Command Palette
Search for a command to run...
OPEN-SWE-TRACES: Advancing Dual-Mode Multilingual Distillation for Software Engineering Agents
OPEN-SWE-TRACES: Advancing Dual-Mode Multilingual Distillation for Software Engineering Agents
Wasi Uddin Ahmad Nikolai Ludwig Somshubra Majumdar Boris Ginsburg
Abstract
The path toward autonomous software engineering is currently bottlenecked by a severe deficit of diverse, large-scale trajectory data. We address this by introducing OPEN-SWE-TRACES, an expansive dataset of 207,489 agentic trajectories spanning nine programming languages (Python, Go, TS, JS, Rust, Java, PHP, C, C++). Sourced from 20,000 real-world PRs via OpenHands and SWE-agent harnesses, the dataset utilizes a hybrid-reasoning synthesis: Minimax-M2.5 generates trajectories with explicit "thinking" processes, while Qwen3.5-122B provides high-quality "non-thinking" traces. Filtered for permissive licenses (MIT, Apache, BSD) from SWE-rebench-V2, this data facilitates the training of models capable of long-horizon reasoning. We validate the dataset by fine-tuning the Qwen3-30B-A3B series (Thinking, Coder, and Instruct). The best performing model achieves resolve rates of 61.7% on SWE-bench Verified, 57.1% on SWE-bench Multilingual, and 36.8% on SWE-bench Pro. These results establish OPEN-SWE-TRACES as a premier resource for distilling human-level software engineering capabilities into efficient, open-source agentic LLMs.
One-sentence Summary
NVIDIA researchers introduce OPEN-SWE-TRACES, a dataset of 207,489 software engineering trajectories spanning Python, Go, TypeScript, JavaScript, Rust, Java, PHP, C, and C++, generated via a hybrid reasoning synthesis where Minimax-M2.5 produces explicit thinking traces and Qwen3.5-122B provides non-thinking traces, and fine-tuning Qwen3-30B-A3B models on this data yields resolve rates of 61.7% on SWE-bench Verified, 57.1% on SWE-bench Multilingual, and 36.8% on SWE-bench Pro, advancing the distillation of autonomous software engineering into efficient open-source agents.
Key Contributions
- OPEN-SWE-TRACES is a dataset of 207,489 agentic trajectories across nine programming languages, synthesized from 20,000 real-world pull requests using Minimax‑M2.5 for thinking traces and Qwen3.5‑122B for non‑thinking traces, and filtered for permissive licenses (MIT, Apache, BSD).
- Fine-tuning Qwen3‑Coder‑30B‑A3B on OPEN-SWE-TRACES yields the OPEN-SWE-AGENT model, achieving resolve rates of 61.7% on SWE‑bench Verified, 57.1% on SWE‑bench Multilingual, and 36.8% on SWE‑bench Pro.
- An empirical study isolates the drivers of agentic performance by evaluating base model selection, data filtering (resolved-only versus all trajectories), and multilingual versus Python‑only distillation; it further analyzes trade‑offs between thinking and non‑thinking modalities and demonstrates generalization to unseen execution harnesses.
Introduction
The expanding capabilities of LLM-driven agents have reshaped software engineering, allowing systems to autonomously resolve real-world bugs across entire code repositories, a trend now measured by multilingual benchmarks. A major bottleneck has been the scarcity of large-scale interaction traces and pre-built executable environments needed to train these agents effectively, creating a gap between increasingly diverse evaluation suites and practical model development. The authors bridge this gap by releasing OPEN-SWE-TRACES, a corpus of 207,489 synthesized agent trajectories in nine languages, uniquely designed for dual-mode distillation with separate “thinking” and “non-thinking” traces. They validate the dataset by fine-tuning an open-source agent that reaches state-of-the-art resolve rates on SWE-bench Verified (61.7%), Multilingual (57.1%), and Pro (36.8%) benchmarks.
Dataset
The authors construct OPEN-SWE-TRACES, a collection of 207,489 agentic trajectories derived from 20,000 real-world pull requests across nine programming languages (Python, Go, TypeScript, JavaScript, Rust, Java, PHP, C, C++). The data is built from repositories in SWE-rebench-V2 that carry permissive licenses (MIT, Apache-2.0, BSD) and is intended for distilling software engineering capabilities into open-source models.
