Command Palette
Search for a command to run...
In-Context World Modeling for Robotic Control
In-Context World Modeling for Robotic Control
Siyin Wang Junhao Shi Senyu Fei Zhaoyang Fu Li Ji Jingjing Gong Xipeng Qiu
Abstract
Modern Vision-Language-Action (VLA) models often fail to generalize to novel setups, such as altered camera viewpoints or robot morphologies, because they are typically conditioned only on current observations and language instructions. By ignoring the underlying system configuration as a variable, these models implicitly assume a fixed execution context encountered during training, necessitating data-intensive fine-tuning for any new environment. In this work, we introduce In-Context World Modeling (ICWM), a framework that treats system identification as an in-context adaptation problem. ICWM enables robot policies to autonomously infer essential system variables from a short history of self-generated, task-agnostic interactions. Unlike traditional In-Context Learning that uses demonstrations to specify what task to perform, ICWM leverages the context window to understand how the system operates. By processing these interactions before task execution, the model implicitly captures the world dynamics of the current system, enabling adaptation to novel configurations without parameter updates. Extensive experiments in simulation and on real-world robot platforms demonstrate that ICWM significantly outperforms standard VLA baselines on novel camera viewpoints.
One-sentence Summary
By treating system identification as in-context adaptation without parameter updates, In-Context World Modeling (ICWM) enables VLA models to infer system variables from a short history of self-generated, task-agnostic interactions, adapting to novel camera viewpoints and robot morphologies and significantly outperforming standard VLA baselines in simulation and real-world experiments.
Key Contributions
- In-Context World Modeling (ICWM) enables vision-language-action policies to infer system configuration from self-generated, task-agnostic interactions, achieving test-time adaptation without parameter updates.
- Unlike conventional in-context learning that specifies what to do, ICWM uses the context window to understand how the system operates, implicitly capturing world dynamics to adapt to novel camera viewpoints, robot morphologies, and semantic scene variations.
- Experiments on simulation benchmarks and real-world robots show that ICWM significantly outperforms standard VLA baselines on novel camera viewpoints and generalizes to other configuration changes, without requiring task-specific demonstrations or reward signals.
Introduction
In robotic manipulation, Vision-Language-Action (VLA) models map visual observations and language commands directly to actions, yet they struggle when deployment conditions such as camera viewpoint or robot morphology change from training. Standard VLA formulations condition only on the current observation, implicitly treating the underlying system configuration as fixed and absorbing it into static model parameters. Prior adaptation strategies rely on task-specific human demonstrations, reward signals, or parameter fine-tuning, leaving no practical mechanism to identify the system dynamics at test time. The authors propose In-Context World Modeling (ICWM), which reframes the problem as a test-time system identification task: the robot autonomously generates a short sequence of task-agnostic exploratory motions and prepends the resulting visual transitions as context, enabling the policy to implicitly recover the current sensory-motor mapping and adapt to novel configurations without parameter updates or human-provided demonstrations.
Dataset
The authors collect a real-world multi‑view manipulation dataset on a 6‑DoF UR5e arm with a Robotiq parallel gripper and a 12‑camera array. The dataset is used to train a vision‑language‑action model with an in‑context system‑identification mechanism.
-
Task coverage and size
Four tasks are included, each recorded with 100–150 human teleoperated demonstrations:
Put the toy on the box into the basket (spatial reasoning and disambiguation),
Stack the yellow cup onto the red cup (fine‑grained alignment),
Lift the basket (handle‑centric structural manipulation),
Pick up the eggplant and place it onto the red plate (multi‑object grounding in clutter).
