HyperAI
Command Palette
Search for a command to run...
Papers
Täglich aktualisierte hochmoderne KI-Forschungsarbeiten, um Sie über die neuesten KI-Trends auf dem Laufenden zu halten

Generative Modelle verstehen den Raum: Freisetzung impliziter 3D-Priors für das Szenenverständnis

Effizientes Reasoning mit Balanced Thinking

























Generative Modelle verstehen den Raum: Freisetzung impliziter 3D-Priors für das Szenenverständnis
Effizientes Reasoning mit Balanced Thinking
Vor dem Handeln schauen: Verbesserung der visuellen Grundrepräsentationen für Vision-Language-Action-Modelle
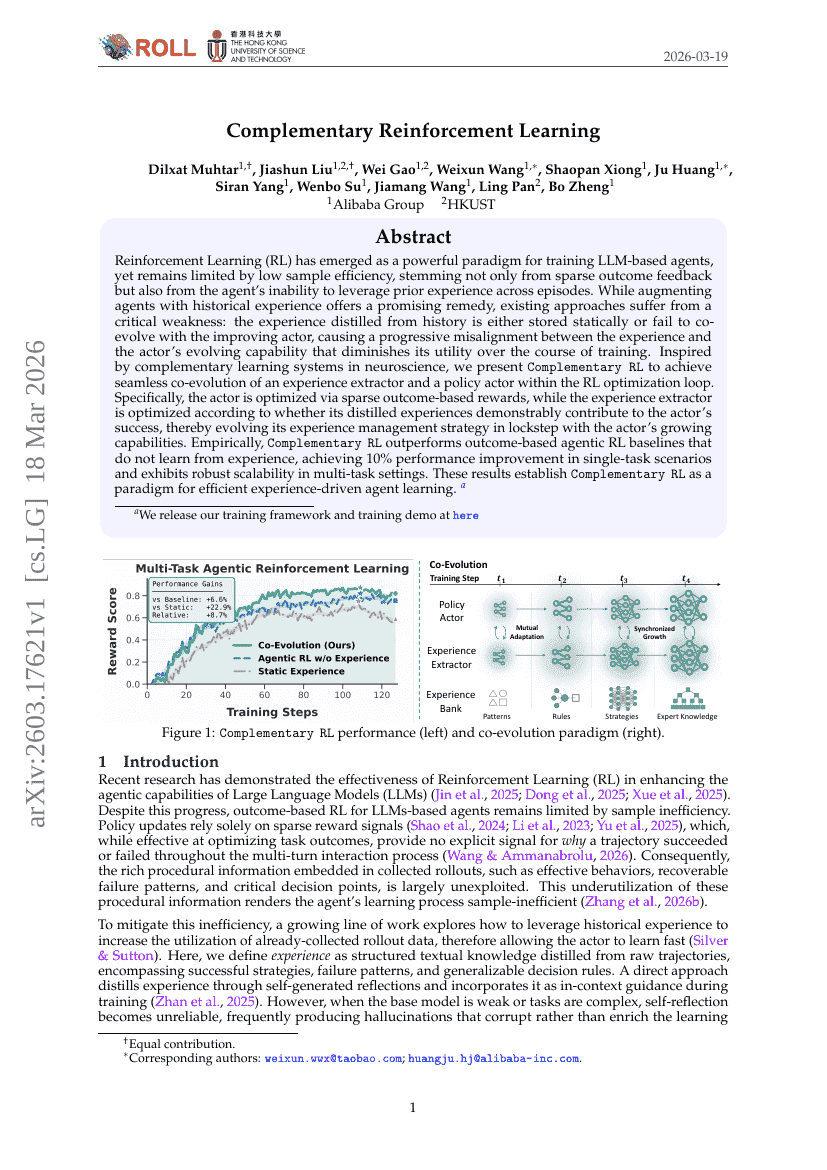
Komplementäres Reinforcement Learning
Alignment macht Sprachmodelle normativ, nicht deskriptiv.