Dataset composition and key details
- Trajectories are generated by two agent harnesses: OpenHands (50.8% of the corpus) and SWE-agent.
- A hybrid-reasoning synthesis is used: MiniMax-M2.5 produces “thinking” traces with explicit chain-of-thought, while Qwen3.5-122B supplies “non-thinking” traces.
- 51.7% of the trajectories include internal reasoning content from MiniMax-M2.5.
- Language distribution is roughly balanced; the largest shares are Python (23.2%), Go (22.6%), TypeScript (17.8%), and JavaScript (14.2%).
- About 40.6% of the generated patches (65,244 trajectories) were verified to resolve the underlying issues via unit tests.
Filtering and processing pipeline
- Stage 1 – Execution aggregation and runtime validation: Heterogeneous interaction logs from the two frameworks are unified into a consistent format, and corrupted or uncompleted traces (e.g., environment exceptions) are discarded.
- Stage 2 – Behavioral pruning and schema standardization: The authors remove trajectories that hit the maximum iteration limit, produce empty patches, alter the test suite instead of fixing the bug, or exhibit malformed tool interactions (illegal concurrent calls, repeated tool errors). The surviving high-fidelity logs are then standardized into role, content, and tool_calls fields, while preserving the reasoning_content from MiniMax-M2.5 traces.
- Post-hoc Git hacking detection: A TrajectoryScanner uses AST parsing to identify and prune trajectories that use banned commands (e.g., reflog, blame) or restricted commands (log, diff) in unsafe ways, eliminating shortcuts that leak repository metadata.
How the data is used in the paper The full corpus serves as the training set to fine-tune all three variants of the Qwen3-30B-A3B series: Thinking, Coder, and Instruct. The authors leverage the mixture of thinking and non-thinking trajectories without an explicit train/validation split, using the unified schema to teach both long-horizon chain-of-thought reasoning and direct code editing behaviors.
Method
The authors leveragea comprehensive pipeline to construct the Open-SWE-Traces dataset, integrating diverse sources, LLM-powered synthesis, rigorous filtering, and trust and safety checks to produce a high-quality corpus for software engineering tasks.
As shown in the figure below:
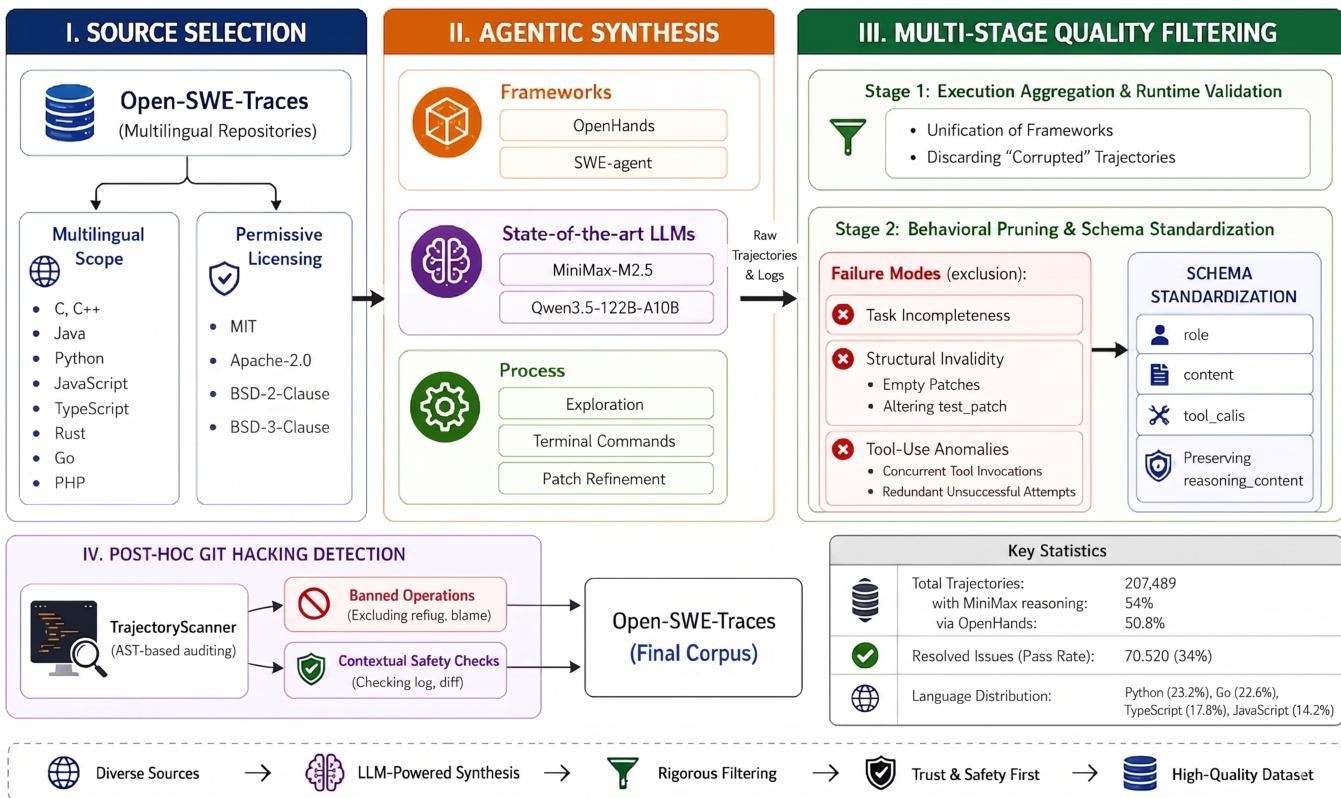