Every demonstration provides multi‑view RGB streams, end‑effector actions, and a corresponding language instruction. -
Camera split and generalization protocol
The 12 cameras are divided into two equal groups: 6 designated for training, the other 6 held out exclusively for zero‑shot generalization testing. This balanced split forces the model to infer system dynamics from the interaction context rather than memorizing camera‑to‑robot geometries. -
Training data and processing
Training uses all demonstrations from the 6 training cameras, with no explicit task balancing beyond the natural demonstration counts. For each training sample, the authors prepend N task‑agnostic interaction clips to a full demonstration episode. These clips are randomly drawn from a pool of short interaction segments extracted from the complete set of training trajectories across all tasks and viewpoints; the sampling ensures diversity in the interaction context. The model then receives the entire sequence and is optimized with a next‑action prediction loss that conditions on the prepended interaction context, the current observation, and the language instruction. No image cropping or special metadata construction is applied beyond this clip‑prepending step. -
Implicit dynamics signal
Because the interaction clips are drawn from trajectories collected under diverse camera configurations, the variation in the prepended context serves as an implicit training signal: the model must learn to extract the action‑to‑observation mapping that characterizes the current system configuration, enabling zero‑shot adaptation to unseen viewpoints.
Method
The authors propose In-Context World Modeling (ICWM) to address the generalization collapse of standard Vision-Language-Action (VLA) models under out-of-distribution system configurations, such as novel camera viewpoints or robot morphologies. Unlike traditional world models that require dedicated parameters to predict future observations or inverse dynamics, ICWM realizes world modeling implicitly. It leverages standard sequence modeling to extract time-invariant causal structures directly from task-agnostic interaction histories, treating world modeling as an emergent inference capability at test time.
As shown in the figure below, the authors contrast the standard VLA approach with their ICWM method. While current VLAs map observations and instructions directly to actions and fail under viewpoint shifts, ICWM incorporates a self-probing interaction context to adapt to the specific visual and physical setup.
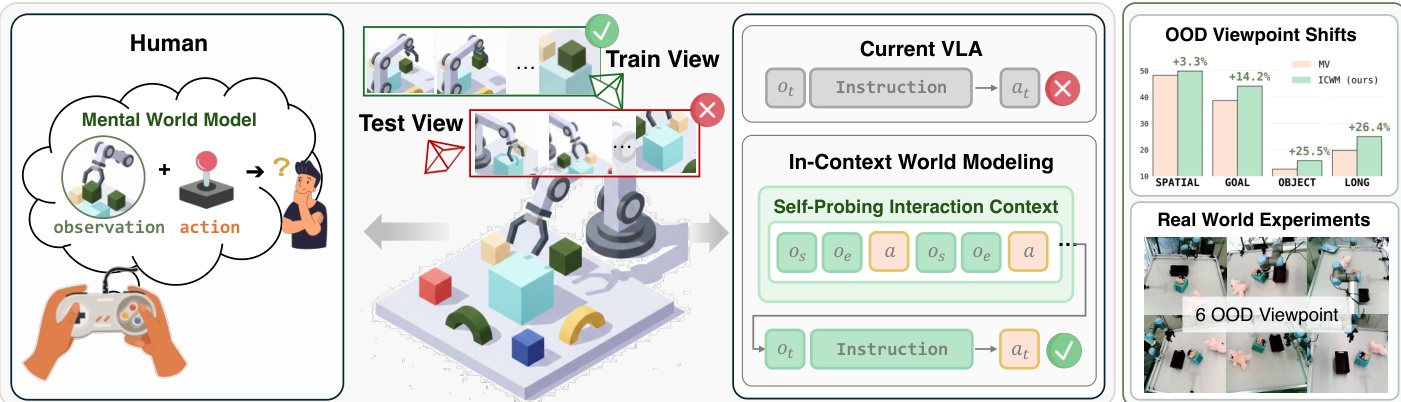
The method is grounded in a Partially Observable Markov Decision Process (POMDP) formulation where the latent state decomposes into a time-invariant system configuration ψ and a time-varying scene state ξk. The authors define the interaction context as T=(o0:t,a1:t) and demonstrate that under mild assumptions of partial observability and information-preserving transitions, this context carries strictly more information about ψ than any single observation. This allows task-agnostic random movements to enrich the information available about the system configuration.
Refer to the framework diagram for a detailed view of the training and inference pipeline.
