Command Palette
Search for a command to run...
Video-basierte Belohnungsmodellierung für Computer-Nutzung-Agenten
Video-basierte Belohnungsmodellierung für Computer-Nutzung-Agenten
Linxin Song Jieyu Zhang Huanxin Sheng Taiwei Shi Gupta Rahul Yang Liu Ranjay Krishna Jian Kang Jieyu Zhao
Zusammenfassung
Computer-Nutzung-Agenten (CUAs) werden zunehmend leistungsfähiger; gleichwohl bleibt die skalierbare Evaluation, ob eine Trajektorie eine Benutzeranweisung tatsächlich erfüllt, nach wie vor schwierig. In dieser Arbeit untersuchen wir das Reward-Modellieren auf Basis von Ausführungs-Videos: eine Folge von Schlüsselbildern aus einer Agenten-Trajektorie, die unabhängig von der internen Schlussfolgerung oder den Aktionen des Agenten ist. Obwohl die Modellierung von Ausführungs-Videos methodenagnostisch ist, stellt sie zentrale Herausforderungen, darunter stark redundante Layouts sowie subtile, lokalisierte Hinweise, die über Erfolg oder Misserfolg entscheiden. Wir stellen Execution Video Reward 53k (ExeVR-53k) vor, einen Datensatz mit 53.000 hochwertigen Triplets aus Video, Aufgabe und Reward. Darüber hinaus führen wir eine adversarische Instruktionsübersetzung ein, um negative Stichproben mit Annotationen auf Ebene einzelner Schritte zu synthetisieren. Um das Lernen aus langen, hochauflösenden Ausführungs-Videos zu ermöglichen, entwickeln wir eine spatiotemporale Token-Pruning-Strategie, die homogene Regionen und persistente Token entfernt, während entscheidende Änderungen der Benutzeroberfläche erhalten bleiben. Auf Basis dieser Komponenten fine-tunen wir ein Execution Video Reward Model (ExeVRM), das ausschließlich eine Benutzeranweisung und eine Sequenz von Ausführungs-Videos als Eingabe erhält, um den Erfolg der Aufgabe vorherzusagen. Unser ExeVRM-8B erreicht bei der Bewertung von Ausführungs-Videos eine Genauigkeit von 84,7 % und eine Recall-Rate von 87,7 % und übertrifft dabei leistungsstarke proprietäre Modelle wie GPT-5.2 und Gemini-3 Pro auf den Plattformen Ubuntu, macOS, Windows und Android, wobei es eine präzisere zeitliche Zuordnung liefert. Diese Ergebnisse zeigen, dass das Reward-Modellieren auf Basis von Ausführungs-Videos als skalierbarer, methodenagnostischer Evaluierer für CUAs dienen kann.
One-sentence Summary
Researchers from USC, University of Washington, MBZUAI, and Amazon AGI propose ExeVRM, a video-execution reward model that leverages spatiotemporal token pruning and adversarial instruction translation to accurately assess computer-use agent success across diverse platforms while outperforming proprietary baselines.
Key Contributions
- Computer-use agents lack scalable evaluation methods that are independent of internal reasoning, necessitating a shift toward video-based reward modeling that assesses task success solely from observable interface states.
- The authors introduce the ExeVR-53k dataset with 53k video-task-reward triplets and propose adversarial instruction translation to synthesize negative samples, alongside a spatiotemporal token pruning strategy to filter redundant visual content while preserving decisive UI changes.
- Their Execution Video Reward Model (ExeVRM) achieves 84.7% accuracy and 87.7% recall on the ExeVR-Bench, outperforming strong proprietary models like GPT-5.2 and Gemini-3 Pro across multiple operating systems while providing superior temporal attribution for error localization.
Introduction
Computer-use agents (CUAs) automate complex tasks across diverse operating systems, yet evaluating their success remains a bottleneck due to the reliance on brittle, hand-crafted scripts that do not scale to new environments. Prior approaches struggle with the high redundancy of interface layouts and the scarcity of annotated failure cases, which makes it difficult to train models that can detect subtle visual cues determining task completion. The authors address these issues by introducing ExeVR-53k, a large-scale dataset of video-task-reward triplets, and propose adversarial instruction translation to synthesize hard negative samples with step-level annotations. They further develop a spatiotemporal token pruning strategy to efficiently process long, high-resolution execution videos by removing static regions while preserving decisive UI changes. Leveraging these components, they train the Execution Video Reward Model (ExeVRM), which achieves superior accuracy and recall compared to proprietary models by judging task success directly from observable video sequences without needing access to internal agent reasoning.
Dataset
ExeVR-53k Dataset Overview
-
Dataset Composition and Sources The authors introduce ExeVR-53k, a 53,000-sample training corpus designed to overcome data bottlenecks in computer-use reward modeling. This dataset aggregates trajectories from three primary sources: AgentNet and ScaleCUA, which provide human-supervised demonstrations, and OSWorld, which supplies solutions generated by 30 diverse computer-using agents. This combination ensures coverage across end-to-end and agentic paradigms while spanning multiple operating systems including Windows, macOS, Ubuntu, Android, and web environments.
-
Key Details for Each Subset
- OSWorld: Contains 361 evaluated tasks focused on open-domain web and desktop applications. The authors treat rollouts from 30 distinct agent systems (ranging from proprietary models like Claude and Gemini to open-weight research models) as training trajectories to ensure behavioral diversity.
