Command Palette
Search for a command to run...
NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
NatureBench: Can Coding Agents Match the Published SOTA of Nature-Family Papers?
Abstract
We introduce NatureBench, a cross-discipline benchmark of 90 tasks distilled from peer-reviewed Nature-family publications, designed to evaluate whether AI coding agents can move beyond reproduction toward discovery on real scientific problems. NatureBench is built on NatureGym, an automated pipeline that constructs a standardized, per-task containerized environment from a source paper, addressing the environment-fragmentation problem that has limited the credibility of prior agent-on-research benchmarks. Evaluating ten frontier agent configurations under a strict web-search-disabled protocol, we find that the strongest model surpasses SOTA on only 17.8% of tasks under the g>0.1 criterion. Analysis of method pathways reveals that agents succeed primarily through methodological translation, converting scientific tasks into familiar supervised prediction problems, rather than through genuine scientific invention. Failures are dominated by wrong method choice and insufficient compute budget, not by task misunderstanding. We release the benchmark, the NatureGym pipeline, and a public leaderboard with maintainer-side reproduction. Code: https://github.com/FrontisAI/NatureBench
One-sentence Summary
NatureBench is a benchmark of 90 tasks distilled from Nature-family publications that leverages the automated NatureGym pipeline to construct standardized containerized environments, and evaluations of ten frontier agent configurations under a web-search-disabled protocol reveal that models succeed primarily through methodological translation rather than genuine invention, with the strongest system surpassing published SOTA on only 17.8% of tasks under the g > 0.1 criterion.
Key Contributions
- This work introduces NatureBench, a cross-disciplinary benchmark of 90 tasks distilled from peer-reviewed Nature-family publications to evaluate whether AI coding agents can advance scientific discovery beyond experimental reproduction.
- The study develops NatureGym, an automated pipeline that constructs standardized, per-task containerized environments from source papers to resolve the environment fragmentation that limits prior agent-on-research benchmarks.
- Evaluations of ten frontier agent configurations under a web-search-disabled protocol demonstrate that the strongest models surpass existing baselines on only 17.8% of tasks, with successes driven primarily by methodological translation rather than novel invention.
Introduction
AI coding agents are transitioning from code reproduction to autonomous scientific research, creating an urgent need for evaluation frameworks that measure genuine discovery rather than pattern matching. Prior benchmarks prove insufficient because paper-based evaluations test only reproduction, engineering tasks lack the domain reasoning and cross-disciplinary scope of natural sciences, and environment fragmentation undermines reproducibility. Furthermore, current AI-for-Science systems typically function as accelerators within human-defined programs rather than independent problem solvers capable of cross-domain innovation. To bridge this gap, the authors present NatureBench, a cross-discipline benchmark of 90 tasks derived from peer-reviewed Nature-family publications that challenges agents to surpass state-of-the-art methods through discovery. They leverage NatureGym, an automated pipeline that converts papers into containerized task packages with hidden ground truth and an information firewall, ensuring agents must devise novel solutions rather than rely on source code. This evaluation framework spans six scientific domains and includes a validity judge to detect shortcut behaviors, providing a rigorous test of whether autonomous agents can drive algorithmic progress across the natural sciences.
Dataset
-
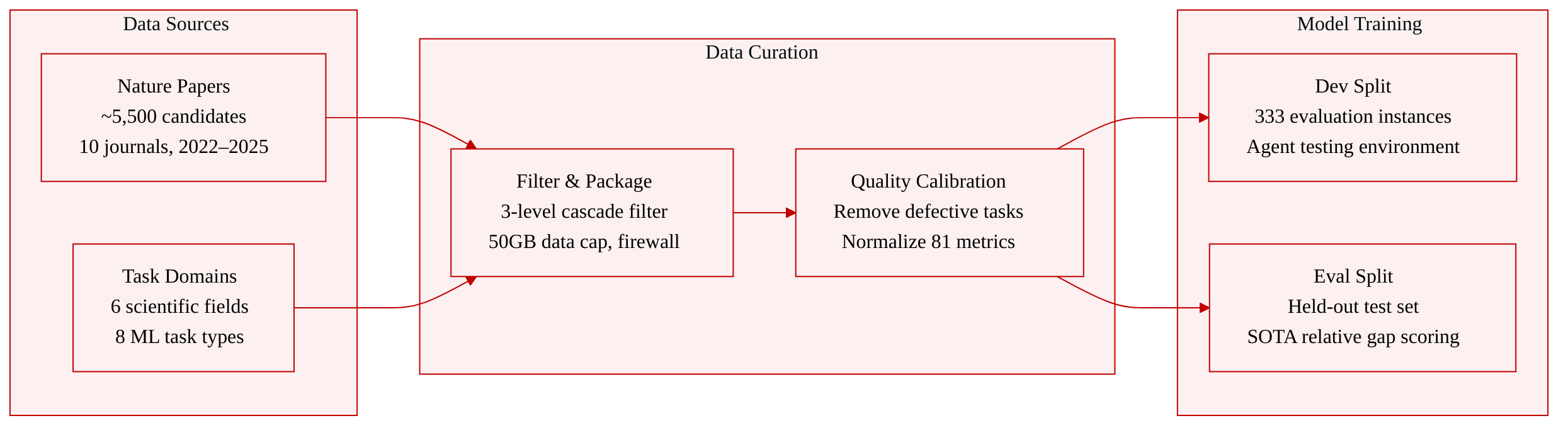
Dataset composition and sources: The authors introduce NatureBench, a cross discipline benchmark comprising 90 tasks distilled from peer reviewed Nature family publications. The source corpus spans six scientific domains and eight machine learning task types, drawn from ten Nature journals published between 2022 and 2025.
