, expressed in natural language. This phase leverages the model's ability to perform global pattern recognition and understand 2D structural relationships, which is crucial for identifying complex spatial transformations.
 The second phase, rule application, shifts to the textual modality. The derived rule rpred is used to guide the transformation of the test input. All matrices, including the test input and the examples, are converted into their textual representations t=T(m), which are nested lists of integers. The same LVLM, now operating in text mode with a rule application prompt, performs element-wise reasoning to generate the predicted output matrix tpred. This phase exploits the precision of textual representation for manipulating individual elements according to the summarized rule. The authors emphasize that the same base model is used for both phases, with the only difference being the input modality and the specific prompting strategy, ensuring a consistent reasoning process.
The second phase, rule application, shifts to the textual modality. The derived rule rpred is used to guide the transformation of the test input. All matrices, including the test input and the examples, are converted into their textual representations t=T(m), which are nested lists of integers. The same LVLM, now operating in text mode with a rule application prompt, performs element-wise reasoning to generate the predicted output matrix tpred. This phase exploits the precision of textual representation for manipulating individual elements according to the summarized rule. The authors emphasize that the same base model is used for both phases, with the only difference being the input modality and the specific prompting strategy, ensuring a consistent reasoning process.
To further enhance the reliability of the output, the authors introduce a Modality-Switch Self-Correction (MSSC) mechanism. This strategy addresses the challenge of intrinsic self-correction by using different modalities for reasoning and verification. After the initial textual rule application produces a candidate output tpred, the model first converts this textual output back into a visual representation ipred. This visualized output is then presented to the LVLM, which acts as a critic to assess the consistency of the predicted transformation with the provided examples. The model evaluates whether the test input-output pair (itestinput,ipred) follows the same pattern as the training examples. If the model determines the output is inconsistent, it receives feedback and performs an iterative refinement step, using the previous attempt's information to generate a new candidate output. This process repeats until the output is deemed consistent or a maximum number of iterations is reached. This modality switch provides a fresh perspective, breaking the model's confirmation bias and enabling it to identify errors that are imperceptible when using the same modality for both reasoning and verification.
Experiment
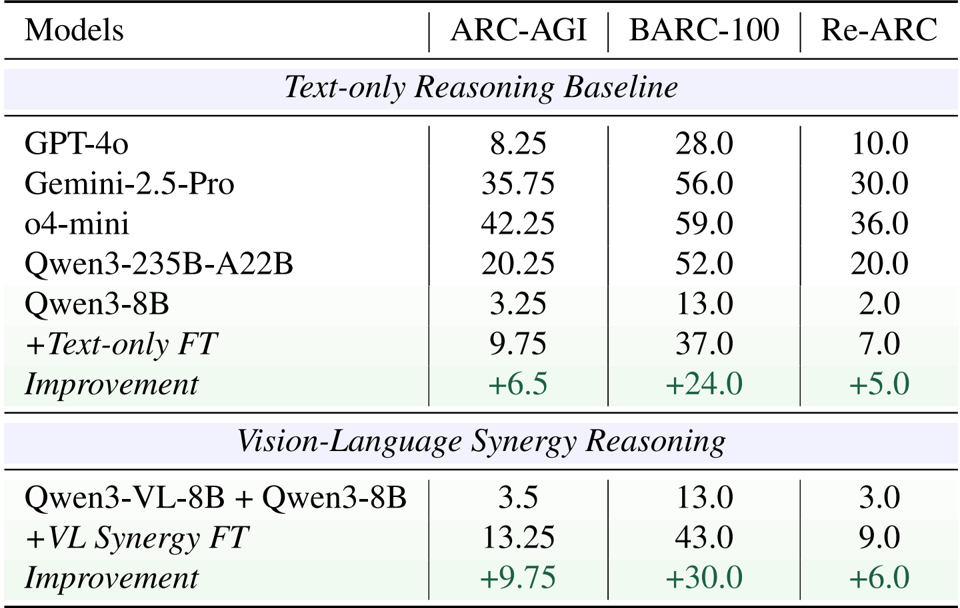
- Modality isolation experiments validated that visual representations excel at rule summarization (yielding a 3.2% average improvement), while textual representations are superior for rule application, where visual methods caused a 15.0% performance drop.
