Command Palette
Search for a command to run...
How Robust is OCR-Reasoning? Evaluating OCR-Reasoning Robustness of Vision-Language Models under Visual Perturbations
How Robust is OCR-Reasoning? Evaluating OCR-Reasoning Robustness of Vision-Language Models under Visual Perturbations
Yuxing Cheng Yuan Wu Yi Chang
Abstract
Vision-language models (VLMs) have achieved strong performance on OCR-based benchmarks and increasingly focused on text-rich understanding, but their robustness under controlled visual degradation remains insufficiently understood. This gap is critical for OCR reasoning, where visual corruption can induce OCR errors and structural distortions, thereby introducing uncertainty into the reasoning task. To systematically study this problem, we introduce OCR-Robust, a benchmark designed for evaluating OCR reasoning robustness under visual perturbations. It contains 812 samples across two complementary subsets: OCR1.0, covering documents, scene text, receipts, handwriting, and mathematical content, and OCR2.0, focusing on charts, geometry diagrams, and tables. To enable efficient yet informative evaluation, we conduct a pilot study over 18 candidate perturbations and select 5 representative types at 3 severity levels each based on their impact and cross-model discriminability. We evaluate robustness using clean accuracy, Relative Corruption Retention (RCR), Worst-Case Retention (WCR), and a composite Corruption Robustness Index (CRI), and benchmark 18 models spanning proprietary systems, open-source VLMs, and OCR+LLM pipelines. Our results show that higher clean accuracy does not necessarily imply stronger robustness, and that models can suffer pronounced degradation in the worst case on OCR tasks that are sensitive to structure, and charts and tables are substantially more fragile than document-like inputs under perturbation.
One-sentence Summary
The authors introduce OCR-Robust, a benchmark comprising 812 samples across OCR1.0 and OCR2.0 subsets that systematically evaluates 18 vision-language models under five visual perturbation types at three severity levels using clean accuracy, Relative Corruption Retention, Worst-Case Retention, and the Corruption Robustness Index to quantify robustness in text-rich reasoning.
Key Contributions
- The paper introduces OCR-Robust, a benchmark containing 812 samples divided into OCR1.0 for natural text and OCR2.0 for structured visual content such as charts and tables. This dataset provides a controlled diagnostic setting to systematically evaluate how visual perturbations impact text-rich perception and downstream reasoning.
- A principled perturbation selection pipeline evaluates 18 candidate visual corruptions to identify five discriminative types, each applied at three severity levels. This methodology establishes a reproducible framework for probing model sensitivity under controlled degradation.
- The study develops a robustness metric suite comprising clean accuracy, Relative Corruption Retention (RCR), Worst-Case Retention (WCR), and a composite Corruption Robustness Index (CRI) that aggregates baseline capability, average retention, and worst-case risk. Evaluations across 18 proprietary, open-source, and OCR-plus-LLM models demonstrate how these metrics quantify performance degradation under visual corruption.
Introduction
Vision-Language Models have achieved impressive results on clean benchmarks for document understanding and text recognition, but their reliability often falters in practical applications where images suffer from blur, uneven lighting, or physical distortion. Prior work largely overlooks this gap by focusing evaluations on pristine data or general object recognition, neglecting the specific risk that visual corruption introduces discrete symbolic errors which can severely disrupt downstream reasoning processes. The authors present OCR-Robust, a benchmark designed to systematically evaluate OCR reasoning robustness under visual perturbations, featuring a diverse dataset of natural and structured content, a principled selection of five effective perturbation types, and a suite of metrics including Relative Corruption Retention and Worst-Case Retention to diagnose model vulnerabilities.
Dataset

-
Dataset Composition and Sources The authors introduce OCR-Robust, a benchmark containing 812 samples designed to evaluate OCR reasoning robustness under visual perturbations. The dataset comprises two complementary subsets: OCR1.0 with 482 samples covering documents, scene text, receipts, handwriting, and mathematical content, and OCR2.0 with 330 samples focusing on charts, geometry diagrams, and tables. OCR2.0 draws from ChartVQA, GNS-260K, and TableVQA-Bench. OCR1.0 integrates data from DocVQA, TextVQA, MTWI, SROIE, Screen2Words, M6Doc, OCR-Reasoning, and InfographicVQA, while the math subset is derived from GSM8K and TheoremQA.
-
Subset Details and Construction For OCR2.0, the authors apply visual diversity sampling by extracting ResNet50 features, performing agglomerative clustering with 150 clusters, and selecting samples closest to cluster centroids. OCR1.0 uses direct selection for handwriting samples and VLM-assisted annotation for other subsets. The authors generate reasoning questions using GPT-5.2, Gemini-3-Pro, and Claude-Sonnet-4.5, randomly selecting one model per image, followed by human verification. The math subset is synthetically constructed by converting source questions to free-form answers, rendering images via GPT-4o-image, and filtering with PaddleOCR to ensure character recall exceeds 0.9.