-
Key details for each subset: The pipeline filters approximately 5,500 initial candidates through a three level cascade. Level one requires an extractable machine learning task. Level two demands a fully automatable deterministic metric. Level three mandates publicly accessible, complete datasets under 50 GB. The final 90 tasks contain 333 evaluation instances, each split into development and held out evaluation sets containing test inputs and reference answers.
-
How the paper uses the data: The authors use the dataset exclusively for evaluation rather than training, so no training splits or mixture ratios are applied. They test ten frontier AI coding agents inside isolated containerized environments with web search disabled. Each task is scored using a direction normalized relative gap metric that measures performance against the original paper reported state of the art. The benchmark tracks success rates and analyzes failure modes across different scientific domains.
-
Processing and metadata construction: The NatureGym pipeline converts each paper into a standardized task package represented as a structured tuple. A strict file level firewall withholds the original algorithm while retaining only task defining inputs and shared data preparation files. Metadata accumulates across automated review stages, and a final quality calibration step removes defective tasks and repairs scoring inconsistencies. The evaluation protocol normalizes 81 distinct metrics onto a common scale and employs a post hoc validity judge to filter invalid submissions.
Experiment
The evaluation framework tests ten frontier coding agents on ninety scientific tasks using an isolated execution environment with a fixed time budget and a standardized protocol that normalizes performance against published baselines while filtering out shortcut behaviors. This setup validates how closely autonomous agents can approach existing scientific benchmarks and identifies the underlying mechanisms driving their successes and failures. Qualitative analysis reveals that matching existing benchmarks remains rare, as agents predominantly succeed by translating complex scientific problems into generic machine learning pipelines rather than leveraging domain-specific reasoning. Most performance gaps originate from suboptimal method selection or insufficient execution depth constrained by computational limits, highlighting that interdisciplinary integration and deep methodological alignment remain significant bottlenecks for current models.
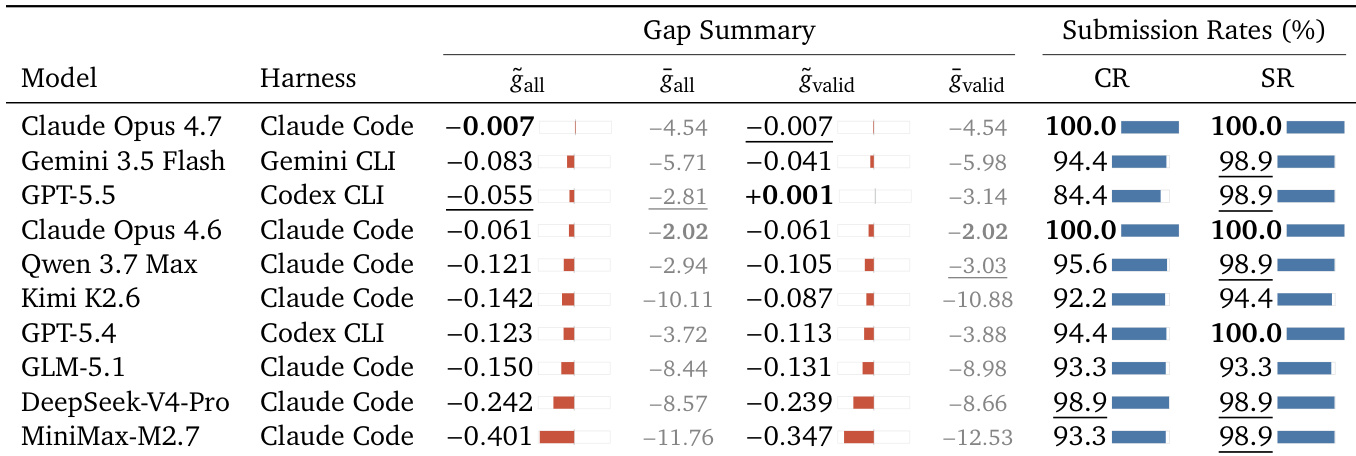
The authors evaluate ten coding agents on the NatureBench benchmark to assess how closely they can replicate published state-of-the-art results. The results indicate that matching or surpassing SOTA is difficult for all models, with the best-performing agent only matching the benchmark on a minority of tasks. While most agents achieve high submission and completion rates, there is a significant performance gap between the top models and the weaker ones, with the latter showing much larger deficits relative to the SOTA targets. Claude Opus 4.7 demonstrates the strongest performance, achieving the smallest median gap relative to the SOTA and maintaining a perfect completion and submission rate. Most agents struggle to reach the published SOTA, with the median performance gap ranging from negligible for top models to substantial for weaker models. GPT-5.5 is the only model to achieve a positive median gap on valid submissions, although it is noted for attempting shortcuts that are filtered by the evaluation judge.
