HyperAI
Command Palette
Search for a command to run...
Papers
Daily updated cutting-edge AI research papers to help you keep up with the latest AI trends

MiA-Signature: Approximating Global Activation for Long-Context Understanding

Continuous Latent Diffusion Language Model



























MiA-Signature: Approximating Global Activation for Long-Context Understanding
Continuous Latent Diffusion Language Model
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
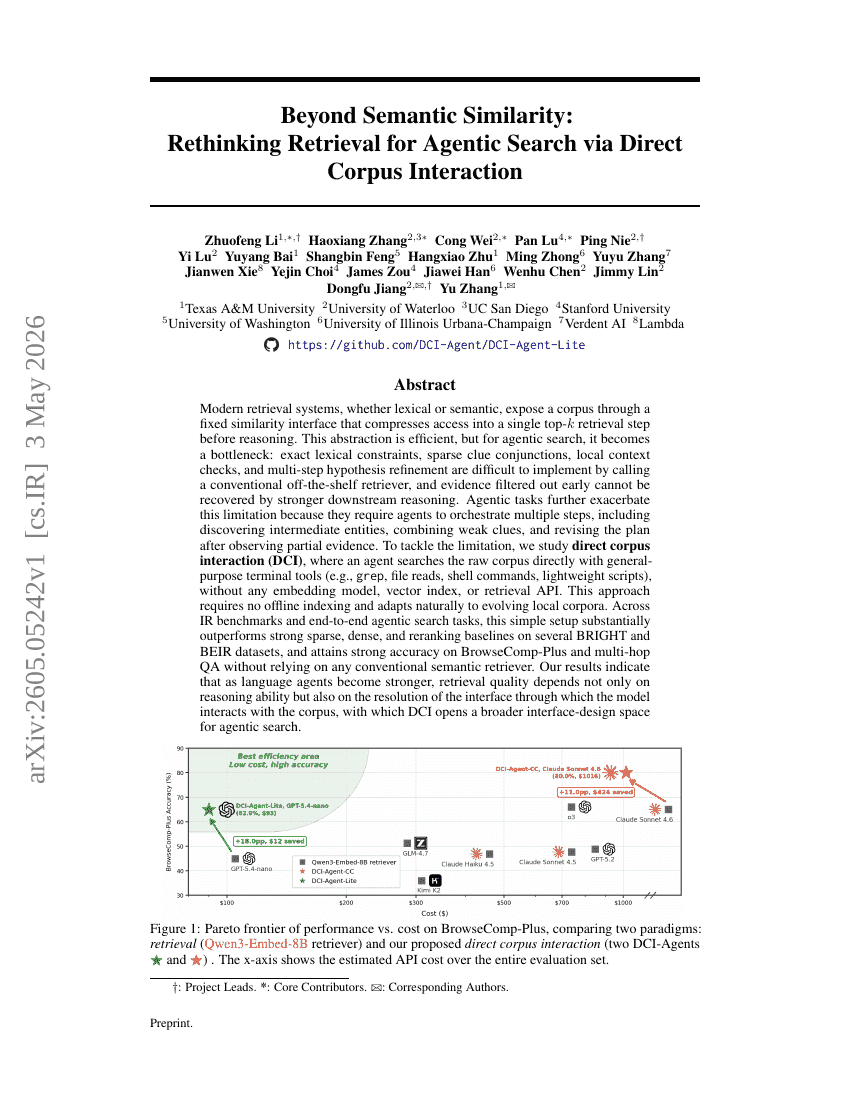
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
MathNet: A GLOBAL MULTIMODAL BENCHMARK FOR MATHEMATICAL REASONING AND RETRIEVAL
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
ZAYA1-8B Technical Report
PhysForge: Generating Physics-Grounded 3D Assets for Interactive Virtual World
HERMES++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
RLDX-1 Technical Report
Stream-T1: Test-Time Scaling for Streaming Video Generation
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
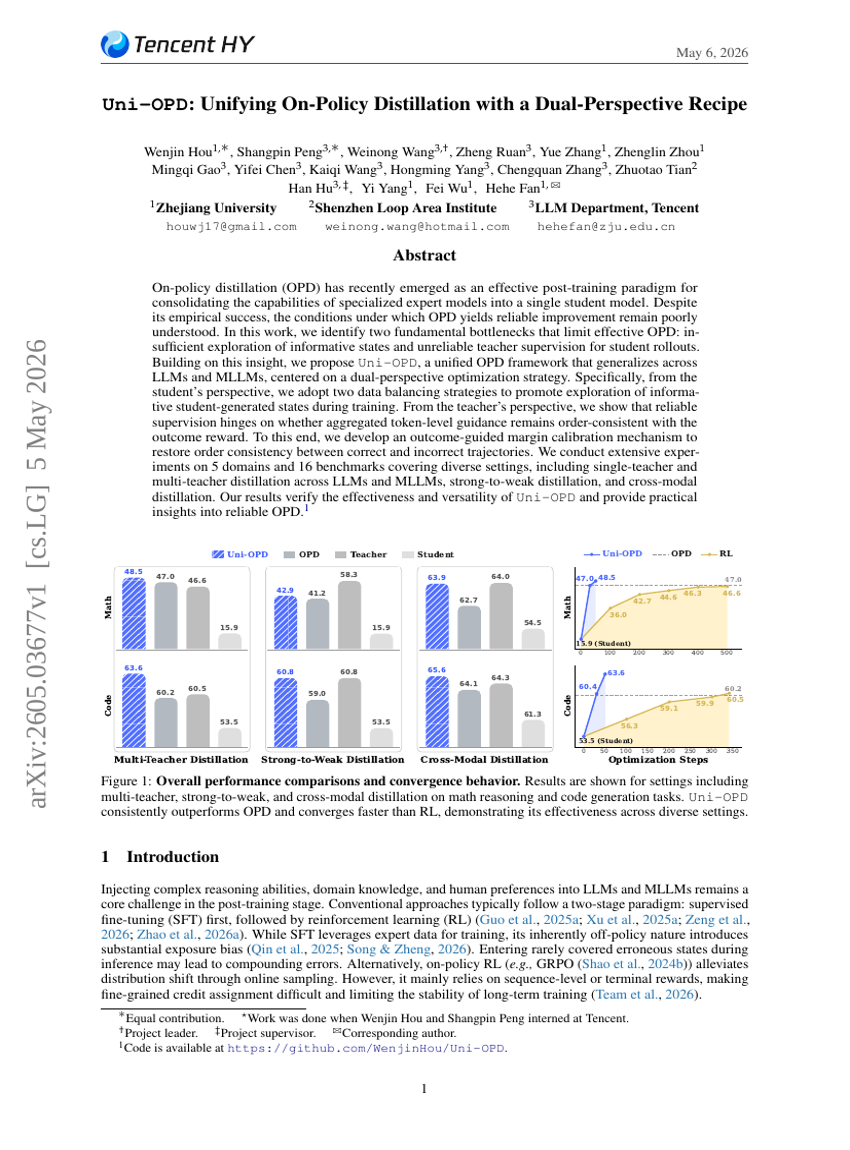
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
AGENTIC-IMODELS: Evolving agentic interpretability tools via autoresearch
HEAVYSKILL: Heavy Thinking as the Inner Skill in Agentic Harness
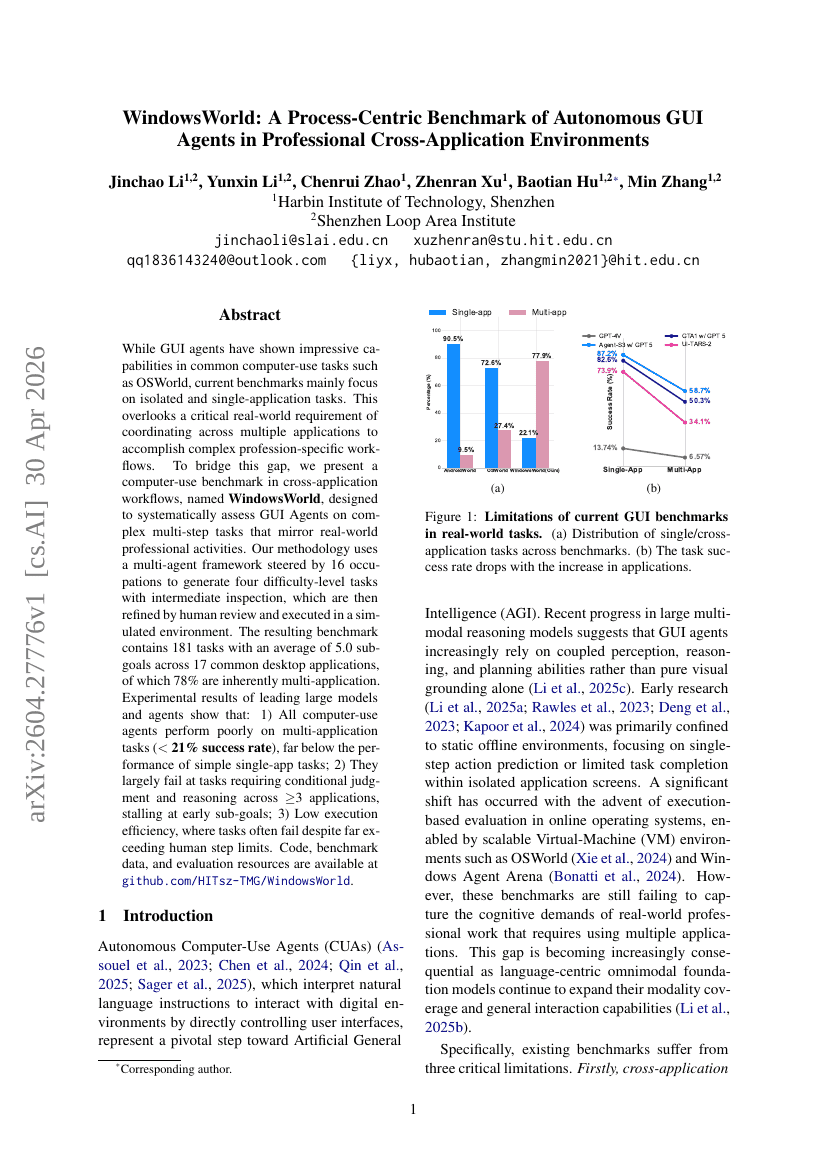
WindowsWorld: A Process-Centric Benchmark of Autonomous GUI Agents in Professional Cross-Application Environments
Hallucinations Undermine Trust; Metacognition is a Way Forward
X2SAM: Any Segmentation in Images and Videos
OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