MosaicMem: Hybride räumliche Speichersysteme für kontrollierbare Videoweltmodelle
MetaClaw: Einfach sprechen – Ein Agent, der im Freien metanlernt und sich weiterentwickelt
Video-CoE: Verstärkung der Video-Ereignisvorhersage mittels Chain of Events
FunCineForge: Ein einheitliches Dataset-Toolkit und Modell für Zero-Shot Movie Dubbing in diversen filmischen Szenen
In-Context Watermarks für Large Language Models
WorldCam: Interaktive autoregressive 3D-Spielwelten mit Kameraposen als vereinheitlichender geometrischer Darstellung
Die Entmystifizierung von Video Reasoning
Kinema4D: Kinematische 4D-Weltmodellierung für raumzeitliche eingebettete Simulationen
Qianfan-OCR: Ein einheitliches End-to-End-Modell für Dokumentenintelligenz
InCoder-32B: Ein Code-Grundmodell für industrielle Anwendungsszenarien
MiroThinker-1.7 & H1: Hin zu Heavy-Duty Research Agents durch Verifikation
HSImul3R: Physik-in-the-Loop-Rekonstruktion simulationsbereiter Mensch-Szenen-Interaktionen
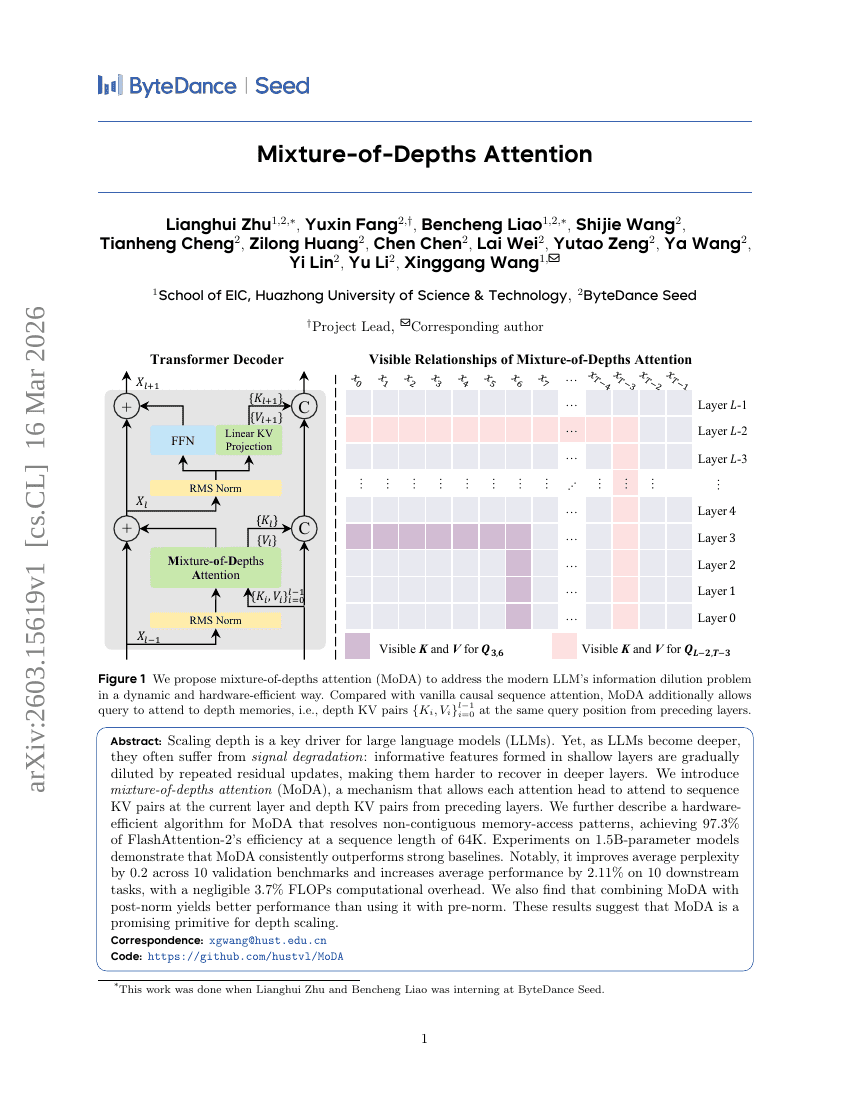
Mixture-of-Depths Attention
Aufmerksamkeitsresiduen
Verankierung von Welt-Simulationsmodellen in einer realen Metropole
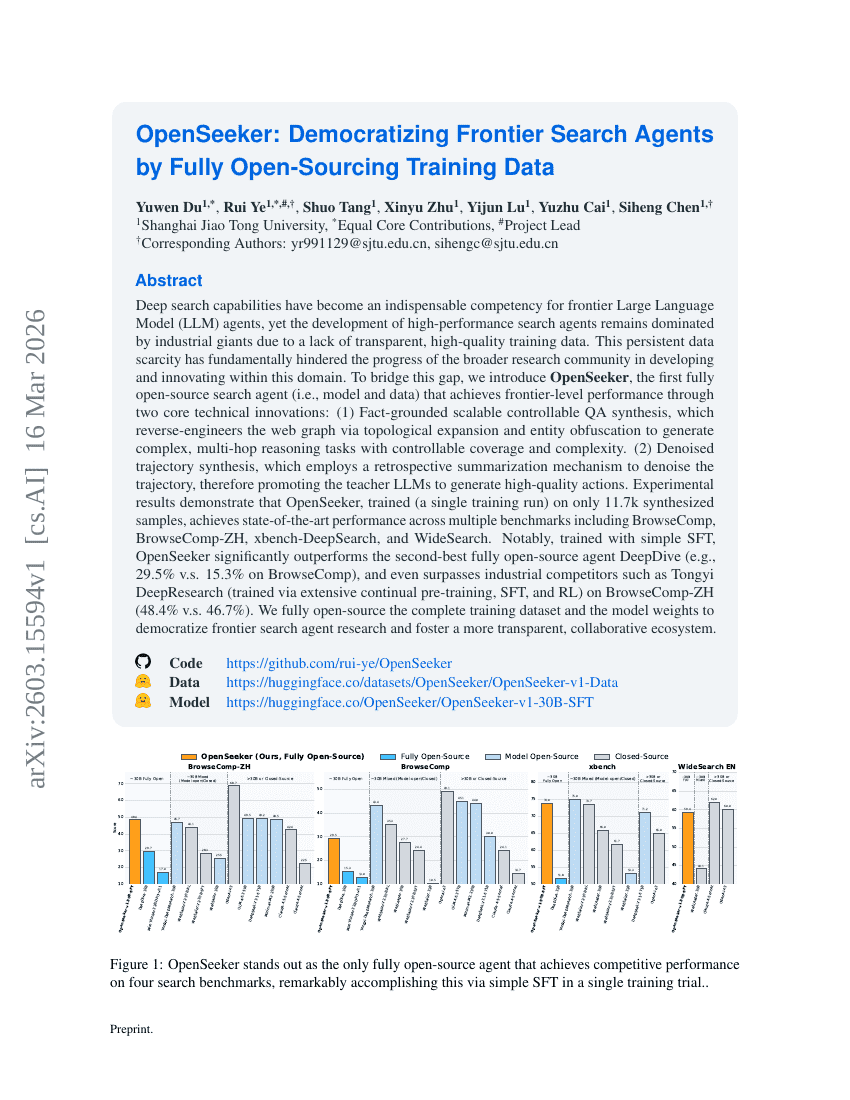
