Command Palette
Search for a command to run...
OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
OmniVideo-100K: A Dataset for Audio-Visual Reasoning through Structured Scripts and Evidence Chains
Xinyue Cai Chaoyou Fu Yi-Fan Zhang Ran He Caifeng Shan
Abstract
Current automated pipelines for audio-visual Question Answering (QA) generally adopt a "video-caption-QA" paradigm. However, these methods typically segment videos into short clips and generate separate descriptions for audio and visual modalities. This decoupled processing severs inherent associations between sounds and their visual sources, while independent clip processing often causes inconsistent descriptions of the same entity across segments. Furthermore, coupling long-text comprehension and QA synthesis into a single step often restricts models to localized events, yielding questions lacking long-term temporal connections and deep cross-modal reasoning. To address these issues, we propose an automated data engine featuring two mechanisms: (1) Entity-Anchored Video Scripting transforms videos into structured scripts, comprising summaries, main entity lists, and segment-wise audio-visual descriptions. The entity list serves as a global prior to ensure cross-segment referential consistency and reconstruct audio-visual associations. (2) Clue-Guided QA Generation prompts models to first mine cross-segment, multimodal clues from the script, and subsequently generate QA pairs based on these high-value clues. Leveraging this pipeline, we construct the instruction-tuning dataset OmniVideo-100K and a human-verified test set, OmniVideo-Test.
One-sentence Summary
To address the decoupled and short-clip processing limitations of current pipelines, the authors propose an automated data engine that constructs OmniVideo-100K, an audio-visual reasoning instruction-tuning dataset, by transforming videos into entity-anchored structured scripts for cross-segment consistency and cross-modal association reconstruction, and by performing clue-guided QA generation to mine long-term multimodal clues.
Key Contributions
- Entity-Anchored Video Scripting converts videos into structured scripts containing summaries, a main entity list, and segment-wise audio-visual descriptions. The entity list acts as a global prior to enforce cross-segment referential consistency and restore associations between sounds and their visual sources.
- Clue-Guided QA Generation prompts a model to first mine cross-segment, multimodal clues from the structured script, then produces question-answer pairs with long-term temporal connections and deep cross-modal reasoning based on those high-value clues.
- This pipeline is used to construct OmniVideo-100K, an instruction-tuning dataset of 100K samples, and OmniVideo-Test, a human-verified evaluation benchmark, for fine-tuning multimodal large language models on coherent audio-visual question answering.
Introduction
In audio-visual question answering, models must jointly reason about visual and auditory streams in videos to answer complex queries, which is critical for robust multimodal understanding. Prior automated pipelines rely on a “video-caption-QA” approach that segments videos and processes audio and visual modalities separately, breaking the natural coupling between sounds and their visual sources. This decoupling causes inconsistent entity descriptions across segments and limits questions to short, localized events without long-range temporal or deep cross-modal reasoning. The authors address these challenges with an automated data engine that first constructs entity-anchored video scripts, using a global entity list to maintain referential consistency and restore audio-visual associations, and then employs clue-guided QA generation to mine cross-segment, multimodal evidence before creating reasoning-rich question-answer pairs. This pipeline produces the OmniVideo-100K training set and a verified test set, and fine-tuning multimodal large language models on this data yields substantial gains in audio-visual comprehension and generalization.
Dataset
The authors construct the OmniVideo dataset, a large-scale audio-visual QA resource for instruction tuning and evaluation. Its composition, processing, and usage are summarized below.
-
Dataset composition and sources
- Videos are collected from online platforms, starting from a keyword pool of seven categories (vlog, news, cartoon, sports, documentary, tv, ego) that is iteratively expanded with new video tags.
- All videos are filtered to retain only English content with a minimum resolution of 480p. Additionally, visual dynamics and word density filters ensure rich audio-visual information, and videos containing hard-coded subtitles are discarded through automatic subtitle detection.
- The curated source pool consists of 5,214 videos, predominantly 1–3 minutes long and spanning a diverse set of real-world domains.