PRISM: Pre-alignment via Black-box On-policy Distillation for Multimodal Reinforcement Learning
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
ProgramBench: Can Language Models Rebuild Programs From Scratch?
Efficient Accelerated Graph Edit Distance Computation on GPU
LLM-based uncertainty assessment of social media situational signals for crisis reporting
Canonical LST: A Protocol-Native Liquid Staking Solution for Tezos
Separating Intelligence from Execution: A Workflow Engine for the Model Context Protocol
Understanding the Performance Plateau in Text-to-Video Retrieval: A Comprehensive Empirical and Linguistic Analysis
Persistent Visual Memory: Sustaining Perception for Deep Generation in LVLMs
EnergAIzer: Fast and Accurate GPU Power Estimation Framework for AI Workloads
Leveraging Verifier-Based Reinforcement Learning in Image Editing
Efficient Training on Multiple Consumer GPUs with RoundPipe
Skill1: Unified Evolution of Skill-Augmented Agents via Reinforcement Learning
Beyond Semantic Similarity: Rethinking Retrieval for Agentic Search via Direct Corpus Interaction
MathNet: A GLOBAL MULTIMODAL BENCHMARK FOR MATHEMATICAL REASONING AND RETRIEVAL
D-OPSD: On-Policy Self-Distillation for Continuously Tuning Step-Distilled Diffusion Models
ZAYA1-8B Technical Report
PhysForge: Generating Physics-Grounded 3D Assets for Interactive Virtual World
HERMES++: Toward a Unified Driving World Model for 3D Scene Understanding and Generation
OpenSearch-VL: An Open Recipe for Frontier Multimodal Search Agents
RLDX-1 Technical Report
Stream-T1: Test-Time Scaling for Streaming Video Generation
