Command Palette
Search for a command to run...
Credit Assignment with Resets in Language Model Reasoning
Credit Assignment with Resets in Language Model Reasoning
Ankur Samanta Akshayaa Magesh Ayush Jain Youliang Yu Daniel Jiang Kavosh Asadi Kaveh Hassani Paul Sajda Jalaj Bhandari Yonathan Efroni
Abstract
Contemporary reinforcement learning with verifiable rewards (RLVR) methods post-train language models by propagating a single outcome reward uniformly across all intermediate steps. For language models on long multi-step reasoning tasks, this assigns identical credit to every step, obscuring which were most responsible for the observed outcome. Learning from steps that most directly shape the outcome can enable efficient learning as it provides a more meaningful signal for policy updates. Such mechanisms are also found in biological systems, which reinstate high-impact decision points and learn from counterfactual "what if" outcomes simulated from those states. Motivated by this, we study RL post-training methods that use resets to improve credit assignment by learning from the counterfactual outcomes of improvable states. A reset re-enters a previously-visited state and resamples a continuation, binding outcome differences to the decisions made from that state. In this work, we argue that resets are useful for credit assignment when the reset state admits a strictly better action, namely, when it has significant potential for improvement. We propose two reset-based RLVR post-training methods for language models, Random-Reset Policy Optimization (RRPO) and Self-Reset Policy Optimization (SRPO). Both resample multiple suffix continuations from a reset state drawn from a failed trajectory, and apply the policy gradient only to those suffix tokens. This shared-prefix group can be thought of as a counterfactual group of rollouts whose outcome differences attribute credit to the divergent suffix tokens. They differ in how the reset state is chosen. RRPO chooses it uniformly at random across the reasoning steps, while SRPO chooses it via self-localization of the first erroneous step. SRPO requires no external step-level feedback, leveraging the finding that language models can self-localize the first erroneous thought in failed structured-reasoning traces well enough to drive self-correction. To quantify the gain over random resets from self-localization of errors, we use the framework of Conservative Policy Iteration (CPI), a foundational algorithm for policy optimization. CPI draws on-policy state samples via random resets, estimates advantages, and applies a conservative policy update. We refer to this algorithm as CPI-with-random-resets (CPI-RR). We compare its performance to an alternative CPI algorithm that assumes access to a credit-assignment oracle: a membership test for improvable states, answering whether a state admits an action with advantage greater than a threshold τ. The resulting variant, CPI-CARO, uses the oracle to draw reset states only from improvable states and applies the policy update only there. We establish that CPI-CARO reduces sample complexity by 1/pπ² and increases per-iteration improvement by 1/pπ over CPI-RR, where pπ is the on-policy probability of reaching improvable states. On a 10-benchmark suite spanning math, science, strategic, and commonsense reasoning, SRPO outperforms GRPO and contemporary RL baselines that use self-correction or shared-prefix continuation. We also test SRPO in a coding domain, where it converges to a higher pass rate and learns 2–3× faster than GRPO and RRPO. Higher-quality self-localizations yield higher correction rates and better suffix groups: clean prefixes correct nearly 2× as often as erroneous ones, establishing explicit self-localization as an imperfect but effective proxy for the credit-assignment oracle. This sensitivity to localization quality motivates further work on improving it in reset-based RL to enable more efficient learning.
One-sentence Summary
Researchers from multiple institutions propose Self-Reset Policy Optimization (SRPO), a reinforcement learning method that improves credit assignment in language model reasoning by resetting and resampling from self-identified erroneous steps to create counterfactual suffix groups that attribute outcome differences to specific decisions, achieving 2–3× faster learning and higher accuracy than GRPO across math, science, and coding benchmarks.
Key Contributions
- Introduces Random-Reset Policy Optimization (RRPO) and Self-Reset Policy Optimization (SRPO), two reset-based reinforcement learning methods that improve credit assignment by resampling suffix continuations from a reset state in a failed trajectory and applying the policy gradient only to those suffix tokens.
- A theoretical analysis using Conservative Policy Iteration shows that resetting from improvable states via a credit-assignment oracle (CPI-CARO) reduces sample complexity by 1/pπ² and increases per-iteration improvement by 1/pπ compared to random resets (CPI-RR), where pπ is the on-policy probability of reaching such states.
