Command Palette
Search for a command to run...
Qianfan-OCR: Ein einheitliches End-to-End-Modell für Dokumentenintelligenz
Qianfan-OCR: Ein einheitliches End-to-End-Modell für Dokumentenintelligenz
Zusammenfassung
Wir stellen Qianfan-OCR vor, ein end-to-end Vision-Language-Modell mit 4 Milliarden Parametern, das Dokumentenparsen, Layout-Analyse und Dokumentenverständnis in einer einzigen Architektur vereint. Das Modell ermöglicht eine direkte Bild-zu-Markdown-Konvertierung und unterstützt diverse promptgetriebene Aufgaben, darunter Tabellenextraktion, Diagrammverständnis, Dokumenten-Frage-Antwort-Systeme (Document QA) sowie die Extraktion von Schlüsselinformationen. Um den Verlust expliziter Layout-Analyse bei end-to-end OCR zu adressieren, führen wir „Layout-as-Thought" ein: eine optionale Denkphase, die durch spezielle think-Tokens ausgelöst wird und vor der Generierung der endgültigen Ausgabe strukturierte Layout-Repräsentationen erzeugt – einschließlich Begrenzungsrahmen (bounding boxes), Elementtypen und Lesereihenfolge. Dieser Ansatz stellt die Fähigkeit zur Layout-Verankerung wieder her und verbessert gleichzeitig die Genauigkeit bei komplexen Layouts. Qianfan-OCR belegt auf OmniDocBench v1.5 (93,12) und OlmOCR Bench (79,8) unter end-to-end Modellen den ersten Platz, erzielt auf OCRBench, CCOCR, DocVQA und ChartQA wettbewerbsfähige Ergebnisse im Vergleich zu allgemeinen VLMs ähnlicher Skalierung und erreicht die höchste durchschnittliche Punktzahl auf öffentlichen Benchmarks zur Extraktion von Schlüsselinformationen, wodurch es Gemini-3.1-Pro, Seed-2.0 und Qwen3-VL-235B übertrifft. Das Modell ist öffentlich über die Baidu AI Cloud Qianfan-Plattform zugänglich.
One-sentence Summary
The Baidu Qianfan Team introduces Qianfan-OCR, a 4B-parameter end-to-end model that unifies document parsing and understanding. By integrating its novel Layout-as-Thought mechanism, it recovers explicit spatial analysis within a single architecture, outperforming prior multi-stage pipelines and large competitors on complex document benchmarks.
Key Contributions
-
The paper introduces Qianfan-OCR, a 4B-parameter end-to-end vision-language model that unifies layout analysis, text recognition, and semantic understanding to perform direct image-to-Markdown conversion across diverse prompt-driven tasks. This architecture eliminates inter-stage error propagation by retaining full visual context throughout processing, enabling joint optimization for structured parsing and document comprehension.
-
A novel mechanism called Layout-as-Thought is presented to recover explicit layout analysis within the end-to-end paradigm by triggering an optional thinking phase that generates structured representations like bounding boxes and reading order. This approach provides spatial grounding results directly while leveraging structural priors to resolve recognition ambiguities in documents with complex layouts or non-standard reading orders.
-
Experimental results demonstrate that the model ranks first among end-to-end systems on OmniDocBench v1.5 and OlmOCR Bench while achieving state-of-the-art performance on key information extraction benchmarks, surpassing larger models like Gemini-3.1-Pro. The work also shows strong generalization on standard OCR and document understanding tasks, matching the capabilities of general vision-language models of comparable scale.
Introduction
Current OCR applications in industries like contract review and document retrieval often rely on fragmented pipelines that chain separate detection, recognition, and language models. This approach increases deployment costs and causes error propagation while discarding critical visual context during text extraction. Existing solutions struggle to balance the low cost of specialized small models with the high accuracy of large vision-language models, which often underperform on structured parsing tasks.
The authors introduce Qianfan-OCR, a 4B-parameter unified end-to-end model that integrates layout analysis, text recognition, and semantic understanding into a single architecture. They leverage a novel mechanism called Layout-as-Thought, which allows the model to optionally generate explicit structural reasoning via bounding boxes and reading orders before producing final outputs. This design eliminates inter-stage errors and preserves full visual context, enabling the system to match pipeline accuracy while supporting complex tasks like chart interpretation and document question answering.