- The proposed VLSR and MSSC strategies consistently improved performance across ARC-AGI, Re-ARC, and BARC benchmarks, boosting baseline results by up to 6.25% for GPT-4o and 7.25% for Gemini-2.5-Pro on ARC-AGI.
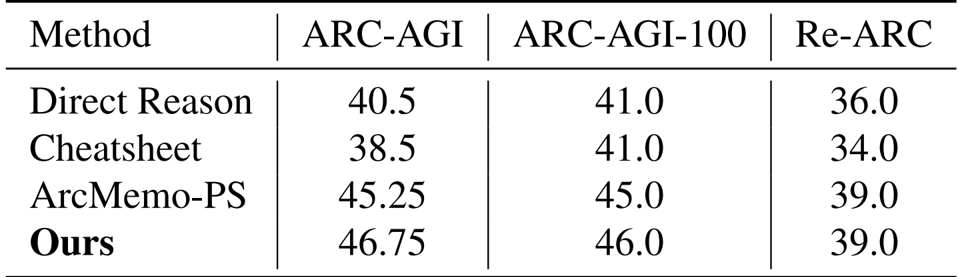
- In comparative evaluations using o4-mini, the method achieved the highest accuracy across all test sets, surpassing the strongest training-free baseline (ArcMemo-PS) by 1.5% on ARC-AGI.
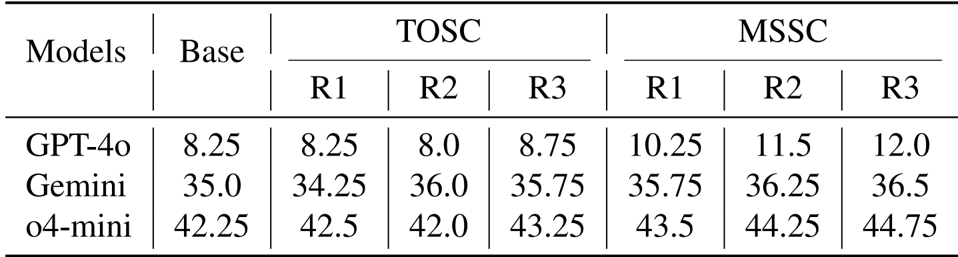
- Analysis of self-correction mechanisms showed that Modality-Switch Self-Correction (MSSC) achieved consistent monotonic gains (e.g., improving GPT-4o scores from 8.25 to 12.0), whereas text-only self-correction provided minimal or negative value.
- Fine-tuning experiments on ARC-Heavy-200k demonstrated that vision-language synergy achieved 13.25% accuracy on ARC-AGI, significantly outperforming text-centric fine-tuning (9.75%) and the closed-source GPT-4o baseline (8.25%).
Results show that using visual modality for rule summarization improves performance across all models, with GPT-4o increasing from 8.25 to 13.5, Gemini-2.5 from 35.0 to 38.75, and o4-mini from 42.25 to 45.5. However, applying rules using visual representations in the rule application phase leads to significant performance drops, with GPT-4o decreasing from 13.5 to 6.25, Gemini-2.5 from 38.75 to 23.75, and o4-mini from 45.5 to 25.0.
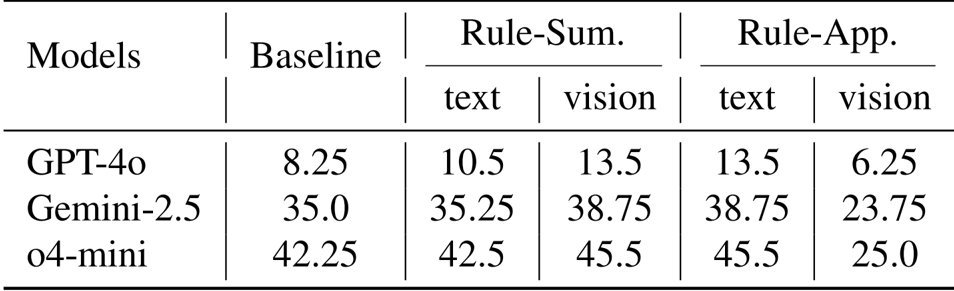
The authors use a modality-switching approach to improve abstract reasoning, where visual representations are used for rule summarization and textual representations for rule application. Results show that combining both methods consistently improves performance across all models and benchmarks, with the best results achieved when both VLSR and MSSC are applied.