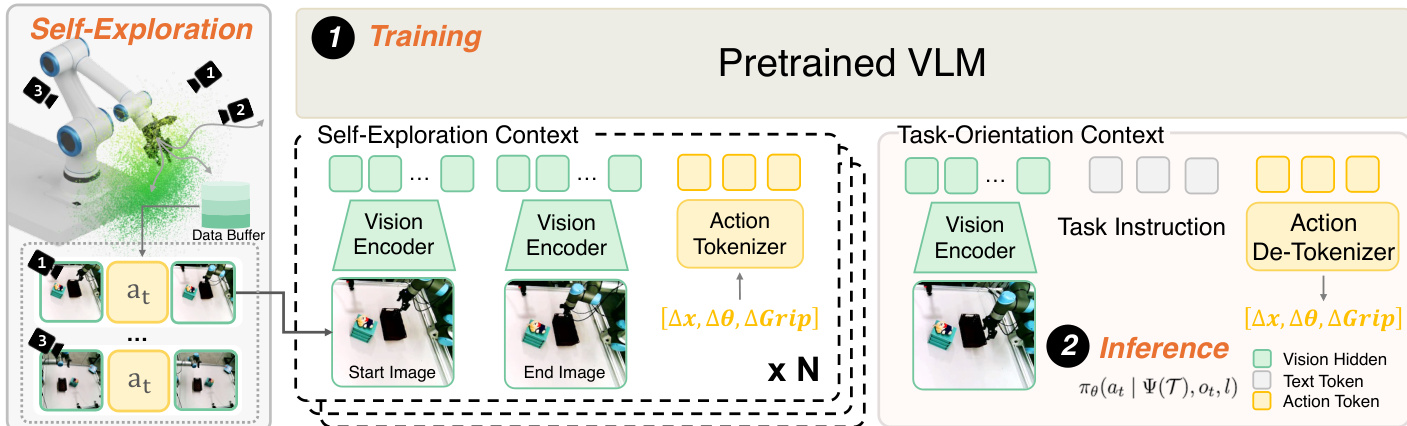
During training, the model is trained on data collected across diverse system configurations. Task-agnostic interaction clips are prepended to each training sample as context. Specifically, given a short history of interaction clips T={(ois,ai,oie)}i=1N, the configuration is inferred implicitly via a function Ψ(T). The policy is reformulated to condition on this inferred representation:
at∼πθ(at∣Ψ(T),ot,l)This interaction-centric conditioning enables the model to interpret the current observation ot within the correct context.
At deployment, ICWM enables demonstration-free adaptation through a two-phase inference protocol requiring no gradient updates.
Active Probing Phase: Before task execution, the robot performs N task-agnostic probing actions to collect the interaction context T. Random target poses are sampled within the safe workspace, and the robot executes actions to reach them, recording the transitions (ois,ai,oie). These movements are spatially diverse to cover the local dynamics manifold without disturbing task-relevant objects.
In-Context Execution Phase: Once T is collected, the configuration inference function Ψ processes the context to recover the latent system configuration. Conditioned on Ψ(T), the current observation ot, and the language instruction l, the policy generates the task action. Since Ψ shares parameters with the VLA backbone, this is implemented as a single forward pass where the Transformer first attends to T to build configuration-aware hidden states before processing the task query.
Experiment
The evaluation employs a cross-view protocol on LIBERO and a real UR5e multi-camera platform, testing in-context world modeling (ICWM) against multi-view behavior cloning and explicit camera parameters under unseen viewpoints, long-horizon tasks, semantic distractions, and modified robot kinematics. Across these settings, ICWM consistently outperforms baselines by using a short interaction prefix to implicitly identify system geometry rather than pattern match; ablations reveal that removing visual outcomes or providing misaligned context severely degrades performance, confirming the model actively conditions on paired observation-action sequences for calibration. The approach also generalizes to distractor objects, novel textures, and morphological changes like varied link lengths, maintaining a stable advantage that grows with kinematic uncertainty, while the interaction format itself, not a specific probing strategy, drives the benefit. Overall, ICWM offers a parameter-free mechanism that grounds actions in the current system dynamics, enabling robust adaptation to diverse distribution shifts.