-
Usage and Evaluation Protocol This dataset serves as an evaluation benchmark rather than a training set. The authors assess model performance using a zero-shot evaluation protocol. They apply five perturbations selected from a pilot study of 18 candidates, each applied at three severity levels. The final perturbations include glass blur, color shift, elastic transform, motion blur, and snow. The authors implement perturbations using OpenCV and PIL with fixed random seeds for reproducibility and save perturbed images as PNGs to avoid compression artifacts. Severity calibration during the pilot phase utilized LPIPS distances to ensure perceptual uniformity across perturbation types.
-
Processing and Quality Control The authors enforce strict quality control, including manual review for answer verifiability, OCR necessity, and image-text consistency. They remove near-duplicates using perceptual hashing with a distance threshold of 5. Images must meet a minimum resolution of 224 by 224 pixels and an RMS contrast threshold greater than 15. For diversity sampling, images are pre-processed by resizing to 256 pixels and center-cropping to 224 pixels before feature extraction. The authors also filter synthetic math samples based on PaddleOCR character recall to maintain textual fidelity.
Method
The evaluation protocol begins with a rigorous answer normalization step to ensure consistent comparison between ground-truth and predicted responses. Both answers undergo a standardization process that involves converting text to lowercase, removing punctuation (with exceptions for decimal points and currency symbols), stripping leading and trailing whitespace, and collapsing multiple spaces into a single space. Following normalization, the system attempts a direct exact match.
For cases where exact matching fails—excluding multiple-choice questions—the protocol employs a fallback mechanism utilizing GPT-4o as a semantic judge. This approach is particularly useful for free-form answers where phrasing may vary despite preserving the underlying meaning. To verify the reliability of this automated judgment, the authors conducted a manual review of 367 instances where GPT-4o was invoked. The results demonstrated high stability, with a 99.18% agreement rate between GPT-4o and human annotators, yielding Cohen’s κ scores of 0.967 for OCR1.0 and 0.903 for OCR2.0. Only three judgments were found to be inconsistent during manual inspection.
To guide model outputs, the evaluation framework incorporates format hints derived from the specific answer type. These hints are appended uniformly to the prompts. For instance, monetary value questions might include a hint specifying the expected composition, such as "$ + Integer". The general prompt structure integrates the input image, the question text, and the specific format hint, instructing the model to output the answer directly without explanation.
Refer to the prompt template structure below:

As illustrated in the figure above, the prompt template ensures that the model receives clear instructions regarding the expected output format. While format hints may theoretically favor models trained on structured outputs, the authors observed no systematic bias, noting that performance gaps between models of similar architectures remained significant.
Experiment
The OCR-Robust benchmark evaluates closed-source vision-language models, open-source variants, and decoupled OCR-LLM pipelines under controlled visual perturbations to assess their reasoning resilience across natural scenes and structured documents. Results indicate that proprietary systems consistently demonstrate superior worst-case retention, while scaling model capacity or employing chain-of-thought reasoning enhances baseline accuracy without reliably mitigating corruption-induced failures. Additionally, structured visual content proves significantly more vulnerable to degradation than natural text, and modular pipelines remain constrained by optical character extraction bottlenecks rather than downstream reasoning capabilities. These findings establish that robust visual understanding requires dedicated architectural strategies beyond mere scale or prompting, positioning OCR robustness as a distinct evaluation challenge.
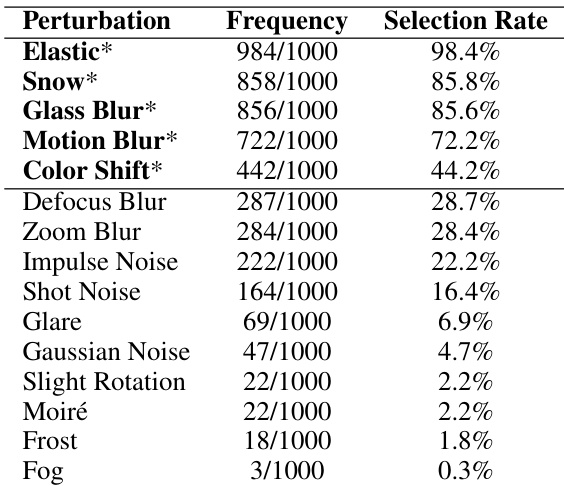
The authors investigate compound perturbations by evaluating triple combinations of visual degradations. The results show that adding multiple perturbation types does not consistently lead to proportionally larger performance drops. Combinations involving color shift and snow exhibit similar performance and sub-additive behavior, while a combination including pixelate achieves higher accuracy but a super-additive degradation ratio. Combinations involving color shift, glass blur, and snow show similar performance and sub-additive degradation ratios. The combination of elastic, glass blur, and pixelate achieves higher accuracy and a super-additive degradation ratio. The findings suggest that overlapping failure modes can limit the cumulative impact of multiple perturbations.

The authors evaluate the robustness of various multimodal language models and OCR pipelines against visual perturbations. The results demonstrate that closed-source systems generally maintain better performance stability under corruption than open-source counterparts. Additionally, the evaluation reveals that models are significantly more sensitive to perturbations affecting structured visual content compared to natural scene text. Closed-source models consistently show lighter colors in the heatmaps, indicating lower relative accuracy drops compared to open-source models. The heatmap for structured content displays darker shades overall, suggesting models suffer greater performance degradation on this type of data. Perturbations like color shift and snow are associated with darker regions across many models, indicating they cause more significant accuracy loss.