-
Key subsets
- OmniVideo-100K (training set): 100,000 automatically generated QA pairs covering ten audio-visual tasks evenly. The questions are a mix of open-ended (OE) and multiple-choice (MCQ) formats in a 7:3 ratio. OE answers are notably longer because they include a detailed reasoning explanation alongside the final conclusion; the four MCQ options are balanced in length to avoid length bias.
- OmniVideo-Test (evaluation set): 505 multiple-choice QA pairs drawn from 264 videos. All samples are initially generated by the same pipeline and then subjected to a rigorous manual review. Reviewers enforce factual accuracy, cross-modal dependency (discarding questions answerable from a single modality), and answer uniqueness. Only about 38% of the initial generations pass this filtering, yielding a high-quality test set.
-
How the data is used in the model
- The full OmniVideo-100K set serves as the instruction-tuning corpus for Qwen2.5-Omni. No additional datasets are mixed during this fine-tuning stage.
- Training hyperparameters are kept identical to those used for baselines (AVQA and JavisInst-Und) to enable fair comparison. The fine-tuned model is evaluated on OmniVideo-Test and external benchmarks.
-
Cropping, metadata, and processing details
- The dataset is built with an automated pipeline that employs Gemini-2.5-Pro and Gemini-3-Pro. For basic Alignment and Context Understanding tasks, most queries target localized events inside short clips; the authors directly prompt the model to mine clues and generate QA pairs in a single pass, rather than using the full multi-step strategy employed for more complex tasks.
- The pipeline uses a clue-guided strategy that anchors every QA pair to explicit cross-modal evidence chains. As a byproduct, it produces structured audio-visual scripts that serve as reusable intermediate representations, useful beyond QA generation (e.g., video editing).
- No video cropping is applied to the training or evaluation inputs; the model receives the full video and the associated question.
Method
The authors propose an automated audio-visual QA generation pipeline designed to enhance the cross-modal understanding capabilities of Multimodal Large Language Models (MLLMs). As shown in the framework diagram below, the method consists of two primary modules: Entity-Anchored Video Scripting and Clue-Guided QA Generation.
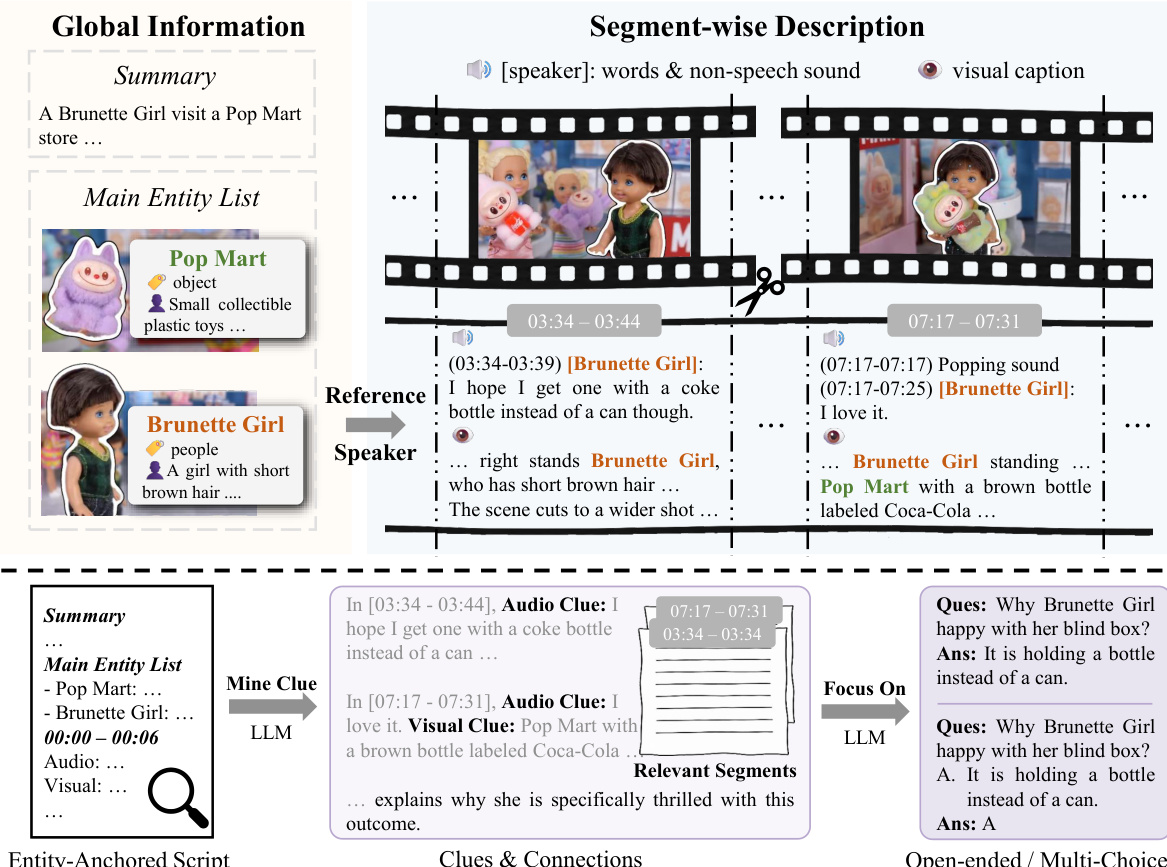
Entity-Anchored Video Scripting
This stage transforms raw audio-visual videos into structured, script-like text to ensure narrative coherence and explicit audio-visual associations.
Main Entity List Before processing segments, the authors leverage MLLMs to identify main active entities (people, animals, objects) critical to the video's narrative. For each entity, a unique descriptive identifier and detailed feature description are generated. This list serves as a global prior to constrain subsequent descriptions and ensure consistent entity references. The prompt used for this identification process is illustrated below.

