Command Palette
Search for a command to run...
EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory
EvoEmbedding: Evolvable Representations for Long-Context Retrieval and Agentic Memory
Chang Nie Chaoyou Fu Junlan Feng Caifeng Shan
Abstract
Existing embedding models are inherently static: they encode text segments in isolation, ignoring their surrounding context and temporal order. This paper introduces EvoEmbedding, a novel embedding model that generates evolvable representations for retrieval. It is tailored for long-context scenarios, where information is dynamic, sequential, and requires continuous state tracking. Our design is simple: EvoEmbedding maintains a continuously updated latent memory as it sequentially processes inputs, and uses it alongside the raw content to jointly generate evolvable embeddings. Consequently, for the same query, our model adapts its representation to retrieve distinct targets based on the evolving context, going beyond static semantic search. To equip the model with this capability, we construct EvoTrain-180K, a diverse dataset for the joint optimization of latent memory and retrieval. Furthermore, we introduce a memory queue to prevent representation collapse during recurrent encoding, alongside segment-batching techniques that tackle significant length variance and accelerate training by 3.8times. Extensive experiments show that our model not only outperforms larger-scale specialists (e.g., Qwen3-Embedding-8B and KaLM-Embedding-Gemma3-12B) across a range of long-context retrieval benchmarks, but also generalizes well to downstream tasks (e.g., personalization) with contexts 10times longer than its training window. Notably, EvoEmbedding seamlessly integrates into agentic workflows to boost performance. For instance, a naive RAG pipeline equipped with our model surpasses dedicated agentic memory systems. Project Page: https://clare-nie.github.io/EvoEmbedding.
One-sentence Summary
EvoEmbedding sequentially updates a latent memory to generate evolvable representations, enabling long-context retrieval that outperforms larger static embedding models on established benchmarks, generalizes to downstream tasks with contexts ten times longer than its training window, and seamlessly boosts agentic RAG pipelines.
Key Contributions
- The paper introduces EvoEmbedding, a novel architecture that maintains a continuously updated latent memory to generate contextually evolvable representations for long-context retrieval. By integrating a memory queue to prevent representation collapse and employing segment-batching techniques, the model efficiently captures temporal dynamics while accelerating training by 3.8×.
- The work presents EvoTrain-180K, a diverse dataset designed for the joint optimization of latent memory and retrieval across highly variable context lengths. This dataset enables the model to learn dynamic context tracking and temporal retrieval capabilities without requiring curriculum learning.
- Extensive evaluations across ten long-context retrieval benchmarks demonstrate that the model achieves state-of-the-art accuracy, surpassing Qwen3-Embedding-8B by 11.1%. The architecture generalizes to 128K contexts, enhances agentic RAG pipelines with zero additional memory token overhead, and decouples temporal query intents from coarse semantic matches.
Introduction
Retrieval-Augmented Generation has become essential for equipping large language models with long-term memory, particularly for AI agents navigating dynamic, sequential information. Conventional embedding models operate statically by encoding text segments in isolation, which disrupts temporal continuity and leaves them ill-equipped for tasks requiring continuous state tracking or coreference resolution. To overcome these limitations, the authors introduce EvoEmbedding, a framework that maintains a continuously updated latent memory to generate context-aware representations as new inputs arrive. The authors leverage a purpose-built training dataset and a memory queue to prevent representation collapse, enabling the model to dynamically adapt to evolving contexts while bypassing the computational overhead of traditional pipeline modifications.
Dataset

-
Dataset Composition and Sources: The authors construct EvoTrain-180K, a large-scale synthetic dataset designed for long context retrieval. The collection combines three primary context types: sequential text segments sampled from FineWeb, multi turn persona based dialogues generated by LLMs, and extracted memory fragments derived from both web and dialogue sources.
-
Subset Details and Filtering Rules: The final pipeline yields 184,137 high quality samples. To guarantee diversity, the team employs over forty predefined question templates and leverages LLMs of varying scales to create queries that range from basic semantic matching to complex reasoning. A verification stage powered by Gemini-3.1-Pro-Preview labels positive retrieval targets, strictly filters hallucinations, and enforces answers that rely exclusively on the provided context.
-
Training Usage and Processing: The complete dataset is used to jointly train the memory and retrieval capabilities of EvoEmbedding. The authors apply strict length constraints to optimize training efficiency, capping every sample at 12,000 tokens and 256 segments.
