Command Palette
Search for a command to run...
Qwen-AgentWorld: Language World Models for General Agents
Qwen-AgentWorld: Language World Models for General Agents
Abstract
A world model predicts environment dynamics based on current observations and actions, serving as a core cognitive mechanism for reasoning and planning. In this work, we investigate how world modeling based on language models can further push the boundaries of general agents. (i) We first focus on building foundation models for agentic environment simulation. We introduce Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, the first language world models capable of simulating agentic environments covering 7 domains via long chain-of-thought reasoning. Leveraging more than 10M environment interaction trajectories of 7 domains in real-world environments, we develop Qwen-AgentWorld through a three-stage training pipeline: CPT injects general-purpose world modeling capabilities from the state transition dynamics and augmented professional corpora, SFT activates next-state-prediction reasoning, and RL sharpens simulation fidelity through a tailored framework with hybrid rubric-and-rule rewards. To evaluate language world models, we present AgentWorldBench, a comprehensive benchmark constructed from real-world interactions of 5 frontier models on 9 established benchmarks. Empirical results demonstrate that Qwen-AgentWorld significantly outperforms existing frontier models. (ii) Beyond foundation models, we further investigate two complementary paradigms through which world modeling enhances general agents. First, as a decoupled environment simulator, Qwen-AgentWorld supports scalable and controllable simulation of thousands of real-world environments for agentic RL, yielding gains that surpass real-environment training alone. Second, as a unified agent foundation model, world-model training acts as a highly effective warm-up that improves downstream performance across 7 agentic benchmarks. Code: https://github.com/QwenLM/Qwen-AgentWorld
One-sentence Summary
The authors introduce Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B, language world models trained via a three-stage pipeline (CPT, SFT, and RL) on over 10M trajectories across seven domains to simulate agentic environments through long chain-of-thought reasoning, evaluated on AgentWorldBench across five dimensions, and demonstrated to function as both a scalable simulator for agentic reinforcement learning and an effective foundation model warm-up that significantly outperforms frontier models on downstream benchmarks.
Key Contributions
- Qwen-AgentWorld-35B-A3B and Qwen-AgentWorld-397B-A17B are introduced as the first language world models simulating agentic environments across seven domains via long chain-of-thought reasoning. These models are developed through a three-stage pipeline combining continual pretraining, supervised fine-tuning, and reinforcement learning on over ten million real-world interaction trajectories to optimize next-state prediction and simulation fidelity.
- AgentWorldBench is presented as a comprehensive evaluation framework constructed from real-world interactions of five frontier models across nine established platforms. The benchmark assesses simulation quality through ground-truth grounded rubric judging across five dimensions to establish standardized metrics for language world modeling.
- Two complementary paradigms are demonstrated for enhancing general agents, utilizing the models as either a decoupled simulator for scalable agentic reinforcement learning or a unified foundation model for downstream warm-up. Empirical validation confirms that controllable simulation surpasses real-environment training alone, while cross-domain transfer consistently improves performance across seven agentic benchmarks.
Introduction
World models that predict environment dynamics are widely recognized as a fundamental requirement for general intelligence, yet current large language model agents lack a unified mechanism for simulating text-based environments. Existing approaches often treat world modeling as a secondary task via post-hoc fine-tuning or rely on synthetic code generation, which restricts coverage to programmatically defined domains and fails to capture the complexity of real-world interactions. The authors introduce Qwen-AgentWorld, the first native language world model that simulates seven distinct agentic domains using a three-stage training pipeline comprising continual pre-training, supervised fine-tuning, and reinforcement learning with hybrid rewards. They also release AgentWorldBench for comprehensive evaluation and demonstrate that this model enhances general agents through two complementary strategies: serving as a decoupled simulator for scalable and controllable reinforcement learning and acting as a unified foundation model where next-state prediction serves as an effective warm-up for downstream tasks.
Dataset

Experiment
The evaluation framework utilizes a reference-grounded, five-dimensional rubric calibrated via a double-blind Turing test to assess simulation fidelity, while systematic ablations validate effective solutions for reward collapse, sparse feedback, and policy hacking. Experiments further demonstrate that unifying the agent and world model instills a robust meta-reasoning capability, enabling mental simulation of environment responses before action and consistent generalization to out-of-distribution tasks. Additionally, controlled simulation protocols, including targeted environment adaptation and fictional-world construction, validate the effectiveness of adversarial and self-consistent synthetic training in shaping precise agent behaviors. Collectively, these results establish that high-fidelity environment modeling transforms next-state prediction into a transferable planning mechanism that fundamentally elevates agentic reasoning beyond superficial formatting.