The framework initiates with Source Selection, drawing from multilingual repositories. The authors filter these repositories based on a multilingual scope covering languages such as C, C++, Java, Python, JavaScript, TypeScript, Rust, Go, and PHP, alongside permissive licensing requirements including MIT, Apache-2.0, BSD-2-Clause, and BSD-3-Clause.
In the Agentic Synthesis phase, the authors utilize state-of-the-art LLMs, specifically MiniMax-M2.5 and Qwen3.5-122B-A10B, integrated within frameworks like OpenHands and SWE-agent. The synthesis process encompasses exploration, terminal command execution, and patch refinement to generate raw trajectories and logs.
Subsequently, a Multi-Stage Quality Filtering mechanism refines the data. Stage 1 performs Execution Aggregation and Runtime Validation by unifying frameworks and discarding corrupted trajectories. Stage 2 applies Behavioral Pruning and Schema Standardization. This stage excludes specific failure modes, including task incompleteness, structural invalidity such as empty patches or altering test patches, and tool-use anomalies like concurrent tool invocations or redundant unsuccessful attempts. The surviving data is standardized into a schema defining roles, content, and tool calls while preserving reasoning content.
Finally, the pipeline employs Post-Hoc Git Hacking Detection via TrajectoryScanner, which conducts AST-based auditing. This module enforces banned operations and performs contextual safety checks by examining logs and diffs. The resulting Open-SWE-Traces final corpus contains 207,489 total trajectories, with 54% utilizing MiniMax reasoning and 50.8% generated via OpenHands, achieving a 34% resolved issue pass rate.
Experiment
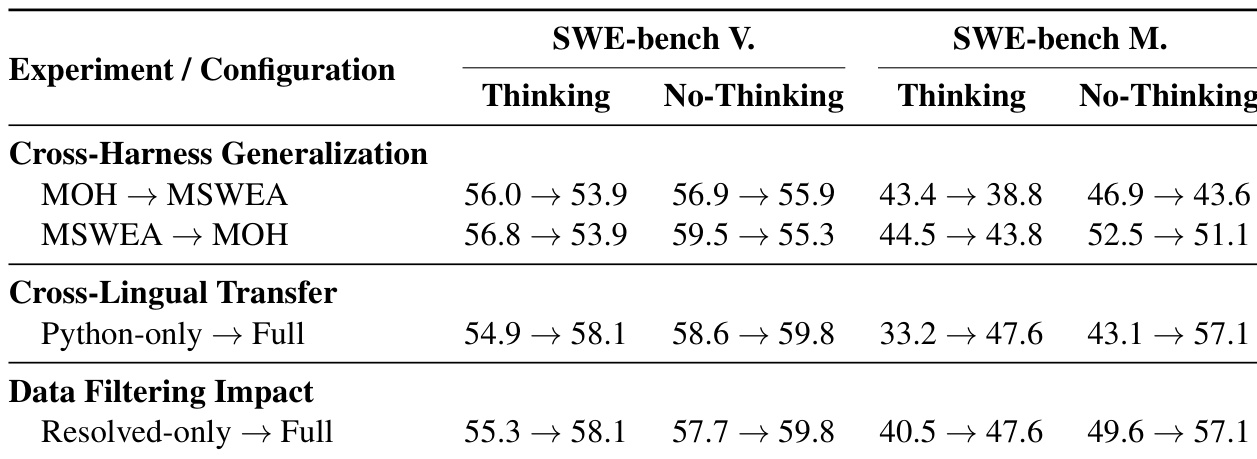
The evaluation employs MOpenHands and MSWE-agent scaffolds to test distilled OPEN-SWE-AGENT models on monolingual and multilingual SWE-bench benchmarks, confirming that distilling trajectories from a heterogeneous set of teacher agents yields strong improvements over base models. Ablations reveal that incorporating multilingual data and including unresolved trajectories are the key drivers of performance, while switching agent harnesses causes consistent degradation due to overfitting to interaction patterns, and the think mode underperforms without sufficient training. The overall performance is ultimately constrained by inherited teacher biases and the stochastic nature of execution environments.