-
Additional Processing Steps: Raw web documents are initially chunked using a sliding window technique. The automated workflow then constructs retrieval metadata by pinpointing the exact indices of relevant segments to serve as positive targets. This rigorous synthesis and validation process ensures the model achieves strong generalization while requiring significantly less data and shorter training context lengths than standard embedding models.
Experiment
The evaluation spans ten diverse benchmarks across retrieval and generation tasks, positioning EvoEmbedding against standard dense retrievers, specialized agentic memory systems, and advanced optimization strategies. Results validate the model’s strong scalability and generalization to long contexts, demonstrating that a straightforward RAG pipeline consistently outperforms complex memory architectures while eliminating unnecessary token overhead. Additional analyses confirm the method’s plug-and-play compatibility and its unique capacity to capture temporal semantics by cleanly structuring historical context within the latent space. Finally, ablation and efficiency studies establish that the core latent memory mechanism is indispensable for representation quality and significantly reduces peak GPU memory consumption despite a modest increase in encoding time.
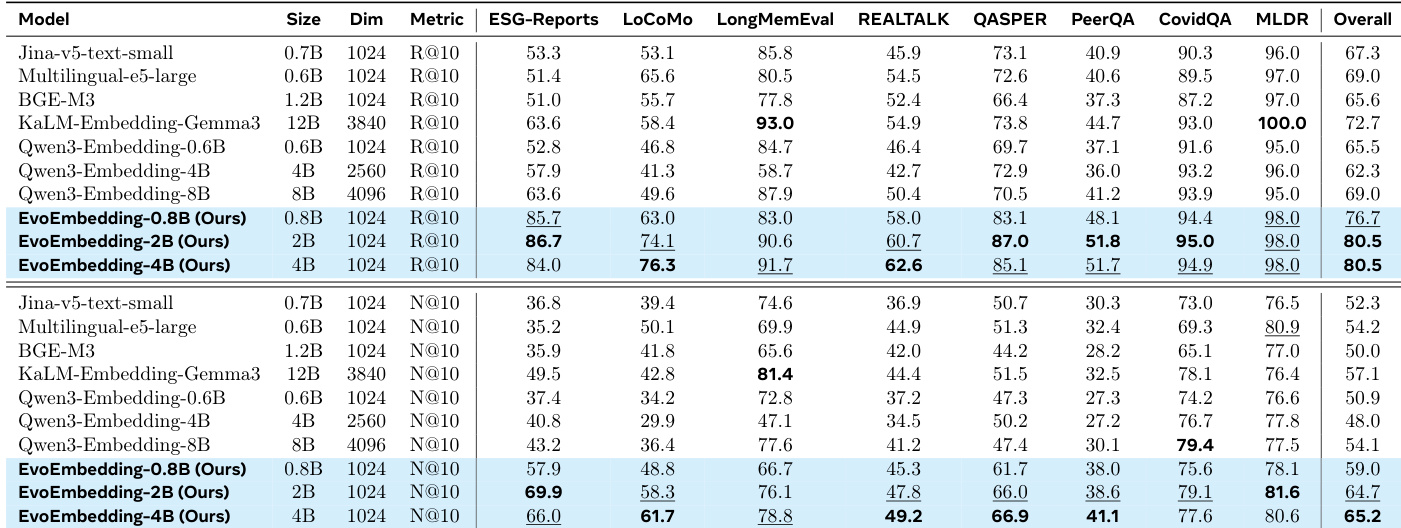
The authors evaluate EvoEmbedding against various baselines across diverse retrieval and generation benchmarks. The results demonstrate that the EvoEmbedding-4B variant achieves the highest aggregate performance across the entire suite of tasks, surpassing larger models like KaLM-Embedding-Gemma3 and Qwen3-Embedding-8B. While specific baselines excel in niche long-context scenarios, EvoEmbedding shows superior generalization and consistency across the overall evaluation. EvoEmbedding-4B achieves the best overall performance across all tested benchmarks, outperforming significantly larger baselines in both recall and ranking metrics. Smaller variants of EvoEmbedding, such as the 2B model, demonstrate strong competitiveness, frequently exceeding the performance of much larger models on specific datasets like QASPER and PeerQA. Although KaLM-Embedding-Gemma3 leads in specific long-context benchmarks like LongMemEval, EvoEmbedding maintains a distinct advantage in the aggregate overall scores.