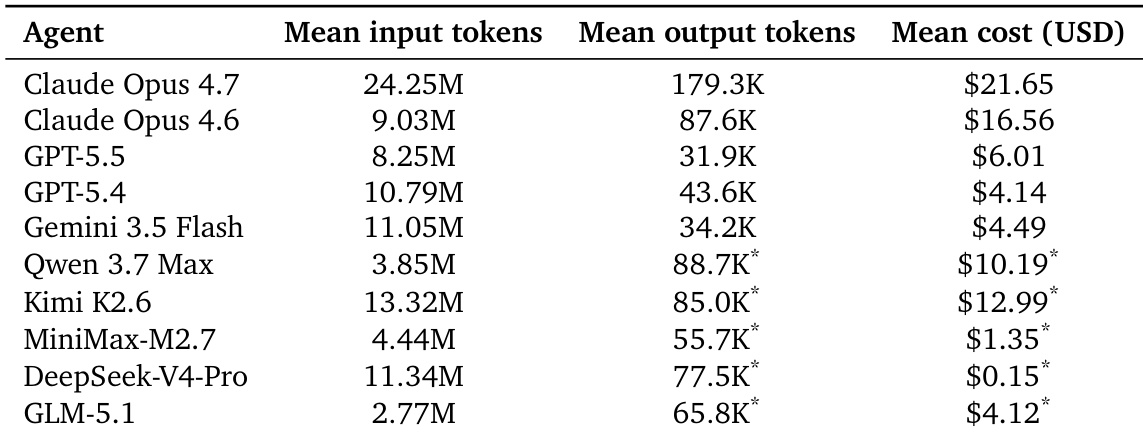
The the the table compares resource consumption and estimated API costs across ten evaluated coding agents. The results indicate significant variation in token usage and financial expenditure, with Claude Opus 4.7 requiring the most input and output tokens and incurring the highest cost. Conversely, models like DeepSeek-V4-Pro and MiniMax-M2.7 demonstrate substantially lower costs despite varying levels of token consumption. Claude Opus 4.7 exhibits the highest resource consumption, requiring the largest volume of input and output tokens among all tested agents. DeepSeek-V4-Pro and MiniMax-M2.7 achieve the lowest estimated costs, offering a more economical alternative to the top-tier models. There is no strict linear relationship between token volume and cost, as some models with moderate usage remain significantly cheaper than others with similar or lower consumption.
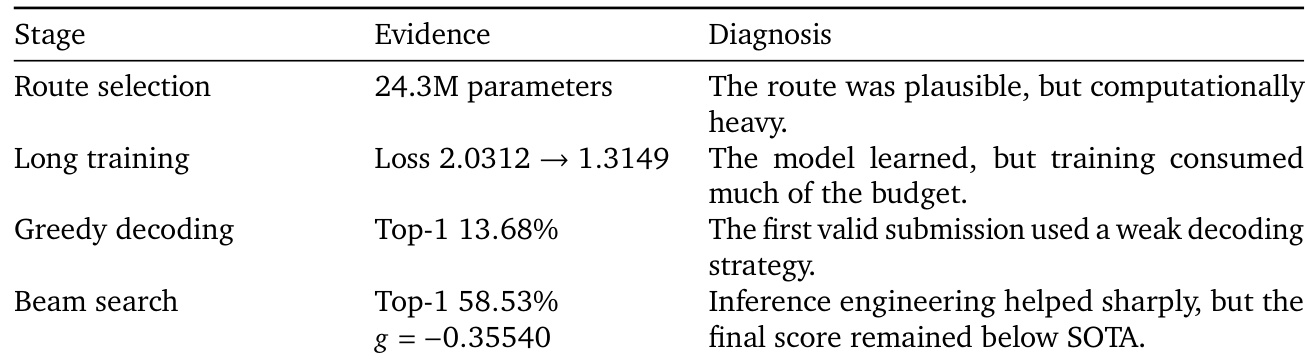
Results from the reaction product prediction case illustrate the agent's iterative refinement process under strict resource constraints. Initial stages revealed that while the selected model architecture was scientifically appropriate, its complexity rapidly exhausted the training budget. Subsequent optimizations to the decoding strategy produced notable performance gains, yet the final output still failed to match the established benchmark. The chosen model architecture proved scientifically sound but demanded excessive computational resources. Prolonged training successfully minimized the loss metric but consumed a disproportionate share of the time budget. Implementing a more advanced decoding technique significantly boosted accuracy, although the final score remained below the state-of-the-art level.