Audio Information Processing The audio stream is processed to extract speech and non-speech sounds. MLLMs generate timestamped transcriptions for speech, segmented by natural pauses or speaker changes. The specific prompt for generating these transcriptions is shown below.

Simultaneously, the model identifies non-speech sounds (e.g., music, environmental noises) and logs them chronologically with timestamps, avoiding inferred context. The prompt for this acoustic event logging is detailed below.

Coherent Segmented Visual Narratives The video is partitioned into primary segments (target duration of 15 seconds) to establish a temporal backbone. Visual captions are generated for each segment based on video frames. The MLLM analyzes shots across four dimensions: Setting & Environment, Characters & Objects, Actions & Interactions, and Cinematography. The main entity list is used as a prior to ensure consistent references. The prompt instructing the model to generate these detailed visual descriptions is provided below.

Sound-Source Association and Summary To link audio and visual modalities, MLLMs identify the speaker for each transcription by jointly analyzing visual and audio features. If a speaker is in the main entity list, the existing identifier is used; otherwise, a new one is generated. This process handles off-screen speakers as well. Finally, a high-level summary of the video is generated, constrained by the main entity list. The prompt for this summary generation is shown below.

Clue-Guided QA Generation
Based on the coherent script, the authors adopt a two-step strategy to construct QA pairs with long-term temporal spans and deep cross-modal dependencies.
Global Clue Mining LLMs scan the full script to extract clues needed for task-specific QA generation (e.g., causal reasoning). This step emphasizes integrating information across multiple segments and modalities to construct reasoning chains. The model provides relevant segment timestamps and a logical description of the audio-visual synergy, converting implicit understanding into explicit reasoning steps.
Locally Focused Generation Using the logical descriptions and timestamps from the mining step as contextual prompts, the model focuses on key segments to generate QA pairs. This approach filters irrelevant content, reducing cognitive load and ensuring the resulting questions require both long-term temporal reasoning and audio-visual synergy. The generation process produces both open-ended and multiple-choice questions, validated through strict solvability tests (such as the Blind Test and Unimodal Trap check) to prevent unimodal or simple matching answers.