The ablation study confirms that the latent memory mechanisms are fundamental to the model's success, while specific batching strategies are critical for training efficiency. Removing the memory queue or memory loss leads to a catastrophic performance collapse, particularly on long-context benchmarks, and significantly increases training time. In contrast, omitting segment-batching drastically slows down training with only a minor impact on accuracy, whereas removing length-weighting results in a modest decline in overall performance. Eliminating the memory queue or loss causes a severe performance degradation on conversational and long-context benchmarks. Segment-batching is vital for computational efficiency, as its removal drastically increases training time while yielding only a slight decrease in accuracy. Length-weighting provides a beneficial regularization effect, with its absence leading to a noticeable drop in overall model performance.

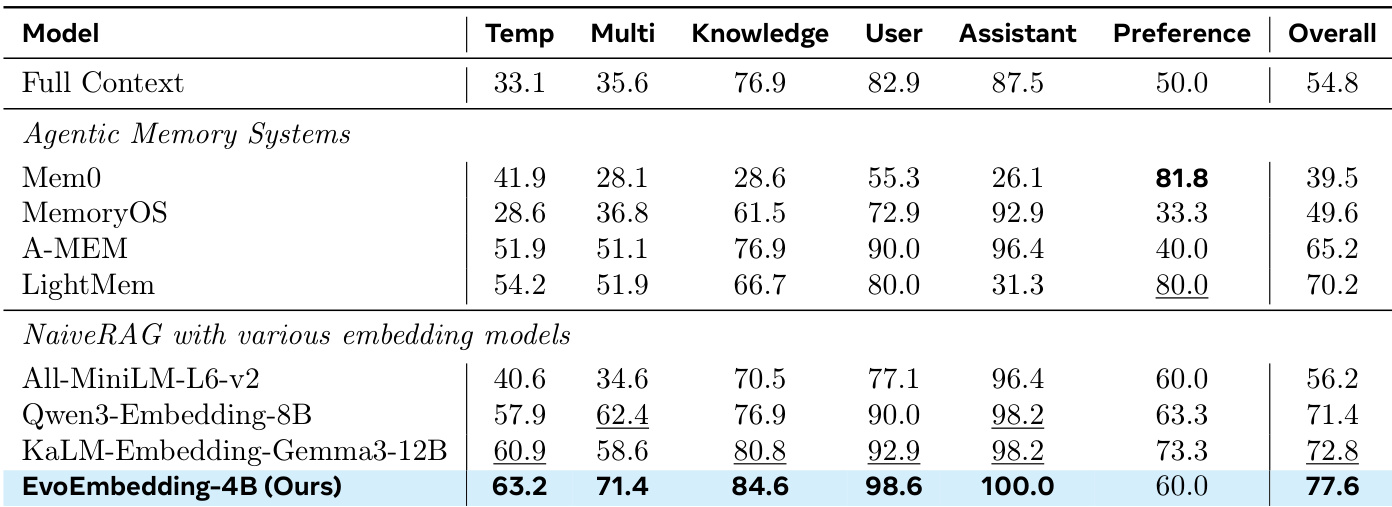
EvoEmbedding-4B achieves the highest overall performance (77.6) among all evaluated models, surpassing both agentic memory systems like LightMem (70.2) and standard embedding baselines such as KaLM-Embedding-Gemma3-12B (72.8). The model demonstrates superior capabilities across multiple dimensions, particularly in temporal reasoning, multi-session dialogue, and knowledge retention, while also maintaining strong performance in user and assistant tracking. EvoEmbedding-4B achieves the highest overall score of 77.6, outperforming the best agentic memory system (LightMem, 70.2) and the strongest embedding baseline (KaLM-Embedding-Gemma3-12B, 72.8). The model excels in specific subtasks, achieving the highest scores in Temporal Reasoning (63.2), Multi-Session Dialogue (71.4), and Knowledge (84.6) compared to all other models listed. EvoEmbedding-4B reaches near-perfect performance in User (98.6) and Assistant (100.0) tracking, surpassing even the Full Context baseline in these categories.