Dataset
-
Dataset Composition and Sources: The authors construct a large-scale, unified dataset using six specialized synthesis pipelines covering document parsing, key information extraction, complex tables, chart understanding, formula recognition, and multilingual OCR. Sources include internal document repositories, the HPLT multilingual corpus, and arXiv LaTeX sources from 2022 to the present.
-
Key Details for Each Subset:
- Document Parsing: Converts images to structured Markdown with normalized bounding boxes and HTML tables. The authors adopt a fine-grained 25-category label system from PaddleOCR-VL to distinguish elements like abstracts, references, and vertical text.
- Key Information Extraction (KIE): Combines open-source data with multi-model collaborative labeling to reduce hallucinations. It includes hard rule filtering for business logic validation and targets difficult samples with long sequences or dense text.
- Complex Tables: Merges programmatic synthesis (3–20 rows/columns with random merging) using Faker and LLMs with real document extraction. Real samples undergo consistency validation between PaddleOCR-VL and internal models to ensure structural reliability.
- Chart Understanding: Synthesizes over 300,000 samples from arXiv by re-rendering LaTeX figure code into vector images. The data includes metadata and visual descriptions for 11 chart types with custom reasoning tasks like trend analysis and outlier detection.
- Multilingual OCR: Extends coverage to 192 languages via reverse synthesis from the HPLT corpus. The pipeline handles diverse writing systems with automatic RTL detection, character reshaping, and randomized typesetting variations.
-
Model Usage and Training Strategy: The data supports multi-stage progressive training. The authors implement a "Layout-as-Thought" mechanism where the model generates structured layout analysis within
<layout>tags before final output to improve spatial reasoning. Sample distributions are rebalanced based on task difficulty to enhance stability in extreme scenarios. -
Processing and Augmentation Details:
- Cropping and Geometry: Bounding box coordinates are normalized to [0, 999] for resolution invariance. Rotation augmentation (90°, 180°, 270°, and ±15°) is applied to improve performance on non-standard document orientations.
- Noise Injection: Two distinct augmentation pipelines apply three noise stages: text noise (broken strokes, ink bleeding), background noise (textures, watermarks), and imaging noise (blur, shadows, exposure variation).
- Filtering: Automatic filters remove repetitive or extreme-length samples, while consistency checks and business logic rules ensure high annotation quality across all subsets.
Method
The authors present Qianfan-OCR, a 4B-parameter end-to-end document intelligence model that unifies document parsing, layout analysis, and understanding within a single vision-language architecture. The model adopts a multimodal bridging architecture consisting of three core components: a vision encoder for flexible visual encoding, a lightweight projection adapter for cross-modal alignment, and a language model backbone for text generation and reasoning.
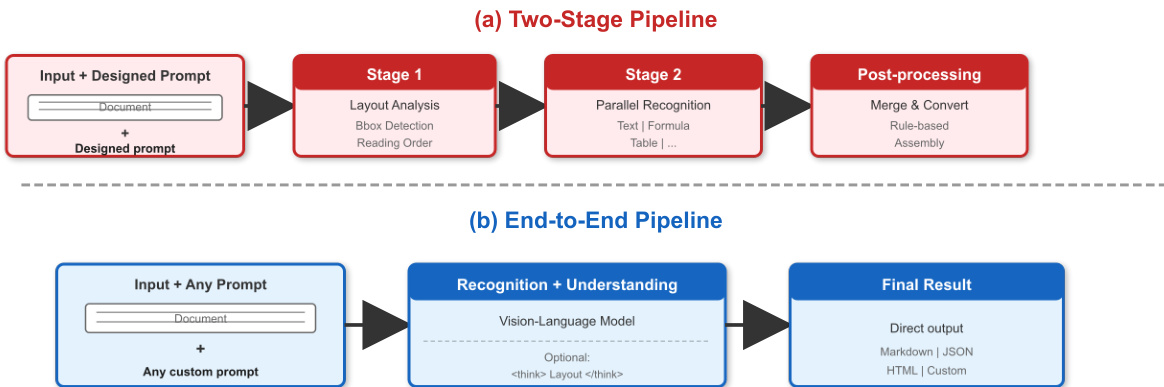
As shown in the figure above, the proposed End-to-End Pipeline (b) contrasts with traditional multi-stage approaches (a) by performing direct image-to-Markdown conversion and supporting prompt-driven tasks within one model. The vision encoder employs Qianfan-ViT, which utilizes an AnyResolution design to dynamically tile input images into 448×448 patches, supporting variable-resolution inputs up to 4K. This encoder consists of 24 Transformer layers with 1024 hidden dimensions and 16 attention heads, producing 256 visual tokens per tile. With a maximum of 16 tiles, the system can represent a single document image with up to 4,096 visual tokens, ensuring sufficient spatial resolution for fine-grained character recognition.