Experiment
The evaluation fine-tunes VITA-1.5, Qwen2.5-Omni-7B, and Qwen3-Omni-30B-A3B on OmniVideo-100K, assessing them on the new OmniVideo-Test suite and several established audio-visual and general video benchmarks. The key finding is that OmniVideo-100K substantially boosts cross-modal synergy and temporal alignment, enabling models to move from unimodal speculation to grounded audio-visual reasoning and achieving large gains on challenging Alignment and Reasoning tasks while preserving general video understanding. Ablation studies on data generation show that the clue-guided, script-based pipeline produces questions with longer temporal spans and stricter cross-modal dependency, and that maintaining entity consistency and speaker labels significantly reduces referential confusion and sound-source mismatch, validating the dataset’s quality. Data scaling experiments confirm rapid performance improvements even with small subsets, saturating around 75K samples and demonstrating the efficiency of the automated generation approach.
The authors compare the accuracy of various multimodal large language models on question-answer pairs generated by direct and clue-guided strategies. Results indicate that all models achieve lower accuracy on the clue-guided set, demonstrating that this strategy produces more challenging questions. The fine-tuned model shows a substantial improvement on the demanding clue-guided set compared to the baseline, validating the effectiveness of the training data. All models perform worse on clue-guided question-answer pairs than on direct generation pairs, confirming the increased difficulty of the clue-guided strategy. The fine-tuned model achieves a significant accuracy boost on the challenging clue-guided set compared to the baseline model. Performance gaps between different models are more pronounced on clue-guided pairs, suggesting this strategy better distinguishes varying model capabilities.

The authors investigate how the volume of generated training data affects model performance by fine-tuning on subsets of varying sizes. Results show that incorporating even a small amount of data leads to significant performance improvements across multiple benchmarks, with steady gains observed as the data volume increases up to a certain point before reaching saturation or slight fluctuations at the largest scale. Incorporating a small subset of training data yields a substantial performance leap across nearly all evaluated benchmarks compared to the baseline. Model performance demonstrates steady improvements as the training data volume increases from the smallest to intermediate scales. Expanding the dataset to its maximum size results in slight performance fluctuations or saturation, indicating diminishing returns from further data scaling.

The authors evaluate various multimodal large language models on the OmniVideo-Test benchmark to assess capabilities across understanding, alignment, and reasoning tasks. Results indicate that existing open-source models generally perform better on understanding tasks compared to alignment and reasoning tasks. Fine-tuning these models on the OmniVideo-100K dataset yields significant performance improvements across all task dimensions, effectively enhancing their synergistic audio-visual understanding. Existing open-source models generally perform better on understanding tasks than on alignment and reasoning tasks, indicating limitations in temporal alignment and deep cross-modal reasoning. Models fine-tuned on the OmniVideo-100K dataset exhibit significant performance gains over their baselines across all task dimensions, including fine-grained perception and causal reasoning. The fine-tuned models consistently outperform other open-source baselines, with the largest fine-tuned model achieving the highest overall scores among the open-source variants.