- AgentNet: Contributes 22,625 human-labeled tasks across 11 subdomains such as e-commerce, office tools, and software development. Data is distributed across Windows (12K), macOS (5K), and Ubuntu (5K) environments.
- ScaleCUA: Provides a large-scale, GUI-centric dataset covering Linux, macOS, Windows, Android, and web platforms. It utilizes a hybrid pipeline where grounding examples are automatically collected with LLM assistance and human verification, while trajectory data relies on human interaction logs augmented with LLM annotations.
-
Data Processing and Video Construction The authors convert raw interaction records into a unified step-level video representation. They segment each trajectory into individual steps and extract a representative key frame (screenshot) for each action to capture the UI state. These frames are concatenated in temporal order to create compact video summaries rendered at 1 FPS. This strategy maintains a coarse-grained view of interaction progression while keeping input lengths manageable for model training.
-
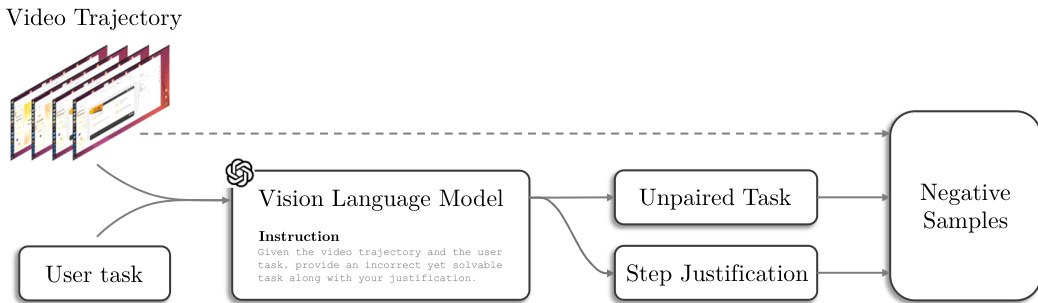
Adversarial Instruction Translation for Negative Samples To address the lack of counterexamples in demonstration-heavy datasets, the authors employ an adversarial instruction translation technique. They prompt a vision-language model to generate plausible but unpaired task instructions for valid trajectory segments, creating hard negatives that are visually similar yet semantically inconsistent. The model also outputs justifications and reference steps for temporal grounding. These synthetic pairs undergo manual verification to ensure a 100% pass rate on quality audits before inclusion.
-
Evaluation Benchmark (ExeVR-Bench) The authors construct ExeVR-Bench from a held-out split of ExeVR-53k containing 789 instances with a balanced class ratio of positive and negative trajectories. The benchmark includes tasks from Ubuntu (Agent and Human), Mac/Win, and Android. For evaluation, all videos are rendered at 720p with a maximum of 100 frames sampled at 1 FPS. The dataset supports both binary judgment (correct vs. incorrect) and attribution judgment, which requires identifying the specific time range where the first error occurs.
Method
The authors propose a comprehensive framework for training vision-language models on computer-use trajectories, addressing the computational challenges of high-resolution video inputs while ensuring robust evaluation. The core methodology integrates an efficient spatiotemporal token pruning mechanism with a structured evaluation protocol utilizing specific prompting strategies.
Spatiotemporal Token Pruning
Training reward models for computer use typically requires high-resolution video inputs to capture fine-grained UI elements such as icons, cursors, and small text. However, processing full-resolution frames exhausts the token budget and leads to prohibitive memory usage. To mitigate this, the authors introduce Spatiotemporal Token Pruning, which reduces the effective context length by discarding redundant visual tokens in both space and time.
The training process, summarized in Algorithm 1, begins by freezing the vision encoder V and projector P, training only the LLM parameters. For each training sample (X,V,Y), the video frames V are encoded into patch tokens ZV. The system then applies two pruning stages. First, Spatial Token Pruning (STP) constructs a per-frame UI-connected graph G(t) where nodes represent patches and edges connect spatial neighbors with similar features. Connected components are identified, and large components (likely background regions) exceeding a size threshold τlarge are pruned. This generates a spatial mask Ms.
Second, Temporal Token Pruning (TTP) addresses redundancy across frames. In UI-dense videos, many frames share the same layout while task-relevant evidence is concentrated in transient changes. TTP maintains a reference token vi(ref) for each spatial location, initialized from the first frame. Subsequent tokens are compared against this reference using cosine similarity simcos(⋅,⋅). Tokens with similarity above a threshold τt are pruned, and the reference is updated only when a distinct state is encountered. This generates a temporal mask Mt.
The final mask M is the logical AND of Ms and Mt, ensuring tokens are kept only if they are significant in both space and time. The pruned tokens are packed into a shorter sequence ZV, projected to the LLM input space, and used to update the model parameters via the reward modeling loss Lrm.
Evaluation and Reward Modeling
To assess agent performance and generate training signals, the framework employs specialized prompting strategies for different evaluation components. These prompts guide the model to analyze user intent, action history, and UI states to determine task success.
For the Action Evaluation Reward (AER) component, the system utilizes a structured prompt format. The user prompt provides the user intent, action history, and the final snapshot of the web page. Refer to the user prompt example below:
The corresponding system prompt instructs the model to act as an expert evaluator for GUI agents. It defines various task types, such as information seeking, navigation, and content modification, and requires the model to output a "success" or "failure" status based on the final state. Refer to the system prompt details below:

Additionally, a Simplified Judge mechanism is employed to provide more granular feedback. The user prompt for this component specifies the user goal and the sequence of actions taken by the agent, including step numbers, actions, and reasoning. Refer to the user prompt structure below:

The system prompt for the Simplified Judge requires the model to answer four specific questions regarding the agent's performance: whether the sequence was successful, if unnecessary actions were performed, if the task was performed optimally, and if the agent looped without progress. Refer to the system prompt instructions below:

Finally, the framework incorporates the ZeroGUI prompting strategy, which emphasizes detailed analysis of screenshots to identify mistakes and UI changes. The prompt instructs the model to analyze each screenshot, provide overall reasoning about the final state, and output a score. Refer to the ZeroGUI prompt example below:

This multi-faceted evaluation approach ensures that the model receives detailed feedback on both the outcome and the process of task execution. For instance, when analyzing a specific step, the model examines details such as context menus and hover states to determine intent. Refer to the screenshot analysis example below:

Experiment
- Main performance evaluation demonstrates that training a video reward model on computer-using trajectories yields superior preference modeling and temporal attribution compared to prompting general-purpose vision-language models or using sparse snapshot baselines.
- Ablation studies confirm that dense video context significantly outperforms methods relying only on initial or final screenshots, as ignoring causal transitions hinders accurate task completion judgment.
- Experiments show that higher input resolution (720p) preserves fine-grained GUI cues essential for reward prediction, with spatiotemporal token pruning making high-resolution long-horizon training computationally feasible.
- Analysis of pruning strategies reveals that temporal pruning is more critical than spatial pruning for capturing decisive state transitions, while combining both methods optimizes the trade-off between accuracy, recall, and training efficiency.
- Visualization results validate that the proposed pruning approach effectively removes redundant static elements while retaining subtle, task-relevant evidence such as transient dialogs and localized UI changes.