The authors demonstrate that controllable simulation significantly enhances agent training compared to standard reinforcement learning approaches. Results show that adding targeted environment control instructions leads to substantial performance gains across multiple tool-use domains, whereas uncontrolled simulation often yields negligible or inconsistent improvements. These findings highlight that precise simulation control is essential for stabilizing training signals and maximizing capability transfer in complex tool-interaction tasks. Controlled simulation consistently outperforms both base models and uncontrolled reinforcement learning across nearly all evaluated tool-use domains. The most significant improvements occur in database and file-system tasks, indicating that targeted environmental adjustments effectively address complex state-tracking requirements. Uncontrolled reinforcement learning fails to produce meaningful gains and occasionally degrades performance, underscoring the necessity of grounded simulation instructions for stable training.

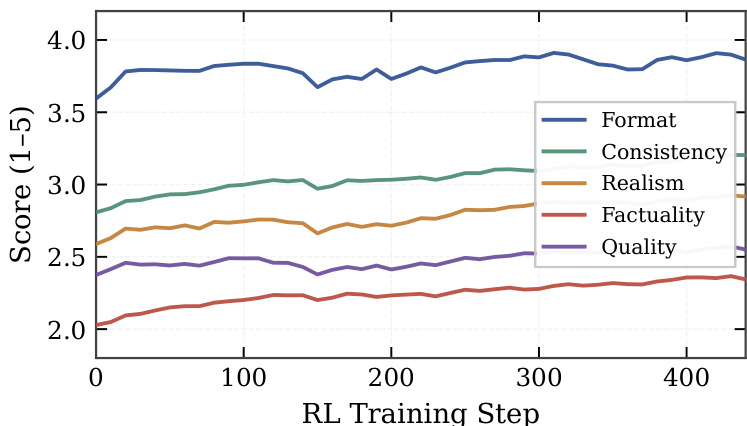
The authors evaluate Qwen-AgentWorld against several frontier proprietary and open-weight models on the AgentWorldBench benchmark. The results demonstrate that the proposed model achieves the highest overall performance, outperforming leading alternatives such as GPT-5.4 and Claude Opus 4.8. The proposed model achieves the highest overall score among all evaluated baselines. Performance surpasses leading proprietary models such as GPT-5.4 and Claude Opus 4.8. The model demonstrates a clear advantage over other open-weight alternatives like DeepSeek V4-Pro and Qwen 3.6-Plus.

The evaluation demonstrates that the proposed world-model training pipeline substantially improves simulation quality across diverse domains. The largest variant achieves top-tier performance in text-based environments such as Terminal and Web, while remaining competitive with leading proprietary models in GUI tasks. Furthermore, the training process enables effective cross-domain generalization, allowing the model to adapt to new environments without additional fine-tuning. World-model training significantly boosts performance over base checkpoints across text and GUI domains. The proposed model leads in text-based benchmarks like Terminal and Web, matching frontier proprietary capabilities. Generalizable environment knowledge allows the model to transfer effectively to out-of-distribution tasks.