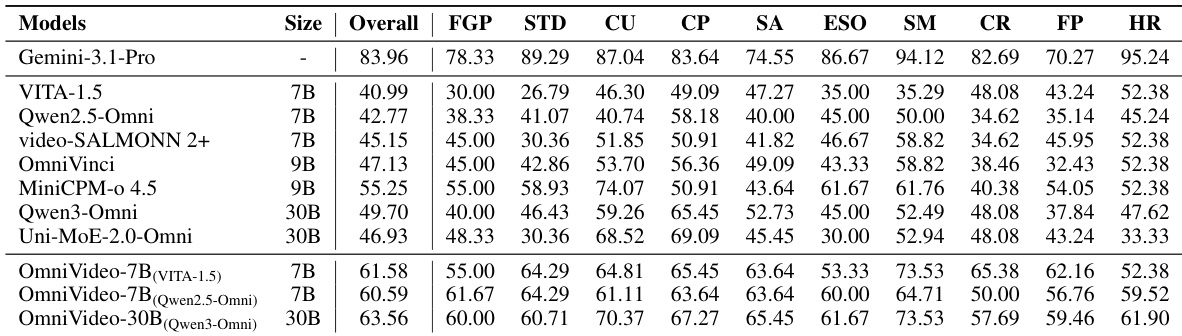
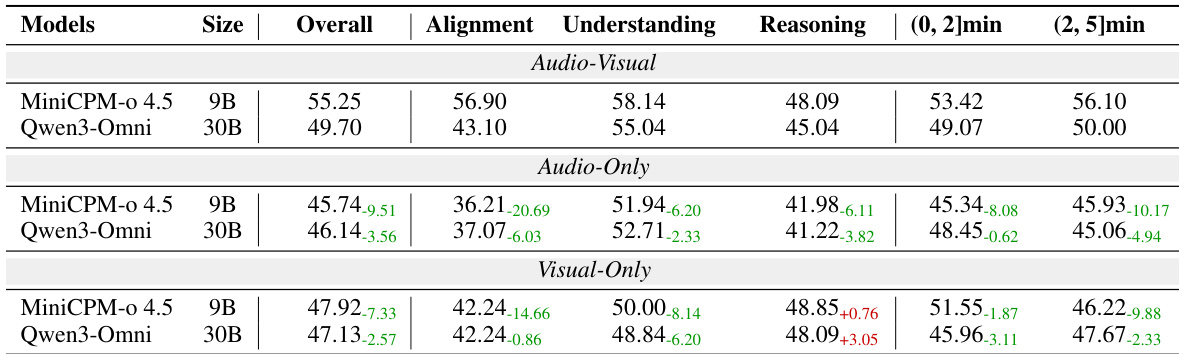
The authors evaluate MiniCPM-o 4.5 and Qwen3-Omni under audio-visual, audio-only, and visual-only settings to analyze cross-modal dependency. Results show that both models experience performance declines when restricted to a single modality, confirming that the test set requires cross-modal synergy. MiniCPM-o 4.5 demonstrates a larger performance increase when both modalities are provided compared to Qwen3-Omni, indicating a higher synergistic gain. Both models show performance drops in unimodal settings compared to the full audio-visual setting. MiniCPM-o 4.5 achieves a greater performance boost from combining modalities than Qwen3-Omni. The unimodal performance of the two models is comparable, with minimal gaps between them.
The authors evaluate the generalization capabilities of models fine-tuned on OmniVideo-100K across various audio-visual and general video benchmarks. Results indicate that fine-tuning on this dataset consistently enhances performance on specialized audio-visual tasks while preserving the model's original general video understanding abilities. Fine-tuning with OmniVideo-100K yields consistent performance gains across multiple audio-visual benchmarks such as Daily-Omni and JointAVBench. The fine-tuned model maintains its baseline performance on general video understanding tasks like Video-MME, showing no significant degradation. Alternative data augmentations like AVQA and JavisInst-Und generally underperform compared to the OmniVideo-100K fine-tuned model on the evaluated benchmarks.

The experiments first validate that a clue-guided question generation strategy yields more difficult multimodal evaluation sets, as all models achieve lower accuracy on these questions and performance gaps widen, better distinguishing model capabilities; a fine-tuned model shows significant gains on this challenging set. Fine-tuning on the OmniVideo-100K dataset consistently improves performance across understanding, alignment, and reasoning tasks while preserving general video comprehension, and even a small amount of training data produces substantial improvements before reaching saturation. Cross-modal synergy is essential, with models dropping sharply in unimodal settings, and MiniCPM-o 4.5 exhibits a greater synergistic boost, while the fine-tuned models consistently outperform other open-source baselines.