Stream-R1: Reliability-Perplexity Aware Reward Distillation for Streaming Video Generation
Uni-OPD: Unifying On-Policy Distillation with a Dual-Perspective Recipe
AGENTIC-IMODELS: Evolving agentic interpretability tools via autoresearch
HEAVYSKILL: Heavy Thinking as the Inner Skill in Agentic Harness
WindowsWorld: A Process-Centric Benchmark of Autonomous GUI Agents in Professional Cross-Application Environments
Hallucinations Undermine Trust; Metacognition is a Way Forward
X2SAM: Any Segmentation in Images and Videos
OpenSeeker-v2: Pushing the Limits of Search Agents with Informative and High-Difficulty Trajectories
PRISM: Pre-alignment via Black-box On-policy Distillation for Multimodal Reinforcement Learning
ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration
ProgramBench: Can Language Models Rebuild Programs From Scratch?
Efficient Accelerated Graph Edit Distance Computation on GPU
LLM-based uncertainty assessment of social media situational signals for crisis reporting
Canonical LST: A Protocol-Native Liquid Staking Solution for Tezos
Separating Intelligence from Execution: A Workflow Engine for the Model Context Protocol
Understanding the Performance Plateau in Text-to-Video Retrieval: A Comprehensive Empirical and Linguistic Analysis
Persistent Visual Memory: Sustaining Perception for Deep Generation in LVLMs
EnergAIzer: Fast and Accurate GPU Power Estimation Framework for AI Workloads
Leveraging Verifier-Based Reinforcement Learning in Image Editing
Efficient Training on Multiple Consumer GPUs with RoundPipe