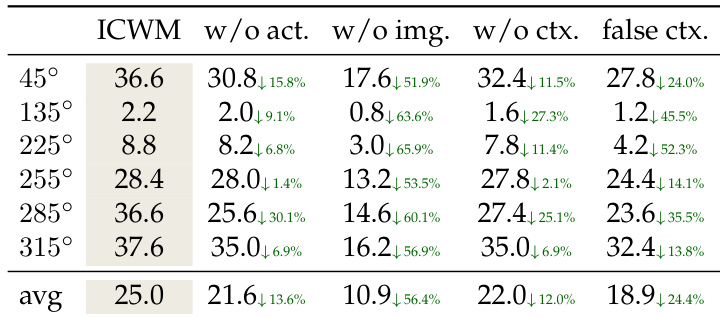
The authors conduct an ablation study on the interaction context components to evaluate their necessity for the In-Context World Modeling approach. Results indicate that removing visual outcomes causes the most severe performance degradation, as the model fails to distinguish exploratory movements from task demonstrations. Furthermore, providing misaligned context from a different viewpoint performs worse than providing no context at all, confirming that the model actively relies on the context content for configuration inference. Removing image tokens causes the largest performance collapse, indicating visual outcomes are critical for grounding actions. False context from an offset viewpoint yields worse results than no context, showing that misaligned information actively misleads the policy. Removing action tokens leads to moderate degradation, suggesting visual flow offers a spatial anchor but full calibration requires the complete observation-action tuple.
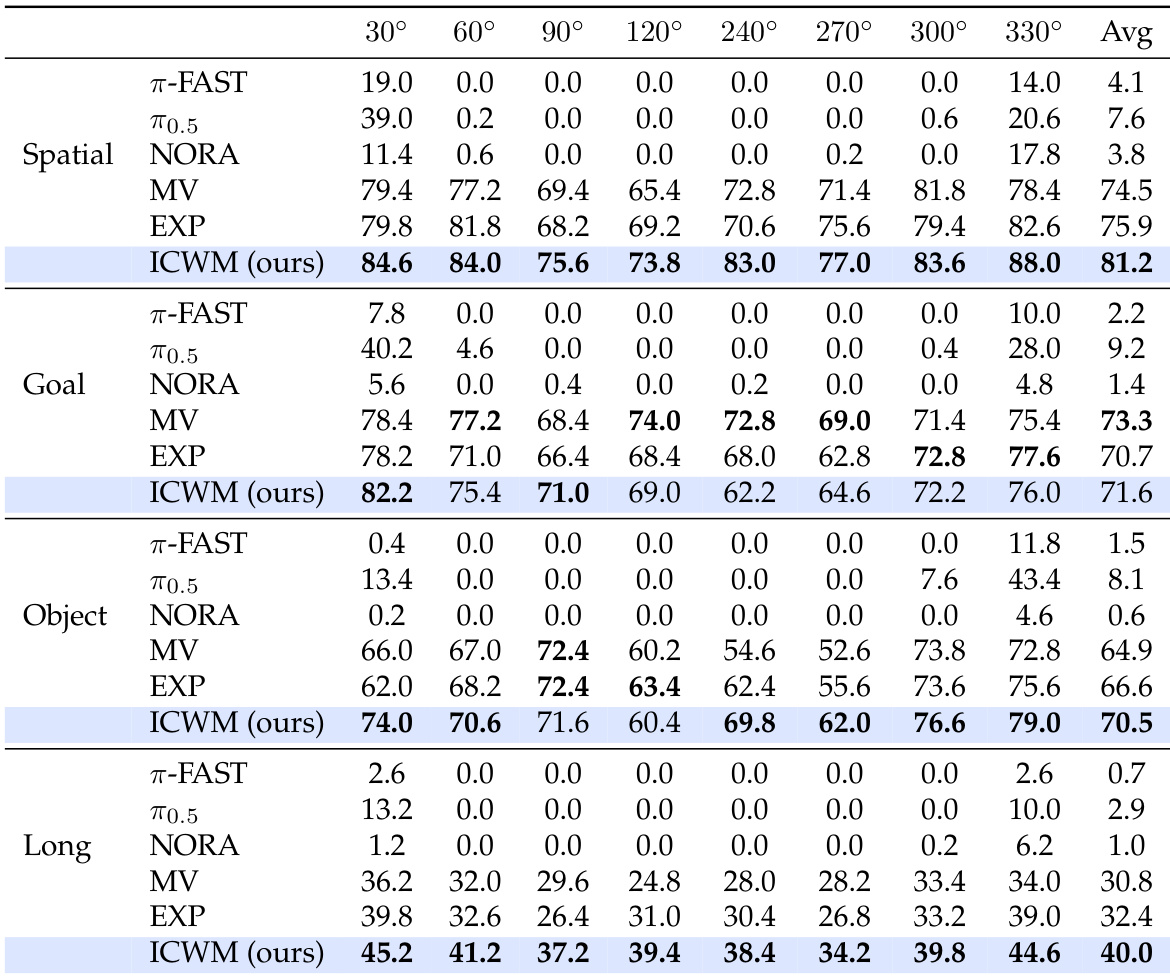
The authors evaluate the In-Context World Modeling approach on out-of-domain viewpoints across four task suites, comparing it against multi-view baselines, explicit configuration methods, and pretrained models. Results show that the proposed method consistently achieves the highest average success rates across all task categories, demonstrating superior generalization to unseen camera angles. While standard multi-view training and explicit angle inputs provide some robustness, they fall short of the