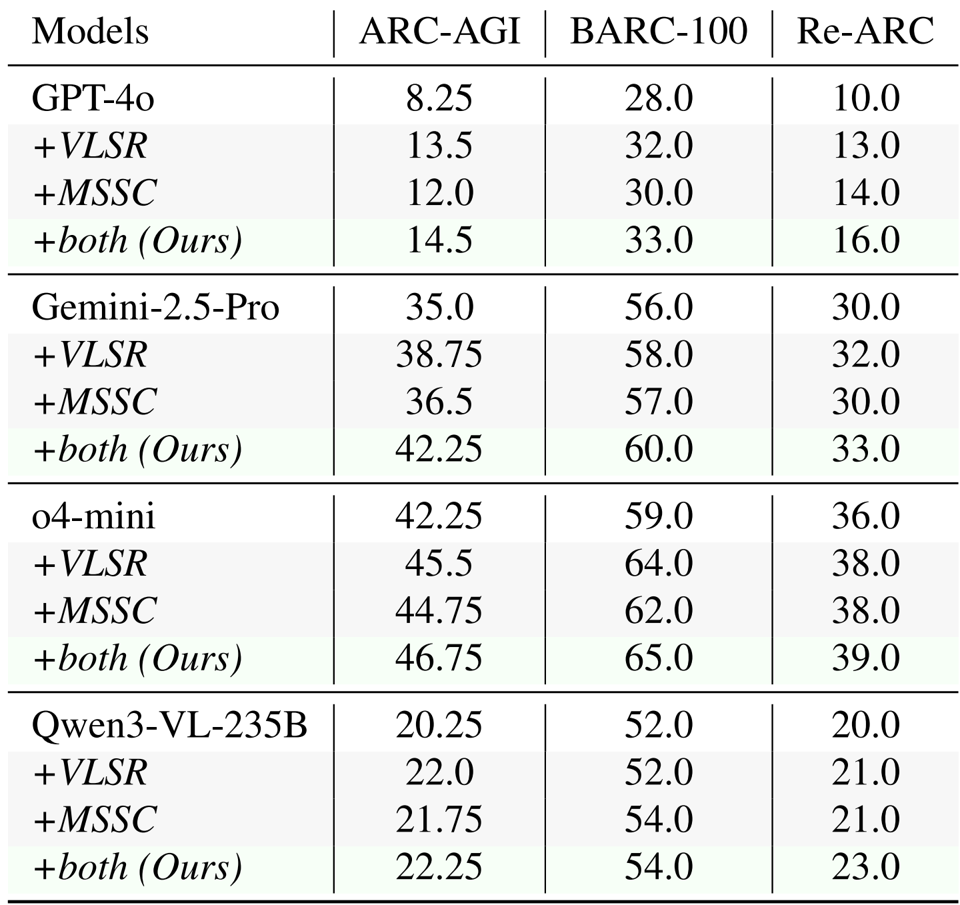
Results show that the proposed method achieves higher accuracy than baseline approaches across all benchmarks, with an improvement of 1.5% over the strongest baseline ArcMemo-PS on ARC-AGI. This demonstrates that visual information provides complementary benefits that text-based memory retrieval alone cannot capture.
Results show that Modality-Switch Self-Correction (MSSC) consistently improves performance over text-only self-correction (TOSC) across all models and iterations, with GPT-4o achieving a 3.75-point increase from Round 1 to Round 3, while TOSC shows minimal gains and even degrades in some rounds. The improvement is attributed to visual verification providing a fresh perspective that helps detect spatial inconsistencies missed during text-only reasoning.
The authors use a vision-language synergy approach to improve abstract reasoning, where visual representations are used for rule summarization and text for rule application. Results show that combining these modalities significantly boosts performance, with the vision-language synergy method achieving an average improvement of 9.75% on ARC-AGI compared to text-only fine-tuning.