HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

delta-mem: Efficient Online Memory for Large Language Models

MCP-Cosmos: World Model-Augmented Agents for Complex Task Execution in MCP Environments

























delta-mem: Efficient Online Memory for Large Language Models
MCP-Cosmos: World Model-Augmented Agents for Complex Task Execution in MCP Environments
Beyond Reasoning: Reinforcement Learning Unlocks Parametric Knowledge in LLMs
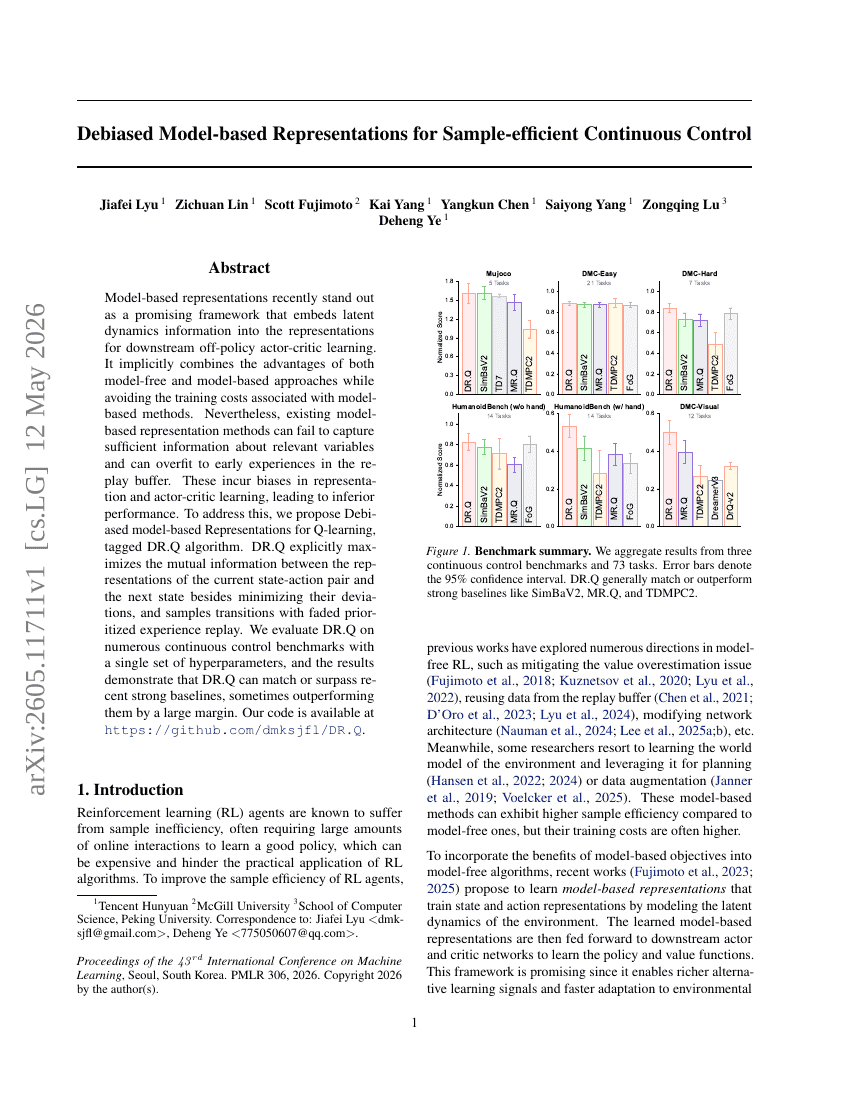
Debiased Model-based Representations for Sample-efficient Continuous Control
Multi-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs
Your Language Model is Its Own Critic: Reinforcement Learning with Value Estimation from Actor's Internal States
Relit-LiVE: Relight Video by Jointly Learning Environment Video
Positive Alignment: Artificial Intelligence for Human Flourishing
LLaVA-UHD v4: What Makes Efficient Visual Encoding in MLLMs?
Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why
A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
ELF: Embedded Language Flows
PaperFit: Vision-in-the-Loop Typesetting Optimization for Scientific Documents
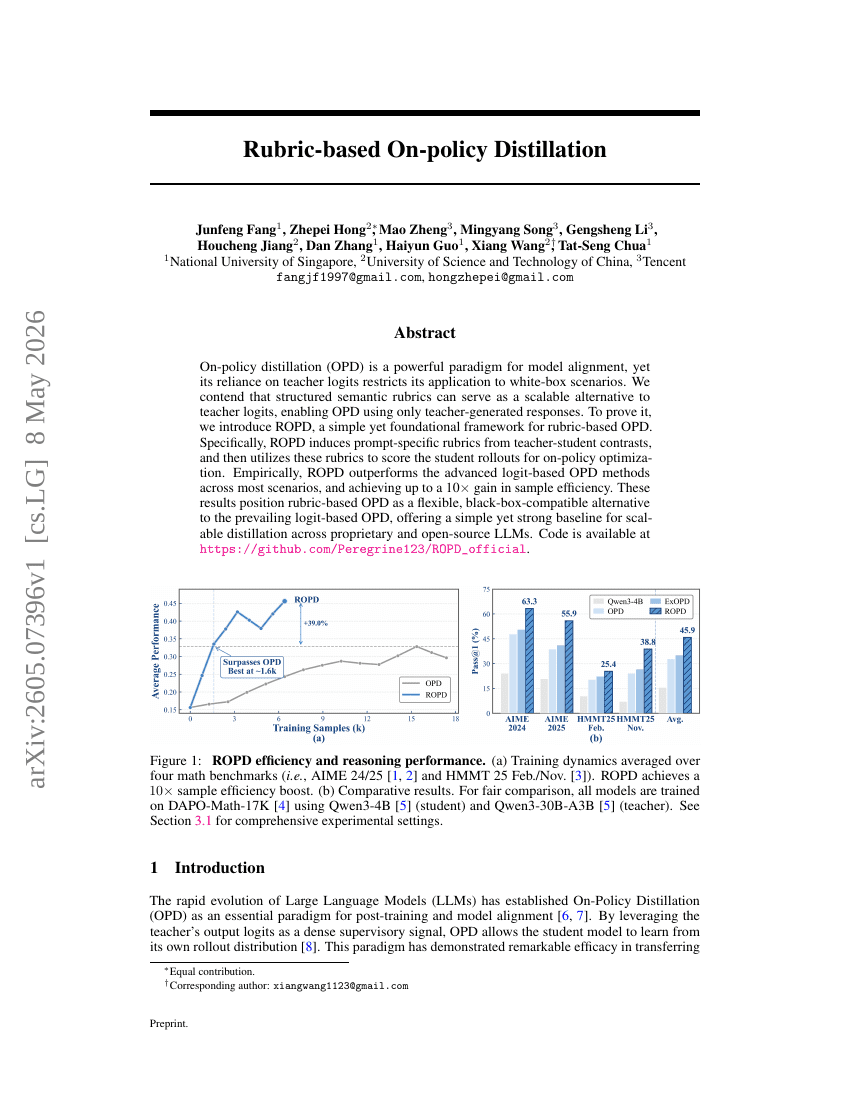
Rubric-based On-policy Distillation
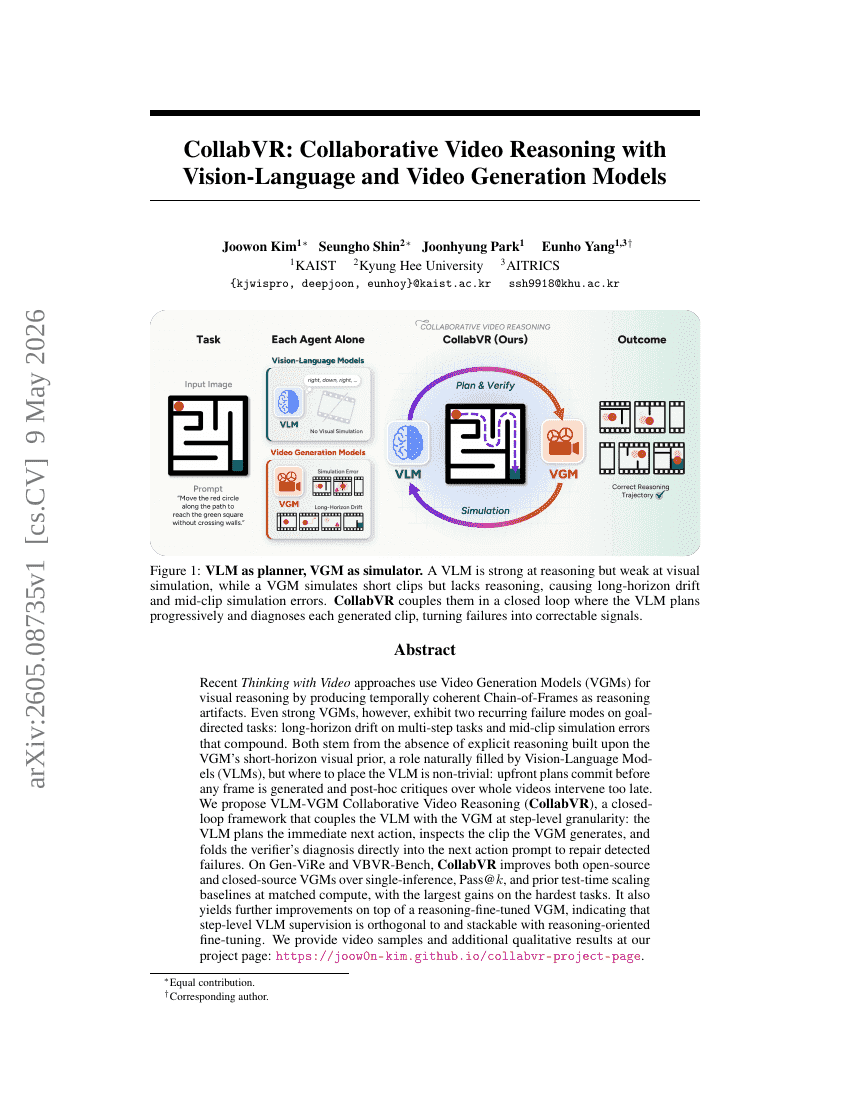
CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
TMAS: Scaling Test-Time Compute via Multi-Agent Synergy
Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
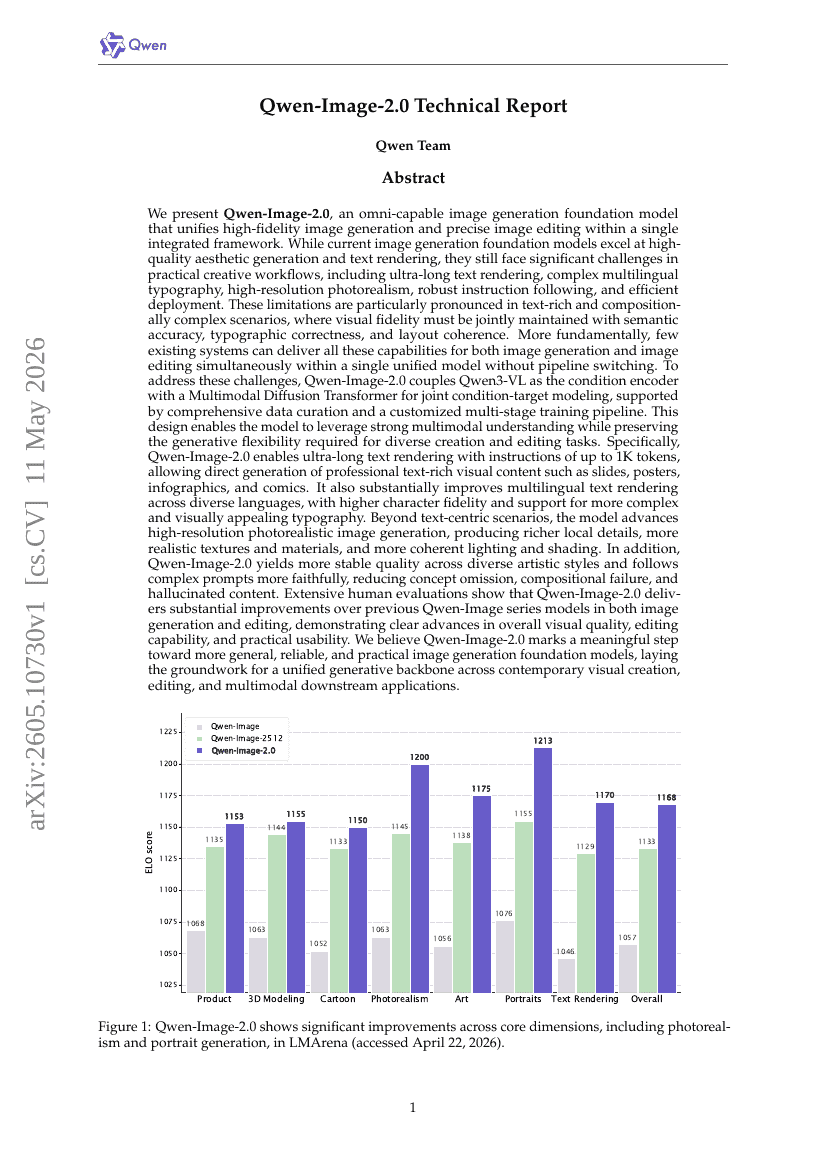
Qwen-Image-2.0 Technical Report
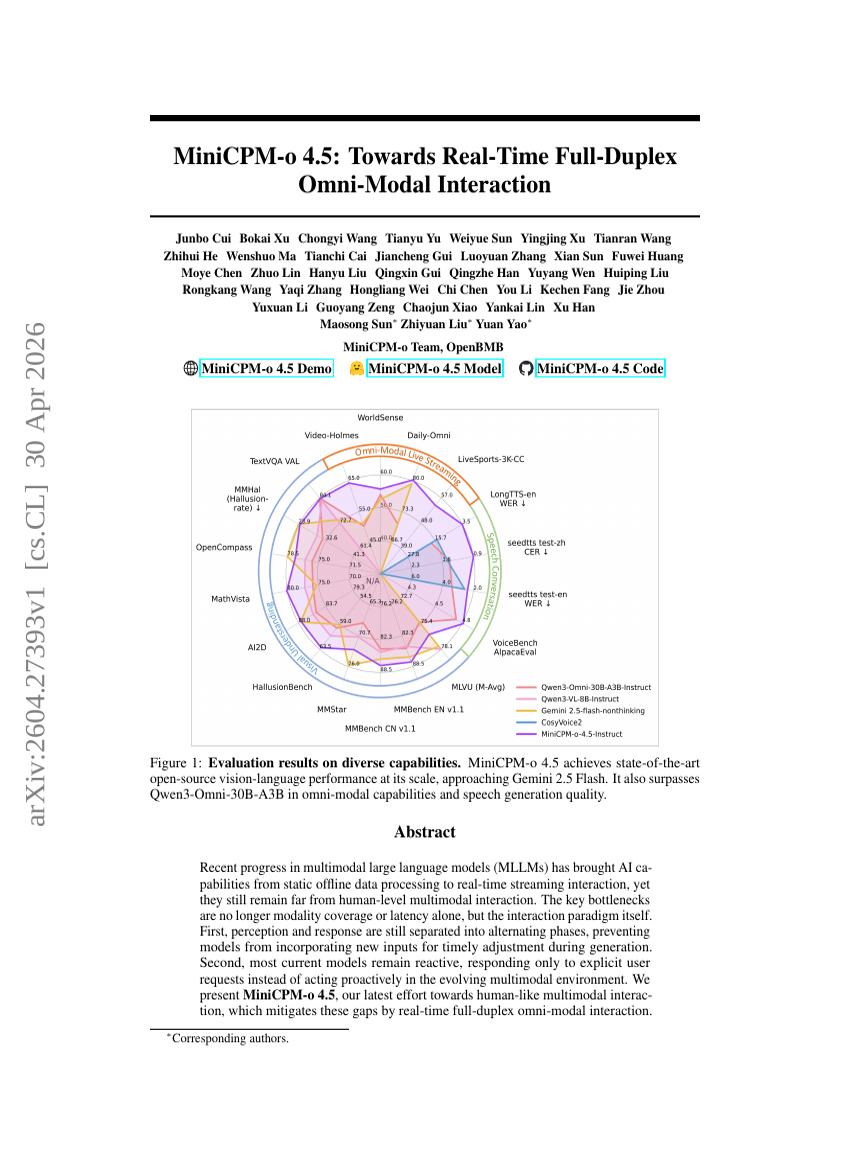
MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction
Learning while Deploying: Fleet-Scale Reinforcement Learning for Generalist Robot Policies
Fast Byte Latent Transformer
AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