performance gained through implicit world modeling via interaction context. The proposed method outperforms all baselines, including multi-view behavior cloning and explicit configuration, in average success rate across all evaluated task suites. Pretrained vision-language-action models struggle significantly with unseen viewpoints, often achieving near-zero success rates compared to the proposed approach. The 135-degree viewpoint presents a common challenge for all evaluated methods due to geometric constraints, though the proposed method still maintains a relative advantage.
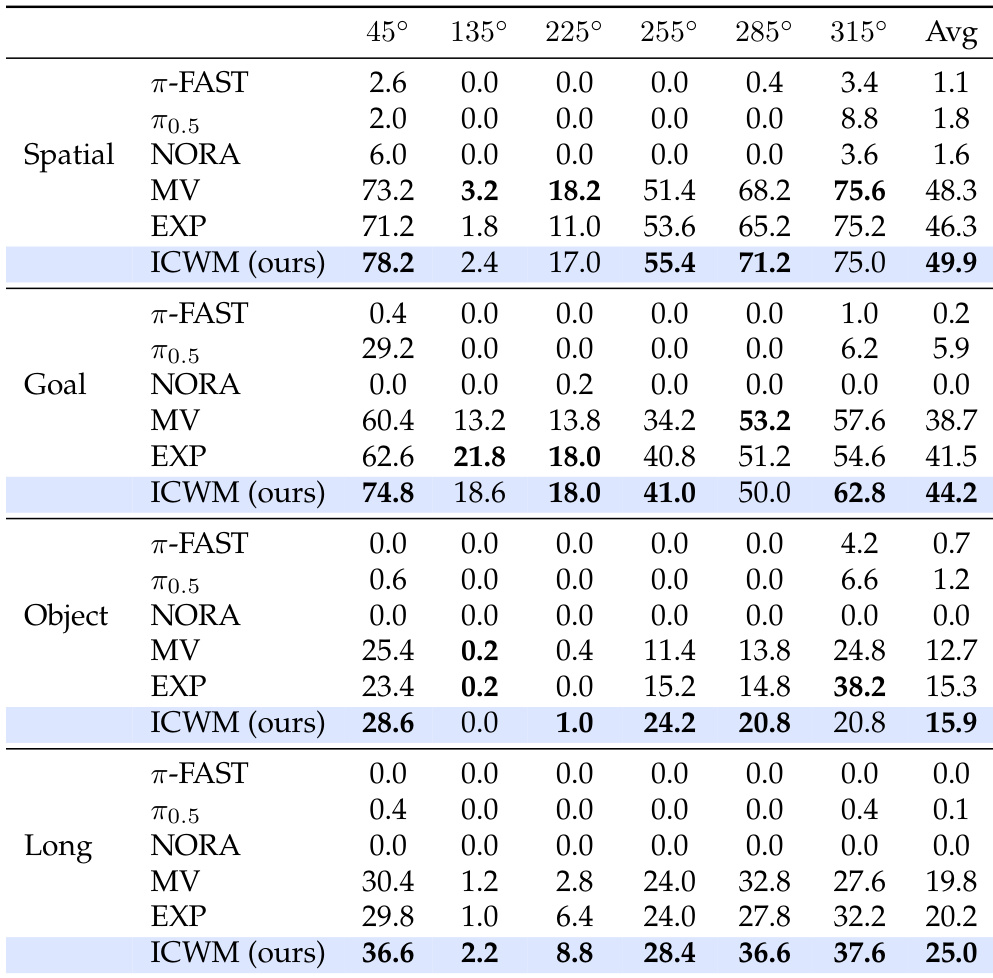
The authors evaluate In-Context World Modeling on in-domain viewpoints across four task suites, comparing it against multi-view baselines, explicit configuration methods, and pretrained models. Results show that the proposed method consistently achieves the highest average success rates across all task categories, demonstrating superior performance over both standard multi-view training and methods augmented with ground-truth camera angles. While all models struggle more with long-horizon tasks, the proposed method maintains a clear lead, whereas pretrained models exhibit near-zero success in many configurations. The proposed method achieves the highest average success rates across all task suites compared to multi-view and explicit configuration baselines. Pretrained models show significantly lower performance than the trained baselines, often failing completely on specific viewpoints. Long-horizon tasks present a greater challenge for all models, yet the proposed method still maintains the best performance margin.