The authors conduct a pilot analysis on compound perturbations using GPT-5.1 to examine how multiple visual degradations interact. They evaluate pairwise combinations of five perturbation types and calculate a degradation ratio to determine if the combined effect is additive, sub-additive, or super-additive compared to individual perturbations. The combination of pixelate and snow results in the largest accuracy drop and a super-additive interaction, suggesting that texture damage and occlusion strongly compound each other. Pairs involving weaker perturbations, such as elastic or glass blur combined with others, frequently exhibit sub-additive behavior where the combined impact is less than the sum of individual effects. Combinations like color shift and snow demonstrate near-additive interactions, whereas other pairings show varying degrees of sub-additivity depending on the specific perturbation types involved.
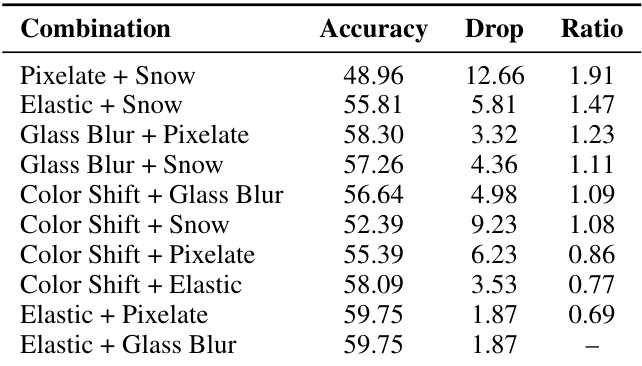
The authors evaluate the effect of Chain of Thought (CoT) prompting versus standard prompting on three open-source vision-language models across two OCR reasoning datasets. The data shows that CoT consistently drives significant improvements in clean accuracy and generally raises the Corruption Robustness Index. However, the influence on specific retention metrics like worst-case and relative corruption retention is inconsistent, particularly on the second dataset, suggesting that extended reasoning primarily strengthens baseline performance rather than uniformly enhancing corruption resilience. Chain of Thought prompting consistently yields higher clean accuracy across all models and datasets compared to standard prompting. The Corruption Robustness Index typically improves with CoT, although worst-case retention benefits are not guaranteed for every model-dataset pair. Performance gains from CoT are more stable on the first dataset, while the second dataset reveals greater variability in retention metrics despite accuracy improvements.
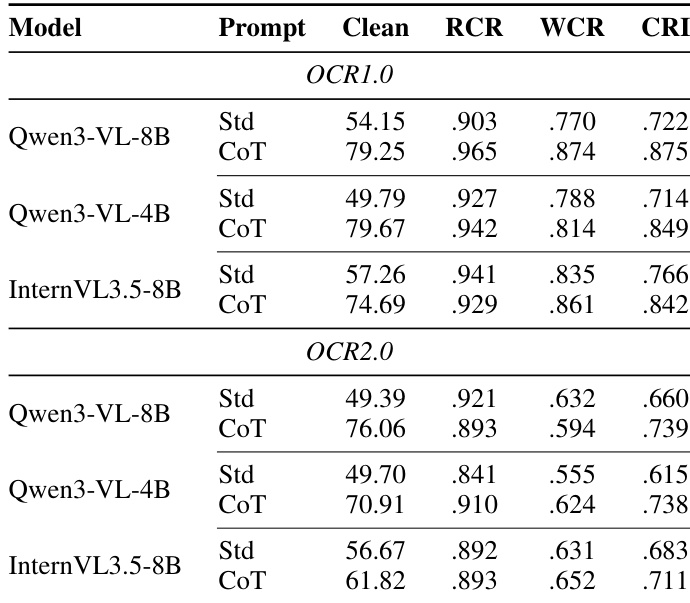
The authors conducted a bootstrap stability analysis to assess the reliability of their perturbation selection by resampling pilot questions one thousand times. The the the table displays the frequency and selection rate for each candidate perturbation across these resamples. The data confirms that the final five perturbations were consistently chosen more often than other candidates, validating the experimental setup. Elastic deformation was selected most frequently, appearing in the vast majority of resampling iterations. The five perturbations marked as final selections consistently outperformed alternatives like defocus blur and various noise types. Color shift had a notably lower selection frequency compared to the top-ranked perturbations, suggesting it is less dominant in the selection criteria.
The experiments evaluate the robustness of multimodal and OCR models against single, pairwise, and triple visual perturbations, assess the impact of Chain of Thought prompting, and validate perturbation selection through bootstrap resampling. Results demonstrate that closed-source systems generally maintain greater stability than open-source models, particularly when processing structured visual content, while compound degradations rarely cause proportionally larger performance drops due to overlapping failure modes. Furthermore, Chain of Thought prompting consistently improves baseline accuracy and general robustness but does not uniformly enhance worst-case corruption retention, and the final perturbation suite shows high selection consistency across resampling trials, confirming the reliability of the experimental design.