OpenSeeker: Demokratisierung von Frontier Search Agents durch vollständige Open-Sourcing von Trainingsdaten
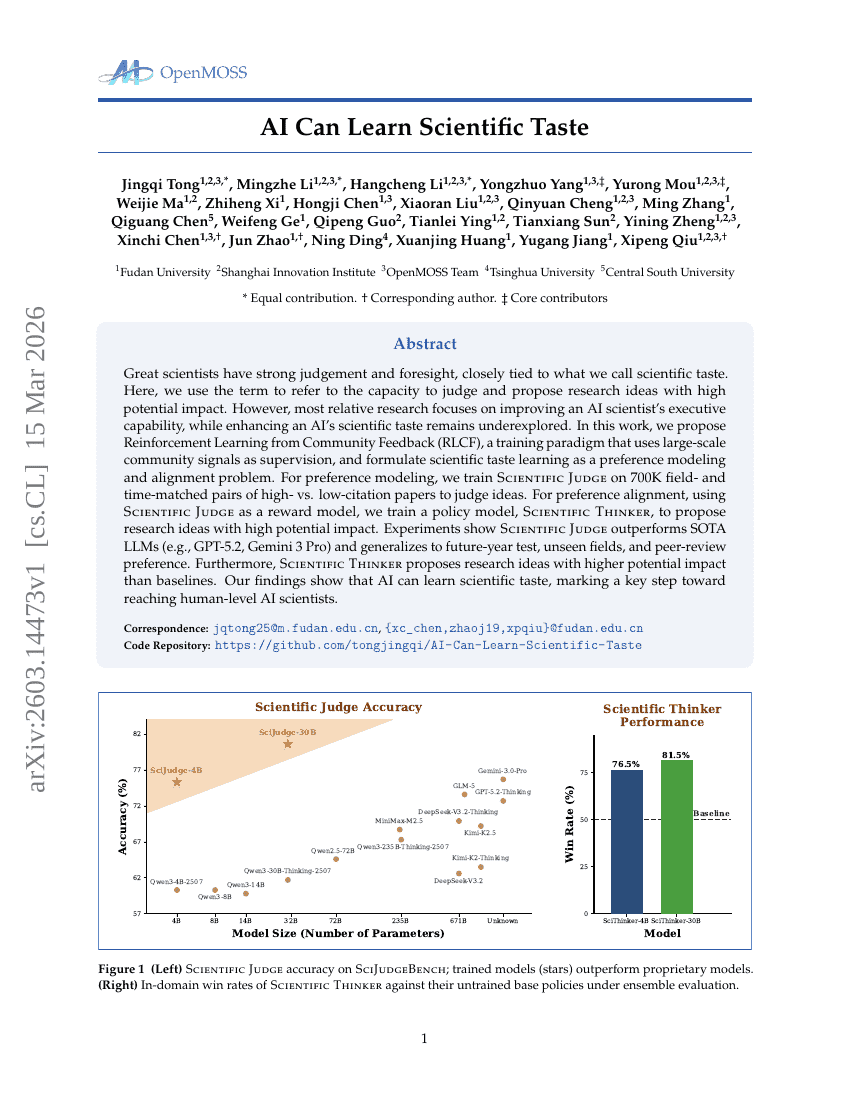
Künstliche Intelligenz kann wissenschaftlichen Geschmack erlernen.
MM-CondChain: Ein programmatisch verifizierter Benchmark für visuell fundiertes tiefes zusammengesetztes Schlussfolgern
Können Vision-Language Models das Shell-Spiel lösen?
OmniForcing: Freisetzung der Echtzeit-gemeinsamen Audio-Visual-Generierung
daVinci-Env: Skalierbare Synthese einer offenen SWE-Umgebung
Cheers: Die Entkopplung von Patch-Details von semantischen Repräsentationen ermöglicht eine einheitliche multimodale Verständigung und Generierung
LMEB: Benchmark für Langzeit-Gedächtnis-Einbettungen
DreamVideo-Omni: Omni-Motion-gesteuerte Mehrsubjekt-Videoanpassung mit latenter Identitätsverstärkung durch Reinforcement Learning
ShotVerse: Fortschritte in der kinematografischen Kamerasteuerung für textgesteuerte Erstellung von Mehrschuss-Videos
Video-basierte Belohnungsmodellierung für Computer-Nutzung-Agenten
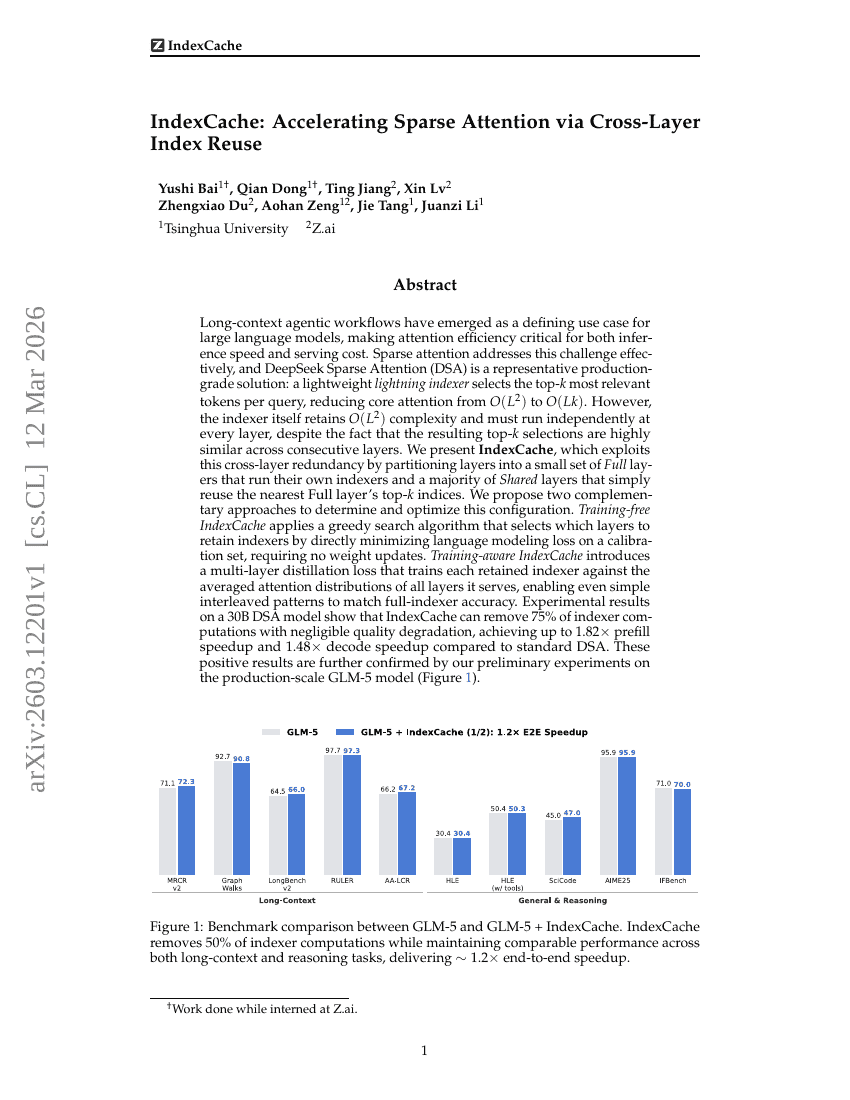
IndexCache: Beschleunigung von Sparse Attention durch Wiederverwendung von Cross-Layer-Indizes
