Command Palette
Search for a command to run...
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
HyTRec:長期間行動順序推薦のためのハイブリッド時系列認識アテンションアーキテクチャ
Lei Xin Yuhao Zheng Ke Cheng Changjiang Jiang Zifan Zhang Fanhu Zeng
概要
ユーザー行動の長期間シーケンスをモデリングすることは、生成型レコメンデーション分野における重要な研究課題として浮上している。しかし、従来の手法は二律背反に直面している:線形アテンション機構は状態容量の制限により検索精度が低下する一方、ソフトマックスアテンションは計算コストが極めて高くなるという問題を抱えている。本研究では、この課題に対応するため、長期的な安定した嗜好と短期的な意図の急上昇を明示的に分離するハイブリッドアテンション構造を有するHyTRecを提案する。本モデルでは、膨大な歴史的行動シーケンスを線形アテンションブランチに割り当て、最近のインタラクションには専用のソフトマックスアテンションブランチを確保することで、1万件を超えるインタラクションを含む産業規模の文脈においても、高精度な検索能力を回復する。さらに、線形層による急速な興味の変化を捕捉する遅れを補うために、時系列に敏感なデルタネットワーク(Temporal-Aware Delta Network; TADN)を設計し、最新の行動信号を動的に重み付けしながら、過去のノイズを効果的に抑制する。産業規模のデータセットを用いた実証実験の結果、本モデルは線形推論速度を維持しつつ、強力なベースラインを上回ることを確認した。特に、超長期間の行動履歴を持つユーザーに対して、Hit Rateが8%以上向上するという顕著な性能向上が達成され、高い効率性を兼ね備えていることが示された。
One-sentence Summary
Researchers from Dewu, Wuhan University, USTC, and Beihang propose HyTRec, a hybrid attention model that decouples long-term preferences from short-term intent using linear and softmax branches, enhanced by TADN for dynamic signal weighting, achieving 8%+ Hit Rate gains on ultra-long sequences with linear inference speed.
Key Contributions
- HyTRec introduces a Hybrid Attention architecture that assigns long-term historical sequences to linear attention and recent interactions to softmax attention, resolving the efficiency-precision trade-off while handling sequences of up to ten thousand interactions.
- The Temporal-Aware Delta Network (TADN) dynamically amplifies fresh behavioral signals using an exponential gating mechanism, reducing lag in capturing rapid interest drifts and suppressing noise from outdated interactions.
- Evaluated on industrial-scale e-commerce datasets, HyTRec achieves over 8% higher Hit Rate for users with ultra-long sequences while preserving linear inference speed, outperforming strong baselines in both efficiency and accuracy.
Introduction
The authors leverage the growing need to model ultra-long user behavior sequences in generative recommendation systems, where capturing both long-term preferences and short-term intent shifts is critical for accurate next-item prediction. Prior approaches face a trade-off: linear attention models scale efficiently but lose retrieval precision, while softmax attention preserves fidelity at prohibitive computational cost, and neither handles rapid interest drift well. HyTRec addresses this by introducing a hybrid attention architecture that routes long-term history through linear attention and recent interactions through softmax attention, preserving linear complexity while restoring precision. They further propose the Temporal-Aware Delta Network to dynamically emphasize fresh signals and suppress stale noise, improving responsiveness to intent changes. Empirically, HyTRec outperforms baselines by over 8% in Hit Rate for users with long sequences, without sacrificing inference speed.
Dataset

- The authors use publicly available datasets with no sensitive information, focusing solely on research with no commercial intent.
- Data is merged across partitions by user ID to reconstruct full behavior histories from registration, enabling richer long-sequence modeling.
- User behavior sequences are structured using ad attribution IDs as numerical identifiers, tracking states across funnel stages (click, redirect, activation, wake-up, product click, stay, collection, add-to-cart, payment).
- Behaviors are sorted by correlation strength with payment to build hierarchical long-cycle sequences, prioritizing signals most predictive of conversion.
- The dataset excludes or handles problematic cases: cold-start users (sparse/no interactions), inactive long-term users (old/limited records), and scalper accounts (high interaction volume but low business value) to avoid misleading model training.
- These filtering and structuring strategies ensure the training data supports efficient, accurate modeling of long user sequences without being skewed by edge cases.