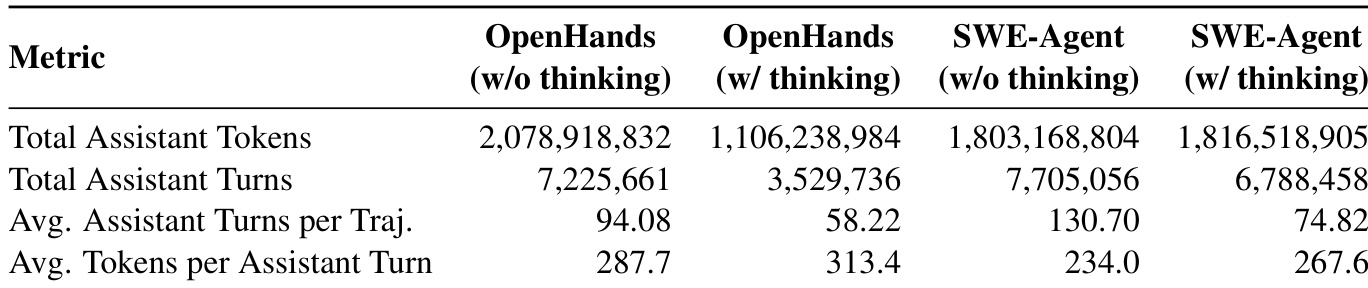
The the the table presents operational metrics for the OpenHands and SWE-Agent frameworks, comparing usage statistics with and without a thinking mode. Enabling the thinking mode consistently reduces the average number of assistant turns per trajectory and the total number of turns across both environments. While the thinking mode leads to longer individual turns in terms of token count, it generally streamlines the interaction process by requiring fewer steps to complete tasks. Enabling the thinking mode significantly lowers the average number of assistant turns per trajectory for both OpenHands and SWE-Agent. The SWE-Agent framework demonstrates a higher average turn count per trajectory than OpenHands when the thinking mode is disabled. Activating the thinking mode increases the average tokens per assistant turn, suggesting more comprehensive responses per step.