Vor dem Handeln schauen: Verbesserung der visuellen Grundrepräsentationen für Vision-Language-Action-Modelle
Komplementäres Reinforcement Learning
Alignment macht Sprachmodelle normativ, nicht deskriptiv.
MosaicMem: Hybride räumliche Speichersysteme für kontrollierbare Videoweltmodelle
MetaClaw: Einfach sprechen – Ein Agent, der im Freien metanlernt und sich weiterentwickelt
Video-CoE: Verstärkung der Video-Ereignisvorhersage mittels Chain of Events
FunCineForge: Ein einheitliches Dataset-Toolkit und Modell für Zero-Shot Movie Dubbing in diversen filmischen Szenen
In-Context Watermarks für Large Language Models
WorldCam: Interaktive autoregressive 3D-Spielwelten mit Kameraposen als vereinheitlichender geometrischer Darstellung
Die Entmystifizierung von Video Reasoning
Kinema4D: Kinematische 4D-Weltmodellierung für raumzeitliche eingebettete Simulationen
Qianfan-OCR: Ein einheitliches End-to-End-Modell für Dokumentenintelligenz
InCoder-32B: Ein Code-Grundmodell für industrielle Anwendungsszenarien
MiroThinker-1.7 & H1: Hin zu Heavy-Duty Research Agents durch Verifikation
HSImul3R: Physik-in-the-Loop-Rekonstruktion simulationsbereiter Mensch-Szenen-Interaktionen
Mixture-of-Depths Attention