- Experiments across a 10-benchmark reasoning suite (math, science, strategic, commonsense) and a coding domain demonstrate that SRPO outperforms GRPO and contemporary RL baselines, converges to a higher pass rate, and learns 2–3× faster than GRPO and RRPO; higher-quality self-localizations yield nearly twice the correction rate of erroneous ones.
Introduction
Standard reinforcement learning with verifiable rewards (RLVR) methods for post-training language models assign a single outcome reward uniformly to every token in a reasoning trajectory. This uniform assignment ignores the fact that some reasoning steps are directly responsible for the final success or failure, diluting the learning signal and preventing targeted refinement of faulty steps. The authors address this limitation by introducing reset-based credit assignment methods that return to an intermediate state and resample counterfactual continuations, so that outcome differences can be attributed to specific decisions. They propose two algorithms, Random-Reset Policy Optimization (RRPO) and Self-Reset Policy Optimization (SRPO), and analyze them within the Conservative Policy Iteration (CPI) framework. Their main contribution is demonstrating that a credit-assignment oracle targeting improvable states yields provable improvements over random resets, and that SRPO, which uses the model itself to localize errors with no external supervision, consistently outperforms standard GRPO and RRPO across models and reasoning benchmarks.
Method
The authors proposea post-training RLVR method that frames resets as a credit-assignment primitive. They operate at a thought-level granularity, formalizing the generation process as a Thought MDP where each action is a semantically coherent reasoning step (a "thought") delimited by a stop pattern. This abstraction allows the model to self-determine boundaries during generation, making every thought an atomic, self-contained unit for credit assignment without requiring retroactive parsing.
To construct training rollouts, the authors build a buffer combining a base group of G i.i.d. rollouts from the prompt x0 (standard GRPO) and a shared-prefix group of G rollouts from a reset state x∗. As shown in the figure below, different configurations of these groups can be utilized, ranging from the standard GRPO baseline to various SRPO splits such as 1x4, 2x4, and 1x8.
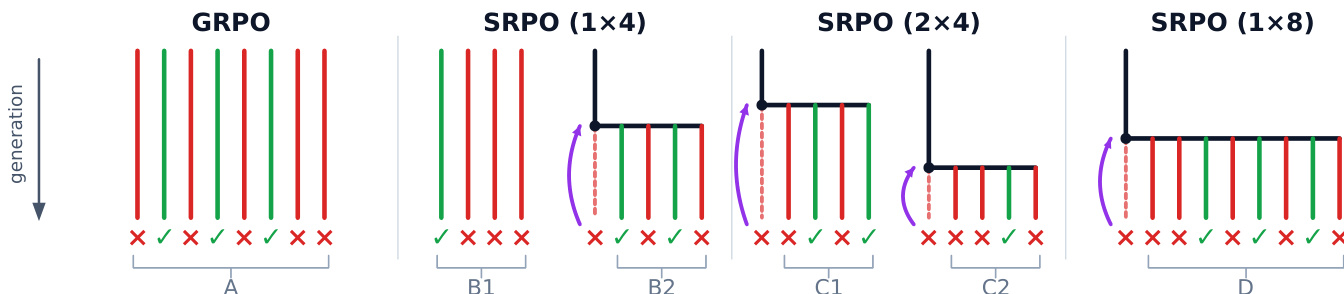 The shared-prefix group is generated by first drawing rollouts until an incorrect "seed" is found. The methods differ in how the reset index h∗ is chosen to form the reset state x∗=(x0,y~1:h∗−1). In Random Reset Policy Optimization (RRPO), h∗ is drawn uniformly, realizing a uniform reset. In Self-Reset Policy Optimization (SRPO), the model performs explicit self-localization to identify the index of the first incorrect thought in the seed. The same policy that generated the seed is prompted to analyze its own reasoning trace, effectively acting as a credit-assignment oracle to find the verified-correct prefix preceding the error.