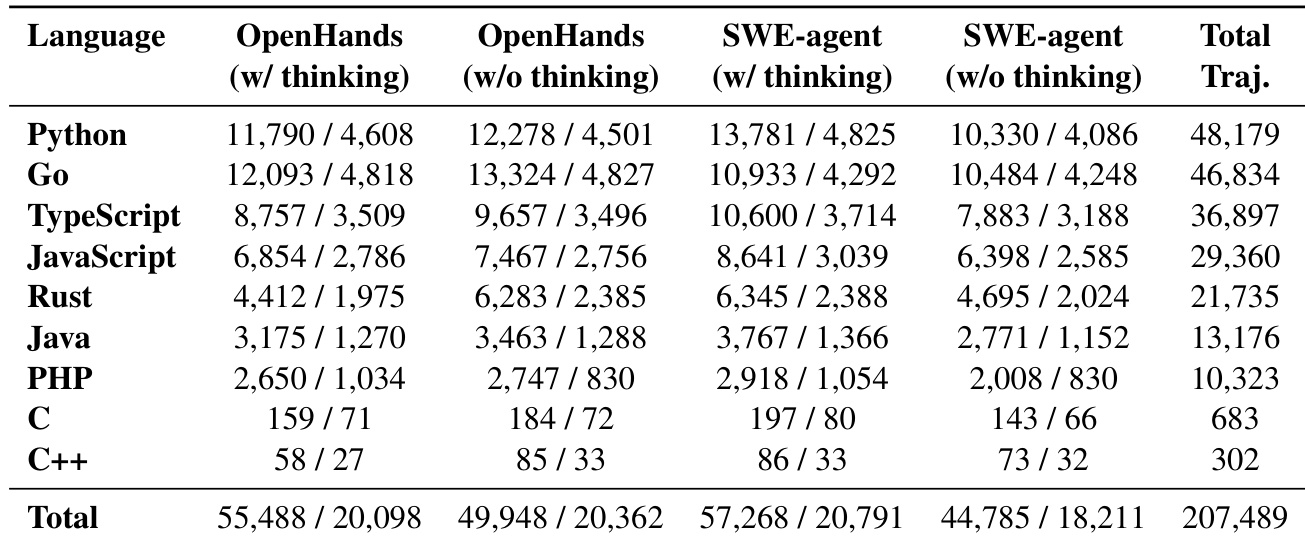
The authors constructed a large-scale multilingual trajectory dataset by deploying diverse LLMs across OpenHands and SWE-agent frameworks to capture varied reasoning strategies. The dataset is heavily skewed towards high-level languages like Python, Go, and TypeScript, which make up the majority of the collected traces. Conversely, lower-level systems languages such as C and C++ are minimally represented, reflecting the distribution of tasks in the underlying benchmarks. The dataset primarily consists of trajectories for Python, Go, and TypeScript, which significantly outnumber those for other languages. Trajectories are generated across both OpenHands and SWE-agent frameworks in thinking and non-thinking modes to ensure diverse agent behaviors. Languages like C and C++ have minimal representation in the dataset, likely due to fewer available tasks in the source benchmarks.
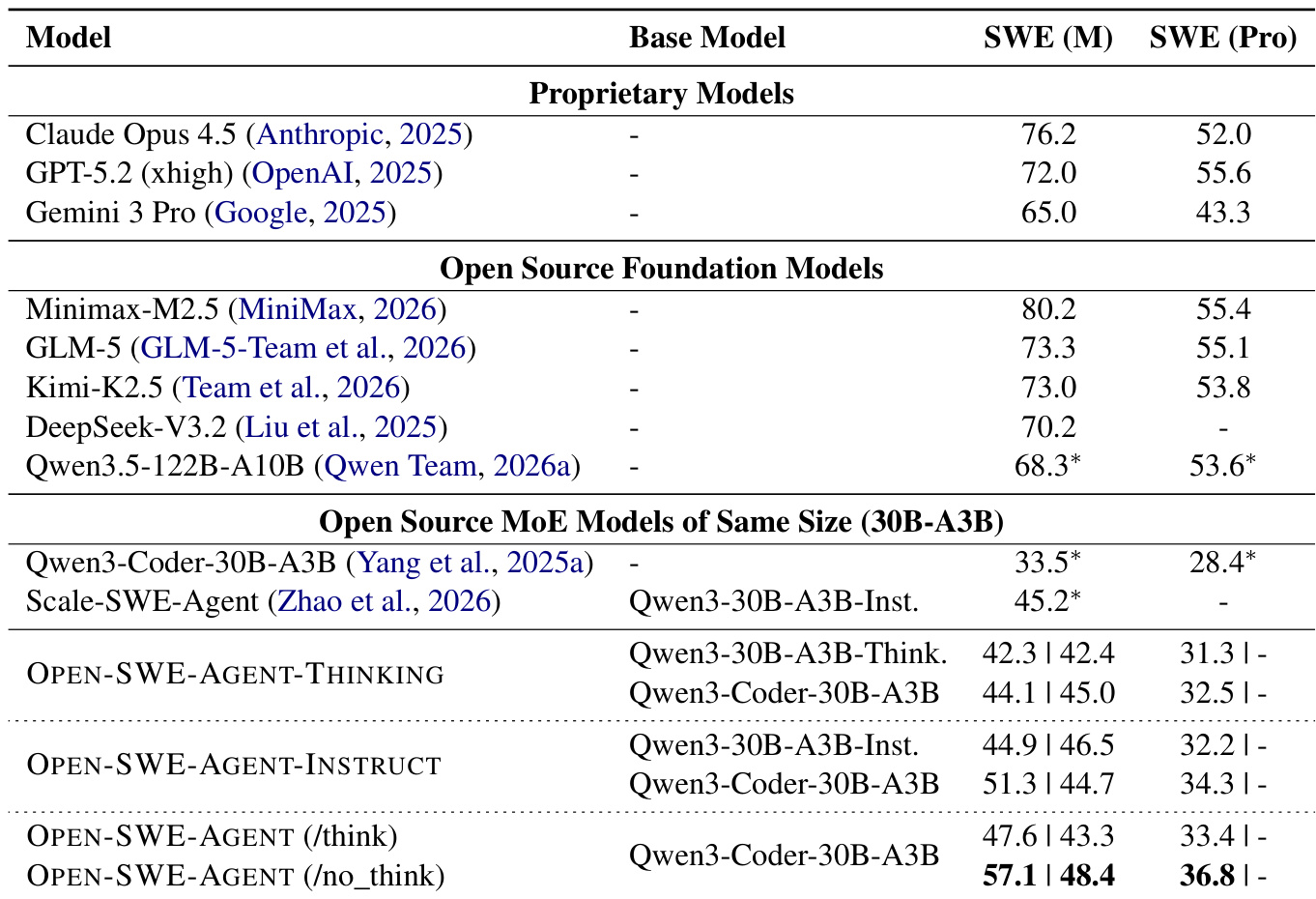
The authors evaluate their distilled OPEN-SWE-AGENT models on multilingual and professional software engineering benchmarks, comparing them against proprietary models, open-source foundation models, and same-size open-source MoE models. Results show that the distilled agents achieve substantial performance gains over their base models, with the no-think variant demonstrating particularly strong improvements across both multilingual and professional tasks. The distilled OPEN-SWE-AGENT models significantly outperform their base models and other same-size open-source MoE baselines on multilingual and professional coding benchmarks. The no-think configuration of the main agent achieves the highest performance among the open-source MoE models, surpassing the thinking variant on both evaluated benchmarks. While proprietary models still lead in absolute performance, the proposed open-source agents close the gap considerably through effective trajectory distillation.
The authors evaluate how training configurations influence agentic capabilities across different environments and modalities. Results indicate that switching agent frameworks incurs a consistent performance penalty, though models trained on one framework generalize better to the other depending on the direction. Furthermore, expanding training data from Python-only to full multilingual corpora and including unresolved trajectories yields significant performance