Method
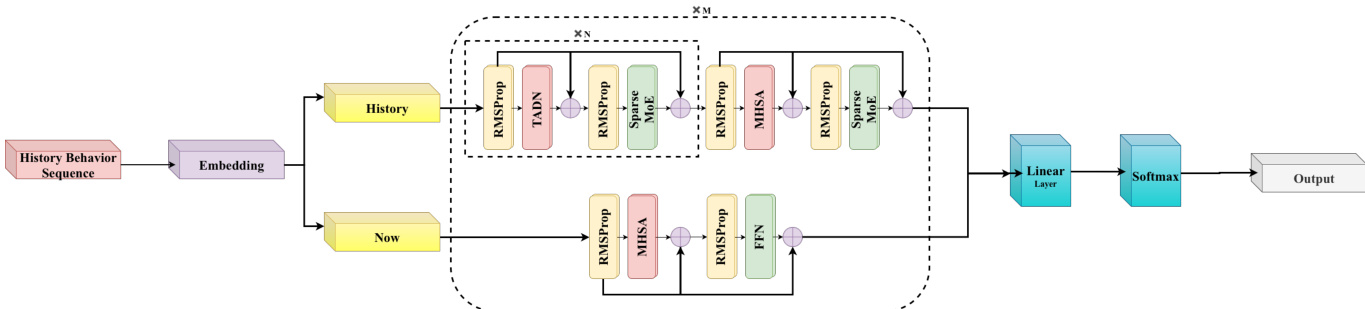
The authors leverage a dual-branch architecture to model long user behavior sequences, explicitly decoupling short-term intent spikes from long-term stable preferences. This stratification begins with sequence decomposition: the full historical sequence Su is split into a short-term subsequence Sushort of fixed length K, capturing recent behaviors, and a long-term subsequence Sulong of length n−K, encoding stable consumption patterns. Each subsequence is processed independently through dedicated branches before fusion.
The short-term branch employs standard multi-head self-attention (MHSA) to preserve fine-grained temporal dynamics and ensure high precision for recent interactions. In contrast, the long-term branch is built upon a novel hybrid attention architecture designed to break the O(n2) complexity bottleneck while retaining global context awareness. This branch consists of N encoder layers, predominantly using the proposed Temporal-Aware Delta Network (TADN) for linear complexity, with sparse interleaving of standard softmax attention layers (e.g., at a 7:1 ratio) to maintain retrieval fidelity.
Refer to the framework diagram for a visual representation of this dual-path processing and fusion mechanism.
At the core of the long-term branch is TADN, which introduces a Temporal-Aware Gating Mechanism to dynamically weight historical behaviors based on their temporal proximity to the target action. The temporal decay factor τt quantifies relevance:
τt=exp(−Ttcurrent−tbehaviort),where T is the decay period. This factor is fused with feature similarity to generate dynamic gating weights gt:
gt=α⋅[σ(Wg⋅Concat(ht,Δht)+b)⊙τt]+(1−α)⋅gstatic,where Δht=ht−hˉ represents short-term deviations, and gstatic encodes long-term preferences. The fused representation h~t is then computed as:
h~t=qt⊙Δht+(1−qt)⊙ht.This gating mechanism is integrated into a linear attention recurrence via the state update rule:
St=St−1(I−gtβtktkt⊤)+βtvtkt⊤,which expands into a linear attention formulation with a temporal-aware decay mask D(t,i):
ot=i=1∑tβi(viki⊤)qt⋅D(t,i),where D(t,i)=∏j=i+1t(I−gjβjkjkj⊤). The inclusion of τj in gj ensures that recent interactions are prioritized while long-term patterns are preserved.
The outputs of both branches are fused and passed through a linear layer and softmax to generate the final recommendation prediction. This hybrid design enables efficient processing of long sequences without sacrificing the semantic richness required for accurate intent modeling.
Experiment
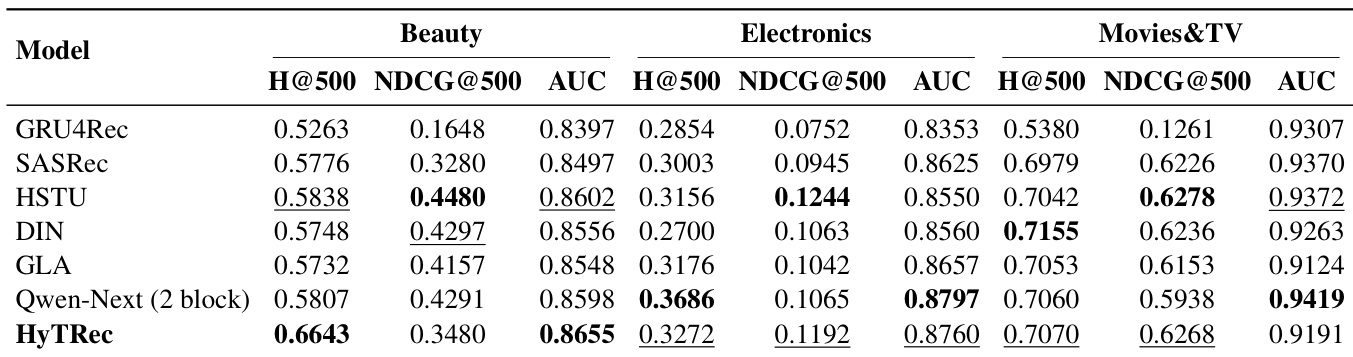
- HyTRec outperforms state-of-the-art baselines in modeling long user behavior sequences, achieving top or near-top performance across multiple datasets, particularly excelling in capturing user interests and adapting to sparse or scattered behavioral patterns.