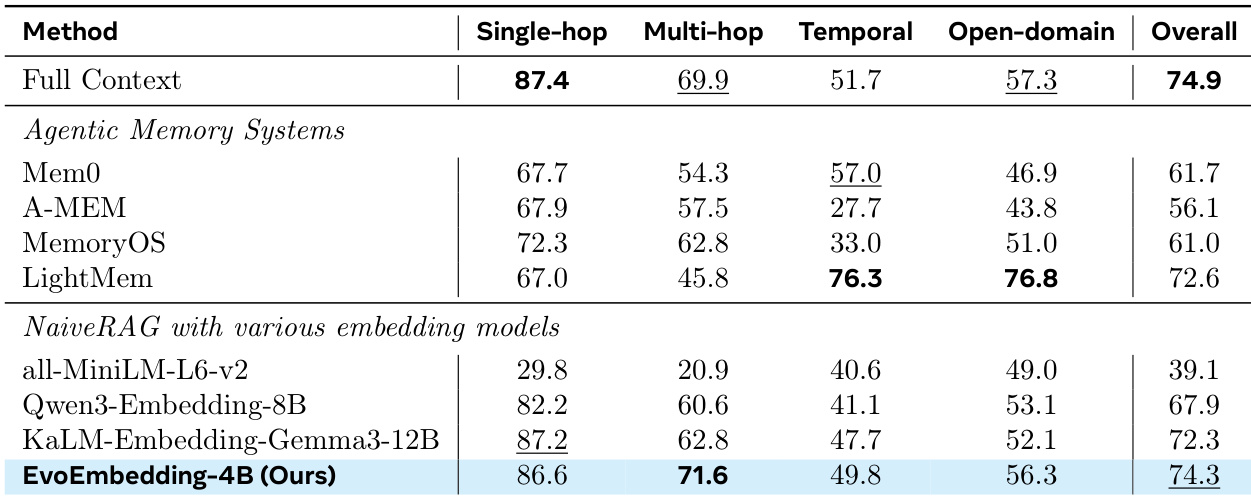
The authors evaluate EvoEmbedding against static embedding baselines to assess the trade-off between encoding efficiency and retrieval performance. The results show that while EvoEmbedding incurs higher context encoding time due to its sequential processing, it achieves the best accuracy and significantly lower peak GPU memory usage compared to larger models. EvoEmbedding achieves the highest retrieval accuracy, surpassing larger baseline models. The method requires significantly less peak GPU memory than the competing static embedding approaches. The model trades off encoding speed for performance, exhibiting the longest context encoding time but delivering the best results.
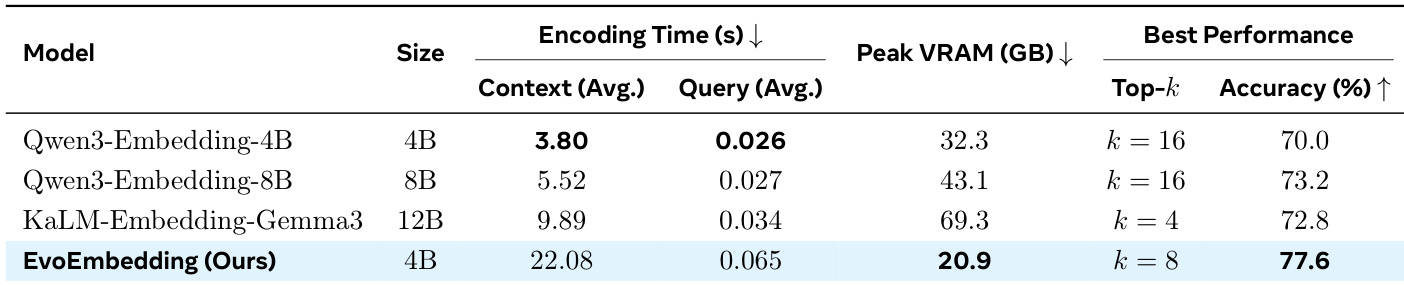
Evaluated against standard embedding baselines and agentic memory systems across diverse retrieval and long-context benchmarks, the primary experiments validate EvoEmbedding's superior accuracy and generalization despite sequential encoding overhead. A dedicated efficiency assessment confirms that the model achieves top retrieval performance while significantly reducing peak GPU memory requirements compared to larger static approaches. Additionally, ablation studies validate that latent memory mechanisms are indispensable for long-context retention, while specific batching strategies are critical for maintaining training efficiency. Collectively, these results demonstrate that EvoEmbedding effectively balances computational constraints with robust multi-session dialogue and knowledge tracking capabilities.