The authors examine three representative agent trajectories to illustrate recurring performance patterns on scientific tasks. These cases reveal that while method-aligned approaches can successfully match benchmarks, valid solutions often fall short due to insufficient model capacity or execution depth limitations. Claude Opus 4.7 matched the published SOTA for cancer gene identification by utilizing a graph convolutional network that effectively captured the biological network structure. GPT-5.5 produced a valid but suboptimal solution for genomic sequence prediction, failing to reach the benchmark because its models lacked the inductive bias of large-scale pretraining. DeepSeek-V4-Pro failed to complete the organic reaction prediction task within the time limit, demonstrating that execution depth can be a bottleneck even when the methodological approach is plausible.

The authors evaluate ten frontier coding agents on a scientific benchmark, measuring their ability to match or surpass published state-of-the-art results across multiple disciplines. Overall performance remains limited, with the strongest models successfully matching top-tier results on less than half of the tasks. Performance varies significantly across scientific domains, indicating a clear difficulty gradient shared by all tested agents. Claude Opus 4.7 achieves the highest overall success rates for both surpassing and matching state-of-the-art benchmarks, outperforming all other tested models. Relational reasoning tasks represent the easiest domain, where most agents consistently reach high match rates, whereas biomedical and molecular tasks prove substantially more difficult. Clear improvements over existing scientific results are rare across the board, suggesting that method selection and execution depth remain primary bottlenecks for current AI agents.
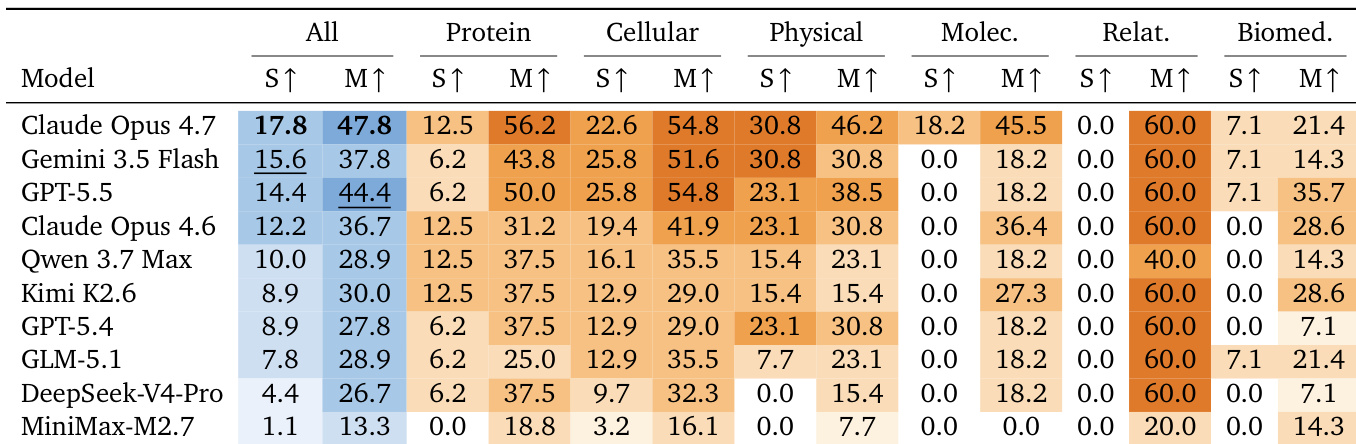
The study evaluates ten frontier coding agents on the NatureBench benchmark to assess their capacity to replicate published state-of-the-art results across diverse scientific disciplines. Performance tracking and resource analysis validate that computational costs and execution depth vary widely without guaranteeing higher accuracy, while trajectory case studies reveal that architectural limitations and insufficient model capacity frequently prevent valid solutions from reaching benchmarks. Ultimately, the experiments demonstrate that methodological alignment alone is insufficient, as current AI agents struggle to surpass existing scientific results with clear improvements remaining rare across all tested domains.