- The model scales efficiently to ultra-long sequences due to its linear attention mechanism, maintaining high throughput even at sequence lengths up to 12k, while transformer-based models suffer sharp efficiency drops beyond 1k.
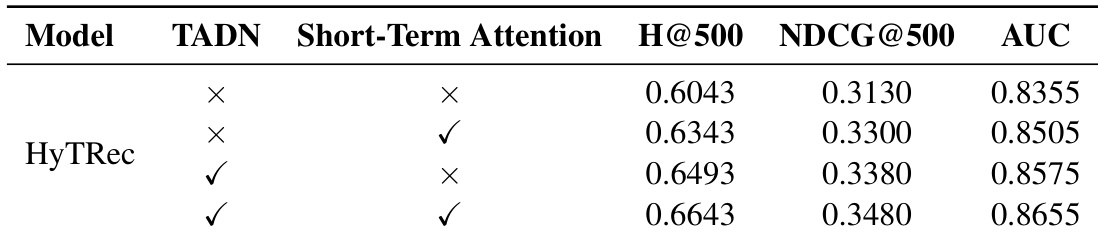
- Ablation studies confirm that both the TADN branch (for long-term dependencies) and the short-term attention branch (for immediate interest drift) are essential, with their combination yielding the best overall performance through complementary modeling.
- A 3:1 hybrid attention ratio between linear and short-term attention provides the optimal balance between recommendation accuracy and inference efficiency, outperforming other ratios in both performance and latency trade-offs.
- HyTRec demonstrates robustness in cold-start and sparse interaction scenarios by leveraging similar user behavior patterns, showing strong generalization and adaptability to challenging user cases.
- Additional parameter studies indicate that 2 attention heads and 4 experts deliver optimal performance-efficiency trade-offs, aligning with user group heterogeneity and computational constraints.
- The model also shows strong cross-domain transfer capability, suggesting structural advantages in handling domain shifts and motivating future work on broader generalization and noise resilience.
The authors use HyTRec to address long user behavior modeling by combining linear and short-term attention mechanisms, achieving competitive or superior performance across multiple datasets compared to transformer and linear attention baselines. Results show that HyTRec maintains high efficiency at ultra-long sequence lengths while delivering strong recommendation accuracy, particularly in capturing both long-term patterns and short-term interest drift. Ablation and ratio studies confirm that the hybrid architecture’s dual-branch design and 3:1 attention ratio offer the best balance between performance and computational cost.
The authors use ablation experiments to isolate the contributions of HyTRec’s two key components: the TADN branch for long-term sequence modeling and the short-term attention branch for capturing immediate interest drift. Results show that each component independently improves performance over the baseline, but their combination yields the highest scores across all metrics, confirming their complementary roles. This design enables the model to effectively balance long-range dependency modeling with responsiveness to recent user behavior.
The authors evaluate the impact of varying the number of experts in their recommendation model and find that performance peaks at 4 experts, with both recommendation accuracy and inference efficiency declining as the number increases to 6 or 8. Results show that higher expert counts introduce unnecessary computational overhead without meaningful gains in key metrics like H@500, NDCG@500, or AUC. This supports the design choice of aligning expert count with user group heterogeneity for optimal balance between effectiveness and efficiency.
The authors evaluate how different hybrid attention ratios affect recommendation accuracy and inference latency, finding that a 3:1 ratio delivers the best balance between performance gains and computational cost. While higher ratios like 6:1 achieve marginally better metrics, they incur significantly increased latency, making them less practical. Results confirm that moderate hybrid configurations optimize both effectiveness and efficiency in long-sequence modeling.
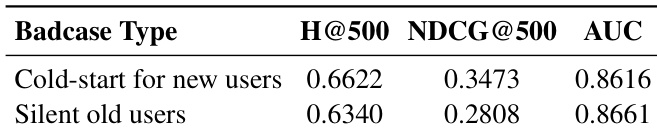
The authors evaluate HyTRec on challenging user scenarios including cold-start new users and silent old users, showing that the model maintains strong retrieval and ranking performance across both cases. Results indicate consistent AUC scores above 0.86 and competitive H@500 values, demonstrating the model’s robustness in handling sparse interaction data through effective user similarity augmentation and generalization.