The shared-prefix group is generated by first drawing rollouts until an incorrect "seed" is found. The methods differ in how the reset index h∗ is chosen to form the reset state x∗=(x0,y~1:h∗−1). In Random Reset Policy Optimization (RRPO), h∗ is drawn uniformly, realizing a uniform reset. In Self-Reset Policy Optimization (SRPO), the model performs explicit self-localization to identify the index of the first incorrect thought in the seed. The same policy that generated the seed is prompted to analyze its own reasoning trace, effectively acting as a credit-assignment oracle to find the verified-correct prefix preceding the error.
Refer to the framework diagram for a detailed view of the SRPO process. In the initial iteration, the model generates a sequence of thoughts. Upon verifying accuracy, a localization step identifies the first erroneous thought (e.g., y~4). The process then resets to the verified-correct prefix (keeping y~1:3) and samples multiple alternative suffixes (Suffix 1 through Suffix 4). The gradients for the shared prefix are masked out, ensuring credit is assigned only to the resampled suffixes based on their final outcomes.
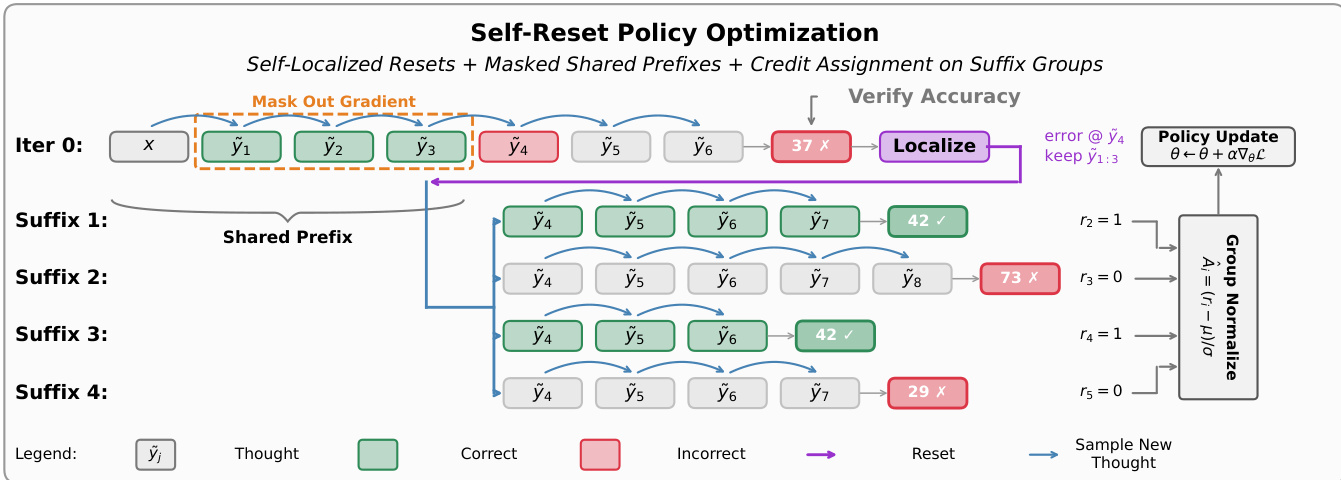
Finally, the authors reinforce these rollouts using group-relative advantages. For each group, advantages are self-normalized based on the group's empirical mean and standard deviation, measuring each rollout's outcome relative to the rest of its group. For the shared-prefix group, the loss applies this advantage only to the suffix tokens, masking the shared prefix. This prefix masking serves as the parametric analog of the theoretical policy update on the reset state, ensuring the credit signal lives on thoughts rather than tokens. The policy is updated via a single on-policy gradient step over the combined buffer without PPO clipping or KL regularization.
Experiment
Resets re-enter a previously visited state to resample continuations, attributing credit to the decisions made from that state, and are most useful when the reset state has significant potential for improvement. The work introduces two reset-based RL post-training methods—RRPO, which selects reset states uniformly at random, and SRPO, which uses the model’s own self-localization of the first erroneous step—and shows that SRPO consistently outperforms random-reset and no-reset baselines across math, science, strategic, commonsense, and coding benchmarks while learning faster. Self-localization acts as an imperfect but effective proxy for a credit-assignment oracle, with clean prefixes correcting nearly twice as often as erroneous ones, making localization quality the primary bottleneck and motivating further work on improving it. The methods rely on verifiable rewards and multi-step reasoning structures, and the theoretical analysis establishes sample-complexity gains from resetting only at improvable states.