improvements across both monolingual and multilingual benchmarks. Models trained on the MSWEA framework demonstrate greater stability and smaller performance drops when transferred to the MOH harness compared to the reverse direction. Transitioning from a Python-only training set to a full multilingual dataset provides substantial gains, particularly for non-Python tasks in the no-thinking mode. Including unresolved trajectories in the training corpus consistently outperforms using only resolved samples, helping models navigate complex states across all benchmarks.
The authors evaluate their distilled OPEN-SWE-AGENT models against various proprietary, foundation, and specialized open-source models on a software engineering benchmark. The results show that while proprietary and top foundation models lead in performance, the proposed distilled agents achieve competitive results among open-source models of similar size. The distillation process yields significant improvements over the base models, with the no-think configuration generally outperforming the think variant. Proprietary models and leading open-source foundation models achieve the highest resolution rates, outperforming most specialized open-source models. The distilled OPEN-SWE-AGENT variants show substantial performance gains over their base models, demonstrating the effectiveness of the training approach. Among open-source models of comparable size, the proposed agents perform competitively with top specialized models, particularly in the no-think configuration.

The authors constructed a large multilingual trajectory dataset by running diverse LLMs across OpenHands and SWE-Agent frameworks in both thinking and non-thinking modes, with the data heavily skewed toward high-level languages like Python, Go, and TypeScript. Enabling the thinking mode reduces the number of assistant turns per trajectory but increases the token count per turn, streamlining overall interaction. Distilled OPEN-SWE-AGENT models significantly outperform their base models and other open-source MoE baselines, with the no-think configuration achieving the best results among open-source agents and substantially closing the gap to proprietary models. Incorporating multilingual data and unresolved trajectories was critical to improving robustness, and models trained on the MSWEA framework demonstrated more stable transfer when switching environments.