Connecting the visual and textual modalities is a lightweight two-layer MLP with GELU activation. This adapter projects visual features from the encoder's representation space of 1024 dimensions into the language model's embedding space of 2560 dimensions. This design minimizes adapter parameters while ensuring effective cross-modal alignment. The language model backbone is Qwen3-4B, featuring 4.0B total parameters, 36 layers, and a 32K native context window extendable to 131K via YaRN. To balance reasoning capability with deployment efficiency, the model uses Grouped-Query Attention (GQA) with 32 query heads and 8 KV heads, reducing KV cache memory by 4× compared to standard multi-head attention.
To bridge the gap between end-to-end generation and the need for explicit layout analysis, the authors introduce Layout-as-Thought. This mechanism utilizes an optional thinking phase triggered by ⟨think⟩ tokens, where the model generates structured layout representations, including bounding boxes, element types, and reading order, before producing final outputs. This approach recovers layout analysis functionality within the end-to-end paradigm and provides targeted accuracy improvements on documents with complex layouts or non-standard reading orders.
The training process follows a four-stage progressive methodology designed to systematically build model capabilities. Stage 1 focuses on Cross-Modal Alignment using 50B tokens with adapter-only training to establish fundamental vision-language alignment. Stage 2 involves Foundational OCR Training with 2T tokens and full parameter training, utilizing an OCR-heavy data mixture comprising Document OCR, Scene OCR, and specialized tasks like handwriting and formula recognition. Stage 3 implements Domain-Specific Enhancement with 800B tokens, targeting enterprise-critical domains such as complex tables, formulas, and charts while maintaining a balance of general data to prevent catastrophic forgetting. Finally, Stage 4 covers Instruction Tuning and Reasoning Enhancement using millions of instruction samples. This stage employs data curation, reverse synthesis, and chart data mining to cover a comprehensive set of document intelligence tasks, ensuring robustness to diverse user instructions.
Experiment
- Multi-stage training ablation studies validate that foundational general-purpose pretraining is essential for OCR performance and cannot be replaced by domain-specific data alone, while mixing general and OCR data during specialization prevents overfitting and maintains general capabilities.
- The complete four-stage training pipeline achieves optimal results, outperforming strong general-purpose vision-language models and demonstrating that the progressive training recipe generalizes effectively across model scales.
- Evaluation on specialized and general OCR benchmarks confirms that the model achieves state-of-the-art end-to-end performance, particularly excelling in multilingual recognition and complex document parsing while retaining competitive general OCR abilities.
- Document understanding tests reveal that end-to-end processing significantly outperforms traditional two-stage OCR-plus-LLM pipelines, especially for chart interpretation and academic reasoning where spatial layout and structural context are critical.
- Key information extraction experiments show the model surpasses both commercial large models and larger open-source alternatives, validating its superior ability to associate spatial fields with content across Chinese and English scenarios.
- Inference throughput analysis demonstrates that the end-to-end architecture avoids CPU bottlenecks inherent in pipeline systems, enabling competitive processing speeds and simpler deployment through efficient GPU-centric batching and quantization.
- Analysis of the Layout-as-Thought mechanism indicates that explicit layout reasoning improves accuracy on documents with heterogeneous and complex structures but introduces unnecessary overhead for simple, homogeneous pages.