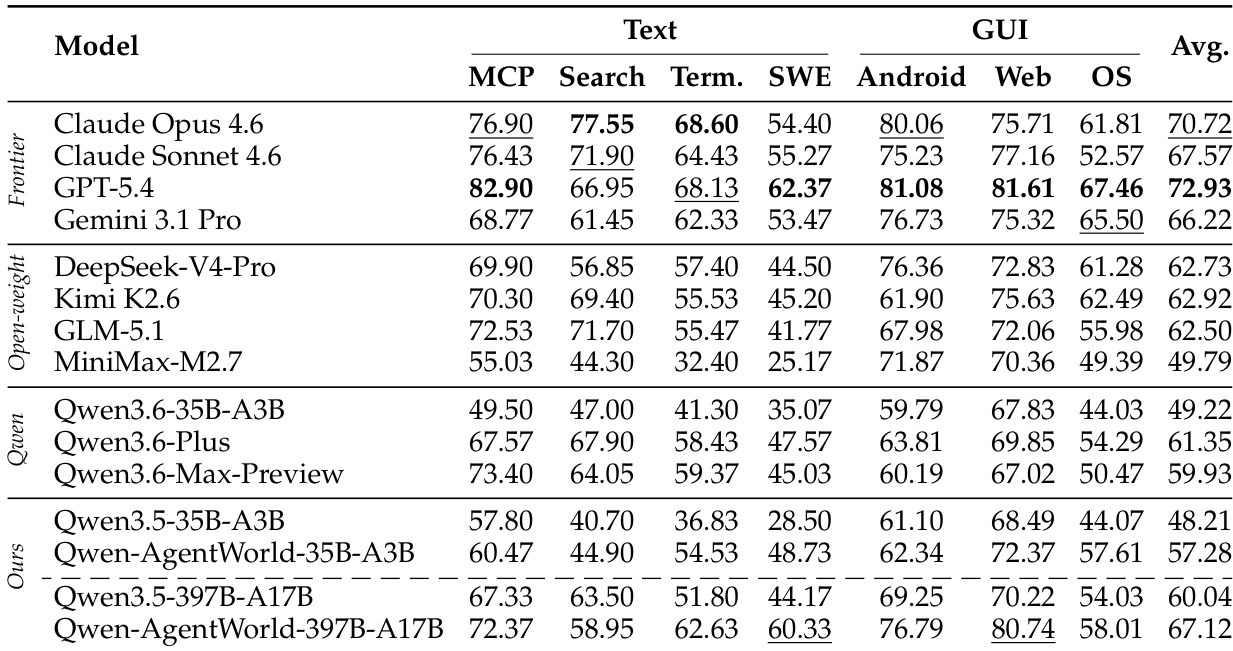
The authors present a breakdown of training data collection and filtering across seven domains, detailing the initial candidate counts, retention percentages, final fine-tuning volumes, and average interaction lengths. The results indicate a moderate overall retention rate, with notable disparities in dataset size and interaction complexity depending on the specific domain. Web and Terminal domains yield the highest number of final training samples, while MCP and SWE contain the smallest pools. Terminal achieves the strongest retention rate among all categories, contrasting with Web, which experiences the lowest percentage of retained data. Interaction length varies considerably, with SWE, Android, and MCP requiring notably more turns per trajectory than Search and Web.
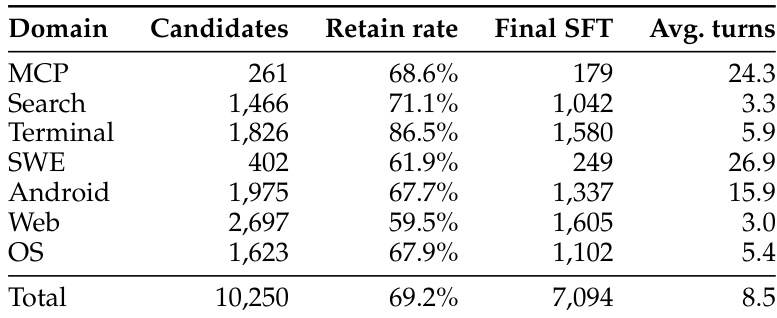
The training dynamics across reinforcement learning steps reveal distinct improvement trajectories for each evaluation dimension. Surface-level formatting conventions converge rapidly, while deeper capabilities like cross-turn consistency and factual accuracy develop more gradually. Despite showing the largest relative gains, factual accuracy consistently remains the lowest-performing dimension throughout the entire training process. Formatting conventions and structural compliance improve most rapidly, reaching near-peak performance early in training. Cross-turn consistency and realism demonstrate steady, gradual gains as the model internalizes complex state-tracking behaviors. Factual accuracy exhibits the highest relative improvement but consistently lags behind all other dimensions, highlighting its difficulty to optimize.
The evaluation compares controllable simulation against standard reinforcement learning across multiple tool-use domains, validating that precise environmental control stabilizes training signals and enables effective capability transfer. Benchmarking against leading proprietary and open-weight models demonstrates the proposed system's superior overall performance and strong generalization across text-based and graphical interfaces. Analysis of training dynamics and data curation reveals that while formatting conventions and structural compliance converge rapidly, deeper capabilities like cross-turn consistency and factual accuracy develop more gradually and remain the most challenging to optimize. Collectively, these findings underscore the necessity of grounded simulation instructions and targeted training pipelines for building robust, state-aware agents.