The authors compare the computational efficiency and resource usage of GRPO, RRPO, and SRPO under a fixed rollout budget. Results show that while reset-based methods like RRPO and SRPO require more total training time than GRPO, SRPO is more efficient than RRPO in terms of total hours and token consumption. Additionally, the reset-based strategies exhibit slower generation speeds and longer response lengths compared to the standard GRPO baseline. SRPO requires less total training and validation time than RRPO, making it the more efficient reset-based method. RRPO consumes the most tokens and generates the longest responses, while SRPO maintains moderate resource usage. GRPO achieves the highest generation speed, whereas reset-based methods experience slower token generation due to their sampling overhead.

The authors evaluate different reset-based sampling strategies for SRPO under a fixed compute budget across ten reasoning benchmarks. The 1x4 split, which balances base-policy coverage with shared-prefix depth, achieves the best performance on the majority of tasks for both evaluated models. Consequently, this configuration is adopted as the default SRPO setup for remaining experiments. The 1x4 sampling strategy outperforms 2x4 and 1x8 splits on most benchmarks for both Qwen2.5-14B-Instruct and OLMo-3-7B-Instruct. Increasing suffix depth to 1x8 or prefix diversity to 2x4 generally yields lower performance compared to the balanced 1x4 split. RRPO with a 2x4 split occasionally achieves top scores on specific tasks but is generally outperformed by the 1x4 SRPO configuration.
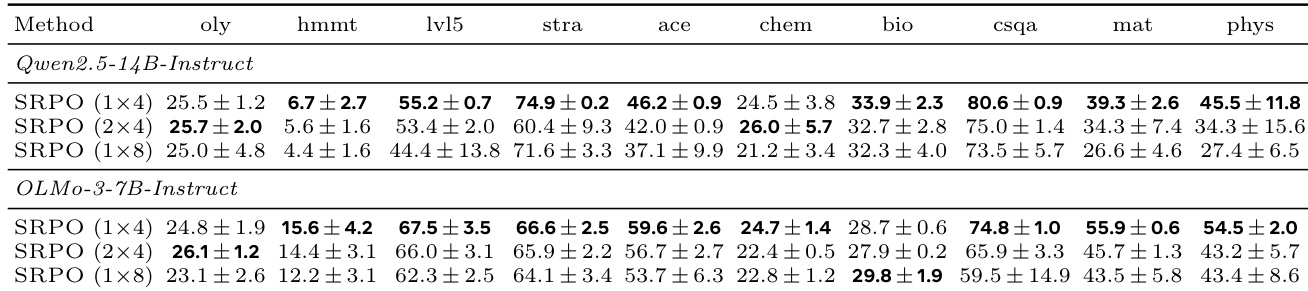
The authors evaluate different sampling strategies for Self-Reset Policy Optimization under a fixed compute budget to determine the optimal balance between base-policy coverage and shared-prefix depth. Results indicate that the 1x4 split, which combines independent base rollouts with resampled suffixes from a single self-localized prefix, achieves the best performance across the majority of reasoning benchmarks. Consequently, this configuration is adopted as the default for subsequent experiments. The 1x4 sampling strategy outperforms alternatives like 2x4 and 1x8 on most benchmarks by effectively balancing base rollouts and shared-prefix depth. Increasing prefix diversity or maximizing suffix depth generally leads to lower performance compared to the balanced 1x4 approach. The 1x4 configuration achieves the highest scores in tasks such as strategy, math, and science reasoning, demonstrating its robustness across different domains.