Aufmerksamkeitsresiduen
Verankierung von Welt-Simulationsmodellen in einer realen Metropole
OpenSeeker: Demokratisierung von Frontier Search Agents durch vollständige Open-Sourcing von Trainingsdaten
Künstliche Intelligenz kann wissenschaftlichen Geschmack erlernen.
MM-CondChain: Ein programmatisch verifizierter Benchmark für visuell fundiertes tiefes zusammengesetztes Schlussfolgern
Können Vision-Language Models das Shell-Spiel lösen?
OmniForcing: Freisetzung der Echtzeit-gemeinsamen Audio-Visual-Generierung
daVinci-Env: Skalierbare Synthese einer offenen SWE-Umgebung
Cheers: Die Entkopplung von Patch-Details von semantischen Repräsentationen ermöglicht eine einheitliche multimodale Verständigung und Generierung
LMEB: Benchmark für Langzeit-Gedächtnis-Einbettungen
DreamVideo-Omni: Omni-Motion-gesteuerte Mehrsubjekt-Videoanpassung mit latenter Identitätsverstärkung durch Reinforcement Learning
ShotVerse: Fortschritte in der kinematografischen Kamerasteuerung für textgesteuerte Erstellung von Mehrschuss-Videos
Video-basierte Belohnungsmodellierung für Computer-Nutzung-Agenten
IndexCache: Beschleunigung von Sparse Attention durch Wiederverwendung von Cross-Layer-Indizes