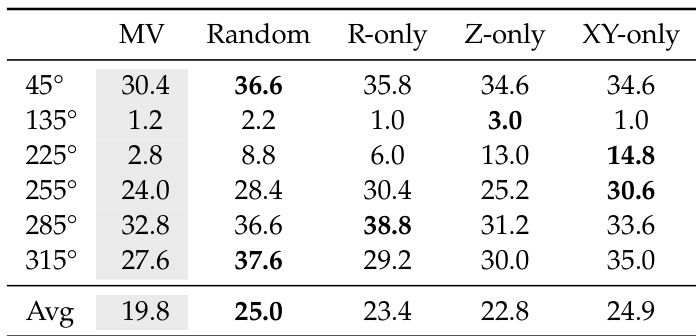
The authors evaluate different probing strategies for In-Context World Modeling on out-of-distribution viewpoints. Results show that all tested strategies significantly outperform the multi-view baseline, indicating that the interaction format itself drives the performance gains rather than specific movement patterns. No single probing strategy dominates across all viewpoints, suggesting different axes reveal different aspects of the local dynamics. All four probing strategies consistently outperform the multi-view baseline across out-of-distribution viewpoints. No single probing strategy dominates across all viewpoints, as different axes expose different aspects of the local dynamics manifold. Random probing yields the highest average performance among the tested strategies.
The authors evaluate In-Context World Modeling through ablation studies on interaction context, viewpoint generalization tests, and probing strategy comparisons. Ablations reveal that visual outcomes are essential for grounding actions and that misaligned context actively misleads the policy. Across both in-domain and out-of-domain viewpoints, the method consistently outperforms multi-view and explicit configuration baselines, with pretrained models often failing completely. Probing experiments show that the interaction format itself drives the performance gains, as all strategies surpass the multi-view baseline without a single dominant pattern.