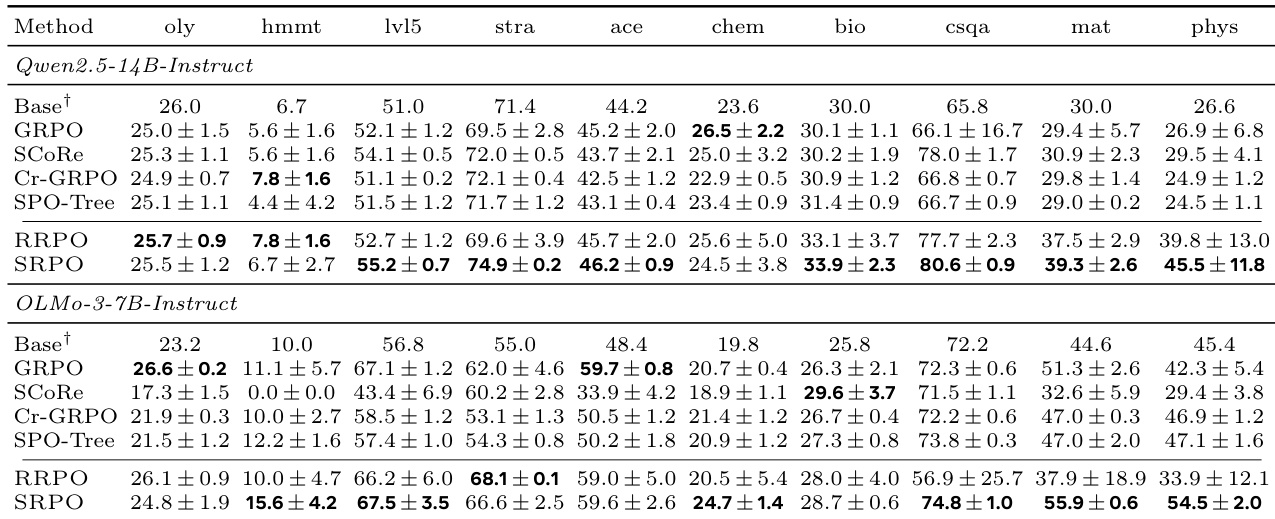
The authors compare SRPO and RRPO against GRPO and related baselines across ten reasoning benchmarks using two language models. SRPO emerges as the strongest method, achieving the best results on the majority of tasks for both models, while RRPO performs comparably to GRPO. These gains on diverse benchmarks indicate strong out-of-distribution generalization from training solely on math problems. SRPO outperforms all other evaluated methods on most benchmarks for both Qwen2.5-14B-Instruct and OLMo-3-7B-Instruct. RRPO demonstrates performance levels similar to GRPO across the tested reasoning tasks. The performance improvements from SRPO extend beyond the training domain, showing effective generalization to science, strategic, and commonsense reasoning.
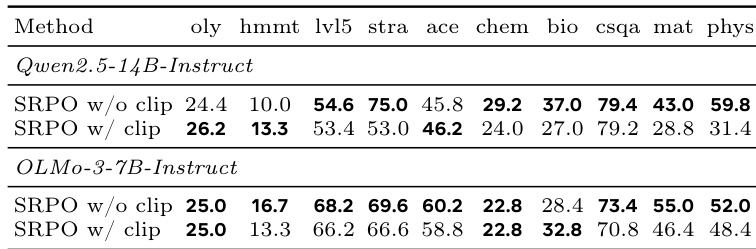
The the the table compares the general reasoning performance of SRPO variants, specifically analyzing the impact of clipping, across two language models on ten diverse benchmarks. The results indicate that the unclipped SRPO configuration generally achieves superior performance across the majority of math, science, and strategy tasks compared to the clipped variant. The SRPO variant without clipping achieves the best results on most benchmarks for both the Qwen and OLMo models. Clipping appears beneficial only for a minority of specific tasks, such as Olympiad math and HMMT for the larger model. The method demonstrates robust performance across science and commonsense domains, reflecting strong generalization from the math-focused training data.
The experiments first compare the computational efficiency of GRPO, RRPO, and SRPO, finding that while reset-based methods incur higher training time and slower generation speeds, SRPO is more resource-efficient than RRPO. A subsequent ablation on sampling strategies establishes the 1x4 split as optimal for SRPO, as it balances base-policy coverage and shared-prefix depth to achieve the best performance across most reasoning benchmarks. Broader evaluations against baselines show that SRPO consistently outperforms all other methods on diverse reasoning tasks, demonstrating strong out-of-distribution generalization from math-only training, whereas RRPO performs comparably to GRPO. Finally, an analysis of clipping reveals that the unclipped SRPO variant generally yields superior results across the majority of domains.