Flow-OPD: On-Policy Distillation for Flow Matching Models
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
When to Trust Imagination: Adaptive Action Execution for World Action Models
RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation
Beyond Reasoning: Reinforcement Learning Unlocks Parametric Knowledge in LLMs
Debiased Model-based Representations for Sample-efficient Continuous Control
Multi-Stream LLMs: Unblocking Language Models with Parallel Streams of Thoughts, Inputs and Outputs
Your Language Model is Its Own Critic: Reinforcement Learning with Value Estimation from Actor's Internal States
Relit-LiVE: Relight Video by Jointly Learning Environment Video
Positive Alignment: Artificial Intelligence for Human Flourishing
LLaVA-UHD v4: What Makes Efficient Visual Encoding in MLLMs?
Unmasking On-Policy Distillation: Where It Helps, Where It Hurts, and Why
A Single Neuron Is Sufficient to Bypass Safety Alignment in Large Language Models
SlimQwen: Exploring the Pruning and Distillation in Large MoE Model Pre-training
ELF: Embedded Language Flows
PaperFit: Vision-in-the-Loop Typesetting Optimization for Scientific Documents
Rubric-based On-policy Distillation
CollabVR: Collaborative Video Reasoning with Vision-Language and Video Generation Models
TMAS: Scaling Test-Time Compute via Multi-Agent Synergy
Soohak: A Mathematician-Curated Benchmark for Evaluating Research-level Math Capabilities of LLMs
Qwen-Image-2.0 Technical Report
MiniCPM-o 4.5: Towards Real-Time Full-Duplex Omni-Modal Interaction
Learning while Deploying: Fleet-Scale Reinforcement Learning for Generalist Robot Policies
Fast Byte Latent Transformer
AI Co-Mathematician: Accelerating Mathematicians with Agentic AI
HyperEyes: Dual-Grained Efficiency-Aware Reinforcement Learning for Parallel Multimodal Search Agents
Mean Mode Screaming: Mean--Variance Split Residuals for 1000-Layer Diffusion Transformers
LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
Listwise Policy Optimization: Group-based RLVR as Target-Projection on the LLM Response Simplex
Flow-OPD: On-Policy Distillation for Flow Matching Models
MACE-Dance: Motion-Appearance Cascaded Experts for Music-Driven Dance Video Generation
Rethinking Reasoning-Intensive Retrieval: Evaluating and Advancing Retrievers in Agentic Search Systems
When to Trust Imagination: Adaptive Action Execution for World Action Models
RaguTeam at SemEval-2026 Task 8: Meno and Friends in a Judge-Orchestrated LLM Ensemble for Faithful Multi-Turn Response Generation